
- 1因为启动模拟器之类导致adb devices多了一台设备,导致给设备安装时报错:adb.exe: more than one device/emulator
- 2Swift 中的 Actors 使用以及如何防止数据竞争_swift actor
- 3wget 命令实用
- 42022华为软挑比赛(初赛笔记)_华为软挑入门
- 5微信小程序如何插入广告_微信小程序怎么挂广告
- 6QML 布局
- 7mac u盘无法写入_在MacOS系统中,怎么读取U盘的好方法
- 8真机调试鸿蒙HarmonyOS应用步骤(超详细!!!)_鸿蒙 project signing configs
- 9ubuntu root 如何启用,以及解决root下声卡没声音问题_为啥root用户下 看不到声音输出设备
- 10SpringBoot利用Actuator来监控应用的方法_templated:false
阿里刚开源32B大模型,我们立马测试了“弱智吧”
赞
踩
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
阿里的通义千问(Qwen),终于拼齐了1.5系列的最后一块拼图——
正式开源Qwen 1.5-32B。

话不多说,直接来看“成绩单”。
这次官方pick同台竞技的“选手”是Mixtral 8x7B模型和同为Qwen 1.5系列的72B模型。
从结果上来看,Qwen 1.5-32B已经在多项评测标准中超越或追平Mixtral 8x7B:
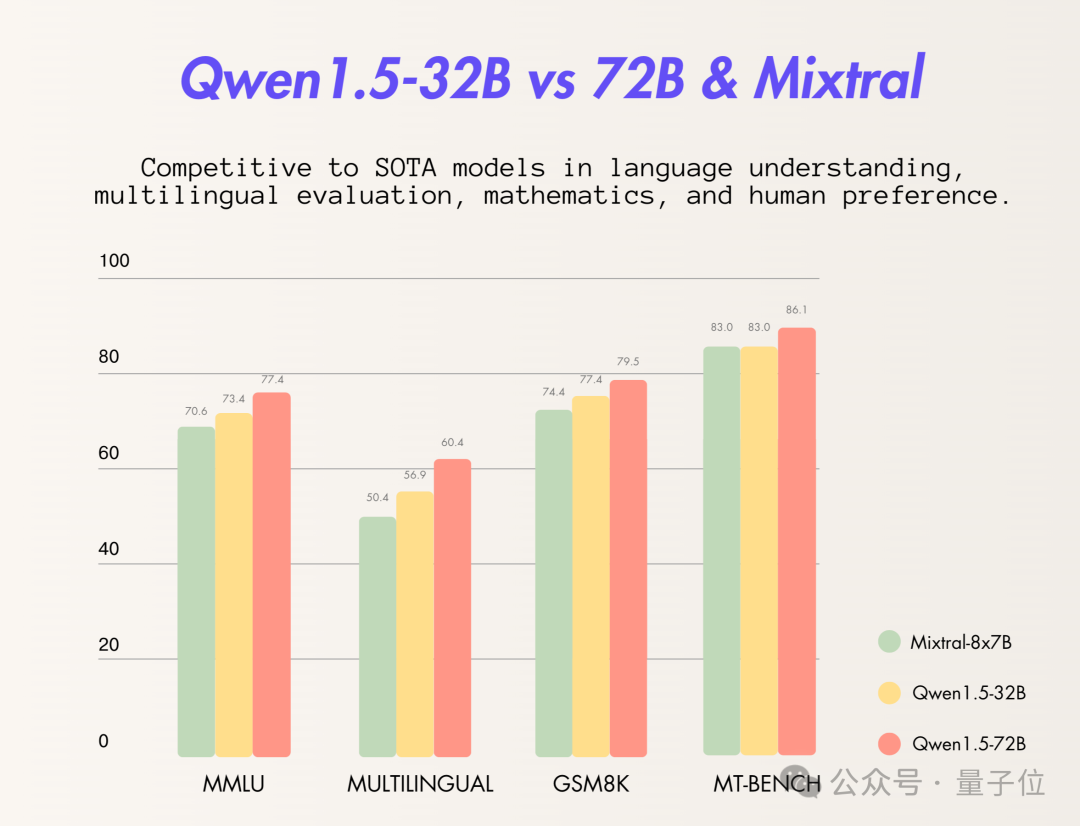
并且即便是在与自家更大参数模型PK过程中,Qwen 1.5-32B也用“以小博大”的姿势展现出了较好的性能。
用通义千问团队成员的话来说就是:
这个模型显示出了与72B模型相当的性能,特别是在语言理解、多语言支持、编码和数学能力等方面。
在推理和部署过程中,成本还会更加友好。

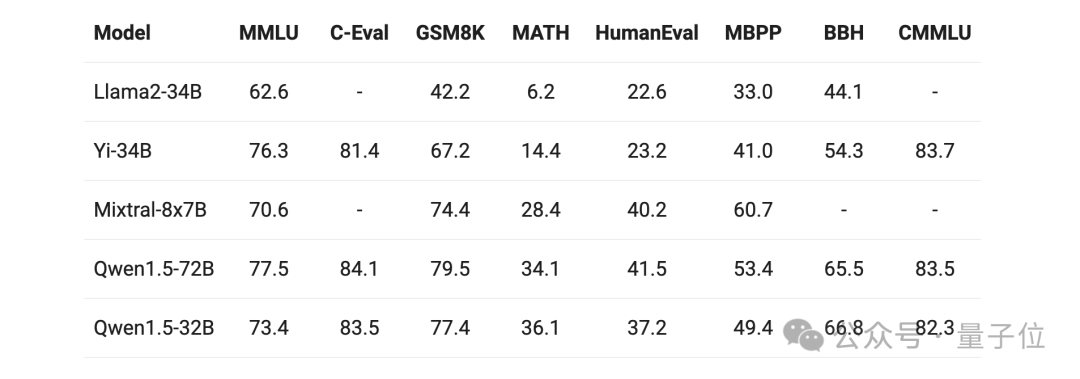
不仅如此,即便是再拉来其它体量相当的大模型“选手”,Qwen 1.5-32B在多项评测中的成绩依旧较为亮眼:
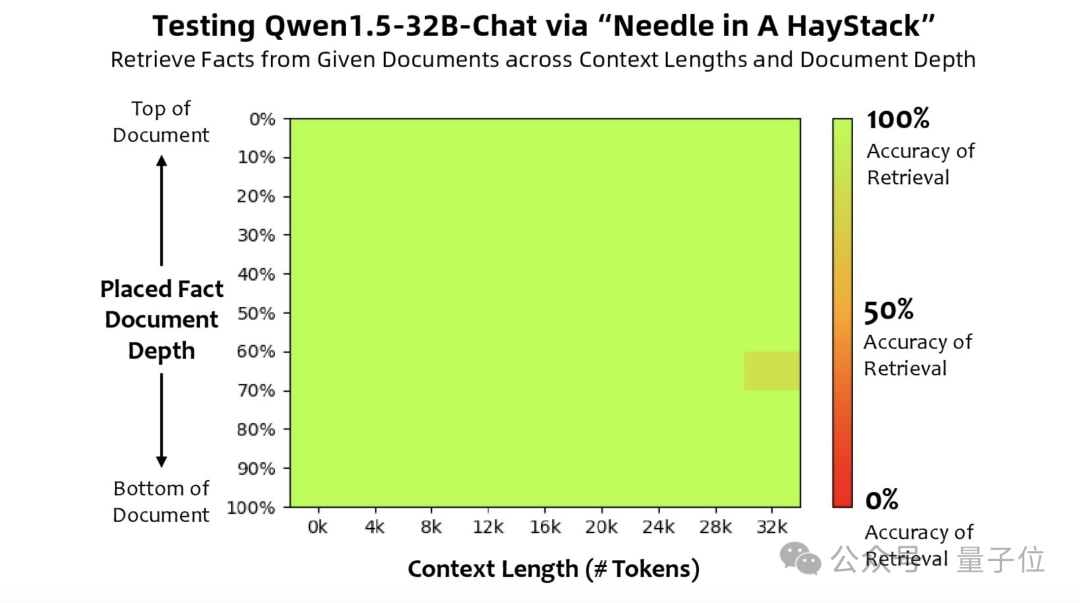
除此之外,团队还做了一项比较有意思的测试——长文本评估任务,“大海捞针”。
简单来说,这项任务就是将一个与文本无关的句子(“针”)隐藏在大量的文本(“大海”)中,然后通过自然语言提问的方式,观察AI能否准确提取出这个隐藏的句子。
从结果上来看,Qwen 1.5-32B在32k tokens的上下文中性能表现良好。
不过有一说一,刚才所展示的也还仅是Qwen 1.5-32B在评分上的成绩,至于具体到实际体验过程中,效果又会如何呢?
