
- 1ChatGPT绘图指南:DALL.E3玩法大全(一)_dall e3
- 2vue实现登录路由跳转到成功页面,看看这篇文章吧,拥有百万粉丝的大牛讲述学前端的历程_使用vue框架实现登录注册页面及路由跳转
- 3SQLite数据库使用指南以及相关API编程_使用sqllite
- 4SQL语言中的查询语句整理_sql包含查询
- 5在ubuntu18.04上安装以及运行Faster-lio_fast lio安装
- 6团队协作方法之:高效使用任务故事墙_软件开发任务墙
- 7简单讲讲在一台机器上用docker部署hadoop HDFS_hdfs docker
- 8AI-人工智能初识,跟上时代的步伐也要走在未来的路上
- 9从内部防护汽车网络安全——硬件安全模块(HSM)保护ECU主处理器内部
- 10中缀表达式转换为后缀表达式_中缀表达式转后缀表达式
一文梳理ICML 2022中图机器学习热点和趋势
赞
踩

©作者 | Mikhail Galkin,Zhaocheng Zhu
译者 | Zhaocheng Zhu
单位 | Mila研究所/麦吉尔大学/蒙特利尔大学
研究方向 | 图机器学习,知识图谱
每年 ICML 都汇集了全球顶级 AI 研究者们的不少工作。在刚过去的 ICML 2022 中,我们看到了上百篇图机器学习相关的工作,以及不少相关的 Workshop [1]。在此,我们和大家来分享一下当下图机器学习中的研究热点。
我们尽力在这篇文章中涵盖 ICML 中图机器学习的所有方向,每篇方向介绍 2-4 篇论文。由于 ICML 的论文数量庞大,这篇文章难免会遗漏了一些工作。欢迎在文末评论指出。

图生成
今年,Denoising diffusion probabilistic model(DDPM [2])以其超越 GAN 和 VAE 的生成质量和理论性质,席卷了深度学习的诸多领域,例如:图像生成(GLIDE [3],DALL-E 2 [4],Imagen [5]),视频生成 [6],文本生成(Diffusion-LM [7]),甚至是在 RL 中使用 diffusion [8]。简单来说,diffusion model 对输入逐步增加噪声(直到它完全变成高斯白噪声),然后学习预测每一步增加的噪声,从而反向消除这些噪声,从噪声中生成输入。
在图机器学习中,diffusion 可能是今年最热的方向——尤其是在药物发现,conformation generation,量子化学等领域中。diffusion 通常会和最新的 equivariant GNN 结合使用。今年 ICML 里我们看到了许多有意思的基于 denoising diffusion 的图生成工作。
Hoogeboom 等人在 Equivariant Diffusion for Molecule Generation in 3D [9] 中定义了一种 equivariant diffusion model(EDM)用于解决 conformation generation。EDM 对三维欧式空间变换(即旋转,平移和翻转)具有 equivariance,以及对输入点 feature 上的群运算具有 invariance。值得注意的是,分子的 feature 具有很多不同的 modality:比如电荷数是个整数标量,原子类型是个 one-hot feature,分子坐标则是实数向量。因此在分子上用 diffusion 模型的难点在于,你没法通过对所有 feature 暴力加相同的高斯噪声使得模型 work。对此,这篇论文设计了一种针对不同 feature 的加噪方法和 loss,并且调整输入 feature 的尺度来使训练更加稳定。
EDM 用 SotA 的 E(n) GNN [10] 来根据输入 feature 和时间步预测增加的噪声强度。在测试的时候,我们先采样一个原子数 M,然后基于给定的性质 c,让 EDM 来生成分子(由 feature x 和 h 控制):
EDM 在 negative log-likelihood,molecule stability,uniqueness 等指标上都大幅超过基于 normalizing flow 和基于 VAE 的生成方法。Ablation study 证明了 equivariant GNN 对性能非常重要,无法被普通的 MPNN 取代。EDM 的代码已经在 GitHub 上开源 [11],值得一试!

