
- 1FPGA实现 TCP/IP 协议栈 服务器 纯VHDL代码编写 提供4套vivado工程源码和技术支持_9527华安 csdn
- 2Git操作 --忽略文件_git忽略文件
- 3基于STM32F103ZET6单片机智能服药药盒开关语音无线设计23-070_stm32f103zet6闹钟
- 4java企业员工管理系统_员工管理系统idea
- 5MATLAB算法实战应用案例精讲-【自动驾驶】路径规划_matlab 路径规划
- 6Opencv | 基于ndarray的基本操作
- 7Docker overview_docker start --checkpoint looper2 looper2
- 8解决maven构建时警告:The artifact xxx has been relocated to xxx_the artifact mysql:mysql-connector-java:jar:8.0.33
- 9头歌educoder-Python程序设计-第四阶段 函数与模块-模块_要求判断是否存在两个整数,它们的和为a,积为b
- 10Android Camera开发入门(4):USB/UVC Camera的使用_android usb camera
机器学习之K-means聚类算法_kmeans聚类算法的特点
赞
踩
一、机器学习中两大类问题
一个是分类,一个是聚类。
- 分类是监督学习,原始数据有标签,可以根据原始数据建立模型,确定新来的数据属于哪一类。
- 聚类是一种无监督学习,聚类是指事先没有“标签”,在数据中发现数据对象之间的关系,将数据进行分组,一个分组也叫做“一个簇”, 组内的相似性越大,组间的差别越大,则聚类效果越好,也就是簇内对象有较高的相似度,簇之间的对象相似度比较低,则聚类效果越好。
K-means聚类算法中K表示将数据聚类成K个簇,means表示每个聚类中数据的均值作为该簇的中心,也称为质心。K-means聚类试图将相似的对象归为同一个簇,将不相似的对象归为不同簇,这里需要一种对数据衡量相似度的计算方法,K-means算法是典型的基于距离的聚类算法,采用距离作为相似度的评价指标,默认以欧式距离作为相似度测度,即两个对象的距离越近,其相似度就越大。
聚类和分类最大的不同在于,分类的目标是事先已知的,而聚类则不一样,聚类事先不知道目标变量是什么,类别没有像分类那样被预先定义出来,也就是聚类分组不需要提前被告知所划分的组应该是什么样的,因为我们甚至可能都不知道我们再寻找什么,所以聚类是用于知识发现而不是预测,所以,聚类有时也叫无监督学习。

二、K-means过程原理
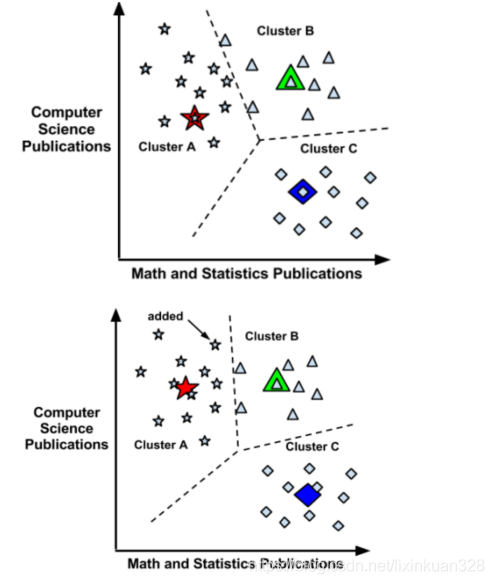
假设有一批关于计算机科学和数学统计相关的人才,这批人才中计算机人才、机器学习人才、数学人才三类,那么该如何将这批数据进行聚类?

