
JDK从8升级到11,使用 G1 GC,HBase性能下降20%。JDK 到底干了什么
赞
踩
JDK 8中 GC 日志片段:
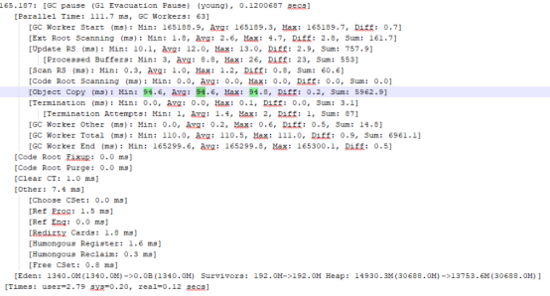
我们对整个日志做了统计,有以下发现:
并发标记时机不同,混合回收的时机也不同;
单次 GC 中对象复制的耗时不同,JDK 11 明显更长;
总体 GC 次数 JDK 11 得更多,包括了并发标记的停顿次数;
总体 GC 的耗时 JDK 11 更多。

针对 Young GC 的性能劣化,我们重点关注测试了和 Young GC 相关的参数,例如:调整
UseDynamicNumberOfGCThreads、G1UseAdaptiveIHOP 、GCTimeRatio 均没有效果。
下面我们尝试使用不同的工具来进一步定位到底哪里出了问题。
3.3JFR分析-确认日志分析结果
=================
毕昇 JDK 11和毕昇 JDK 8 都引入了 JFR,JFR 作为 JVM 中问题定位的新贵,我们也在该案例进行了尝试,关于JFR的原理和使用,参考本系列的技术文章:Java Flight Recorder - 事件机制详解。
3.3.1JDK 11总体信息
===============
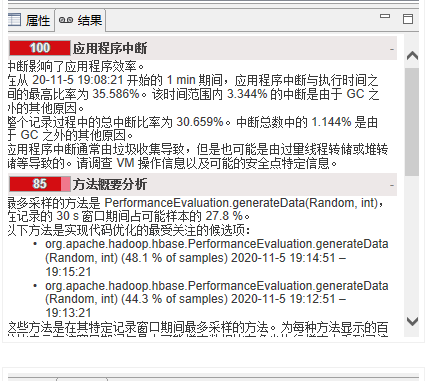
JDK 8 中通过 JFR 收集信息。
3.3.2JDK 8总体信息
==============
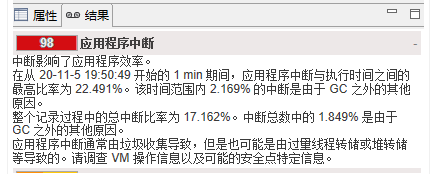
JFR 的结论和我们前面分析的结论一致,JDK 11 中中断比例明显高于 JDK 8。
3.3.3JDK 11中垃圾回收发生的情况
=====================
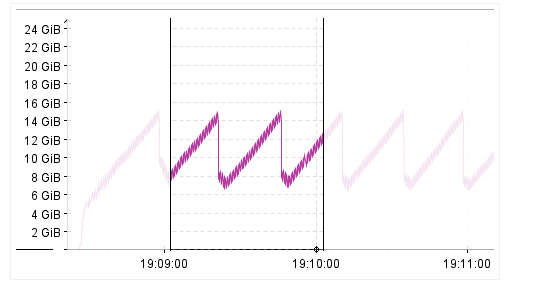
3.3.4JDK 8中垃圾回收发生的情况
====================
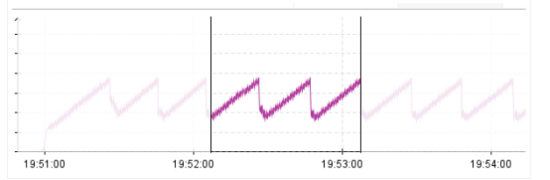
从图中可以看到在 JDK 11 中应用消耗内存的速度更快(曲线速率更为陡峭),根据垃圾回收的原理,内存的消耗和分配相关。
3.3.5JDK 11中VM操作
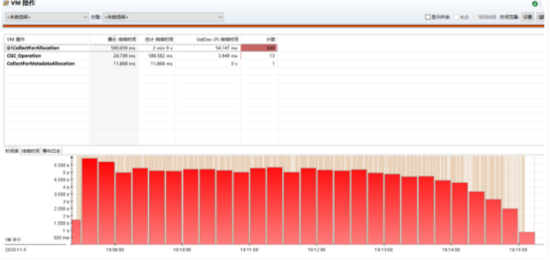
================
3.3.6JDK 8中VM操作
===============
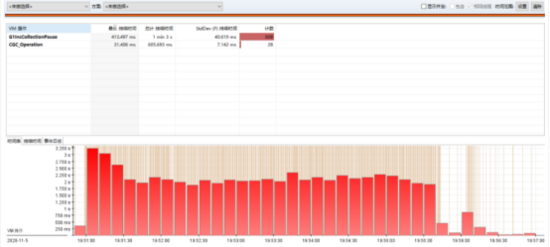
通过 JFR 整体的分析,得到的结论和我们前面的一致,确定了 Young GC 可能存在问题,但是没有更多的信息。
3.4火焰图-发现热点
===========
为了进一步的追踪 Young GC 里面到底发生了什么导致对象赋值更为耗时,我们使用Async-perf 进行了热点采集。关于火焰图的使用参考本系列的技术文章:使用 perf 解决 JDK8 小版本升级后性能下降的问题
3.4.1JDK 11的火焰图
===============
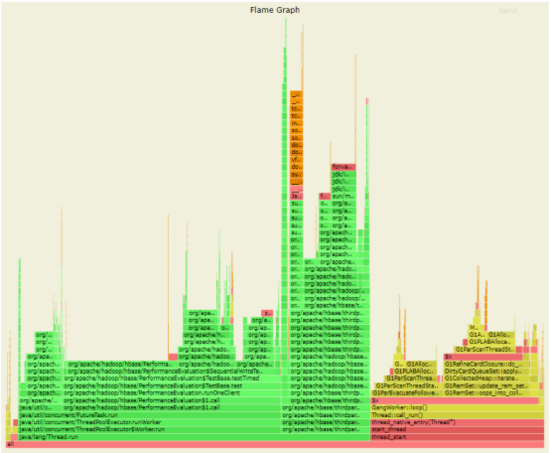
3.4.2JDK 11 GC部分火焰图
===================
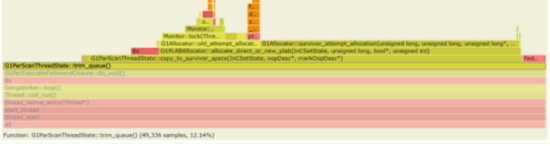
3.4.3JDK 8的火焰图
==============
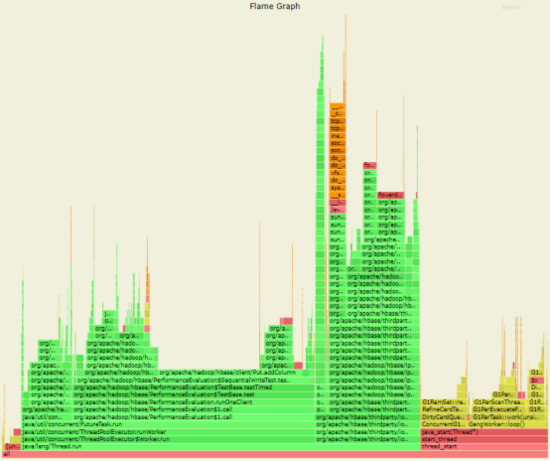
3.4.4JDK 8 GC部分火焰图