▲ Diffusion 的正向和反向过程。来源:Hoogeboom 等人的工作 [12]

▲ Diffusion动态过程演示。来源:Twitter [13]
Jo,Lee 和 Hwang 提出了解决二维图生成的 Graph Diffusion via the System of Stochastic Differential Equations(GDSS)[14]。前面提到的 EDM 是一种 denoising diffusion probabilistic model(DDPM),GDSS 则属于 DDPM 的一个近亲,score-based model。前不久 ICLR’21 的工作 [15] 得出一个结论,如果我们把正向的 diffusion 过程用随机微分方程(SDE)解释的话,DDPM 和 score-based model 是可以统一为一个框架的。
SDE 允许模型在连续空间里像 Wiener process [16](可以理解为一种花式加噪声的方式)那样进行 diffusion,而 DDPM 通常需要离散化成 1000 步加噪过程和时间步的 embedding。
当然,SDE 需要依赖一些复杂的求解器进行计算。跟先前 score-based 图生成方法比,GDSS 取邻接矩阵 和点 feature 作为输入,并同时预测这两。SDE 中的正向和反向 diffusion 需要计算 score,也就是 和 联合概率的对数的梯度。为了预测这个联合概率,我们需要一个score-based model。论文里作者们用的是一个带 attention pooling 的 GNN [17]。
训练过程需要解一个 forward SDE,并且训一个 score model。测试时,我们用训好的 score model 来求解 reverse-time SDE。通常这需要涉及到 Langevin dynamics [18],例如 Langevin MCMC,不过理论上也可以用高阶的 Runge-Kutta [19] 求解器。GDSS 在二维图生成任务中大幅超过 autoregressive 生成模型和 one-shot VAE,尽管由于 reverse-time SDE 的存在,采样速度不尽人意。GDSS 的代码 [20] 已经开源了!

▲ GDSS模型。来源:Jo,Lee和Hwang的工作 [14]
根据最近 arXiv 的情况来看,估计今年还会有不少 diffusion model 出来——DDPM 在图上的应用值得我们单独开一篇博客来写。大家可以期待一下!
最后我们来介绍一篇非 diffusion 的生成工作。Martinkus 等人 [21] 提出了SPECTRE [22],一种解决 one-shot graph generation 的 GAN 模型。跟其他直接生成邻接矩阵的 GAN 不同的是,SPECTRE 根据 Laplacian 的最小的 k 个特征值和特征量来生成图。这意味着我们可以显示控制图的连通性和聚类属性。
生成的过程一共有三步:1)SPECTRE 先生成 k 个特征值;2)在最小 k 个特征向量导出的 Stiefel manifold [23] 上采样得到 k 个特征向量。Stiefel manifold 涵盖了各种标准正交阵,我们可以从中采单个 的矩阵;3)最后,论文用 Provably Powerful Graph Net [24] 把特征值和特征向量转化为邻接矩阵。
SPECTRE 在实验上比其他 GAN 方法有极大的提升,并且比 autoregressive 的图生成方法快了近 30 倍。
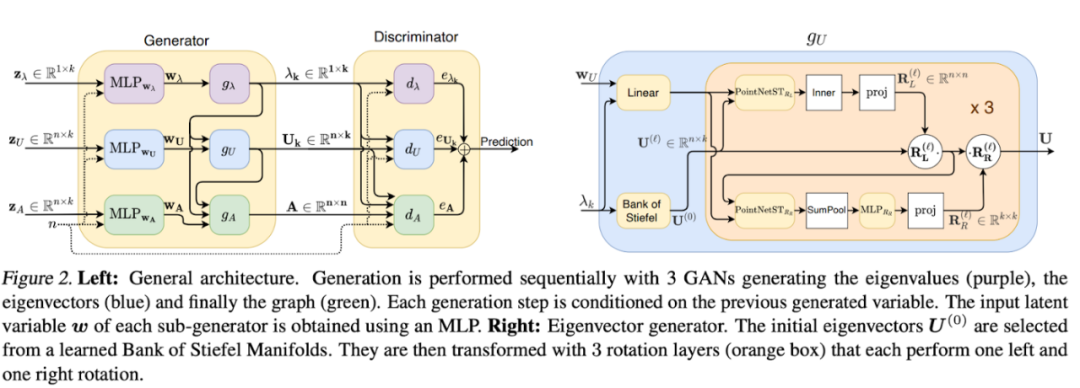
▲ SPECTRE的三步生成过程:特征值→特征向量→邻接矩阵。来源:Martinkus等人 [21]