我们可以直观的感觉到应该如下分类:

但问题是计算机不会直观的去观察数据,首先将这批数据向量化,K-means聚类会随机在这些点中找到三个点,然后计算所有的样本到当前三个点的距离大小,判断样本点与当前三个点哪个距离比较近,当前样本就属于那个类。

当经过一次计算之后,就是经过了一次迭代过程,当完成一次迭代后,就分出来是三个类别(簇),每个类别中都有质心。然后进行下一次迭代,继续计算所有点到三个类别中心点的距离,按照每个样本点与哪个质心距离最近就属于哪个簇,以此类推,继续迭代。当本次计算的中心点的距离较上次计算的中心点的位置不再变化,那么停止迭代。
三、肘部法
K值的选择一般可以根据问题的内容来确定,也可以根据肘部法来确定。如图:横轴表示K值的选择,纵轴表示对应的K值下所有聚类的平均畸变程度。

每个类的畸变程度是每个类别下每个样本到质心的位置距离的平方和。类内部成员越是紧凑,那么类的畸变程度越低,这个类内部相似性越大,聚类也就越好。如图,在k=1请况下,相比k=2情况下,类的平均畸变程度变化大,说明,k=2的情况类的紧凑程度比k=1情况下要紧凑的多。同理,发现当k=3之后,随着k的增大,类的平均畸变程度变化不大,说明k=3是比较好的k值。k>3后类的平均畸变程度变化不大,聚类的个数越多,有可能类与类之间的相似度越大,类的内部反而没有相似度,这种聚类也是不好的。举个极端的例子,有1000个数据,分成1000个类,那么类的平均畸变程度是0,那么每个数据都是一类,类与类之间的相似度大,类内部没有相似性。
K-means算法的思想就是对空间K个点为中心进行聚类,对靠近他们的对象进行归类,通过迭代的方法,逐次更新聚类中心(质心)的值,直到得到最好的聚类结果。K-means过程:
- 首先选择k个类别的中心点
- 对任意一个样本,求其到各类中心的距离,将该样本归到距离最短的中心所在的类
- 聚好类后,重新计算每个聚类的中心点位置
- 重复2,3步骤迭代,直到k个类中心点的位置不变,或者达到一定的迭代次数,则迭代结束,否则继续迭代
四、K-means++算法
K-means算法假设聚类为3类,开始选取每个类的中心点的时候是随机选取,有可能三个点选取的位置非常近,导致后面每次聚类重新求各类中心的迭代次数增加。K-means++在选取第一个聚类中心点的时候也是随机选取,当选取第二个中心点的时候,距离当前已经选择的聚类中心点的距离越远的点会有更高的概率被选中,假设已经选取n个点,当选取第n+1个聚类中心时,距离当前n个聚类中心点越远的点越会被选中,这种思想是聚类中心的点离的越远越好,这样就大大降低的找到最终聚类各个中心点的迭代次数,提高了效率。
五、K-means最邻近算法案例(1)
- # encoding:utf-8
-
- import numpy as np
-
-
- # 将每行数据放入一个数组内列表,返回一个二维列表
-
- def loadDataSet(fileName):
- # 创建空列表
- dataMat = []
- fr = open(fileName, "rb")
- for line in fr.readlines():
- # 按照制表符切割每行,返回一个列表list
- curLine = line.decode("utf-8").strip().split('\t')
- # 将切分后的每个列表中的元素,以float形式返回,map()内置函数,返回一个map object【注意,在python2.7版本中map直接返回list】,这里需要再包装个list
- fltLine = list(map(float, curLine))
- dataMat.append(fltLine)
- return dataMat
-
-
- # 两点欧式距离
- def distEclud(vecA, vecB):
- # np.power(x1,x2) 对x1中的每个元素求x2次方,不会改变x1。
- return np.sqrt(np.sum(np.power(vecA - vecB, 2)))
-
-
- # 随机找到3个中心点的位置坐标,返回一个3*2的矩阵
- def randCent(dataSet, k):
- # 返回dataSet列数,2列
- n = np.shape(dataSet)[1]
- '''
- centerids是一个3*2的矩阵,用于存储三个中心点的坐标
- '''
- centerids = np.mat(np.zeros((k, n)))
- for j in range(n):
- # 统计每一列的最小值
- minJ = min(dataSet[:, j])
- # 每列最大值与最小值的差值
- rangeJ = float(max(dataSet[:, j]) - minJ)
- # np.random.rand(k,1) 产生k行1列的数组,里面的数据是0~1的浮点型 随机数。
- array2 = minJ + rangeJ * np.random.rand(k, 1)
- # 转换成k*1矩阵 赋值给centerids
- centerids[:, j] = np.mat(array2)
- return centerids
-
-
- def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
- # 计算矩阵所有 行数 m=80
- m = np.shape(dataSet)[0]
- # zeros((m,2)) 创建一个80行,2列的二维数组
