
- 1斯坦福NLU笔记之情感分析_斯坦福情绪树
- 2计网习题——第三章_在连接的整个过程中,tcp的rwnd的长度决不会变化
- 3.net操作SQLite数据库_.net获取sqlite数据库视图代码
- 4实时可编辑3D重建!鼠标拖拽就能控制,港大VAST浙大联合出品
- 52023最新SRC漏洞挖掘快速上手攻略!_漏洞盒子影响参数填什么
- 6langchain 加载 csv,json_langchain csv
- 7HCIP网络笔记分享——VLAN及MPLS多标签协议交换_mplsvlan
- 8大模型框架LangChain开发实战(一)_langchain应用流程图
- 9【Python】进阶学习:pandas--info()用法详解_pandas info()函数
- 10git 查看/配置 local/global 用户名称和用户邮箱
使用Yolov3训练自己制作数据集,快速上手(详细图文教程)_yolov3训练自己的数据集
赞
踩
在目标检测和分类这方面,Yolo可以快速很好的解决许多问题,这里总结了快速上手Yolov3的方法,直接快速训练自己的数据集使用。
一、源码包准备
我提供一个已经调试通的源码包,包含了数据集和源代码,以及我修改的代码,学习者可以先下载后配套着进行学习,我接下来的讲解,都将基于此源码包讲解,获取源码包的方法为:文章末扫码到公众号中回复关键字:目标检测YoloV3。获取下载链接。
下载好解压后的文件样纸见下:
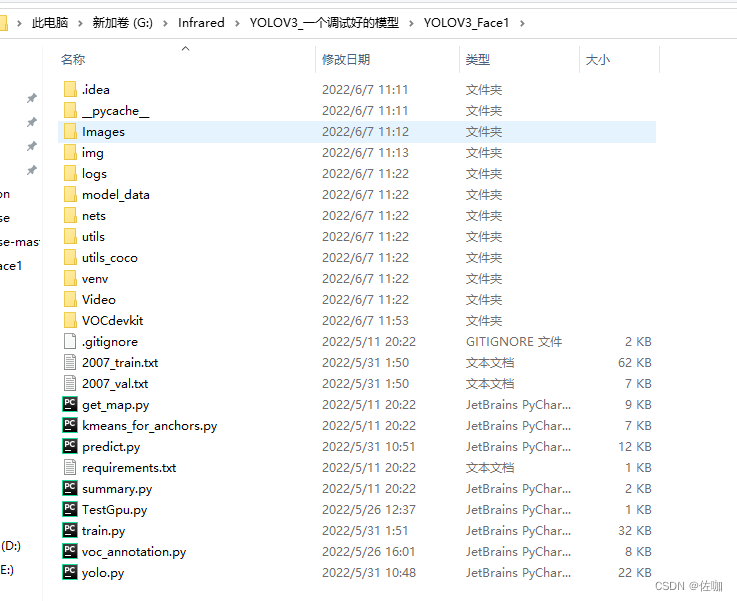
二、训练集准备
使用源码包训练自己的数据集。
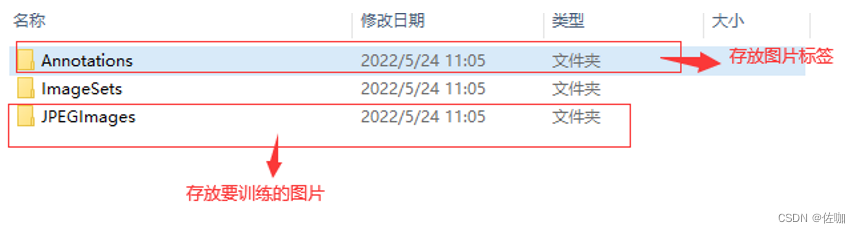
2.1 训练样本和标签存放位置
图片训练样本和标签的存放位置,见下:


2.1.1 JPEGImages文件
其中JPEGImages文件中的样纸见下:
2.1.2 Annotations文件