图Transformer
今年 ICML 有两篇工作改进了图 Transformer。
第一篇论文是 Chen 等人 [25] 提出的 Structure-Aware Transformer(SAT)。他们注意到 self-attention可以看作一种用 exponential kernel 作为query-key product 的 kernel smoothing。从这个角度,我们可以探讨如何设计一种更 general 的 kernel。
这篇论文提出用点和图上的函数,k-subtree 和 k-subgraph 来增加 Transformer 对结构信息的表达能力。k-subtree 即点的 k-hop 邻域,可以被非常快速地提取出来,但表达能力无法超过 1-WL test。而 k-subgraph 的计算代价则更大,但是能提供更强的表达能力。
无论你使用哪种 feature 方式,我们都可以用一个 GNN(例如 PNA)来 encode每个点的 subtree 或 subgraph,通过图层面的 pooling(sum / mean / 虚拟点)得到一个 feature,用在 Transformer 的 self-attention 里作为 query 和 key(见下图)。
实验表明,在 k-subtree 和 k-subgraph 中,k 取 3 或者 4 即可。当我们能接受 k-subgraph 的计算时间时,k-subgraph 得到的结果要明显好于 k-subtree。一个有趣的现象是,诸如 Laplacian 的特征向量和随机游走 feature 等 positional feature 只对 k-subtree SAT 有用,对 k-subgraph SAT 并无太大帮助。

▲ 来源:Chen等人 [25]
第二篇论文是 Choromanski,Lin,Chen 等人 [26](和著名的线性 attention 论文 Performer [27] 几乎是同一拨人)研究 sub-quadratic 复杂度的 attention 的工作。具体来说,他们考虑了图像、音频、视频和图等不同 modality 下 relative positional encoding(RPE)及其变种。
就图而言,我们知道在 attention 中使用最短路距离的 Graphformer 很好用,但它的计算需要实例化整个 attention 矩阵(也就不 scalable)。我们能否设计一种不需要实例化整个矩阵,同时又能整合图 inductive bias 的 softmax attention 方式呢?
答案是肯定的!这篇论文就提出了两种机制:1)我们可以用 Graph Diffusion Kernel(GDK)。GDK 又叫作 heat kernel,可以用于模拟热传播的过程,在这里我们可以把它看作一种 soft 的最短路。然而 Diffusion 需要通过特殊的求解器来计算矩阵的幂,所以这篇论文设计了另一种方案;2)Random Walks Graph-Nodes Kernel(RWGNK)用于计算两个点各自随机游走产生的频率向量的点乘。
没错,随机游走就是这么有效!大家可以在下方图里看到 diffusion 和随机游走 kernel 的结果。论文最终用的基于 RWGNK 的 transformer 叫作 Graph Kernel Attention Transformer(GKAT),并在一众合成数据集、计算生物数据集和社交网络数据集上进行了测试。GKAT 在合成任务上取得了更好的结果,在其他图任务上跟普通 GNN 齐平。可以说,有了这篇工作,Transformer 的 scalability 几乎只受制于输入本身的大小了!
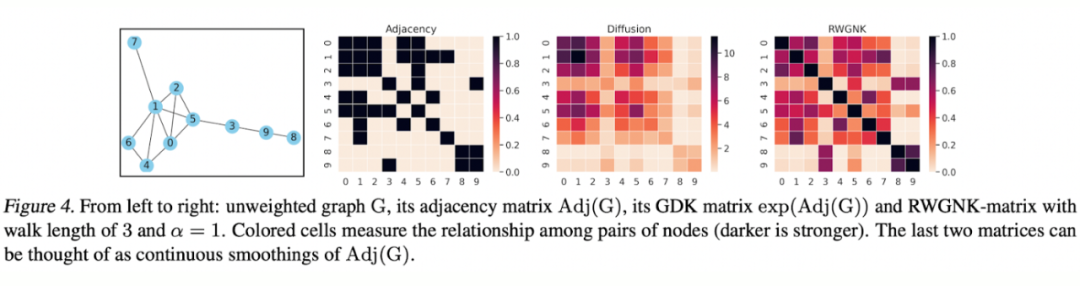
▲ 来源:Choromanski,Lin,Chen等人 [26]

