
热门标签
热门文章
- 1【鸿蒙开发】配置文件中添加权限_鸿蒙arkts 权限
- 2GitHub如何生成密钥_git hub ssl密钥生成
- 3uniapp开发 h5实现复制到剪贴板功能_h5 粘贴板
- 4宇视 VM 平台通过 onvif 协议添加的相机离线问题_宇视添加海康摄像头显示离线
- 5【大模型--- 量化与微调的原理、区别】_微调之后的模型可以量化吗
- 6多系统引导
- 7【NLP】多标签分类【上】_用br和cc算法进行多标签分类
- 8SRC漏洞挖掘--CNVD国家信息安全漏洞共享平台
- 9Ubuntu20.04下cuda、cudnn、paddle安装的完整过程_ubuntu20.04安装cuda
- 10【Devc++】8款经典小游戏_c++游戏
当前位置: article > 正文
11-pyspark的RDD的变换与动作算子总结
作者:小小林熬夜学编程 | 2024-04-10 12:06:47
赞
踩
11-pyspark的RDD的变换与动作算子总结
PySpark实战笔记系列第二篇

前言
一般来说,RDD包括两个操作算子:
默认情况下,在RDD上执行动作算子时,Spark会重新计算并刷新RDD,但借助RDD的持久化存储(cache和persist)方法可以将RDD缓存在内存当中,这样后续在RDD上执行动作算子时,Spark就不会重新计算和刷新RDD,从而显著提高计算速度。
官方文档:https://spark.apache.org/docs/latest/api/python/reference/pyspark.html
变换算子
| 操作 | 调用形式 | 参数说明 | 作用 | 示例 |
|---|---|---|---|---|
| glom | rdd.glom() | 将RDD中每一个分区中类型为T的元素转换成Array[T],这样每一个分区就只有一个数组元素 | 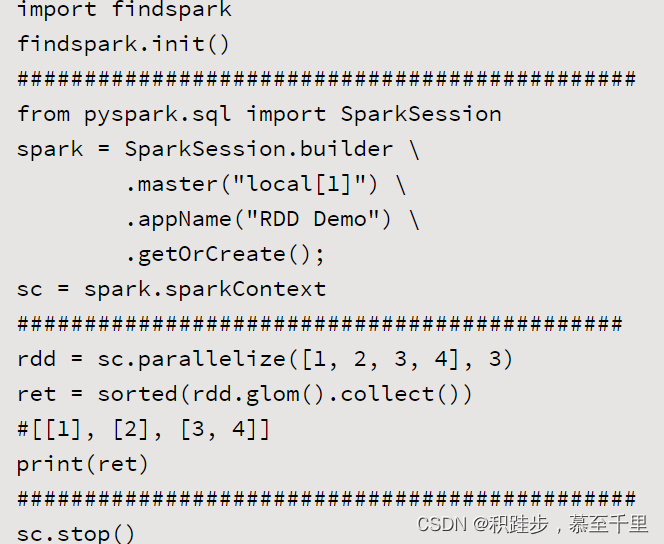 | |
| coalesce | rdd.coalesce(numPartitions,[isShuffle=False]) | numPartitions:重新分区的分区数;isShuffle:是否在重新分区过程中进行混洗操作 | 将RDD进行重新分区 | 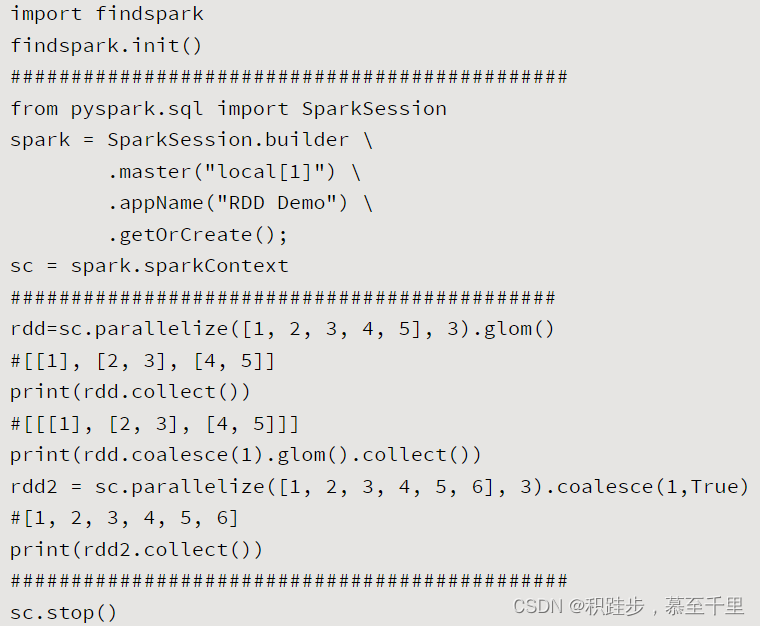 |
| repartition | rdd.repartiton(numParttions) | numPartitions:重新分区的分区数; | coalesce()方法shuffle为true的情况 |  |
| combineByKey | rdd.combineByKey(createCombiner, mergeValue,mergeCombiners,[partitioner], [mapSideCombiner], [serializer]) | createCombiner 将 Value 进行初步转换;mergeValue 在每个分区把上一步转换的结果聚合;mergeCombiners 在所有分区上把每个分区的聚合结果聚合;partitioner 可选, 分区函数;mapSideCombiner 可选, 是否在 Map 端 Combine;serializer 序列化器 | 对数据集按照Key进行聚合 | PySpark之Spark中的CombineByKey |
| distinct | rdd.distinct()duid | 去重,即多个重复元素只保留一个 | ||
| filter | rdd.filter(func) | func:过滤函数 | 根据过滤函数func的逻辑含义对原RDD中的元素进行过滤,并返回一个新的RDD,其由满足过滤函数的True的元素构成 |  |