其中Annotations文件中的样纸见下:
每个.xml文件中的内容见下:
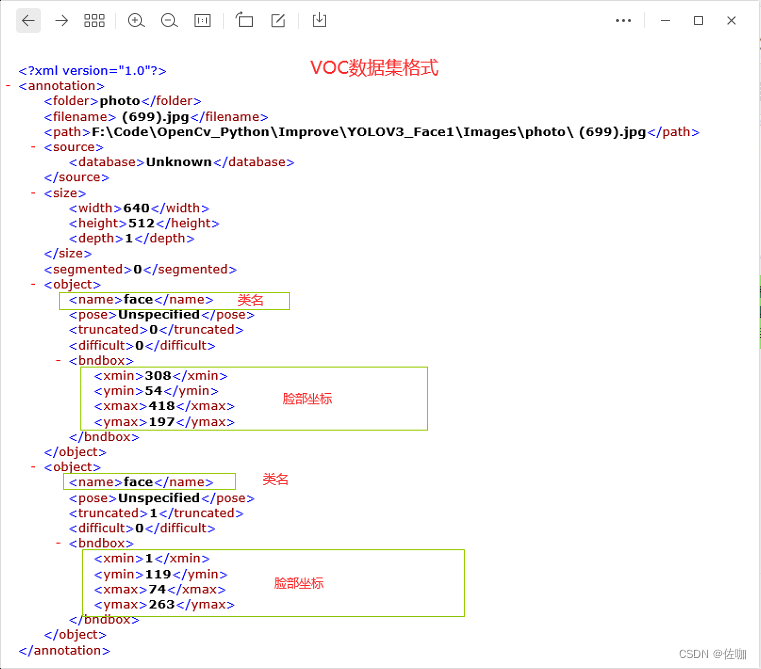
在训练自己数据集的时候,只需要将自己的数据集图片拷贝到文件夹JPEGImages中,标签文件拷贝到文件Annotations中就行,不需要自己重新命名文件夹,直接用我给的框架就可以。
2.2 制作自己训练集
2.2.1 制作数据集标签
关于制作VOC数据集,yolo数据集的详细方法,可以参考我另外一篇博客,链接:VOC数据集制作
制作COCO数据集的详细方法见我另外一篇博客,链接:COCO数据集制作
三、训练
