
- 1Object Detection--RCNN,SPPNet,Fast RCNN,FasterRCNN论文详解
- 2程序员的一生:本科程序员和专科程序员差距大吗_本科c语言和专科c语言一样吗
- 3关于我司在上海物联网行业协会展厅展示项目案例
- 4SQL语言与SQL在线实验工具的使用【修订版】_sql语句在线测试工具
- 5flask接口请求频率限制_python中的flask接口 调用频率
- 6OpenCV 报错:FFMPEG: tag 0x34363258/‘X264‘ is not supported with codec id 27 and format ‘mp4 / MP4‘_opencv: ffmpeg: tag 0x34363248/'h264' is not suppo
- 7jqgrid学习笔记_using events example
- 8本地修改host文件解决github打不开的问题(最新版本亲测有效)_github hosts最新
- 9利用STM32F103单片机输出SPWM波_改变spwm波的占空比
- 10数据库系统头歌实验一 SQL的DDL语言和单表查询_在users表中新增一个用户,user_id为2019100904学号,name为'2019-物联网
海量数据处理数据结构之Hash与布隆过滤器_布隆过滤器hash函数
赞
踩
前言
随着网络和大数据时代的到来,我们如何从海量的数据中找到我们需要的数据就成为计算机技术中不可获取的一门技术,特别是近年来抖音,快手等热门短视频的兴起,我们如何设计算法来从大量的视频中获取当前最热门的视频信息呢,这就是我们今天即将谈到的Hash和布隆过滤器。以下是Hash和布隆过滤器的一些常见应用:
- 使用word文档时,如何判断某个单词是否拼写正确?
- 网络爬虫程序时,怎么让它不去爬相同的url页面(将已经爬过的url页面放到数据库中)
- 垃圾邮件过滤算法如何设计?(当多少人将同一封邮件视为垃圾邮件时,就放到数据库中,当其他人在收到相同的邮件时,直接放到垃圾邮箱中)
- 数据库缓存穿透问题如何解决?(对于redis和数据库中都不存在的数据,在服务器端使用布隆过滤器进行过滤掉,如果服务器的布隆过滤器没有过滤掉,则说明数据库可能存在,对于误判的情况,即不存在的数据判断为存在,则在redis中保存为<key,null>,这样就可以防止数据库不存在的数据对应的数据时,就不会去访问数据库了,后面还会提到,这里先提前说明下)
背景
