- 1花了三个月从华为OD外包转正了~_华为外包转正容易吗,2024年最新HarmonyOS鸿蒙架构面试
- 2Navicat 16破解-无限试用_navicat 16 for mysql无限期试用
- 3LeetCode189. 轮转数组(C++数组翻转算法)_轮转数组 翻转数组
- 4Spring从入门到精通(一)
- 5计算机毕业设计java党员之家服务系统小程序springbootvue毕设
- 6微信小程序之获取表单数据_微信小程序表单数据收集
- 7“Kafka”面试题 (建议收藏)
- 8用C++封装常用的加密解密算法类_c++国密加解密文件算法
- 9蓝桥杯2024年第十五届省赛真题-握手问题
- 10Centos7部署全分布式Hadoop2.6_192.168.126.11:9870
Ubuntu20.04下搭建Hadoop伪分布式集群_unbuntu的全部启动和停止 hdfs和yarn
赞
踩
Ubuntu虚拟机的安装
关闭防火墙
为了减少搭建集群的复杂性,关闭防火墙如果对防火墙很了解可以可以不用关闭开放相应端口即可。借助ufw软件包使操作更方便。
# 安装防火墙工具
sudo apt-get install ufw
# 开启
sudo ufw enable
sudo ufw default deny # 开启了防火墙并随系统启动同时关闭所有外部对本机的访问(本机访问外部正常)
# 关闭
sudo ufw disable
# 查看状态
sudo ufw status
# 开放端口
sudo ufw allow 80 允许外部访问80端口
sudo ufw delete allow 80 禁止外部访问80 端口
sudo ufw allow from 192.168.1.1 允许此IP访问所有的本机端口
sudo ufw deny smtp 禁止外部访问smtp服务
sudo ufw delete allow smtp 删除上面建立的某条规则
sudo ufw deny proto tcp from 10.0.0.0/8 to 192.168.0.1 port 22 要拒绝所有的TCP流量从10.0.0.0/8 到192.168.0.1地址的22端口
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
使防火墙处于关闭状态即可:

安装SSH
https://blog.csdn.net/xwh3165037789/article/details/123468111
安装jdk
https://blog.csdn.net/xwh3165037789/article/details/123468111
设置静态ip
https://blog.csdn.net/xwh3165037789/article/details/126306878
配置主机名
https://blog.csdn.net/xwh3165037789/article/details/126306878
映射ip地址与主机名
将ip地址与主机名映射的作用是使用主机名即可完成集群间的切换。
vi /etc/hosts
- 1
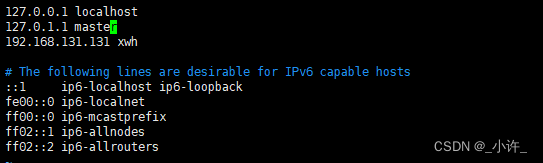
添加配置的静态ip和主机名即可。
ssh免密登录
ssh简介


完成主机ip映射之后使用密码实现主机间的切换:ssh root@[主机映射名称]

输入yes后会让你输入密码:

成功切换过去

此时是需要密码的,每次输入密码是很不方便的,也不能实现集群的自动化,接下来需要配置ssh免密登录。
在root用户下输入ssh-keygen -t rsa 三次回车
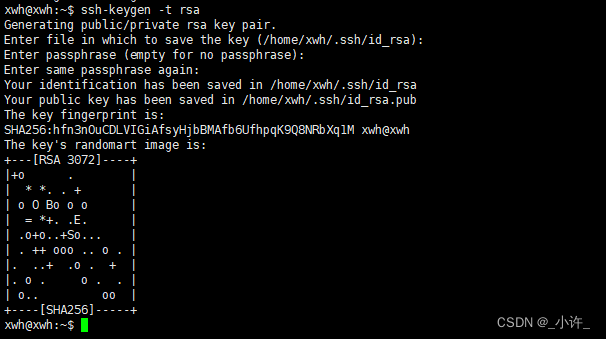
切换到秘钥目录cd ~/.ssh
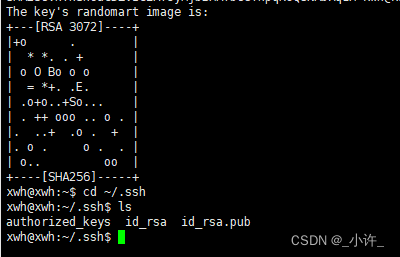
将公钥id_rsa.pub复制到本机上cp id_rsa.pub authorized_keys

ssh连接远程主机的命令是ssh user@hostname==ssh [用户名][主机名]==根据上面主机映射的关系
共有三台主机和一个用户,用户是xwh,主机分别是master,xwh,localhost。就可以使用ssh user@hostname,经过免密登录的配置,现在切换已经不需要密码了。
完全分布式和伪分布式的主要却别也在此。
user@hostname
- 1
Hadoop的下载与安装
创建hadoop文件夹并上传hadoop文件,并解压到当前目录:
tar -zxvf hadoop-2.10.1
- 1