3.1 参数修改
(1)在文件夹model_data文件中cls_classes.txt文件中写入打标签时的类名,见下:
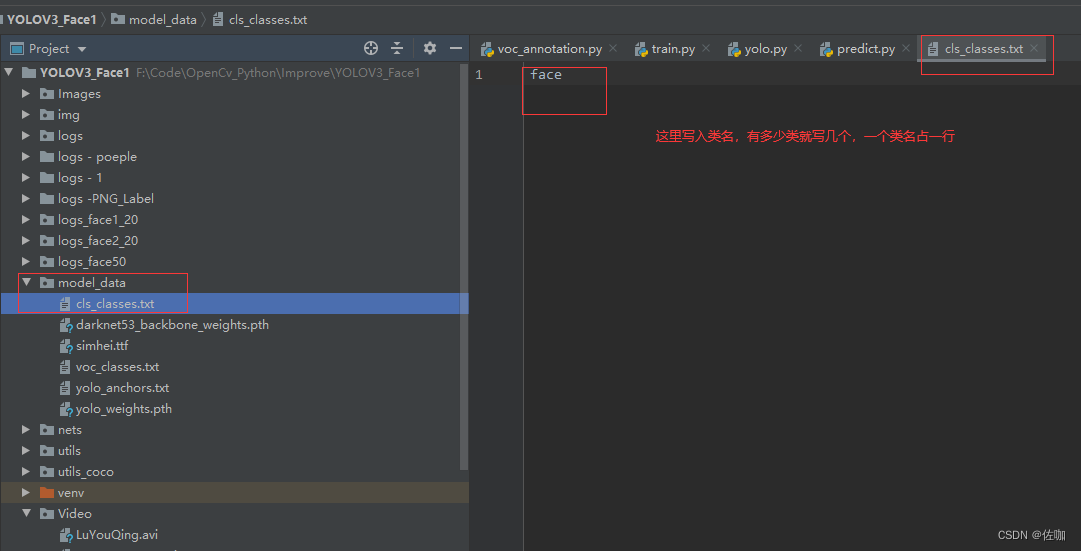
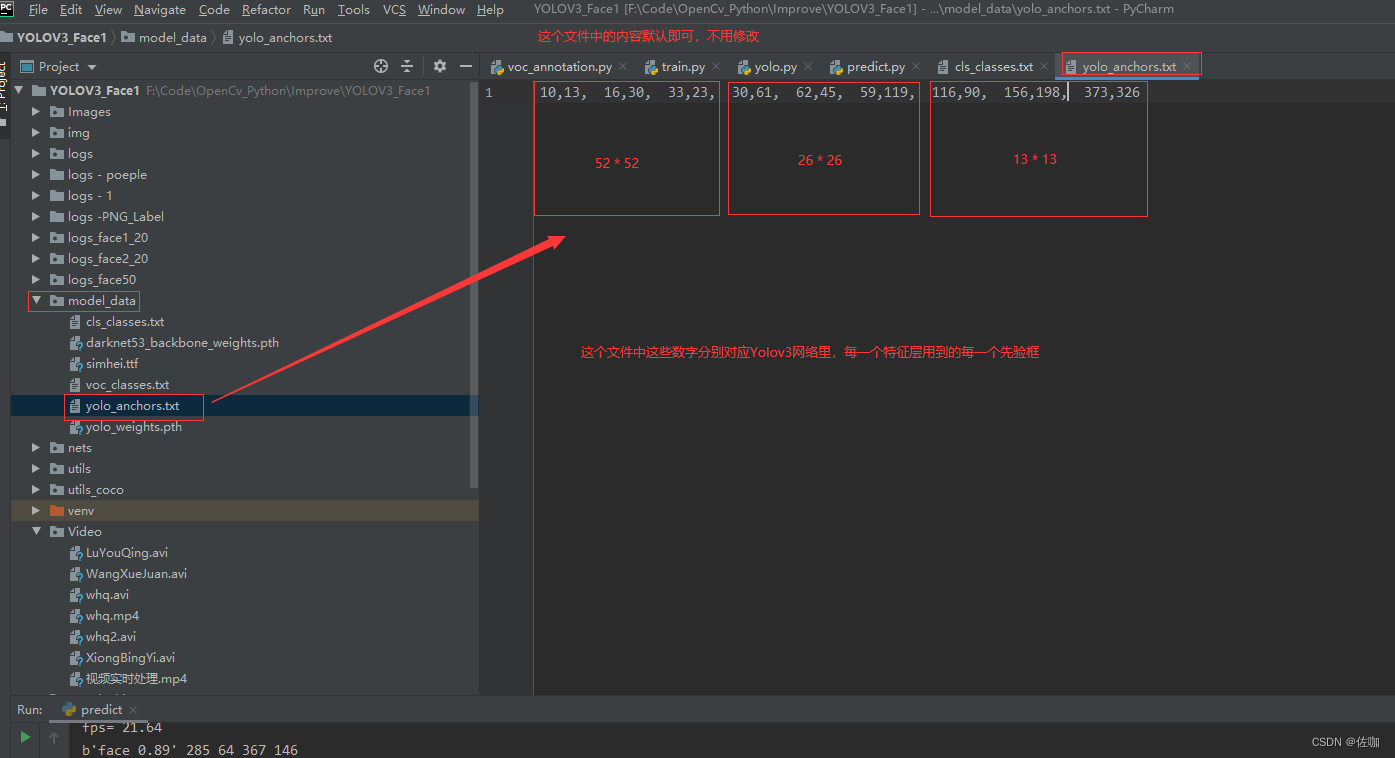
(2)文件夹model_data文件中yolo_anchors.txt文件,这里主要介绍一下文件中的内容,学习者不用修改,保持原有的默认即可,见下:
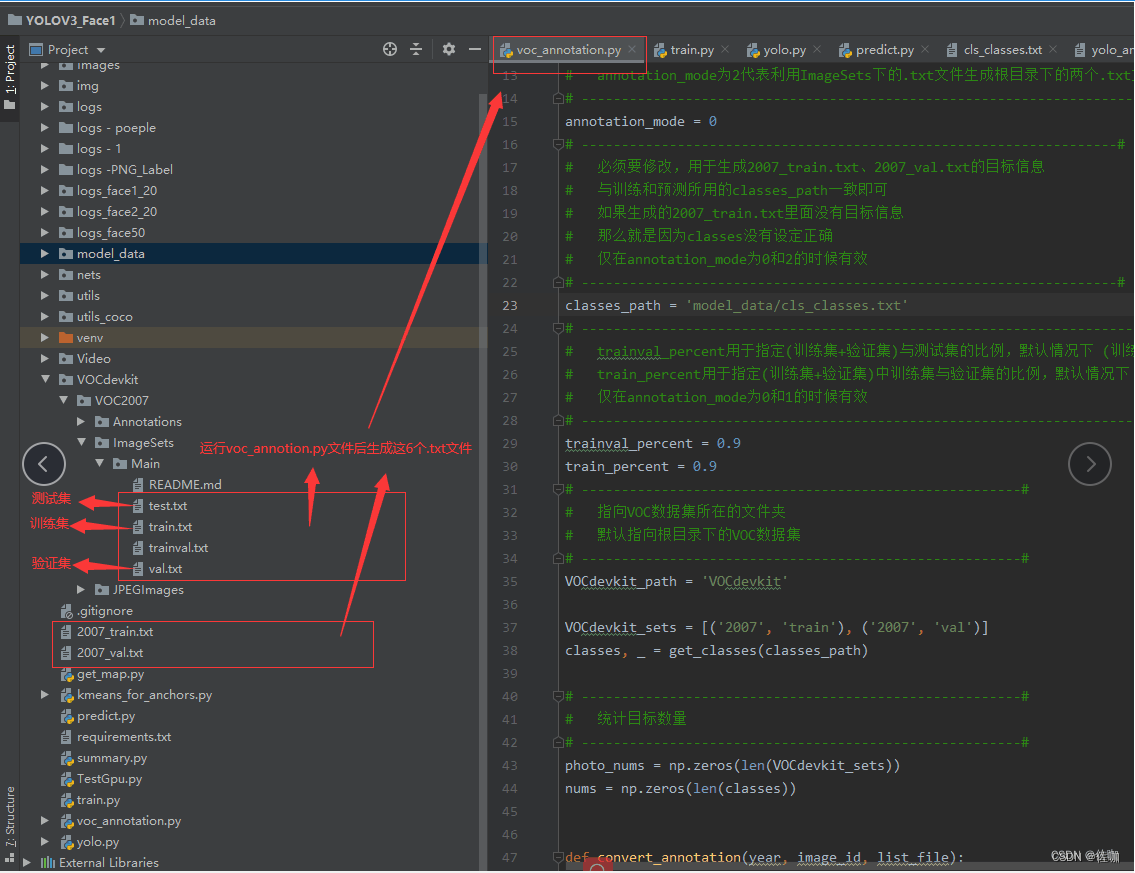
(3)修改voc_annotion.py文件中classes_path的路径:
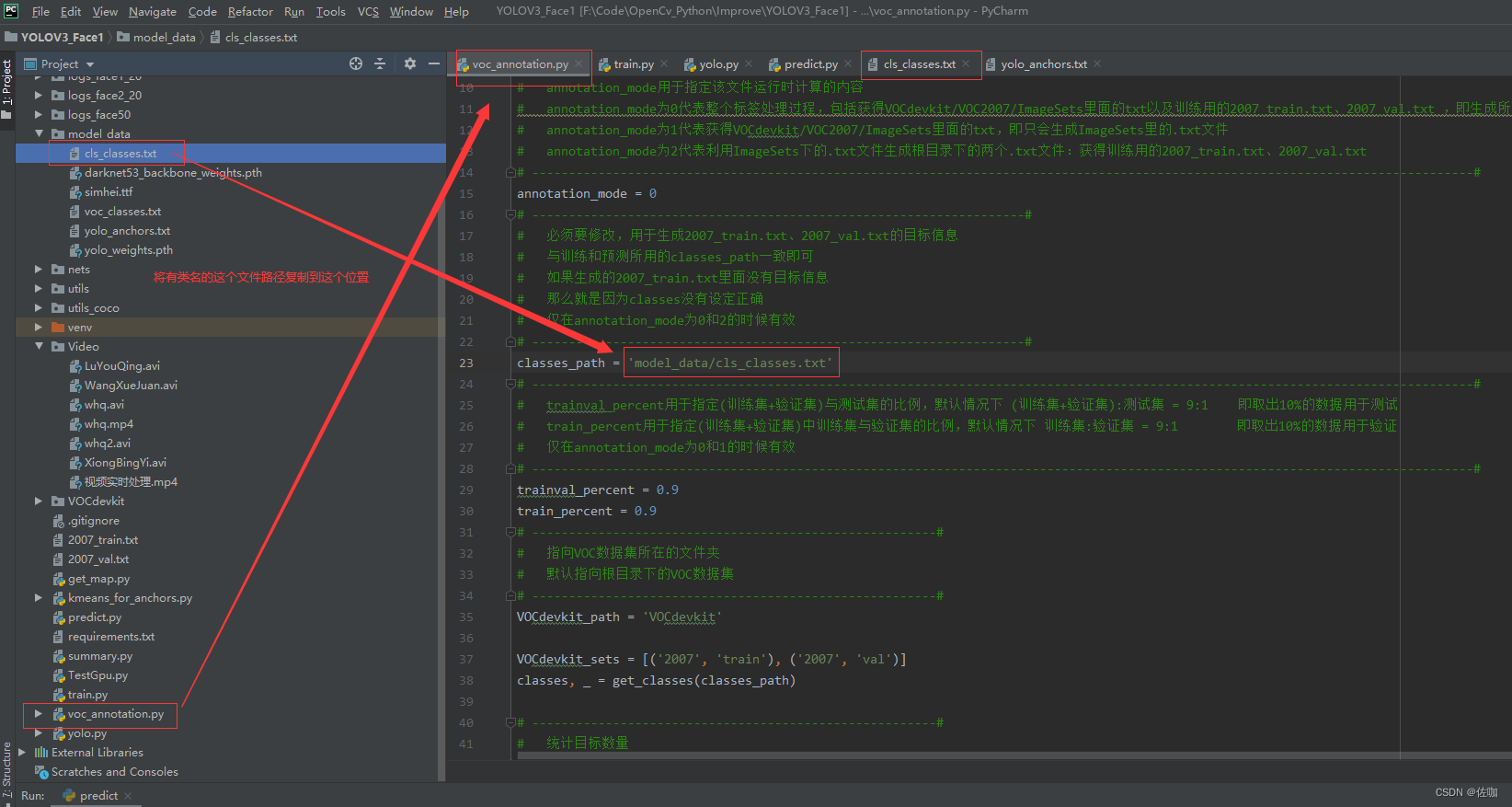
(4) 运行voc_anntion.py文件会生成6个训练要用到的.txt文件,6个.txt文件分别见下:
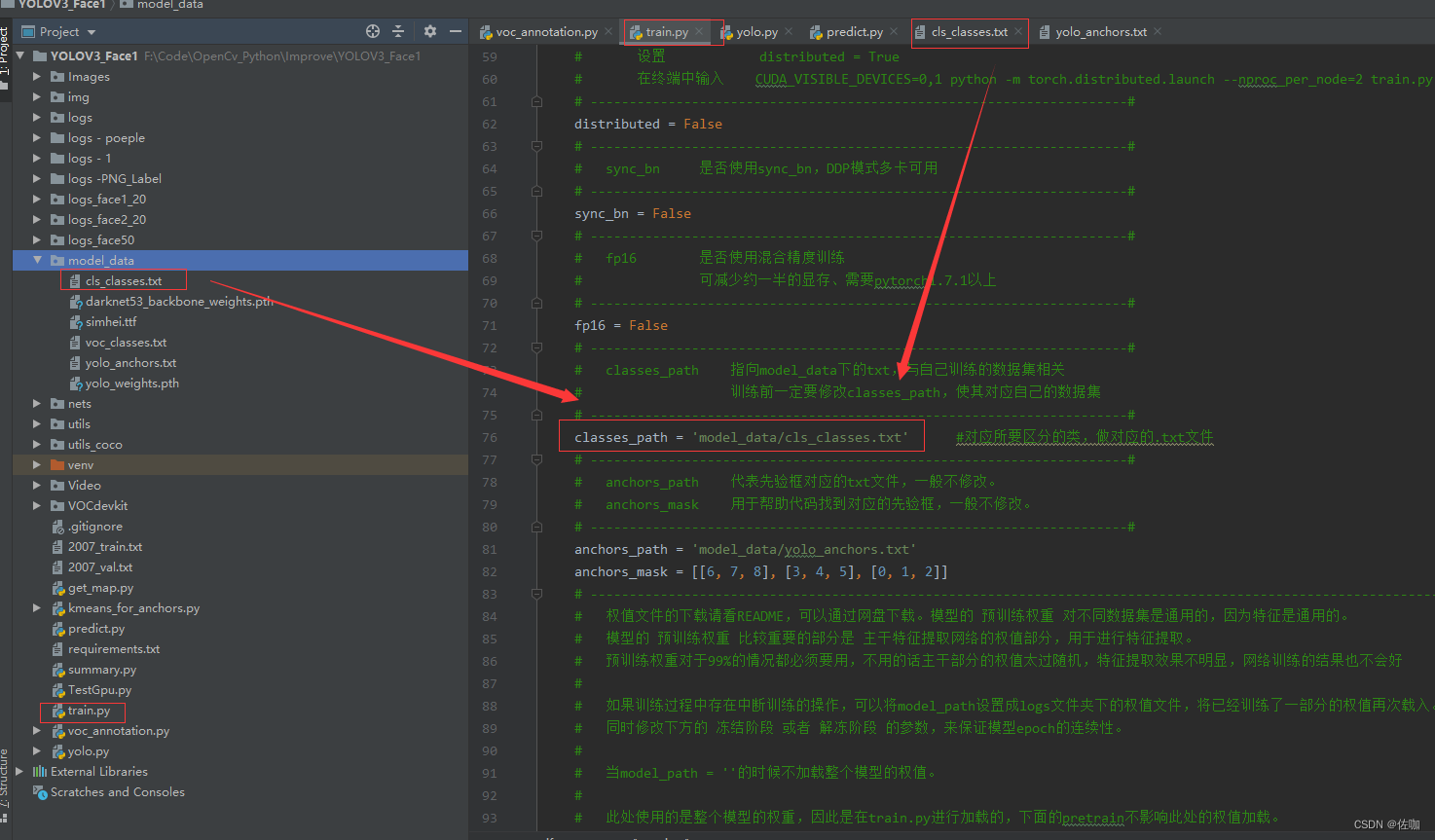
(5) 修改训练文件train.py中的classes_path,见下:
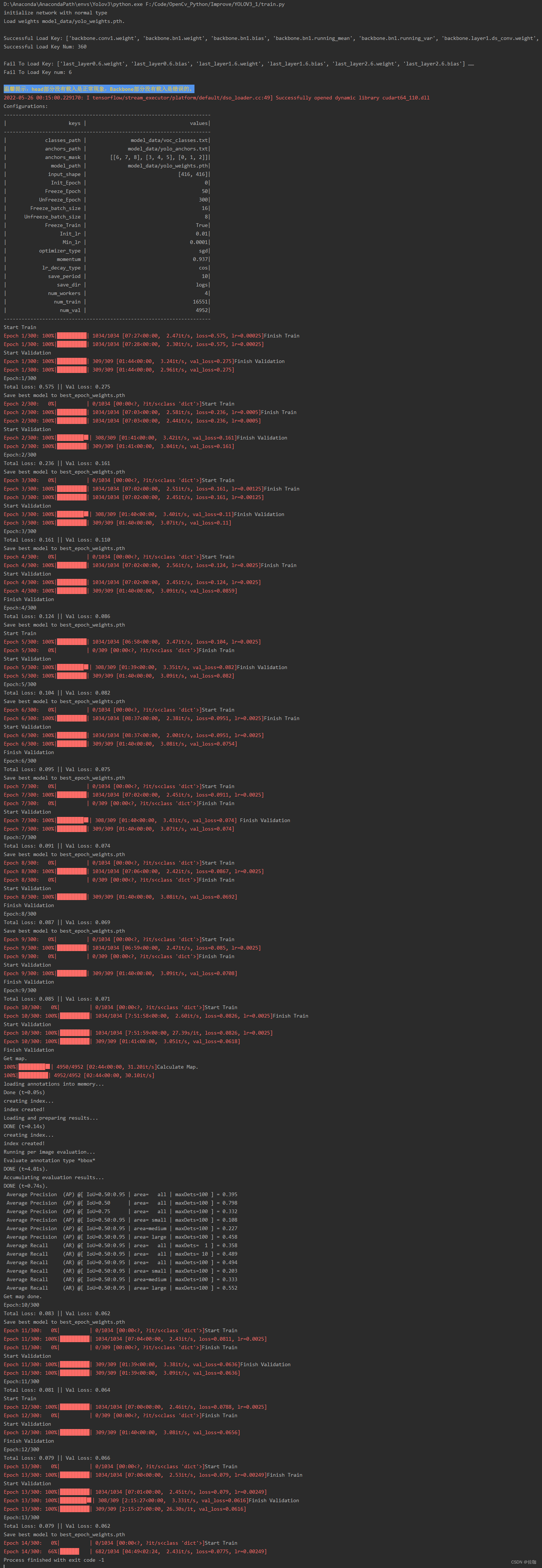
3.2 开始训练
直接运行train.py文件就可以开始训练了,见下:
四、推理测试
4.1 参数修改
