
- 1浅谈软件测试工程师
- 2失物招领|基于Web的校园失物招领系统的设计与实现
- 3CSRF漏洞攻击原理及防御方案_csrf攻击原理与解决方法
- 4微信小程序设置字体上下左右居中_微信小程序字左
- 5c语言斐波那契数列12,小朋友学C语言(12):斐波那契数列和递归
- 6Kafka在Windows上的安装_windows安装kafka教程
- 7标注工具——Label Studio安装与简单使用
- 8双向链表的插入删除操作_双向链表的删除操作
- 9[Solved] Can not extract resource from com.android.aaptcompiler
- 10java项目之固定资产管理系统(源码+文档)_java资产管理系统
春节放大招,阿里通义千问Qwen1.5开源发布_qwen1.5 git
赞
踩
2月6日·阿里发布了通义千问1.5版本,包含6个大小的模型,“Qwen” 指的是基础语言模型,而 “Qwen-Chat” 则指的是通过后训练技术如SFT(有监督微调)和RLHF(强化学习人类反馈)训练的聊天模型。
模型概览
在此次Qwen1.5版本中,我们开源了包括0.5B、1.8B、4B、7B、14B和72B在内的6个不同规模的Base和Chat模型,并一如既往地放出了各规模对应的量化模型。
以下是此次更新的一些重点:
- 支持 32K 上下文长度;
- 开放了 Base + Chat 模型的 checkpoint;
- 可与 Transformers 一起本地运行;
- 同时发布了 GPTQ Int-4 / Int8、AWQ 和 GGUF 权重。
性能评测基础能力Qwen1.5在多项基准测试中均展现出优异的性能。无论是在语言理解、代码生成、推理能力,还是在多语言处理和人类偏好对产等方面。
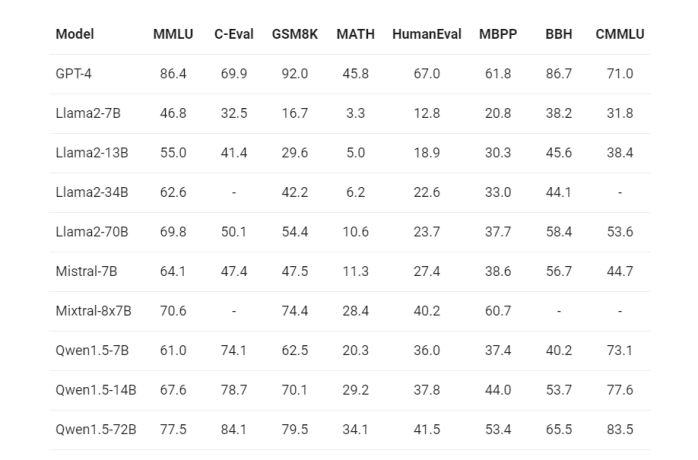
Qwen1.5-72B 在所有基准测试中都远远超越了Llama2-70B,展示了其在语言理解、推理和数学方面的卓越能力。
多语言能力 挑选来自欧洲、东亚和东南亚的12种不同语言,全面评估Base模型的多语言能力 Qwen1.5 Base模型在12种不同语言的多语言能力方面表现出色,在考试、理解、翻译和数学等各个维度的评估中,均展现优异结,可用于翻译、语言理解和多语言聊天等下游应用。
人类偏好对齐 尽管落后于 GPT-4-Turbo,但最大的 Qwen1.5 模型 Qwen1.5-72B-Chat 在 MT-Bench 和 Alpaca-Eval v2 上都表现出不俗的效果,超过了 Claude-2.1、GPT-3.5-Turbo-0613、Mixtral-8x7b-instruct 和 TULU 2 DPO 70B,与 Mistral Medium 不相上下。
使用Qwen1.5开发
在于 Qwen1.5 与 HuggingFace transformers 代码库的集成。从 4.37.0 版本开始,您可以直接使用 transformers 库原生代码,而不加载任何自定义代码(指定trust_remote_code选项)来使用 Qwen1.5,像下面这样加载模型:
from transformers import AutoModelForCausalLM# This is what we previously usedmodel = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True)# This is what you can use nowmodel=AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-7B-Chat",device_map="auto")
项目地址 GitHub:https://github.com/QwenLM/Qwen1.5