==================

通过分析火焰图,并比较 JDK 8 和 JDK 11 的差异,可以得到:
在 JDK 11 中,耗时主要在:
1)G1ParEvacuateFollowersClosure::do_void()
2)G1RemSet::scan_rem_set
在 JDK 8 中,耗时主要在:
1)G1ParEvacuateFollowersClosure::do_void()
下一步,我们对 JDK 11 里面新出现的 scan_rem_set() 进行更进一步分析,发现该函数仅仅和引用集相关,通过修改 RSet 相关参数(修改 G1ConcRefinementGreenZone ),将 RSet 的处理尽可能地从Young GC的操作中移除。火焰图中参数不再成为热点,但是 JDK 11 仍然性能下降。
比较 JDK 8 和 JDK 11 中
G1ParEvacuateFollowersClosure::do_void() 中的不同,除了数组处理外其他的基本没有变化,我们将 JDK 11 此处的代码修改和 JDK 8 完全一样,但是性能仍然下降。
结论:虽然
G1ParEvacuateFollowersClosure::do_void() 是性能下降的触发点,但是此处并不是问题的根因,应该是其他的原因造成了该函数调用次数增加或者耗时增加。
3.5逐个版本验证-最终确定问题
================
我们分析了所有可能的情况,仍然无法快速找到问题的根源,只能使用最笨的办法,逐个版本来验证从哪个版本开始性能下降。
在大量的验证中,对于 JDK 9、JDK 10,以及小版本等都重新做了构建(关于 JDK 的构建可以参考官网),我们发现 JDK 9-B74 和 JDK 9-B73 有一个明显的区别。为此我们分析了 JDK 9-B73 输入的代码。发现该代码和 PLAB 的设置相关,为此梳理了所有 PLAB 相关的变动:
B66 版本为了解决 PLAB size 获取不对的问题(根据 GC 线程数量动态调整,但是开启
UseDynamicNumberOfGCThreads 后该值有问题,默认是关闭)修复了 bug。具体见 jira:Determining the desired PLAB size adjusts to the the number of threads at the wrong place
B74 发现有问题(desired_plab_sz 可能会有相除截断问题和没有对齐的问题),重新修改,具体见 8079555: REDO - Determining the desired PLAB size adjusts to the the number of threads at the wrong place
B115 中发现 B74 的修改,动态调整 PLAB 大小后,会导致很多情况 PLAB 过小(大概就是不走 PLAB,走了直接分配),频繁的话会导致性能大幅下降,又做了修复 Net PLAB size is clipped to max PLAB size as a whole, not on a per thread basis
重新修改了代码,打印 PLAB 的大小。对比后发现 desired_plab_sz 大小,在性能正常的版本中该值为 1024 或者 4096(分别是 YoungPLAB 和 OLDPLAB),在性能下降的版本中该值为 258。由此确认 desired_plab_sz 不正确的计算导致了性能下降。
3.6PLAB 为什么会引起性能下降?