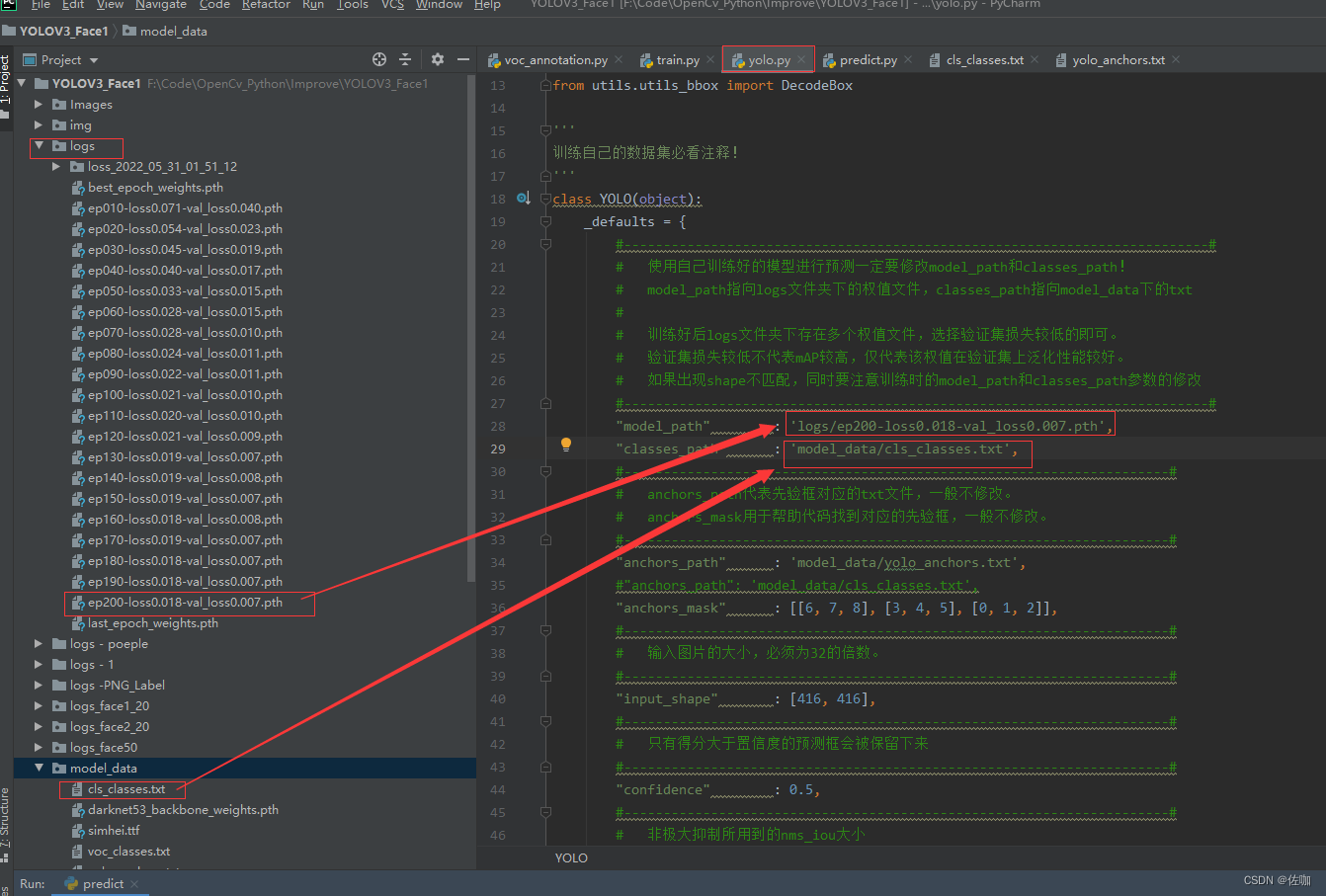
训练好模型后进行测试,将训练好的模型复制到yolo.py文件下,并修改classes_path,见下:
4.2 测试
开始验证训练后模型的检测效果,直接运行文件predict.py文件,见下:
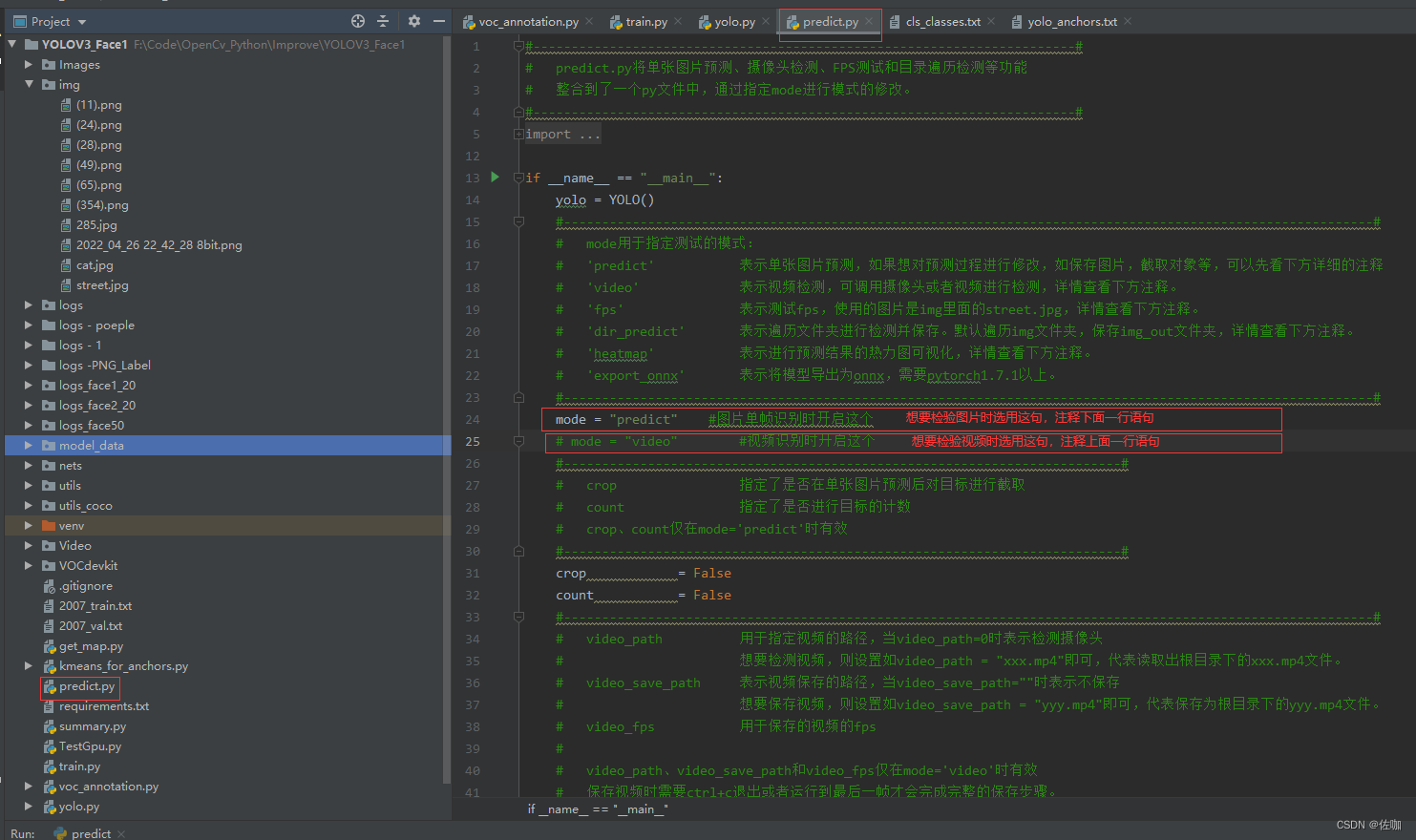
4.3 测试输出
运行后的输出见下:
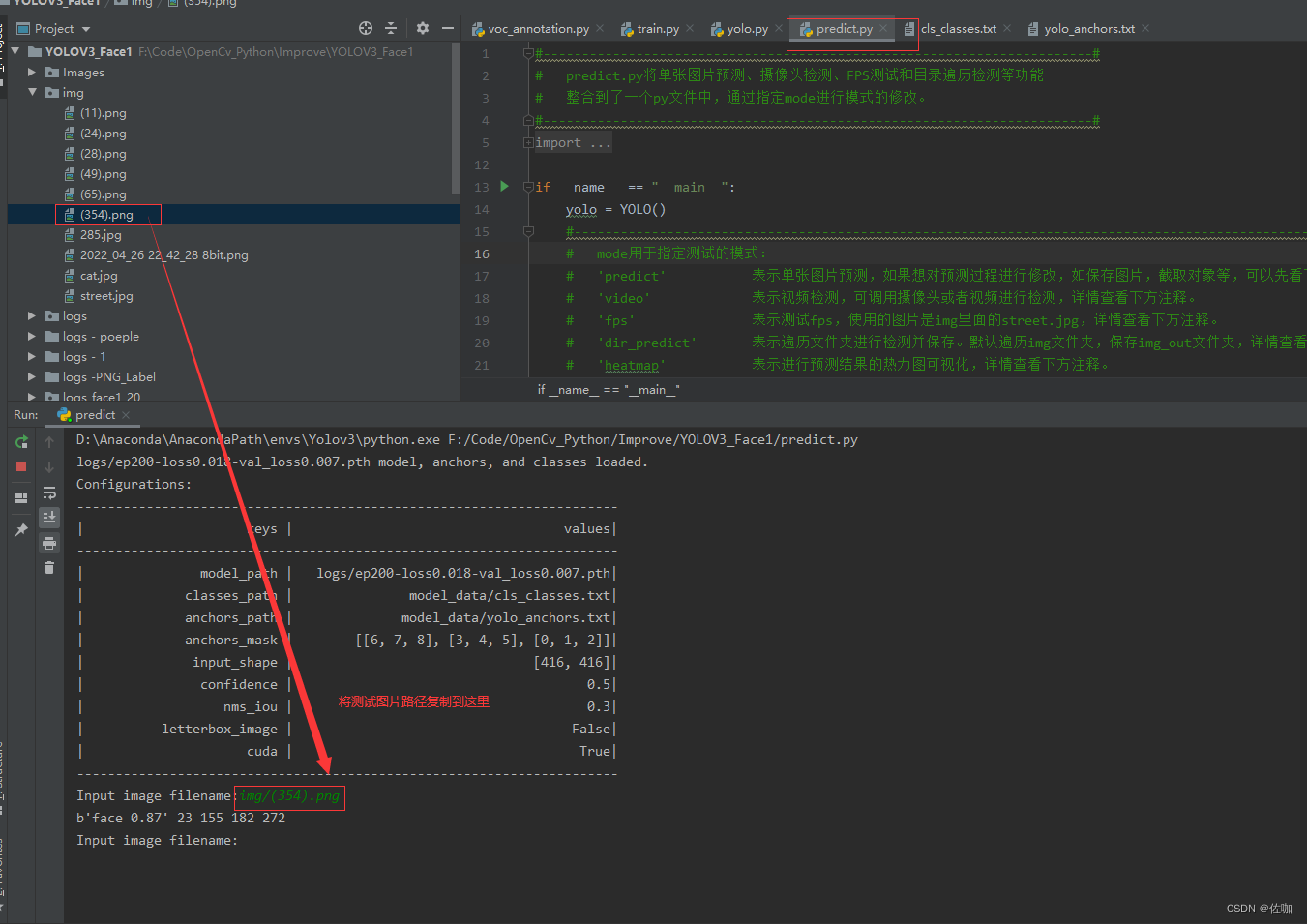
4.4 测试结果
4.4.1 测试单帧图像
检测结果见下:

4.4.2 视频实时测试
