
- 1【web3技术】什么是 WEB3?
- 2Ubuntu pycharm配置Conda环境
- 3项目经理必备的5种管理能力
- 4win电脑解析获取微信小程序源码(分包及具体操作)_xiaochengxu.exe
- 5API请求报错 Required request body is missing问题解决
- 6无代码自动化测试工具_applitools
- 7ESP8266安信可及正点原子最新AT固件(2.2.1.0)
- 8mac电脑使用谷歌浏览器,el-upload上传文件点击没反应_el-upload 点击无反应
- 9CSS基础:margin属性4种值类型,4个写法规则详解
- 10完美解决 fatal unable to access ‘httpsgithub.comxxxxxxxxxxx.git’ Recv failure Connection was reset_fatal: unable to access recv failure: connection w
大模型时代下的“金融业生物识别安全挑战”机遇
赞
踩
作者:中关村科金AI安全攻防实验室 冯月
金融行业正在面临着前所未有的安全挑战,人脸安全事件频发,国家高度重视并提出警告,全行业每年黑产欺诈涉及资金额超过1100亿元。冰山上是安全事件,冰山下隐藏的是“裸奔”的技术防御系统,快速发展的生成式算法平均每1.5天就有一个新的变种出现,而防御技术的迭代上线周期超过90天,零日漏洞风险敞口超过88.5天。
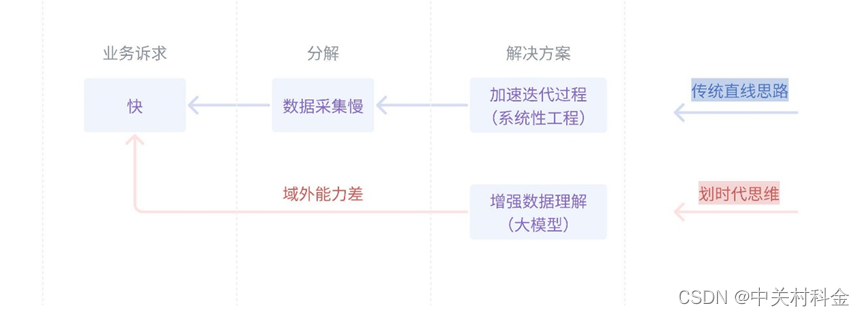
其中核心问题是攻击数据的严重不足,“引擎缺乏燃料”,现有防御方法跟不上攻击方法的演变速度,基于事件的专家防御体系强依赖于人工数据采集、标注、处理的流程,以扩大corner case规模,该过程占据了技术迭代更新过程中超过90%的时间成本。
行业迫切需要一个针对“零日漏洞”的“零日修复”方案缩小风险敞口,下一代防伪技术“金融领域的多模态防伪专有大模型”为此提供了一个新思路,大模型可以同时解决燃料和引擎问题,实现“tesla的跑车油改电”、“福特的汽车代马车”。中关村科金通过使用超过2PB的海量数据对大模型进行专项调优,增广基础攻击数据类型、激发模型“涌现”潜能,激活其域外识别能力,将识别数量级从1个9提升到3个9,大幅缩小漏洞风险敞口。大模型是跨时代的产物,是当下解决金融机构面临的生物识别“零日漏洞”频发危机的唯一可行路径。
人脸安全事件层出不穷,国家多部门发出紧急警告。
从具体事件来看,据媒体披露,2024年一家跨国公司香港分部的职员受“换脸、换声”技术欺骗,将2亿港元分别转账15次、转到5个本地银行账户内;2023年包头警方发布一起利用“换脸、换声”技术欺诈案例,福州市某科技公司法人代表郭先生10分钟内被骗430万元;2021年交通银行受到来自IP地址为中国台湾的犯罪分子攻击,7次通过了交通银行的人脸识别,6次通过活体检测。
从国家监管预警趋势看,公安部分两次于2020年、2022年向头部互联网服务机构发出预警,披露9种人脸安全风险;国家网信办于2021年、2023年发出警示,并要求各互联网机构提升人脸识别技术应用安全管理水平;国家金融管理中心,原中国银保监会,于2021年、2023年直接向金融机构下达指示,警惕利用AI新型技术实施诈骗、加强人脸识别技术应用安全管理。这只是冰山上的数字,如果我们下沉到海平面之下,深入到金融机构中,一家普通规模的金融机构一年就要面临超过1万次攻击;据联盟统计,全行业每年黑产欺诈涉及资金超1100亿元。
究其原因,金融是国民经济的血脉,也是被不法分子攻击的首要目标,可谓“野火烧不尽、春风吹又生”。
提升金融业技术防御水平已迫在眉睫,新攻击方法层出不穷,而金融机构科技建设严重滞后,形同“裸奔”。
从机构建设速度看,最快更新时间需要90天。据公开招标信息披露,过去2年间,以国股行为首的头部金融机构已经完成了一轮技术升级,但相较于上一次技术升级,间隔在3-5年;而在金融机构采买的服务中,最短的升级速度也在90天以上,更常见的是1年1次的更新服务。