- # numpy.mat 将二维数组转换成矩阵 【类别号,当前点到类别号中心点的距离】
- clusterAssment = np.mat(np.zeros((m, 2)))
- # createCent找到K个随机中心点坐标
- centerids = createCent(dataSet, k)
- # print centerids
- clusterChanged = True
- while clusterChanged:
- clusterChanged = False
- # 遍历80个数据到每个中心点的距离
- for i in range(m):
- # np.inf float的最大值,无穷大
- minDist = np.inf
- # 当前点属于的类别号
- minIndex = -1
- # 每个样本点到三个中心点的距离
- for j in range(k):
- # x = centerids[j,:]
- # print x
- # 返回两点距离的值
- distJI = distMeas(centerids[j, :], dataSet[i, :])
- if distJI < minDist:
- # 当前最小距离的值
- minDist = distJI
- # 当前最小值属于哪个聚类
- minIndex = j
- # 有与上次迭代计算的当前点的类别不相同的点
- if clusterAssment[i, 0] != minIndex:
- clusterChanged = True
- # 将当前点的类别号和最小距离 赋值给clusterAssment的一行
- clusterAssment[i, :] = minIndex, minDist
- for cent in range(k):
- # array = clusterAssment[:,0].A==cent
- # result = np.nonzero(clusterAssment[:,0].A==cent)[0]
- # clusterAssment[:,0].A 将0列 也就是类别号转换成数组
- # clusterAssment[:,0].A==cent 返回的是一列,列中各个元素是 True或者False,True代表的是当前遍历的cent类别
- # np.nonzero(clusterAssment[:,0].A==cent) 返回数组中值不为False的元素对应的行号下标数组 和列号下标数组
- # currNewCenter 取出的是对应是当前遍历cent类别的 所有行数据组成的一个矩阵
- currNewCenter = dataSet[np.nonzero(clusterAssment[:, 0].A == cent)[0]]
- # numpy.mean 计算矩阵的均值,axis=0计算每列的均值,axis=1计算每行的均值。
- # 这里是每经过一次while计算都会重新找到各个类别中中心点坐标的位置 ,axis = 0 是各个列求均值
- centerids[cent, :] = np.mean(currNewCenter, axis=0)
- # 返回 【 当前三个中心点的坐标】 【每个点的类别号,和到当前中心点的最小距离】
- return centerids, clusterAssment
-
-
- if __name__ == '__main__':
- # numpy.mat 将数据转换成80*2的矩阵
- dataMat = np.mat(loadDataSet('./testSet.txt'))
- k = 3
- # centerids 三个中心点的坐标。clusterAssment 每个点的类别号|到当前中心点的最小距离
- centerids, clusterAssment = kMeans(dataMat, k, distMeas=distEclud, createCent=randCent)
- print(centerids)
- print(clusterAssment)

测试结果:
- C:\ProgramData\Anaconda3\python.exe "C:\Program Files\JetBrains\PyCharm 2018.3.4\helpers\pydev\pydevd.py" --multiproc --qt-support=auto --client 127.0.0.1 --port 9468 --file I:/11_python/Pythonscikit-learn/com/bjsxt/kmeans/KMeansOnHand.py
- pydev debugger: process 8776 is connecting
-
- Connected to pydev debugger (build 183.5429.31)
- [[-0.83188333 -2.97988206]
- [ 2.95373358 2.32801413]
- [-2.46154315 2.78737555]]
- [[1. 2.34663587]
- [2. 1.17900336]
- [1. 3.95705319]
- [0. 4.56386331]
- [1. 2.06889695]
- [2. 1.67362246]
- [0. 1.32238441]
- [0. 2.93706604]
- [1. 0.78660783]
- ...