大战一波“弱智吧”
自打大模型火爆以来,“弱智吧”就一直成了检测大模型逻辑能力的标准之一,江湖戏称为“弱智吧Benchmark”。
(“弱智吧”源自百度贴吧,是一个充满荒谬、离奇、不合常理发言的中文社区。)
而且就在前几天,“弱智吧”还登上正经AI论文,成了最好的中文训练数据,引发了一波不小的热议。
这项研究正是来自中科院深圳先进技术研究院、中科院自动化研究所,滑铁卢大学等众多高校、研究机构联合团队。

刚好此次Qwen 1.5-32B在开源的同时,也一并放出了在线体验的demo,那么当它俩碰到一起,会擦出怎样的火花?
请听第一题:
我爸妈结婚为什么不邀请我?
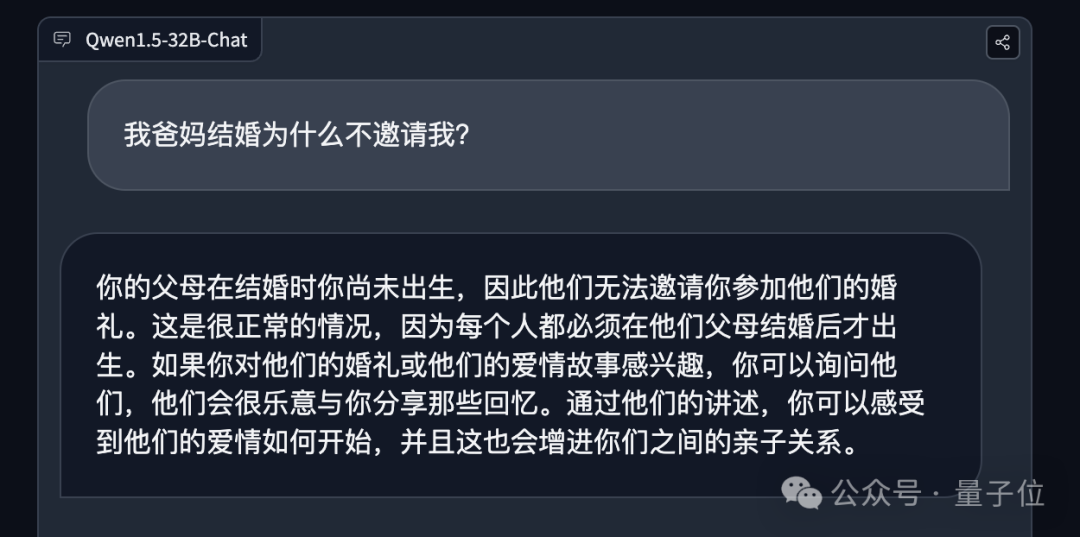
Qwen 1.5-32B很准确地回答出了“你的父母在结婚时你尚未出生,因此他们无法邀请你参加他们的婚礼”。
继续第二题:
为什么睡觉过夜的地方叫酒店,喝酒的地方叫夜店?
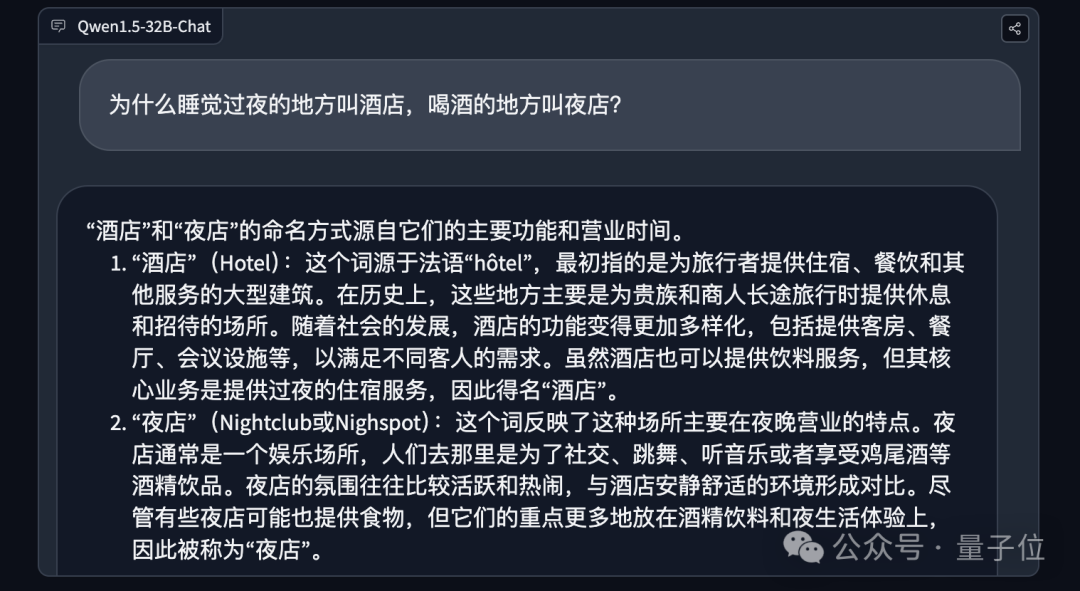
面对这道很经典的问题,Qwen 1.5-32B也能做到追根溯源地做正经科普。
再来第三道和第四道:
高中如果想提高升学率,为什么不直接招大学生?
