
- 1超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门
- 2【Doris】Doris 最佳实践-Compaction调优(3)_doris中如何查看哪个表的版本有堆积?
- 3⑩② 【MySQL索引】详解MySQL`索引`:结构、分类、性能分析、设计及使用规则。_mysql 索引名带`
- 4CentOS 7.6 防火墙打开、关闭,端口开启、关闭_centos7.6开放端口命令
- 5李宏毅-2023春机器学习 ML2023 SPRING-学习笔记:2/24 正确认识chatGPT_李宏毅2023gpt
- 6yaw(pan)/pitch(tilt)/roll计算_yaw pitch roll计算
- 7Vivado PLL锁相环 IP核的使用
- 8雪花id如何保证连续且不重复
- 9解决ssh:connect to host github.com port 22: Connection timed out与kex_exchange_identification_cloning into 'gonganzichan'... ssh: connect to hos
- 10循环队列的初始化,入队,出队,求队长,取队头元素_循环队列初始化
【机器学习】XGBoost 详细解读 (集成学习_Boosting_GBM)_xgboost和gbm
赞
踩
【机器学习】XGBoost 详细解读 (集成学习_Boosting_GBM)
1. 介绍
XGBoost(eXtreme Gradient Boosting、XGB),是一种 Boosting 算法,他对 GBM 算法做了大量的理论和工程优化,准确率和运行效率都大大提升。XGBoost 通常使用 CART 作为基学习器。针对分类或回归问题,效果都非常好。在各种数据竞赛中大放异彩,而且在工业界也是应用广泛,主要是因为其效果优异,使用简单,速度快等优点。
- CART 决策树可以参考: https://blog.csdn.net/qq_51392112/article/details/130508581
- GBM 可以参考:https://blog.csdn.net/qq_51392112/article/details/130530963
- 集成学习 可以参考:https://blog.csdn.net/qq_51392112/article/details/130507112

2. 基本原理
xgb 是 boosting 算法中的 GBM 方法 的一种实现方式,主要是降低偏差,也就是降低模型的误差。因此它是采用多个基学习器,每个基学习器都比较简单(避免过拟合),下一个学习器是学习前面基学习器的结果
y
i
t
y^{t}_{i}
yit 和实际值
y
i
y_{i}
yi 的差值,通过多个学习器的学习,不断降低模型值和实际值的差。

XGB 的基学习器可以选择 CART 或者线性函数,通常都用 CART,这里就以 CART 为例。那么当基学习器为 CART 时,对应的
f
(
x
)
f(x)
f(x) 可以如下表示,这里去掉了脚标。

这个式子有点绕,解释下:
- 假设决策树有 T T T 个叶子, w = { w 1 , w 2 , . . . . . w T } \mathbf w = \{w_1, w_2,.....w_T\} w={w1,w2,.....wT} 是由各个叶子权重组成的权重向量。
- 角标 q ( x ) ∈ { 1 , 2 , . . . . T } q(x) \in \{ 1, 2, ....T\} q(x)∈{1,2,....T} 代表具体的叶子序号,这个 q 函数就代表决策树的决策过程。
- 所以 w q ( x ) w_{q(x)} wq(x)就是输入 x 被 q 函数分到的叶子节点的权重。
- 举个例子,比如像下图,有个输入
x
i
x_i
xi, q 函数对它做出判断,认为它应该被分到 3 号叶子节点,这样函数
f
(
x
)
f(x)
f(x) 就会把 3 号节点的权重
w
3
w_3
w3 作为输出结果返回。
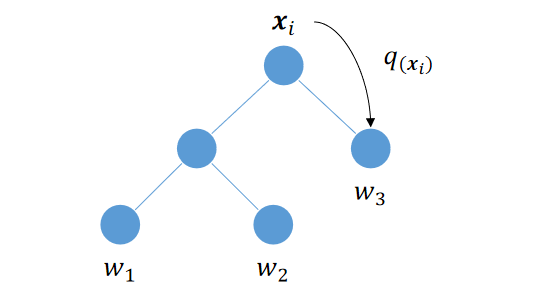
归纳下,XGB 的基本思路就是:
- 不断生成新的树,每棵树都是基于上一颗树和目标值的差值来进行学习,从而降低模型的偏差。
- 最终模型结果的输出如下: y i = ∑ k = 1 t f k ( x i ) y_{i}=\sum_{k=1}^{t}f_{k}(x_{i}) yi=∑k=1tfk(xi),即所有树的结果累加起来才是模型对一个样本的预测值。
那在每一步如何选择/生成一个较优的树呢?那就是由下面的目标函数来决定。
3. 目标函数(二阶泰勒展开求解)
3.1 基础的目标函数