假如我们需要从海量数据中查询某个字符串是否存在?如果让你设计一种数据结构,你会想到哪些数据结构呢?链表和数组(直接排除,查询复杂度为0(n)),二叉树(红黑树,AVL树,时间复杂度o(log(n)),可以考虑),平衡多叉树(B树,B+树等,时间复杂度为h.log(n),其中h为树的层高),Hash(时间复杂度为O(1)),下面分别介绍这些数据结构
平衡二叉树
增删改查时间复杂度为O(logn) :比如100万个节点,最多比较 20 次;10 亿个节点,最多比较 30 次;
平衡的目的时保证二叉树的左右节点的高度都差不多,这样二叉树才能保证时间复杂度为O(logn),否则最坏的情况,二叉树的时间复杂度为O(n),退化为线性表,插入数据的时候时按顺序插入的。
平衡二叉树是中序遍历有序(左子树的key<根节点的key<右子树的key),每次比较都能保证到左子树或者右子树,每次都能排除一半的元素达到快速索引的目的.元素的比较是使用的二分查找(每次搜索都能排除一半),使用到二分查找的结构如下图所示:
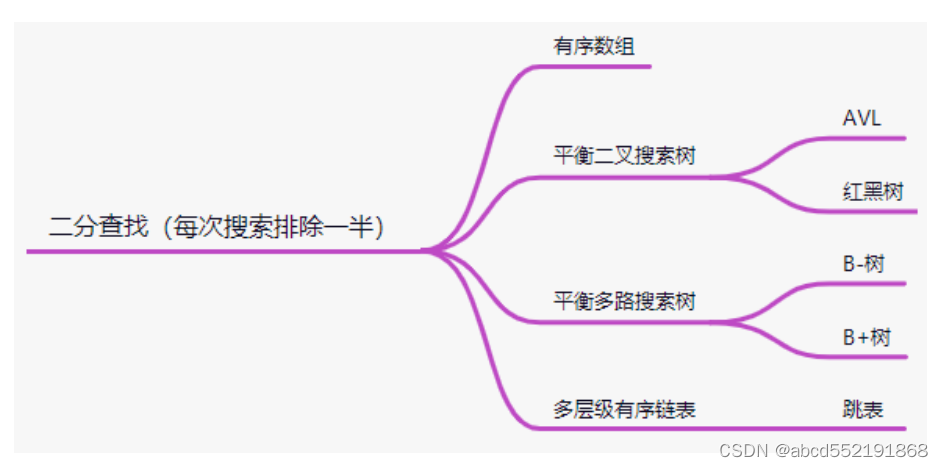
有序数组和平衡二叉搜索树使用二分查找无可厚非,对于B树和B+树而言,其实跟平衡二叉搜索树类似,只是B树的一个节点有多个KEY,每个节点有多个孩子,每个节点内的KEY都是有序的。因此在查找KEY位于哪个节点时,也使用到了二分查找,关于跳表的数据结构请参考其他博客。
如果对平衡二叉树和平衡多叉树有兴趣的同学,可以参考我的博客
1.B树和B+树的分析和实现
2.红黑树的分析与实现
散列表
前面提到的平衡二叉树的时间复杂度为O(log(n)),效率还是蛮高的,不过对于像字符串作为的key时而进行比较时,还是比较耗时的,因此有没有一种更高效的算法来完成字符串的比较呢,那就是使用散列表来完成,散列表是使用hash函数将一个key映射到一个数据表中,这样在没有冲突的情况下,根本不需要字符串的比较,只要在查询的时候,如果相应的key映射的下标中存在元素,即可完成数据的查询。
散列表是根据key计算key在表中的位置的数据结构,是 key 和其所在存储地址的映射关系;在插入数据时,需要将散列表的节点中的key和value一起存储到表中。 为什么需要存储key,这时因为在查询时,需要将查询的key和表中的key进行比较,看是否相等,如果不等,则代表这次查询失败(不等,则代表存在哈希冲突,表中的这个位置被其他key所拥有)
hash函数
映射函数 Hash(key)=addr ;hash 函数可能会把两个或两个以上的不同 key 映射到同一地址,这种情况称之为冲突(或者 hash 碰撞);由于存在冲突情况,因此在选择hash函数时,需要满足以下2个条件,这样才能保证冲突的概率最小化和查询效率。