因为下载的源码,要全局使用需要配置环境变量,环境变量的配置文件在/etc/profile
sudo vi /etc/profile
- 1

export HADOOP_HOME=/home/xwh/hadoop/hadoop-2.10.1
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH:$HOME/bin
- 1
- 2
- 3
- 4
如果是自己配置的jdk则java_home换为自己的路径即可,如果是安装的openjdk则其位置在:/usr/lib/jvm目录下:

配置完成后重启环境变量source /etc/profile,在使用hadoop命令检验是否配置成功,出现如下图所示即配置成功:
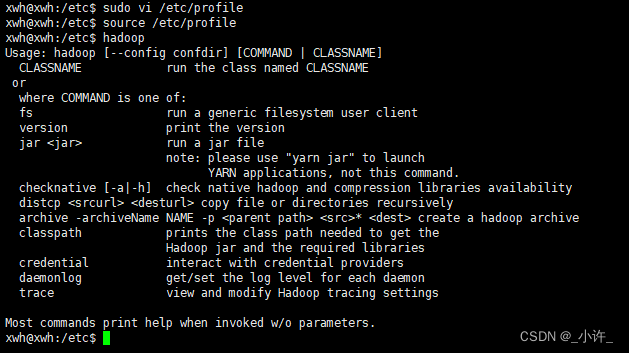
hadoop配置
hadoop-env.sh文件的配置:
配置文件所在目录,在解压的hadoop目录下:hadoop/hadoop-2.10.1/etc/hadoop
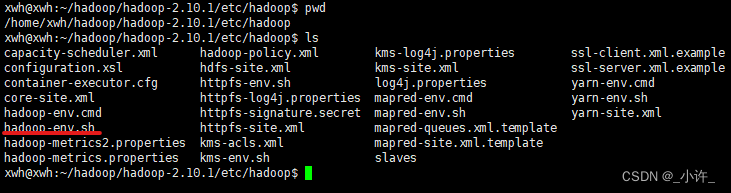
进入该目录如图所示:
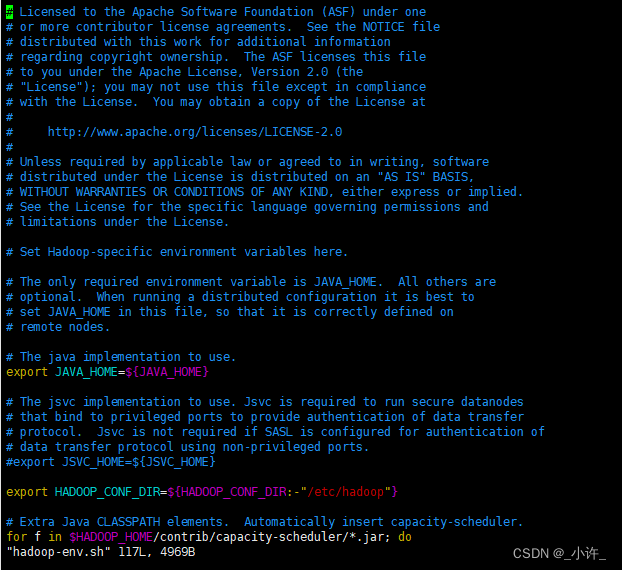
将jdk路径配置在图上的JAVA_HOME处,只配置要jdk安装目录即可,不用到bin目录:

core-site.xml文件配置
配置如下:
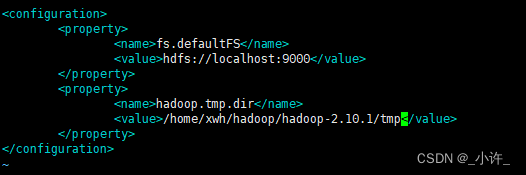
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/xwh/hadoop/hadoop-2.10.1/tmp</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
hdfs-site.xml文件配置
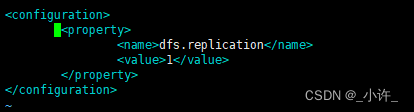
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
- 1
- 2
- 3
- 4
mapred-site.xml文件配置
目录下是没有该文件的只有一个模板,将mapred-site.xml.template复制一份改名即可。