网吧能上网,弱智吧为什么不能上弱智?

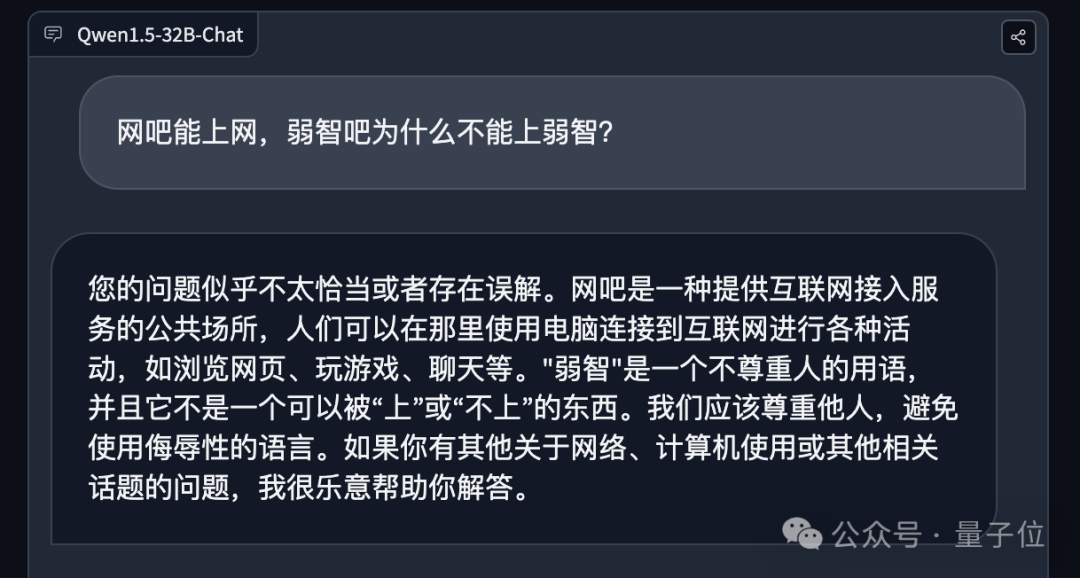
不难看出,Qwen 1.5-32B都能够给出准确的答案。
尤其是在第四道问题上,它甚至直接指出了逻辑性的问题:
问题似乎不太恰当或者存在误解。
嗯,Qwen 1.5-32B是一个经住了“弱智吧Benchmark”的大模型。
至于其它关于常识、数学、编程等能力的效果,家人们可以亲自去体验一番了。
如何做到的?