| flatMap | rdd.flatMap(func) | func:定义的函数名 | 对RDD中每个元素按照func函数定义的处理逻辑进行操作,并将结果扁平化 |  |
| flatMapValues | rdd.flatMapValues(func) | func:定义的函数 | 对RDD元素格式为KV对中的V进行func定义的逻辑处理,Value中每一个元素被输入函数func映射为一系列的值,然后这些值再与原RDD中的Key组成一系列新的KV对,并将结果进行扁平化处理 | 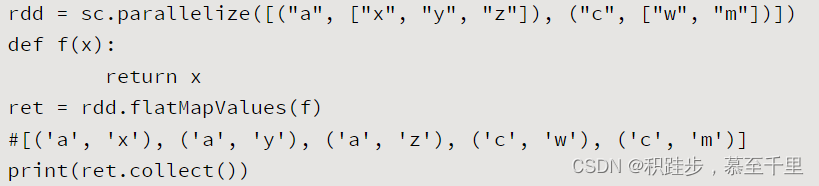 |
| fold | rdd.fold(value,func) | value:设定的初始值 | 对RDD每个元素按照func定义的逻辑进行处理。func包含两个参数a,b,其中a的初始值为value,后续代表累计值,b代表当前元素值。 |  spark的fold函数理解 spark的fold函数理解 |
| foldByKey | rdd.foldByKey(value,func) | value:设定的初始值 | 此操作作用于元素为KV格式的RDD。它的作用是对RDD每个元素按照Key进行func定义的逻辑进行处理。func包含两个参数a,b,其中a的初始值为value,后续代表累计值,而b代表的是当前元素值。 |  |
| foreach | rdd.foreach(func) | 对RDD每个元素按照func定义的逻辑进行处理。 | ||
| foreachPartition | rdd.foreachPartition(func) | 对RDD每个分区中的元素按照func定义的逻辑进行处理 | ||
| map | rdd.map(func,preservesPartitioning=False) | 对RDD每个元素按照func定义的逻辑进行处理,它在统计单词个数等场景下经常使用 |  | |
| mapPartitions | rdd.mapPartitions(func,preservesPartitioning=False) | 对RDD每个分区中的元素按照func定义的逻辑进行处理,并分别返回值 |  | |
| mapValues | rdd.mapValues(func) | 对KV格式的RDD中的每个元素应用函数func,这个过程汇总不会更改键K,同时也保留了原始RDD的分区,即返回新的RDD | 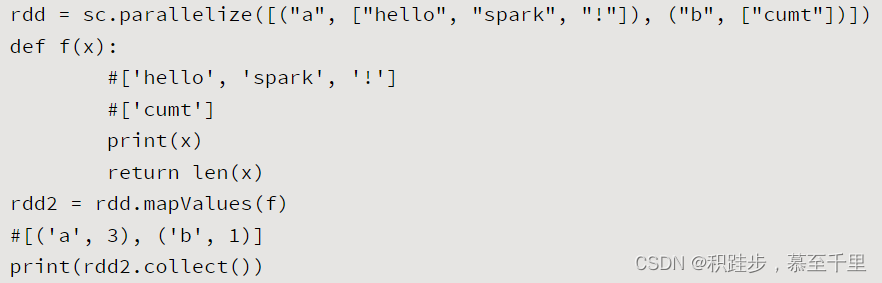 | |
| groupBy | rdd.groupBy(func,numPartitions=None,partitionFunc=<function portable_hash><function portable_hash>) | 它接收一个函数func,这个函数返回的值作为Key,然后通过这个Key来对其中的元素进行分组,并返回一个新的RDD对象(返回的RDD中是KV格式的数据,其中V是一个迭代对象,因此需要遍历进行元素访问。) |  | |
| goupyByKey | rdd.groupByKey(numPartitions=None,partitionFunc=<function portable_hash><function portable_hash>) | 将RDD中每个键的值分组为单个序列,用numPartitions分区对生成的RDD进行哈希分区,并返回一个新的RDD对象 |  | |
| keyBy | rdd.keyBy(func) | 在RDD上应用函数func,其中将原有RDD中的元素作为Key,该Key通过func函数返回的值作为Value创建一个元组,并返回一个新的RDD对象 |  | |