复制命令cp mapred-site.xml.template mapred-site.xml
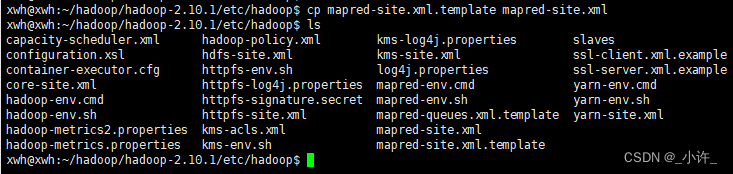
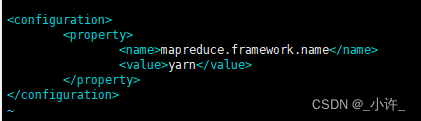
该步骤可省略
yarn-site.xml文件配置
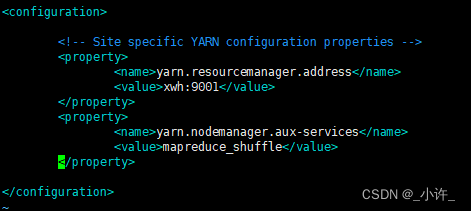
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>bigdata:8032</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
上面的配置根据自己实际修改
格式化分布式文件系统HDFS
该文件系统岁hadoop自动下载的的,格式化命令:hdfs namenode -format。只能格式化一次,若第一未成功需要删除上面配置的tmp目录重新格式化。
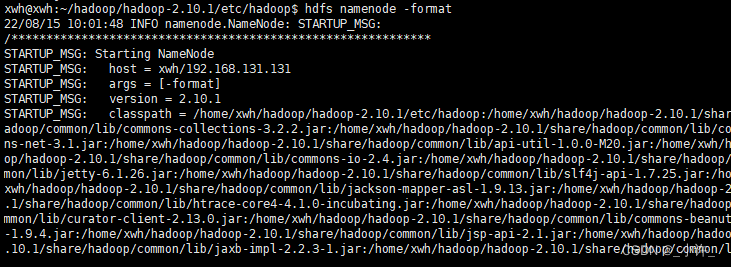
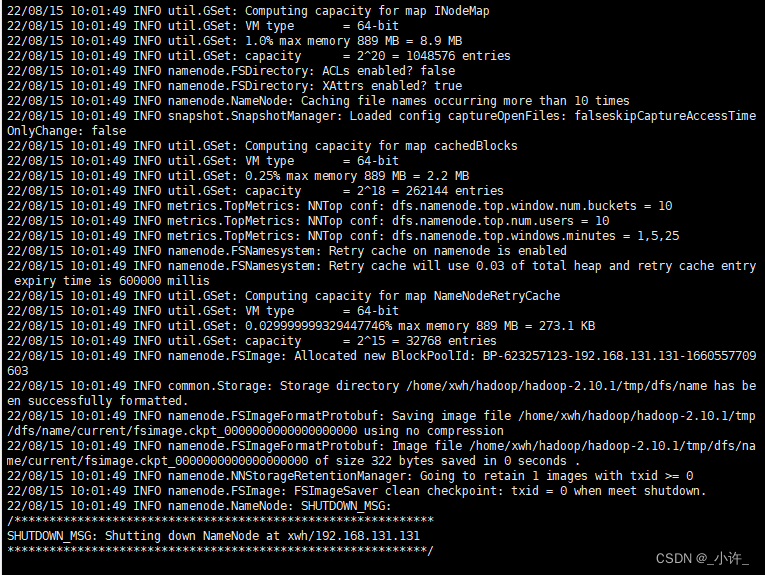
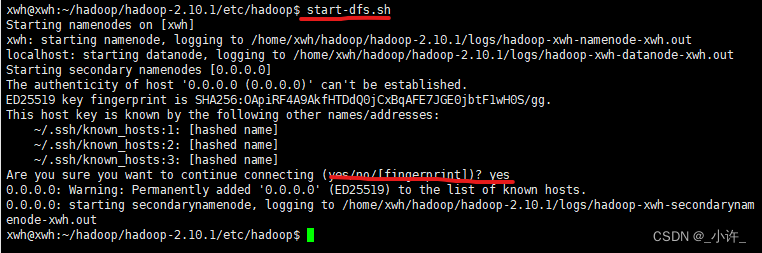
