
- 1计算机网络协议详解(一)
- 2多终端云同步文献管理:Zotero+TeraCloud(Windows+Android)_zotero win
- 3用XML文件对控件的设置-shape形状的使用与自定义图形_xml如何调节布局圆角
- 4青龙面板之【追书神器】——5.29_追书神器如何抓cookie
- 5安全功能,加密相关,密码杂凑函数(aes,rsa,ECC , sha1,sha256,md5,HMAC)_sha1 sha256 hmac ccm aes
- 6ideal的maven工程jar冲突处理
- 7oracle sql 一对多_oracle 一对多查出关联的数量
- 8MathType2024永久激活码(包括免费注册机)_mathtype最新注册码下载
- 9数字IC实战后端项目| 必须掌握的28个SoC低功耗项目经验!_数字ic后端项目
- 10C# webapi接口调用实例_webapi接口开发实例
chatGPT解读(chatGPT前世今生之今生)_chatgpt 应用指南 gpt 的前世今生的问题
赞
踩
chatGPT解读
我们带着几个问题,一起去看看chatGPT吧。
上周讲了GPT-1,GPT-2, GPT-3的整体演化过程。那么,既然chatGPT是在GPT3上生成出来的,为什么不叫GPT-3.5或者GPT-4呢?
因为chatGPT是在GPT-3上做拓展,不是提升网络规格,也不是数据上拓展,而是去真正解决一些问题。解决什么问题呢?
问题1:nlp带有语言偏见,早在2022年,斯坦福就指出NLP偏见很大。比如通过大量新闻,一说到黑人,nlp就大概率认为是罪犯,白人呢,是好人。
问题2:所问非所答,可能会自作聪明,生成一些没有的东西。
问题3:看到GPT从1到3,参数量达到了1750B,成指数级增长,难道模型越大,参数越大,就越好吗?实际上是训练集和验证集而言是这样的。
但是,如果你问一个问题,回答越多越好吗?那可能就不是啦,答案只需要好理解,接近就可以,所以说参数量可能不是越大越好。
对于GPT-3来说,他太大了,能胡说八道,比如你跟他对诗,就好像你跟唐朝的李白对诗,那你肯定干不过他啊。而对于GPT-3的训练更是可望不可即,它的batch达到3.2M。这个数据,国内现有的集群,估计都玩不了。
chatGPT前景如何呢,会不会导致大部分人失业呢?对于大模型的发展,是希望能解决实际的问题,而现在的chatGPT只能说只是个取悦人类的工具,离落地尚有一段距离。
你知道为什么chatGPT为什么来的那么猝不及防吗?
以下结果也只是猜测:
原因1.openai吃过亏,之前搞饥饿营销,结果把自己饿死了。
原因2.猜测openai原来没想这个时候公布,但是2022年每天就产生一个大模型,为了抢占先机,后面再出来的,哪怕再厉害,也会被认为是模型openai的;
原因3.微软肯定想着怎么占领市场,怎么取代谷歌,取代百度。取代搜索引擎;
回到问题3.模型越大,参数越大,结果可能越精确,越固定,但是那不是我们要的,我们想要模型学人类说话,也就是让chatGPT更像人,更符合人。所以呢,chatGPT加入了有监督学习,GPT-3属于无监督学习,chatGPT就需要有监督学习了。所以呢,chatGPT是在无监督的基础上再去走这个有监督的数据,让模型能够说人话办人事。
在CV领域呢,就是比算法,谁算法强,谁效果好。
nlp就是比数据,谁数据更大,模型更大。也就是预训练模型就更好。
举个例子:
假如我问一个问题:9楼和10楼跳楼哪个比较合适?因为有9和10进行提示,相当于告诉模型这是个分类任务。GPT-3就会回答,10楼,因为更容易摔死。
但是,这样的回答符合人性吗?
现在的chatGPT就会很人性。甚至跟你谈到心理学。鼓励你好好生活。
那么,这个回答是无监督任务能学到的内容吗?肯定不是,所以现在的chatGPT就需要有监督,尤其针对敏感性话题,更要监督。
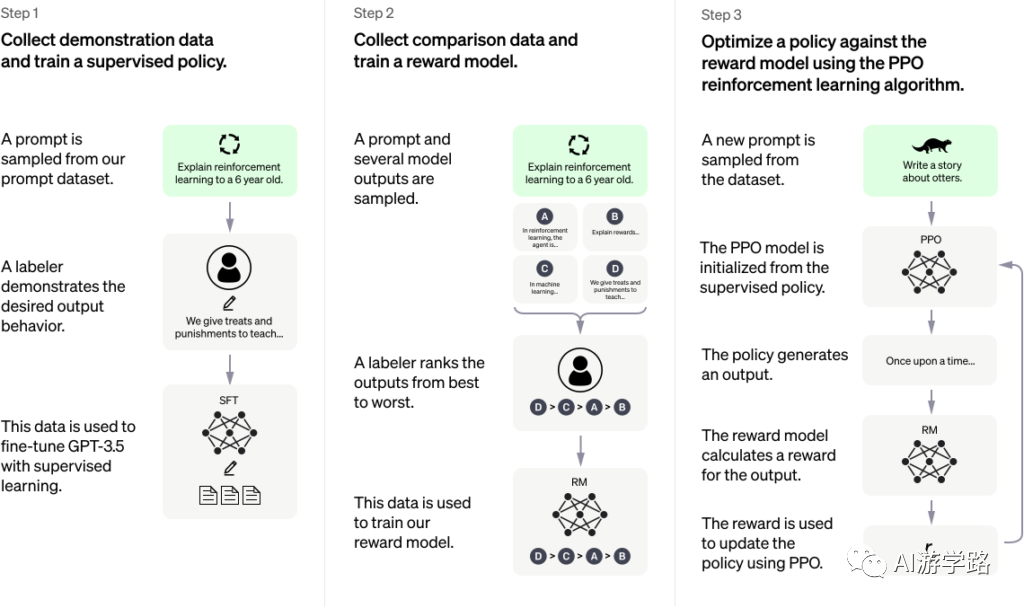
chatGPT第一点,加入有监督学习;
第二点,加入奖励机制。
奖励机制,也就是强化学习PPO。当年阿尔法狗打败了李世石,就是使用类似的机制,没走对一步棋,就会获得奖励。
具体怎么奖励呢,比如输出一句话,到底奖励多少?这就需要一个奖励模型。这也是chatGPT的强大之处,通过强化学习,能让你举一反三,并不是一对一输出的一个结论。

