
- 1java使用方法重载求最大值_java的方法/调用/重载/递归
- 2003-PyCharm将Python文件导入到其他Project项目中
- 3C++ 滑动窗口最大值_滑动窗口的最大值c++
- 4【Python笔记-FastAPI】后台任务+WebSocket监控进度_fastapi websocketendpoint
- 5Qt/C++通用跨平台Onvif工具/支持海康大华宇视华为天地伟业等/云台控制/预置位管理/工程调试利器_qt控制摄像头云台onvif
- 6深度学习预训练与MMPretrain_win10 mmpretrain
- 72023年全国职业院校技能大赛应用软件系统开发赛项(高职组)赛题第6套_职业技能大赛软件开发
- 8Oracle中实现SQL中的newid() 生成GUID_oracle数据库如何使用newid
- 9解决方法:OpenCV: FFMPEG: tag 0x00000898/'???' is not found (format 'avi / AVI (Audio Video Interleaved)
- 10设计模式七大原则之迪米特法则_迪米特法则实例
基于YOLOv8的知识蒸馏_yolov8 蒸馏
赞
踩
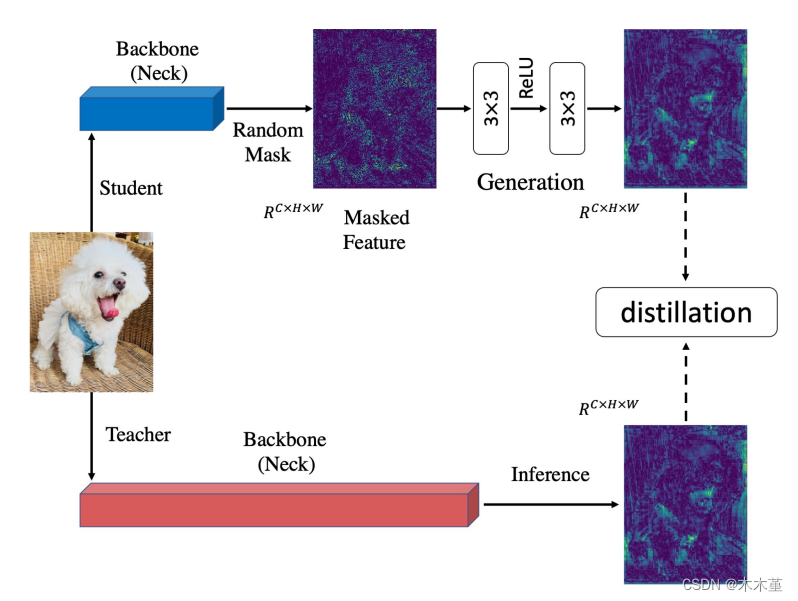
09.14 在YOLOv8下的知识蒸馏,目前实验进展,已测试基于特征图的CWD和MGD,对自建数据集均有提点。其中,学生模型YOLOv8n,教师模型YOLOv8s,CWD有效提点1.01%,MGD提点0.34%。同时,支持对自己的改进模型进行知识蒸馏。
09.16 框架大改,加入Logits蒸馏。支持Logits蒸馏和特征蒸馏同时或者分别进行。
目前支持如下方法:
Logits蒸馏:最新的BCKD(Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detection)https://arxiv.org/pdf/2308.14286.pdf,后续将加入其它Logits蒸馏方法。
特征蒸馏:CWD(Channel-wise Knowledge Distillation for Dense Prediction)https://arxiv.org/pdf/2011.13256.pdf;MGD(Masked Generative Distillation)https://arxiv.org/abs/2205.01529;FGD(Focal and Global Knowledge Distillation for Detectors)https://arxiv.org/abs/2111.11837;FSP(A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning)https://openaccess.thecvf.com/content_cvpr_2017/papers/Yim_A_Gift_From_CVPR_2017_paper.pdf
。后续将加入其它特征蒸馏方法。
09.17 BCKD实验结果,自制数据集上提点1.63%,优于CWD,并且两者可以同时训练。
09.18 加入调试成功的各类蒸馏方法。
目前支持如下方法:
Logits蒸馏:最新的BCKD(Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detection)https://arxiv.org/pdf/2308.14286.pdf;CrossKD(Cross-Head Knowledge Distillation for Dense Object Detection)https://arxiv.org/abs/2306.11369;NKD(From Knowledge Distillation to Self-Knowledge Distillation: A Unified Approach with Normalized Loss and Customized Soft Labels)https://arxiv.org/abs/2303.13005;DKD(Decoupled Knowledge Distillation) https://arxiv.org/pdf/2203.08679.pdf; LD(Localization Distillation for Dense Object Detection) https://arxiv.org/abs/2102.12252;WSLD(Rethinking the Soft Label of Knowledge Extraction: A Bias-Balance Perspective) https://arxiv.org/pdf/2102.00650.pdf;Distilling the Knowledge in a Neural Network https://arxiv.org/pdf/1503.02531.pd3f。
特征蒸馏:CWD(Channel-wise Knowledge Distillation for Dense Prediction)https://arxiv.org/pdf/2011.13256.pdf;MGD(Masked Generative Distillation)https://arxiv.org/abs/2205.01529;FGD(Focal and Global Knowledge Distillation for Detectors)https://arxiv.org/abs/2111.11837;FSP(A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning)https://openaccess.thecvf.com/content_cvpr_2017/papers/Yim_A_Gift_From_CVPR_2017_paper.pdf
;PKD(General Distillation Framework for Object Detectors via Pearson Correlation Coefficient) https://arxiv.org/abs/2207.02039。
09.20 单独使用LD在回归分支的实验结果,目前表现最好,提点1.69%,比加了分类分支的BCKD要好。原因分析:可能是分类分支的KD影响了回归分支。
需要的联系,代码复现不易。