===================
PLAB 是 GC 工作线程在并行复制内存时使用的缓存,用于减少多个并行线程在内存分配时的锁竞争。PLAB 的大小直接影响 GC 工作线程的效率。
在 GC 引入动态线程调整的功能时,将原来 PLABSize 的大小作为多个线程的总体 PLAB 的大小,将 PLAB 重新计算,如下面代码片段:
其中 desired_plab_sz 主要来自 YoungPLABSize 和 OldPLABSIze 的设置。所以这样的代码修改改变了 YoungPLABSize、OldPLABSize 参数的语义。
另外,在本例中,通过参数显式地禁止了 ResizePLAB 是触发该问题的必要条件,当打开 ResizePLAB 后,PLAB 会根据 GC 工作线程晋升对象的大小和速率来逐步调整 PLAB 的大小。
注意,众多资料说明:禁止 ResziePLAB 是为了防止 GC 工作线程的同步,这个说法是不正确的,PLAB 的调整耗时非常的小。PLAB 是 JVM 根据 GC 工作线程使用内存的情况,根据数学模型来调整大小,由于模型的误差,可能导致 PLAB 的大小调整不一定有人工调参效果好。如果你没有对 YoungPLABSize、OldPLABSize 进行调优,并不建议禁止 ResizePLAB。在 HBase 测试中,当打开 ResizePLAB 后 JDK 8 和 JDK 11 性能基本相同,也从侧面说明了该参数的使用情况。
3.7解决方法&修复方法
============
由于该问题是 JDK 9 引入,在 JDK 9, JDK 10, JDK 11, JDK 12, JDK 13, JDK 14, JDK 15, JDK 16 都会存在性能下降的问题。
我们对该问题进行了修正,并提交到社区,具体见Jira:
https://bugs.openjdk.java.net/browse/JDK-8257145;代码见:https://github.com/openjdk/jdk/pull/1474;该问题在JDK 17中被修复。
同时该问题在毕昇 JDK 所有版本中第一时间得到解决。
当然对于短时间内无法切换 JDK 的同学,遇到这个问题,该如何解决?难道要等到 JDK 17?一个临时的方法是显式地设置 YoungPLABSize 和 OldPLABSize 的值。YoungPLABSize 设置为 YoungPLABSize* ParallelGCThreads,其中 ParallelGCThreads 为 GC 并行线程数。例如 YoungPLABSize 原来为 1024,ParallelGCThreads 为 8,在 JDK 9~16,将 YoungPLABSize 设置为 8192 即可。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
看完美团、字节、腾讯这三家的面试问题,是不是感觉问的特别多,可能咱们又得开启面试造火箭、工作拧螺丝的模式去准备下一次的面试了。
开篇有提及我可是足足背下了1000道题目,多少还是有点用的呢,我看了下,上面这些问题大部分都能从我背的题里找到的,所以今天给大家分享一下互联网工程师必备的面试1000题。
注意不论是我说的互联网面试1000题,还是后面提及的算法与数据结构、设计模式以及更多的Java学习笔记等,皆可分享给各位朋友

互联网工程师必备的面试1000题
而且从上面三家来看,算法与数据结构是必备不可少的呀,因此我建议大家可以去刷刷这本左程云大佬著作的《程序员代码面试指南 IT名企算法与数据结构题目最优解》,里面近200道真实出现过的经典代码面试题。

《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!
,皆可分享给各位朋友
[外链图片转存中…(img-Du3oDWsj-1712036411989)]
互联网工程师必备的面试1000题
而且从上面三家来看,算法与数据结构是必备不可少的呀,因此我建议大家可以去刷刷这本左程云大佬著作的《程序员代码面试指南 IT名企算法与数据结构题目最优解》,里面近200道真实出现过的经典代码面试题。
[外链图片转存中…(img-KeqA50Gg-1712036411989)]
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!