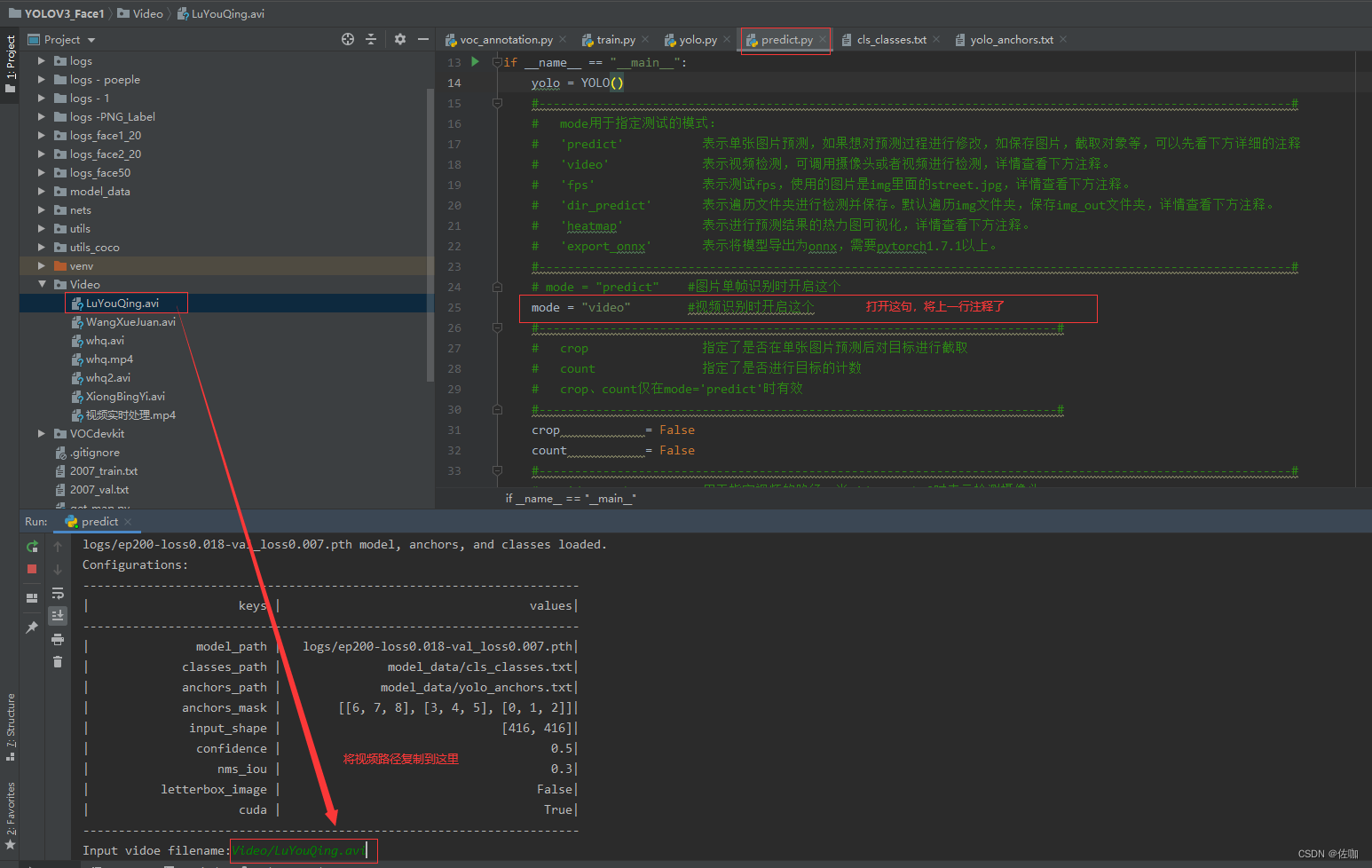
4.4.2.1 代码修改
想用视频检测时的代码修改见下:
4.4.2.2 视频测试效果
视频实时的检测效果见下(这里只是截取了其中一帧,运行代码视频是可以实时高效检测到人脸的):

五、总结
以上就是使用Yolov3训练自己制作的数据集,快速上手的方法,学习者在使用的时候只需要按照我上面的步骤,修改几个文件参数就可以训练自己的数据集了,希望对正在学习Yolov3的你有所帮助,想快速上手学习Yolov5的学者,详见我另外一篇博客YoloV5。
总结不易,多多支持,谢谢!