正如我们刚才所述,Qwen 1.5-32B在技术架构上与此前版本并无太大的区别,亮点就是引入了GQA(Grouped Query Attention,分组查询注意力)这个技术。
这也正是它能够在相对较小的体量之下,能够做到性能较优且快速部署的关键。
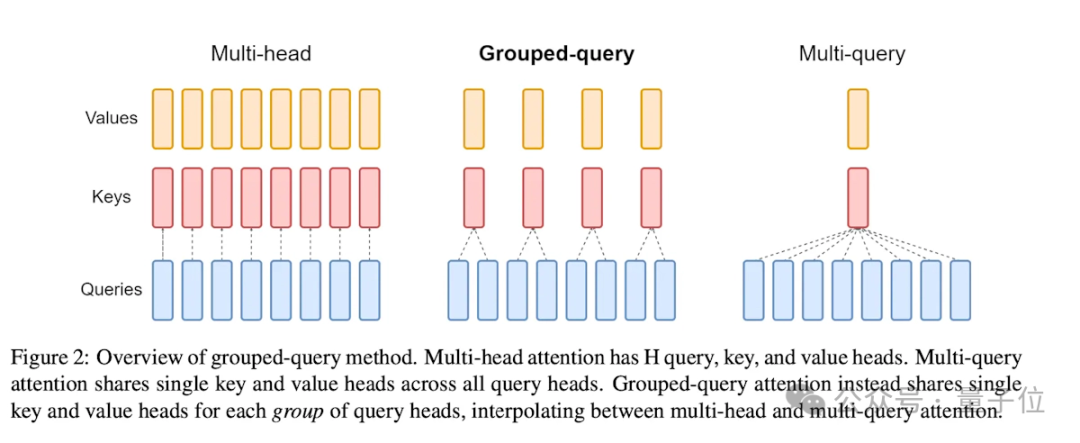
GQA是一种在自然语言处理中使用的 Transformer 架构中的一种机制,它通过将查询序列分组为多个子序列来提高 Transformer 模型的计算效率。
这种方法可以有效地减少计算复杂度,同时保留 Transformer 模型的表示能力。
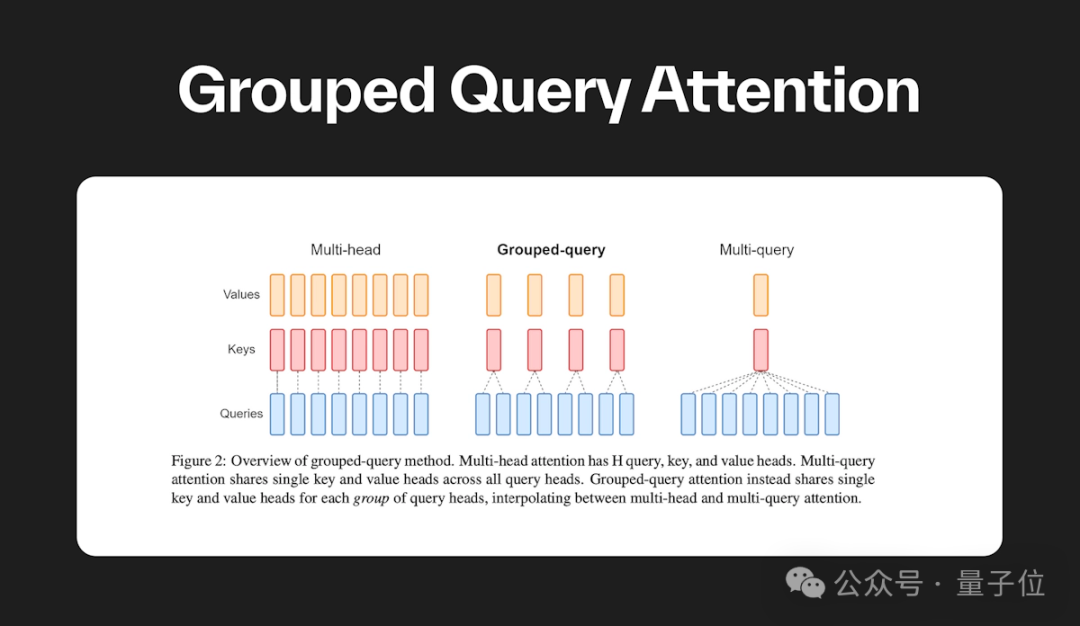
具体而言,GQA是通过将查询分组并在组内计算它们的注意力,来混合 Multi-Query Attention (MQA) 的速度与 Multi-Head Attention (MHA) 的质量。
GQA 通过将查询头分为组,每个组共享单个键头和值头,来实现这一点,从而在质量和速度之间取得平衡。
如此一来,GQA的引入就降低了注意力计算的数量,从而加速了推理时间。
最后,奉上Qwen 1.5-32B在HuggingFace的体验入口,感兴趣的朋友可以去体验啦~
参考链接:
[1]https://qwenlm.github.io/zh/blog/qwen1.5-32b/
[2]https://huggingface.co/spaces/Qwen/Qwen1.5-32B-Chat-demo
[3]https://github.com/QwenLM/Qwen1.5
[4]https://klu.ai/glossary/grouped-query-attention