从攻击方法的创新速度看,平均1.5天就有一种新攻击方法出现。国际顶会CVPR2023仅一年便发布超过130篇关于图像、人脸、声音的生成方法,2024年sora发布仅一周后,阿里便发布了EMO算法,精细的还原了一个人的声音、面部表情、口型、舌动;在应用市场中,新增注入攻击、换脸换声软件超过百余种,包括uface、趣换脸、insightface、Xpression等。
从作案工具易得性看,在地下交易市场中,攻击道具交易已颇具规模,通常200元就能买到一次定点攻击服务。金融行业的技术更新速度已经严重制约了金融安全防御体系的建设,零日漏洞(0-day)已经从操作系统、计算机网络下沉到了人工智能中,并深度影响着金融行业的健康发展,在新型攻势的88.5天(90-1.5)中,机构防御手段如同“裸奔”。
金融机构防御体系建设慢的核心问题是“攻击数据的有效性不足”。
这一方面是“吃不饱”导致的。攻击数据少是一个相对概念,是一种由认知偏差导致的数据的动态不足,而不是绝对数量的不足,“人不能知道自己不知道的东西(unconscious incompetence)”。防御方案需要针对攻击特点来设计,天然滞后于攻击的发生,这就带来了认知的客观时间差。金融机构的技术更新就是典型样例,防御升级通常围绕事件展开,如通过巡检、或者行业联盟共享的素材,而这些事件所提供的负样本数目非常少。这些数据是不足以支撑一次训练,也即无法提升专家模型的能力。因此,通常技术部门需要先对这些负样本(corner case)进行解析,分析其生成原理和特征,然后人工进行数据采集、数据标注、数据处理,最后用于训练,验证,最终完成技术升级,超过90%的时间成本被花在了数据的构建上,这也直接造成了机构“裸奔现象”。
更重要的,另一方面是“吸收少”导致的。从攻击数据到模型性能存在一个“能量转化率”,这是一种系统性能力不足,也可以比作“营养失调”、“肠胃差”。专家模型的认知方式与人有较大差异,从标注方式来看,专家模型训练数据真值(ground truth)是在采集前确定的,全部都有真值;人的训练数据是先对海量无标数据的归纳、然后通过极少数量的有标数据启发得来的。专家模型本身并不是拟合的“人的认知”,而是拟合的“特定攻击手法的作案特征”,这也就解释了为什么专家模型在针对同类攻击行为的检出上远高于人类,但对新攻击的识别远逊于人类。
业务目标是更快的补全漏洞,如果我们“头疼医头、脚痛医脚”只能陷入被动,解决吸收问题更重要。因此,我们迫切需要一种划时代的应用,一个胃口好、消化好的“铁胃”来解决“零日漏洞”频发危机。
一种”零日修复“方案、下一代防伪技术,“金融领域的多模态防伪专有大模型”提供了一个新思路。
更强的编码能力。谷歌在2018年提出了预训练模型,transformer技术崭露头角,基于transformer的BERT技术向我们证明了一切专家问题本质是编码问题,编码能力的提升直接影响着专家判断的准确性。
更强的数据承载能力。2020年,OpenAI发表了关于scaling laws的关键论文,并在2022年GPT3.0上证明了超大规模的数据可以产生“知识涌现”现象,如今大模型规模已经突破100B。
“好胃口+好消化=超强的域外推理能力”,大模型增强了对没见过问题的处理能力。2023年,google发布多模态大模型Gemini,中关村科金对其进行了防伪能力的专项测试,发现其不仅可以指出图片的真假,甚至可以讲出图片假在什么地方,如纹理、毛发、环境、一致性等。尽管此时的通用大模型能力还不如专有大模型,但我们快速将大模型引入了防伪体系建设中,我们在超过4亿规模的真人图像、音频样本数据集上,通过“基于超过100种基础伪造攻击算法实现的万倍数据增广方案”最终将数据集扩大到2PB。经过测试,“金融领域的多模态防伪专有大模型”相较于“传统专家模型”能力有显著提升,以针对“对抗样本攻击”的防御为例,我们将防御指标从1个9(90%),提升到了3个9(99.9%),大幅缩小漏洞风险敞口。
大模型是跨时代的产物,是当下解决金融机构面临的生物识别“零日漏洞”频发危机的唯一可行路径。