| keys | rdd.keys() | 获取KV格式的RDD中的Key序列,并返回一个新的RDD对象 |  | |
| zip | rdd.zip(oterRdd) | 将第一个RDD中的元素作为Key,第二个RDD对应的元素作为Value,组合成元素格式为元组的新RDD。这两个参与运算的RDD元素个数应该相同。 | 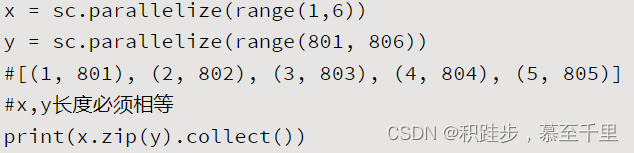 | |
| zipWithIndex | rdd.zipWithIndex() | 是将RDD中的元素作为Key, Key对应的元素索引作为Value,组合成元素格式为元组的新RDD |  | |
| values | rdd.values() | 获取KV格式的RDD中的Value序列,并返回一个新的RDD对象 | ||
| union | rdd.union(oterRDD) | 将第一个RDD中的元素与第二个RDD对应的元素进行合并,返回新RDD |  | |
| takeOrdered | rdd.takeOrdered(num,key=None) | num:获取的元素个数;key:排序依据 | 从RDD中获取排序后的前num个元素构成的RDD,默认按照升序对元素进行排序,但也支持用可选函数进行指定 |  |
| takeSample | rdd.takeSample(withReplacement,num,seed=None) | withReplacement:布尔值,代表元素是否可以多次抽样;num:代表抽样的样本数量;seed:代表随机数生成器的种子 | 从RDD中抽样出固定大小的子数据集合,返回新的RDD |  |
| subtrack | rdd.subtract(otherRDD,numPartitions=None) | numPartitons:可选,用于指定产生的差集RDD的分区数 | 从RDD中排除掉otherRDD中的元素,并返回一个新的RDD |  |
| subtractByKey | rdd.subtractByKey(otherRDD,numPartitions=None) | numPartitons:可选,用于指定产生的差集RDD的分区数 | 从元素为KV格式的RDD中排除掉otherRDD中的元素,只要两个RDD的元素Key一致,则排除,并返回一个新RDD |  |
| sortBy | rdd.sortBy(keyfunc,ascending=True,numPartitions=None) | 根据函数keyfunc来对RDD对象元素进行排序,并返回一个新的RDD |  | |
| sortByKey | rdd.sortByKey(ascending=True, numPartitions=None, keyfunc=<function RDD.<lambda><lambda>>) | keyfunc:可选,不提供则按照RDD中元素的key进行排序 | 针对元素格式为KV的RDD,根据函数keyfunc来对RDD对象元素进行排序,并返回一个新的RDD |  |
| sample | rdd.sample(withReplacement,fraction,seed=None) | withReplacement:布尔值,用于表示在采样过程中是否可以对同一个元素进行多次采样;fraction:数值,在[0,1]之间,指定抽样的比例;seed:随机数生成器的种子 | 对数据按照指定的比例进行抽样(并不精确,例如100个元素的0.2不一定就是20个,可能存在偏差。) |  |
| reduce | rdd.reduce(func) | 以按照函数func的逻辑对RDD中的元素进行运算,以减少元素个数(不能在空RDD上操作,会报ValueError错误) |  | |