目标函数由两部分组成:
- 一是模型误差,即样本真实值和预测值之间的差值,
- 二是模型的结构误差,即正则项,用于限制模型的复杂度。
- 对于 CART类决策树,正则项为:

因为 y i t = y i t − 1 + f t ( x i ) y_{i}^{t}=y_{i}^{t-1}+f_{t}(x_{i}) yit=yit−1+ft(xi),所以将其带入上面的公式中转换为:
O b j t = ∑ n = 1 n L ( y i , y i t − 1 + f t ( x i ) ) + Ω ( f t ) + ∑ t = 1 T − 1 Ω ( f t ) Obj^{t}=\sum_{n=1}^{n}L(y_{i},y_{i}^{t-1}+f_{t}(x_{i}))+\Omega(f_{t})+\sum_{t=1}^{T-1}\Omega(f_{t}) Objt=n=1∑nL(yi,yit−1+ft(xi))+Ω(ft)+t=1∑T−1Ω(ft)
- 对于 CART类决策树,正则项为:
因此,
- 第 t 颗树的误差由三部分组成:n个样本在第 t 颗树的误差求和、第 t 颗树的结构误差、前 t-1 颗树的结构误差。
- 其中前 t-1 颗树的结构误差是常数,其实可以忽略,因为我们已经知道前 t-1 颗树的结构了。
3.2 二阶泰勒简化
泰勒公式可以参考:https://blog.csdn.net/qq_51392112/article/details/130645876。
上述公式即为:xgb第 t 步的目标函数。唯一的变量即为
f
t
f_{t}
ft ,此处的损失函数仍然是一个相对复杂的表达式,所以为了简化它,采用二阶泰勒展开来近似表达,即,这里对
f
t
(
x
i
)
=
y
^
i
t
−
1
f_t(x_i) = \hat y_{i}^{t-1}
ft(xi)=y^it−1 处进行泰勒展开。则上述损失函数转换为二阶导之后:





3.3 缩减(shrinkage)和列抽样
-
这里的缩减和 GBDT 里的缩减一样,都是为了降低单棵树的影响,给后面的树留有空间。因此引入一个学习率 n,用它去乘每步生成的 f t ( x ) f_t(x) ft(x)。
-
列抽样在 GBDT 和随机森林里都有用到,它可以牺牲偏差来降低方差。实现方法就是在分裂节点的时候只用一部分特征。
4. 节点分裂
节点分裂的目标是找出一个特征,按照这个特征的某个节点分裂后,能够使目标函数降低最多。所以这里面有两层循环,外层是特征遍历,内层是特征值遍历。特征遍历没得说了,只能一个一个找,但是特征值遍历可以优化一些,缩短寻找最优分裂节点的耗时。我们分四步来看节点分裂:
- 精准贪心算法:每个位置都试下,精准定位最优分裂节点
- 近似算法:按分位数查找,找出近似最优的分裂节点
- 加权分位数缩略图:按 h 的加权分位数,找出比前一种更好些的分裂节点
- 稀疏感知分裂:针对存在稀疏性或缺失值的数据做了一点优化
4.1 精准贪心算法
首先了解下最基本的方法——精准贪心算法。
贪心算法分裂的方式就是一种暴力搜索的方式,遍历每一个特征,遍历该特征的每一个取值,计算分裂前后的增益,选择增益最大的特征取值作为分裂点。
- 首先,每个特征要排序,排序过后,分裂节点左边和右边的一阶导数加和 G 与二阶导数加和 H 就好计算了。回顾下他俩的定义:

注意到, g i g_i gi, h i h_i hi 是根据 t-1 轮结果计算的,当前是在求解第 t 轮的树结构,所以 g i g_i gi, h i h_i hi 在当前是已知的、计算好的。
精准贪心算法如下图,红线是分割线,在每一个地方都分割一次,计算一次
L
s
p
i
l
t
L_{spilt}
Lspilt 。分割线左侧的
g
,
h
g,h
g,h 分别加起来就是左侧
G
,
H
G, H
G,H ,分割线右侧的
g
,
h
g,h
g,h 分别加起来就是右侧
G
,
H
G, H
G,H 。

那么遍历一遍后选择目标函数降低最多的分裂点进行节点分裂,也就是在
L
s
p
i
l
t
L_{spilt}
Lspilt 最大的分裂点处进行节点分裂。
4.2 近似算法
精准贪心算法的问题显而易见:
- 候选节点太多,耗时太长。
因此有了近似它的算法。最优切分点没必要找的那么精确,
- 因为我们训练的基学习器是弱学习器,所以没必要让他学得特别准,
- 后面还有 Boosting 来提高他的准确率呢。
那么基于这种想法,可以把这个候选节点范围缩小下,不再枚举,而是只选用分位点。比如下图选择了两个三分位点,也可以用四分位点或者其他更多的点。本质上就是把特征分到多个桶里,让数据粒度变粗,只跟桶打交道,降低计算量。