- 计算速度快(满足查询效率)
- 强随机分布(等概率、均匀地分布在整个地址空间),这样才能保证hash冲突的概率最小化
通常常用的哈希函数有:murmurhash1,murmurhash2,murmurhash3,siphash(redis6.0当中使⽤,rust等大多数语言选用的hash算法来实现hashmap),cityhash 都具备强随机分布性;测试地址如下:https://github.com/aappleby/smhasher,siphash主要 解决了字符串接近的强随机分布性,作为redis的hash算法时因为,在redis中,经常使用uid:1000和uid:1001这样的key,这2个key很接近,如果使用其他的算法,很可能都映射到同一个地址,而siphash却可以让这2个key映射到不同的地址。
负载因子
数组存储元素的个数 / 数据长度;用来形容散列表的存储密度;负载因子越小,冲突越小,负载因子越大,冲突越大;
冲突处理
不管如何优秀的hash算法,都不可避免的让不同的key映射到同一个地址,那么如何处理这样的情况,即如何处理hash冲突呢。主要有链表法和开发寻址法
链表法
引用链表来处理哈希冲突;也就是将冲突元素用链表链接起来;这也是常用的处理冲突的⽅
式;但是可能出现一种极端情况,冲突元素比较多,该冲突链表过长,这个时候可以将这个
链表转换为红黑树;由原来链表时间复杂度 转换为红黑树时间复杂度 ;那么判断该链表过长的依据是多少?可以采⽤超过 256(经验值)个节点的时候将链表结构转换为红黑树结构;
开放寻址法
将所有的元素都存放在哈希表的数组中,不使用额外的数据结构;一般使用线性探查的思路
解决;
- 当插入新元素的时,使用哈希函数在哈希表中定位元素位置;
- 检查数组中该槽位索引是否存在元素。如果该槽位为空,则插⼊,否则3;
- 在 2 检测的槽位索引上加一定步长接着检查2; 加⼀定步长分为以下几种:
- i+1,i+2,i+3,i+4, … ,i+n
- i- ,i+ ,i- ,1+ , … 这两种都会导致同类 hash 聚集;也就是近似值它的hash
值也近似,那么它的数组槽位也靠近,形成 hash 聚集;第一种同类聚集冲突在
前,第二种只是将聚集冲突延后; 另外还可以使用双重哈希来解决上面出现hash
聚集现象:在.net HashTable类的hash函数Hk定义如下:
Hk(key) = [GetHash(key) + k * (1 + (((GetHash(key) >> 5)
+ 1) %(hashsize – 1)))] % hashsize
- 1
- 2
在此 (1 + (((GetHash(key) >> 5) + 1) % (hashsize – 1))) 与 hashsize互为素数(两数互为素数表示两者没有共同的质因⼦);执⾏了 hashsize 次探查后,哈希表中的每⼀个位置都有且只有⼀次被访问到,也就是说,对于给定的 key,对哈希表中的同⼀位置不会同时使⽤ Hi 和 Hj;
布隆过滤器
既然hash的查询效率已经达到了O(1),效率已经达到了常数,那么我们需要从海量数据中(比如10亿条)查询某个字符串是否存在时是否可以使用hash来完成查询呢,其实是不可以的,虽然hash查询效率很高,也不需要比较字符串,但是需要将字符串存储到内存中,那么多条数据的字符串key存储到内存中是不现实的,那么是否有不需要字符串key的数据结构就能知道相应的元素是否存在呢?布隆过滤器的出现就是解决这个问题的。
布隆过滤器结构说明
布隆过滤器是一种概率型数据结构,它的特点是高效地插入和查询,能确定某个字符串一定不存在或者可能存在(即存在一定的误差,本来字符串key不存在,却被视为字符串存在);
布隆过滤器不存储具体数据,所以占用空间小,查询结果存在误差,但是误差可控,同时不支持删除操作;
位图操作
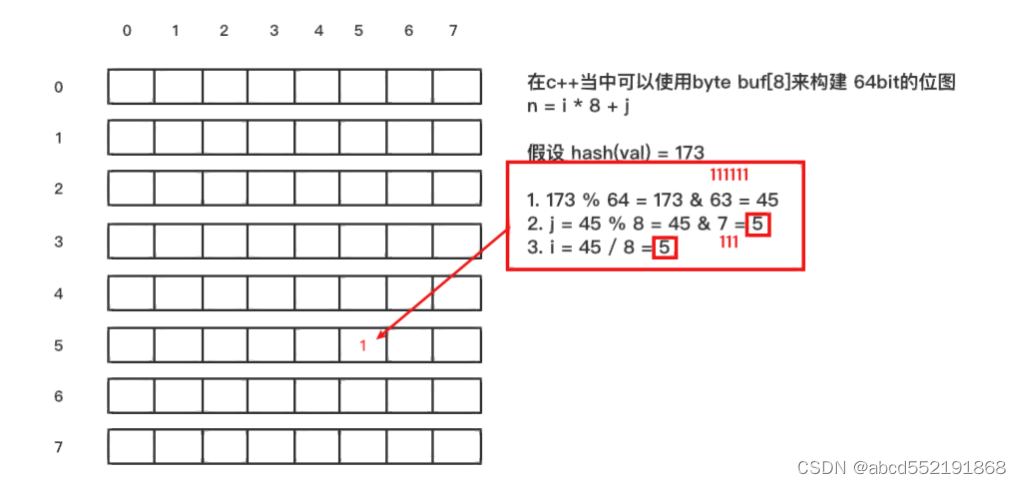
在说明布隆过滤器如何实现之前,先来了解一下,如何采用一个算法将一个字符串key映射到位图中的某一位中。比如我们有一个8 * 8 的位图,另有一个字符串val(假如为"thestringkey"),采用上面或者任意的一种hash算法,比如得到 hash(val) = 173,那么如何将hash值173映射到
下面的二维位图中呢
布隆过滤器原理
了解玩位图操作之后,就很容易理解布隆过滤器原理了。
当一个元素加入位图时,通过 k 个 hash 函数将这个元素映射到位图的 k 个点,并把它们置为 1;当检索时,再通过 k 个 hash 函数运算检测位图的 k 个点是否都为 1;如果有不为 1 的点,那么认为该 key 不存在;如果全部为 1,则可能存在**(这些1可能是由其他key映射的,这也是布隆过滤器存在误差的原因,什么时候使用布隆过滤器呢,在应用场景里面以缓存穿透来进行说明)**;
为什么不支持删除操作?
在位图中每个槽位只有两种状态(0 或者 1),一个槽位被设置为 1 状态,但不确定它被设