GNN理论和表达能力
整个 GNN 领域一直在努力寻找突破 1-WL test 同时保持较低的多项式复杂度的GNN 设计。
Papp 和 Wattenhofer [28] 对理论领域现状提出了一个精准的总结:
每当一个新的 GNN 变种出现时,大家总会用理论去论证这个模型比 1-WL test 强,有时候还会跟经典的 k-WL 分类系统进行比较…… 我们能否设计一个更有意义的衡量 GNN 表达能力的方式?
这篇论文将 GNN 表达能力的相关工作分为了 4 个大类:1)k-WL 家族及其近似;2)子结构计数(S 类);3)提取子图和邻域的 GNN(N 类)(Michael Bronstein 最近的一篇博客详细探讨过这类 [39]);4)带标记的 GNN,例如在点或者边上进行扰动或者打标记的(M 类)。论文在理论框架下讨论了 k-WL,S,N 和 M 四类的关系,以及哪个比哪个强,强多少。这套分类系统比 k-WL 更加精细,有助于设计恰好覆盖任务需求同时节省计算成本的 GNN。
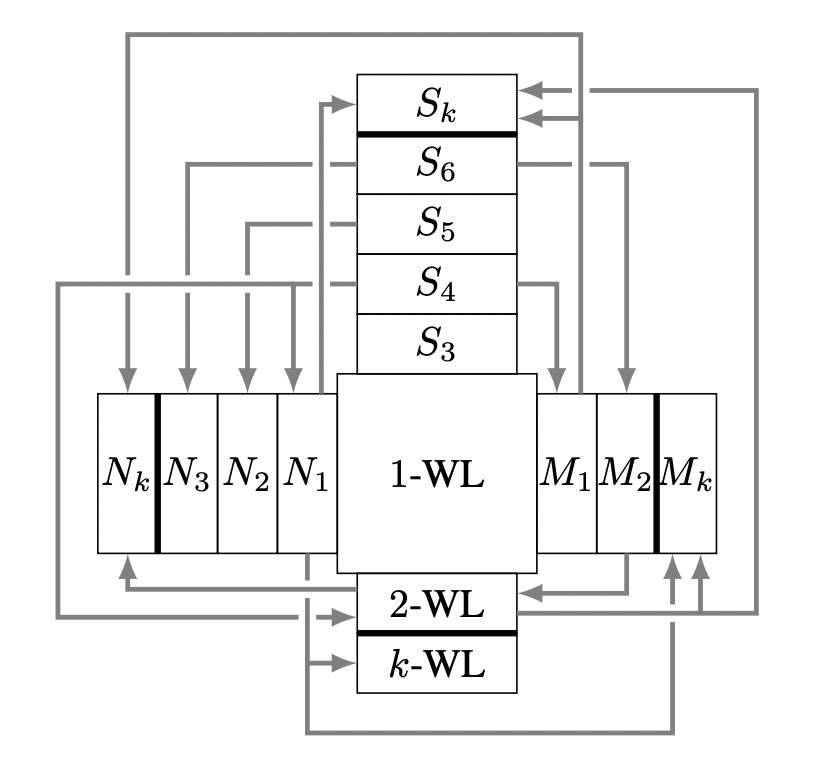
▲ GNN表达能力的分类系统。N表示子图GNN,S表示子结构计数,M表示带标记的GNN。来源:Papp和Wattenhofer [28]
今年 ICMl 最“香”的论文估计是 Morris 等人 [28] 的 SpeqNet 了(注:Speq 在德语里是培根 speck 的谐音)。我们知道高阶的 k-WL GNN 要么依赖 k 维tensor,要么需要考虑所有 k 个点组成的子图,都是关于 k 指数增长的复杂度,没法充分利用图的稀疏性。SpeqNet 提出了一种新的图同构问题的启发算法 (k,s)-WL,可以更精细地控制表达能力和速度的取舍。
论文探讨了一种只需要考虑部分点集的局部 k-WL test,避免了 k-WL 那样指数的时间复杂度。具体来说,论文中只考虑不超过 s 个连通分量的 k 元组或 k 个点组成的子图,有效地利用了图的稀疏特性。通过调整 k 和 s 的取值,我们可以从理论上控制模型的速度和表达能力。
基于上述思想,论文提出了一类新的 permutation-equivariant 的 GNN,SpeqNet。和高阶 GNN 相比,SpeqNet 在点和图任务的监督学习上大幅降低了计算时间。相较于标准 GNN 和图 kernel 而言,SpeqNet 显著提高了预测性能。