这里存在一个划分时机的问题,即,
- 在一棵树分裂前就按分位数给划分好(全局分裂点),
- 还是在每个节点分裂时进行划分(局部分裂点)?
两者都可以,但是后者需要的划分次数更少,因为后者对父节点用过的特征会分的更细。
- 比如 1 号特征在父节点用过一次,那么对于局部分裂情况,孩子节点再用这个特征的时候是在它分到的那部分样本里重新选择候选分裂点;而全局分裂是在一开始就把候选分裂点固定下来,当孩子节点再次使用时不会在细分样本集合里重新选择。
- 作者对于全局分裂点选取和局部分裂点选取这两种方法进行了实验测试,图中 eps 是后面会提到的参数,1/eps 可以近似代表前面提到的分位数个数。
- 可以看到,全局分裂模式在分的细时能够和精准贪心算法获得一样的精度,而局部分裂模式大概分一下,在训练后期就能获得同等精度。

综上,近似算法,其实就是分桶,目的是为了提升计算速度,降低遍历的次数,所以对特征进行分桶。就是将每一个特征的取值按照分位数划分到不同的桶中,利用桶的边界值作为分裂节点的候选集,每次遍历时不再是遍历所有特征取值,而是仅遍历该特征的几个桶(每个桶可以理解为该特征取值的分位数)就可以,这样可以降低遍历特征取值的次数。
- 分桶算法分为global模式和local模式,
- global模式就是在第一次划分桶之后,不再更新桶,一直使用划分完成的桶进行后续的分裂。这样做就是计算复杂度降低,但是经过多次划分之后,可能会存在一些桶是空的,即该桶中已经没有了数据。
- local模式就是在每次分列前都重新划分桶,优点是每次分桶都能保证各桶中的样本数量都是均匀的,不足的地方就是计算量大。
4.3 加权分位数缩略图
前面用分位数选点的方法还有优化的空间。
- 分位数选点的方法没有关注到误差大的样本,他对于排序后的所有样本一视同仁,这样其实不太好。
如果能够在误差比较大的样本处分的更细一些,效果会更好。所以就有了加权分位数缩略图的想法,用权重来表示误差大小。
- XGBoost 文章中用的二阶导数 h h h 代表权重, h h h 累加到一定值的时候做一次切分。
- 比如下图是累加到 0.3 的时候做一次切分。XGBoost 在这里还做了些细节上的工作,比如如何通过 eps 作为
h
h
h 累加和的阈值,来选择加权分位点,具体可以参考原文。

为什么选择 h h h 作为权重呢?可以从两个角度来看。
- 第一个角度是从目标函数的形式上来看。原来的目标函数可以经过恒等变换,配出平方项。
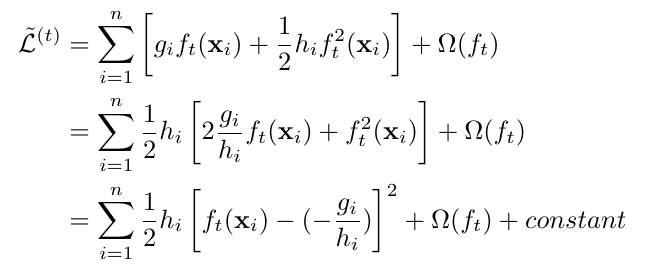
∑ \sum ∑ 里面是一个关于 − g i h i - \frac{g_i}{h_i} −higi 的加权平方误差,当 h i h_i hi 大的时候,这个平方误差在目标函数中所占比例相对来说就会大一些,所以会把 h h h 作为权重。 - 第二个角度是从
h
h
h 的表达式来看。当损失函数选择用于回归的平方误差时,即

h = 2 h = 2 h=2 是个常数,退化为分位数选点;但是当损失函数选择用于分类的交叉熵时,即

h = p ( 1 − p ) h = p(1-p) h=p(1−p) ,当 p = 0.5 p=0.5 p=0.5 附近时 h h h 最大,而预测概率等于 0.5 就意味着这个样本点在分类过程中左右摇摆,需要重点关注下,
h h h 的大小刚好能够用来反映这个摇摆程度,所以选择 h h h 作为权重。
4.4 稀疏感知
机器学习经常会碰到数据稀疏的问题,有三种情况会导致数据稀疏:
- 数据存在大量缺失值
- 数据中存在大量的 0 元素
- 特征工程中使用了 one-hot 编码,产生了大量的 0
所以让算法能够感知数据的稀疏模式是非常重要的。XGBoost 的解决方法是在每个节点中设置一个默认方向,缺失值或者 0 元素直接走默认方向,不参与树模型的学习。比如在下图中就是直接走默认的红色虚线的方向。