- [2. 0.44855365]
- [1. 5.18275042]
- [0. 2.129816 ]
- [1. 0.71880419]
- [2. 0.50980516]
- [1. 4.36787692]
- [0. 4.07426381]]
-
- Process finished with exit code 0
六、K-means最邻近算法案例(2)
- # coding:utf-8
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.cluster import KMeans
- from sklearn.datasets import make_blobs
-
- # 建立12*12英寸 新的图像
- plt.figure(figsize=(12, 12))
- n_samples = 1500
- random_state = 170
- '''
- make_blobs函数是为聚类产生数据集 , 产生一个数据集和相应的标签
- n_samples:表示数据样本点个数,默认值100
- n_features:表示数据的维度,特征,默认值是2
- centers:产生数据的中心点,默认值3个
- shuffle :洗乱,默认值是True
- random_state:官网解释是随机生成器的种子
- '''
- # x返回的是向量化的数据点,y返回的是对应数据的类别号
- x, y = make_blobs(n_samples=n_samples, random_state=random_state)
- print('x=', x, type(x), 'y=', y, type(y))
- # 使用KMeans去聚类,返回聚好的类别集合, n_clusters聚合成几类
- y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(x)
- print("y_pred : ", y_pred)
- # subplot 绘制多个子图,221 等价于2,2,1 表示两行两列的子图中的第一个
- plt.subplot(221)
- # scatter 绘制散点图 ,c 指定颜色
- plt.scatter(x[:, 0], x[:, 1], c=y_pred)
- plt.title("kmeans01")
-
- transformation = [[0.60834549, -0.63667341],
- [-0.40887718, 0.85253229]]
- # numpy.dot 矩阵相乘
- # a1= [[1,2]
- # [3,4]
- # [5,6]]
- # a2= [[10,20]
- # [30,40]]
- # a1*a2 = [[1*10+2*30,1*20+2*40]
- # [3*10+4*30,3*20+4*40]
- # [5*10+5*30,6*20+6*40]
- # ]
- X_aniso = np.dot(x, transformation)
- y_pred = KMeans(n_clusters=3).fit_predict(X_aniso)
- plt.subplot(222)
- # s 设置点的大小,s=8
- plt.scatter(X_aniso[:, 0], X_aniso[:, 1], c=y_pred)
- plt.title("kmeans02")
-
- # vstack 是合并矩阵,将y=0类别的取出500行,y=1类别的取出100行,y=2类别的取出10行
- X_filtered = np.vstack((x[y == 0][:500], x[y == 1][:100], x[y == 2][:200]))
- y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_filtered)
- plt.subplot(223)
- plt.scatter(X_filtered[:, 0], X_filtered[:, 1], c=y_pred)
- plt.title("kmeans03")
-
- dataMat = []
- fr = open("testSet.txt", "rb")
- for line in fr.readlines():
- if line.decode("utf-8").strip() != "":
- curLine = line.decode("utf-8").strip().split('\t')
- fltLine = list(map(float, curLine))
- dataMat.append(fltLine)
- dataMat = np.array(dataMat)
- # 调用Scikitlearn中的KMeans
- # KMeans 中参数 init='k-means++' 默认就是k-means++ 如果设置为'random'是随机找中心点
- y_pred = KMeans(n_clusters=6).fit_predict(dataMat)
- plt.subplot(224)
- plt.scatter(dataMat[:, 0], dataMat[:, 1], c=y_pred)
- plt.title("kmeans04")
- plt.savefig("./kmeans.png")
- plt.show()
测试结果:
- C:\ProgramData\Anaconda3\python.exe I:/11_python/Pythonscikit-learn/com/bjsxt/kmeans/KMeansByScikitlearn.py
- x= [[-5.19811282e+00 6.41869316e-01]
- [-5.75229538e+00 4.18627111e-01]
- [-1.08448984e+01 -7.55352273e+00]
- ...
- [ 1.36105255e+00 -9.07491863e-01]
- [-3.54141108e-01 7.12241630e-01]
- [ 1.88577252e+00 1.41185693e-03]] <class 'numpy.ndarray'> y= [1 1 0 ... 2 2 2] <class 'numpy.ndarray'>
- y_pred : [2 2 1 ... 0 0 0]