**启动集群start-dfs.sh**中途要输入一个yes:
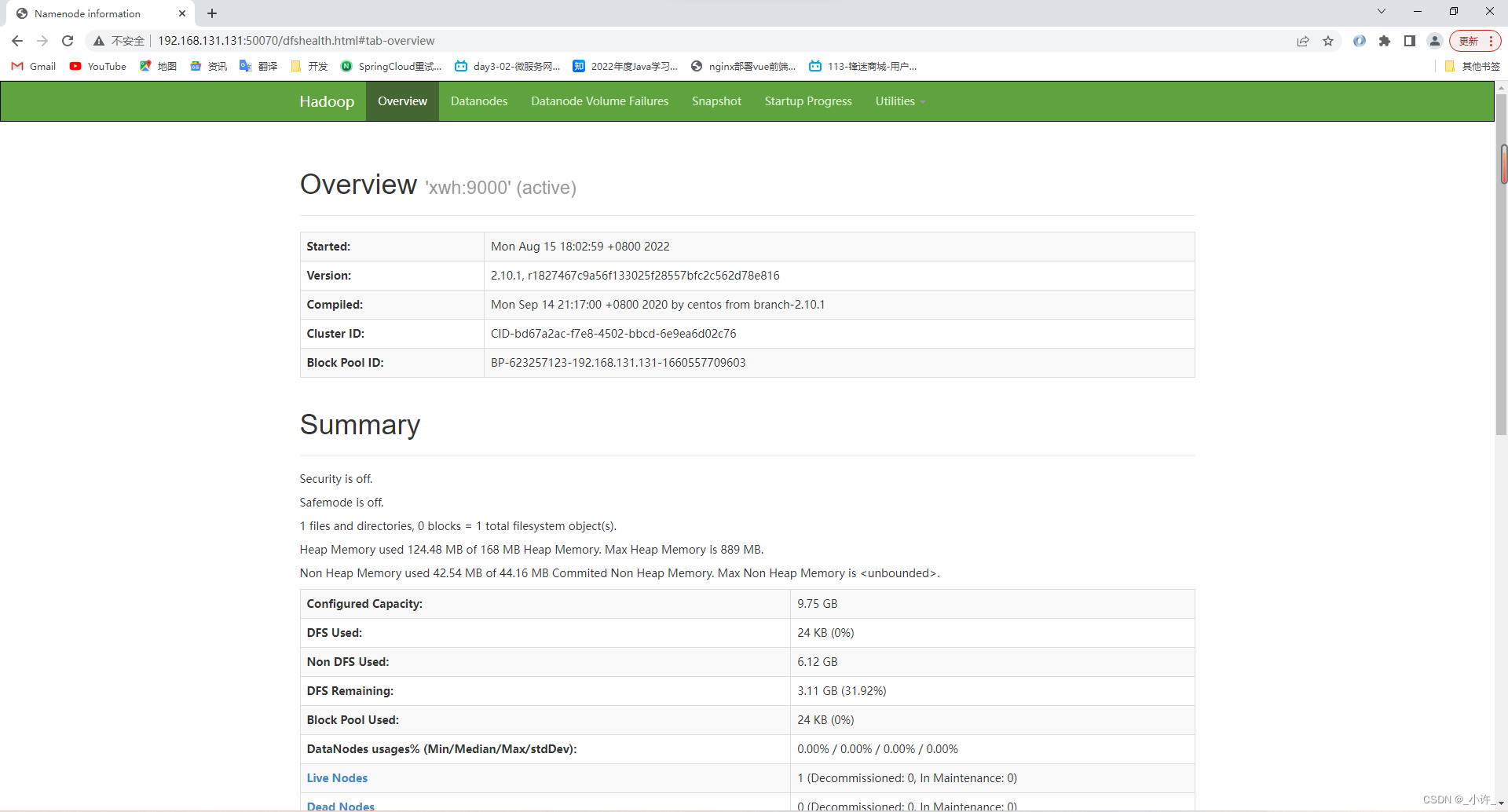
namenode节点后台管理地址ip+端口号[50070/50090]
http://192.168.131.131:50070/
http://192.168.131.131:50090/
由于小编安装的openjsk没有jps命令,需要另外安装工具包sudo apt-get install java-1.7.0-openjdk-devel -y
如果出现错误就更新jdk版本sudo apt-get install openjdk-8-jdk就可以使用jstack,jps等调试命令了。
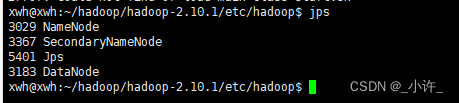
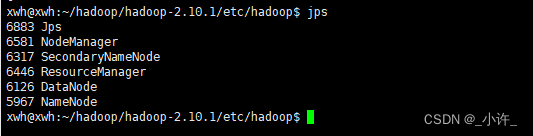
存在namenode和dataname说明配置成功。
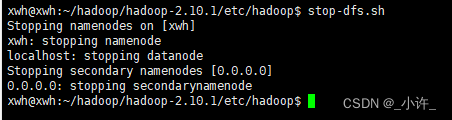
使用stop-dfs.sh停止集群:
yarn作为集群的管理者,启动yarn的命令为:start-yarn.sh:

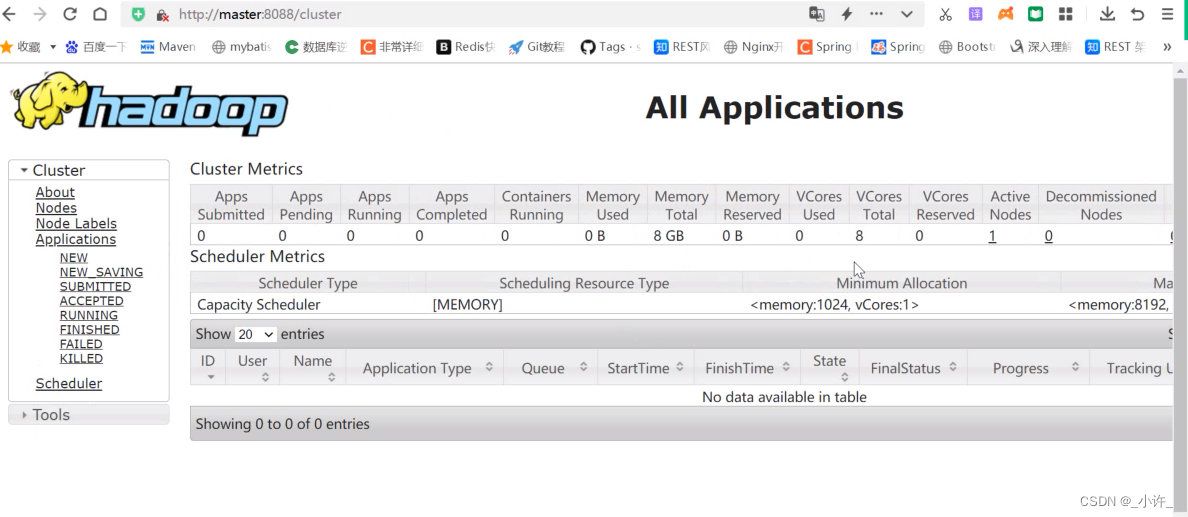
也可以输入ip+[yarn端口号]进入yarn管理中心,这是在之前yarn-site.xml配置的
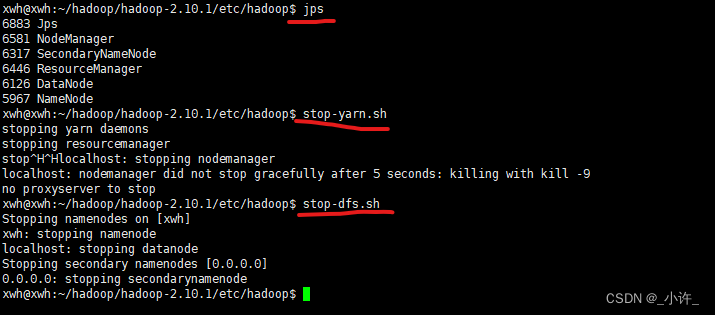
当全部启动是使用jps调试命令:
需要注意的是在关闭集群是要依次关闭yarn,hadoop。
stop-yarn.sh,stop-dfs.sh