| reduceByKey | rdd.reduceByKey(func,numPartitions=None,partitionFunc=<function partable_hash>) | 按照函数func的逻辑对元素格式为KV的RDD中的数据进行运算,以减少元素个数 |  | |
| randomSplit | rdd.randomSplit(weights,seed=None) | weights:随机分割的权重 | 按照权重weights对RDD进行随机分割,并返回多个RDD构成的列表 | 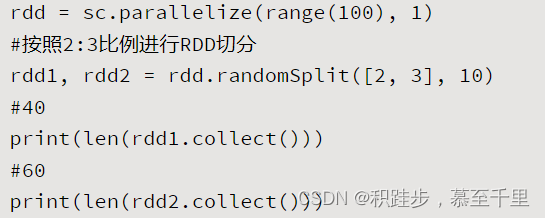 |
| lookup | rdd.lookup(key) | key:指定的查找键值 | 根据key值从RDD中查找到相关的元素,返回RDD中键值的值列表 |  |
| join | rdd.join(otherRDD,numPartitions=None) | 返回一个RDD,其中包含自身和otherRDD匹配键的所有成对元素。每对元素将以(k,(v1,v2))元组返回,其中(k,v1)在自身中,而(k,v2)在另一个otherRDD中 |  | |
| intersection | rdd.intersection(otherRDD) | 返回一个此RDD和另一个otherRDD的交集,在这个过程中,会进行去重操作 |  | |
| fullOuterJoin | rdd.fullOuterJoin(otherRDD,numPartitions=None) | 对于RDD自身中的每个元素(k,v),如果另外一个otherRDD匹配到k,那么生成的RDD元素格式为(k,(v,w));如果另外一个otherRDD匹配不到k,则生成的RDD元素格式为(k,(v,None))。同样地,在otherRDD匹配到k的值,但是在RDD自身没有匹配到值w,则返回None,即生成的RDD元素格式为(k,(None,w))。 |  | |
| leftOuterJoin | rdd.leftOuterJoin(otherRDD,numPartitions=None) | 返回此RDD和另一个otherRDD的左外部连接(left outer join)。对于RDD自身中的每个元素(k,v),如果另外一个otherRDD匹配到k,那么生成的RDD元素格式为(k,(v,w)),如果另外一个otherRDD匹配不到k,则生成的RDD元素格式为(k,(v,None))。 |  | |
| rightOuterJoin | rdd.rightOuterJoin(otherRDD,numPartitions=None) | 返回此RDD和另一个otherRDD的右外部连接(left outer join)。 | ||
| aggregateByKey | rdd.aggregateByKey(zeroValue,seqFunc,combFunc,numPartitions=None,partitionFunc=<function partable_hash>) | zeroValue代表每次按Key分组之后的每个组的初始值。seqFunc函数用来对每个分区内的数据按照key分别进行逻辑计算。combFunc对经过seqFunc处理过的数据按照key分别进行逻辑计算。 | 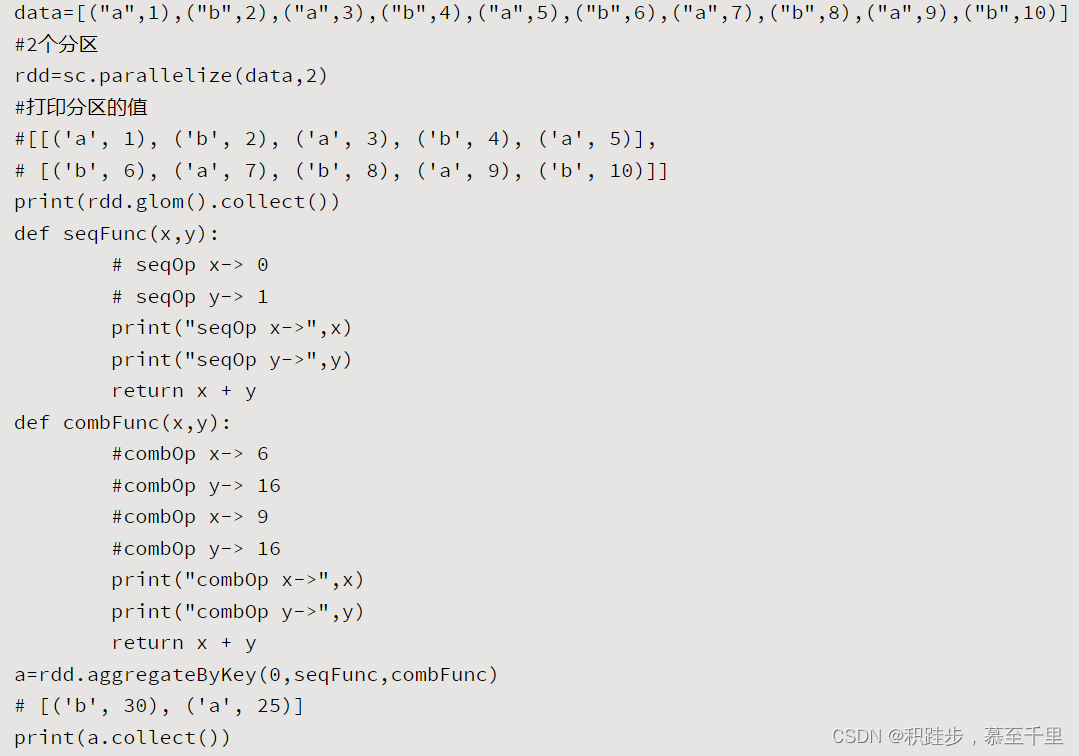 | |
| cartesian | rdd.cartesian(oterRDD) | 返回自身元素和另外一个otherRDD中元素的笛卡尔积 |  |
动作算子
| 操作 | 调用形式 | 参数说明 | 作用 | 示例 |
|---|---|---|---|---|