这个默认方向该怎么选呢?两边都试试,看看哪边带来的
L
s
p
i
l
t
L_{spilt}
Lspilt 更大,就选哪边。具体来说就是在节点分裂的时候,把缺失值或 0 元素样本先分到左边的节点计算下
L
s
p
i
l
t
L_{spilt}
Lspilt ,然后再分到右边的节点计算下
L
s
p
i
l
t
L_{spilt}
Lspilt ,选择大的那边作为默认方向。
对于一个正在分裂的节点来说,因为所选特征对应的稀疏样本其实都被当成了一类,所以在找最优分裂点的时候是不需要考虑稀疏值的,只考虑非稀疏值即可,从而减小了计算量,缩短了运算耗时。

作者做了一个稀疏数据的实验,用了稀疏感知算法,速度能够提升 50 倍左右。

5. 效率优化
5.1 分块并行
决策树学习过程中,最耗时的部分是分裂时对数据的反复排序。为了提高速度,XGBoost 采用了空间换时间的方法。对于一列特征,它创建了等量的指针,每个指针都跟一个特征值绑定,并指向对应样本,按照特征大小排序,把每一个特征的排好序的指针保存在块结构中,就实现了训练前对特征排序的目标,这样速度提升了,但是也因此需要额外空间存储指针。分条来说,块结构的设计有以下特点:
- 采用 CSC(Compressed Sparse Column Format)这种稀疏格式存储数据
- 存储的特征已排好序
- 存储了指向样本的指针,因为要存取一阶导和二阶导等信息
- 由于 CSC 是按列存储的,所以可以在每次分裂时对特征使用多线程并行计算

5.2 缓存感知(Cache-aware)访问
提出的块结构能够优化节点分裂的时间复杂度,但是在索引样本时,存在对内存的非连续访问问题。这是因为我们是按特征大小顺序对样本进行访问,但样本不按这个顺序。对内存的非连续访问将降低 CPU 的缓存命中率。XGBoost 针对精准贪心算法和近似算法设计了两种不同的优化策略。
对于精准贪心算法,采用缓存感知的预读取算法进行解决。在内存中开辟一个新的缓冲区(buffer),在 CPU 访问数据前,先把它要访问的数据存在这个缓冲区,把非连续的数据变成连续数据,这样就能提高 CPU 的缓存命中率,为 CPU 节省了一定的数据读取时间。
对于近似算法,包括加权分位数和稀疏感知这两种情况,通过降低块大小解决这一问题。缓存命中率低,一个原因是块太大了,没法全部存进缓存,如果把块的大小降到 CPU 缓存可以完全容纳的程度,就不会出现没命中了。但是块太小又会导致并行效率低。作者在尝试了多种块大小后,选择了最优的
2
16
2^{16}
216,每个块存储
2
16
2^{16}
216 个样本。实验结果如下图:

5.3 块的核外(Out-of-core)计算
当数据没办法被一次全部读入内存时,就需要用到核外计算方法,单开一个线程从硬盘上读取需要用到的数据,解决内存不够地问题。但是从硬盘读取数据相对于处理器来说是很慢的,所以 XGBoost 采用了两种方法平衡两者速度:
- 块压缩。对于行索引,用当前索引减去开始的块索引,前面提到块大小为 2 16 2^{16} 216 ,所以用 16 位的整数存储这个算出来的偏移,用这个偏移替代原先更占空间的索引。
- 块分片。把数据分开存储到不同的硬盘上,等用的时候多个硬盘一起开工,提高读取速度。
6. 补充
6.1 缺失值处理
对于存在某一维特征缺失的样本,xgb会尝试将其放到左子树计算一次增益,再放到右子树计算一次增益,对比放在左右子树增益的大小决定放在哪个子树。
6.2 防止过拟合
XGB 提出了两种防止过拟合的方法:
- 第一种称为Shrinkage,即学习率,在每次迭代一棵树的时候对每个叶子结点的权重乘上一个缩减系数,使每棵树的影响不会过大,并且给后面的树留下更大的空间优化。
- 另一个方法称为Column Subsampling,类似于随机森林选区部分特征值进行建树,其中又分为两个方式:
- 方式一按层随机采样,在对同一层结点分裂前,随机选取部分特征值进行遍历,计算信息增益;
- 方式二在建一棵树前随机采样部分特征值,然后这棵树的所有结点分裂都遍历这些特征值,计算信息增益。
参考
【1】https://blog.csdn.net/qq_18293213/article/details/123965029
【2】https://zhuanlan.zhihu.com/p/360060567
【3】XGBoost: A Scalable Tree Boosting System https://dl.acm.org/doi/10.1145/2939672.2939785