| first | rdd.first() | 获取到RDD中的一个元素 |  | |
| max | rdd.max() | 获取到RDD中最大的一个元素 |  | |
| min | rdd.min() | 获取到RDD中最小的一个元素 | ||
| sum | rdd.sum() | 获取到RDD中元素的和 |  | |
| take | rdd.take(n) | n:代表获取的元素个数 | 获取到RDD中指定的前n个元素 |  |
| top | rdd.top(n) | n:代表获取的元素个数 | 获取到RDD中排序后的前n个元素 |  |
| count | rdd.count() | 获取到RDD中元素的个数 |  | |
| collect | rdd.collect() | 将RDD类型的数据转化为数组,同时会从集群中拉取数据到driver端 |  | |
| collectAsMap | rdd.collectAsMap() | 与collect操作类似,但适用于键值RDD并将它们转换为Map映射以保留其键值结构 |  | |
| countByKey | rdd.countByKey() | 统计RDD[K,V]中每个K的数量,字典形式返回各键的统计数量情况 | 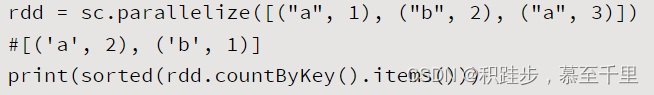 | |
| countByValue | rdd.countByValue() | 统计RDD中各个Value出现的次数,并返回一个字典。字典的K为元素的值,而V是出现的次数 |  | |
| stats | rdd.stats() | 给出RDD数据的统计信息,包括计数、均值、方差、最大值和最小值,返回的是一个StatCounter对象 |  | |
| aggregate | rdd.aggregate(zeroValue,seqOp,combOp) | zeroValue:初始值,形式是(x,y);seqOp函数:是对每个分区上的数据信息操作;combOp函数对每个分区的计算结果再进行合并操作 | 使用给定的seqOp函数和给定的零值zeroValue来聚合每个分区上的元素,然后再用combOp函数和给定的零值zeroValue汇总所有分区的结果。 |  |
| cache | rdd.cache() | 在RDD对象上进行缓存操作,后续的RDD操作会直接从内存中加载数据进行计算。使用默认存储级别(MEMORY_ONLY)保留该RDD,防止多次进行创建,从而提高效率。 |  | |
| persist | rdd.persist(storageLevel) | storageLevel:指定缓存的存储级别 | 在RDD对象上按照指定的存储级别进行缓存操作 | |
| saveAsTextFile | rdd.saveAsTextFile(path,compressionCodecClass=None) | path:代码保存的文件路径;compressionCodecClass:用于压缩,默认为“org.apache.hadoop.io.compress.GzipCodec” | 保存RDD对象为一个文件,其中元素以字符串的形式体现。 |  |
参考文档:
- https://spark.apache.org/docs/latest/api/python/reference/pyspark.html
- 《Python大数据处理库PySpark实战》
博主写博文就是方便对自己所学所做的事做一备份记录或回顾总结。欢迎留言,沟通学习。
刚开始接触,请多指教,欢迎留言交流!

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/398599
推荐阅读
相关标签