置了多少次;也就是不知道被多少个 key 哈希映射而来以及是被具体哪个 hash 函数映射而
来;
应用场景
布隆过滤器通常用于判断某个key一定不存在的场景,同时运行判断存在时有误差的情况;
常见处理场景:(1)缓存穿透的解决 (2)热key限流
下图是解决缓存穿透的解决方案
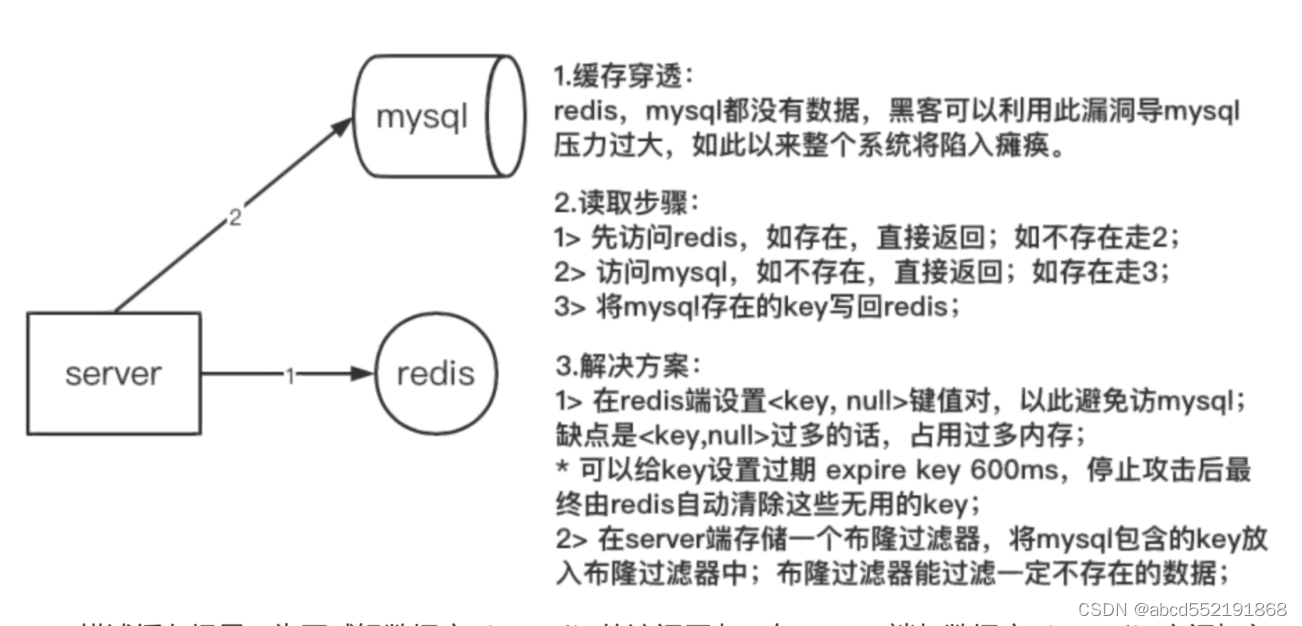
通常,redis的引入是为了减轻数据库(mysql)的访问压力,服务器首先访问redis,如果redis不存在对应的数据,则再去访问数据库,然后再把数据库访问到的数据写入到redis缓存中,但是如果访问的key在redis和数据库中都不存在,那么最终就会去频繁访问数据库,如果产生这样的情况,我们就认为,redis是没有什么作用的,最终的访问都涌向了数据库,这就是缓存穿透。
黑客就是利用数据库不存在的key去频繁访问数据库,导致其他正常用户无法访问数据库。为了解决这个问题,我们在服务器端生成一个布隆过滤器,我们提前将数据库存在的key插入到布隆过滤器中,当黑客频繁的使用不存在的key去访问数据库时,就会直接被布隆过滤器过滤掉。即使黑客频繁使用存在的key去访问,也会从redis直接返回,而不会影响数据库。但是通常在服务器端也应该做一个逻辑,不应该让一个用户使用同一个key去访问redis和数据库很多次。
应用分析
在实际应用中,该选择多少个 hash 函数?要分配多少空间的位图?预期存储多少元素?如何控制误差?
公式如下:
n -- 预期布隆过滤器中元素的个数,如上图 只有str1和str2 两个元素 那么 n=2
p -- 假阳率(误判的概率,不存在却当做存在的概率),在0-1之间
m -- 位图所占空间
k -- hash函数的个数
公式如下:
n = ceil(m / (-k / log(1 - exp(log(p) / k))))
p = pow(1 - exp(-k / (m / n)), k)
m = ceil((n * log(p)) / log(1 / pow(2, log(2))));
k = round((m / n) * log(2));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
根据公式,只要告知了任意2个属性,都能求出任意2个值。
它们之间的关系如下
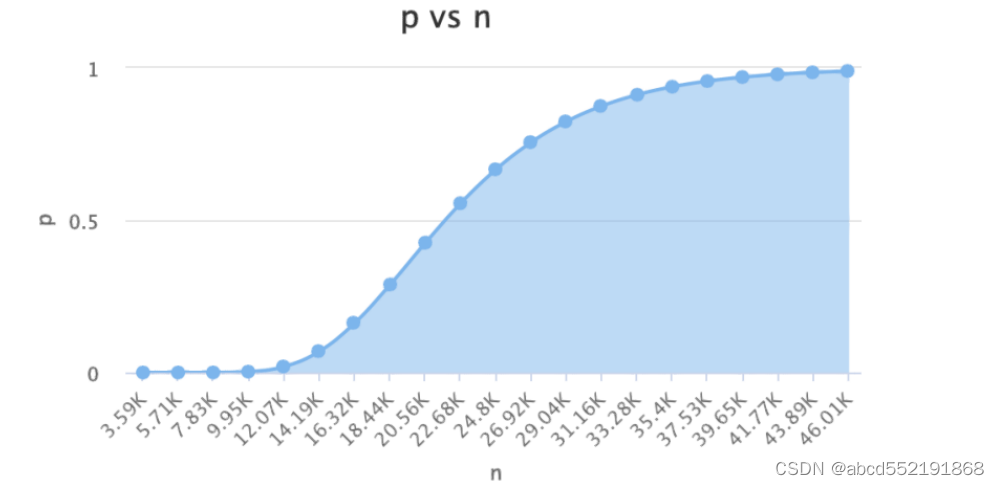
随着预期布隆过滤器中元素的个数的增加,假阳率越来越大,并最终趋于1
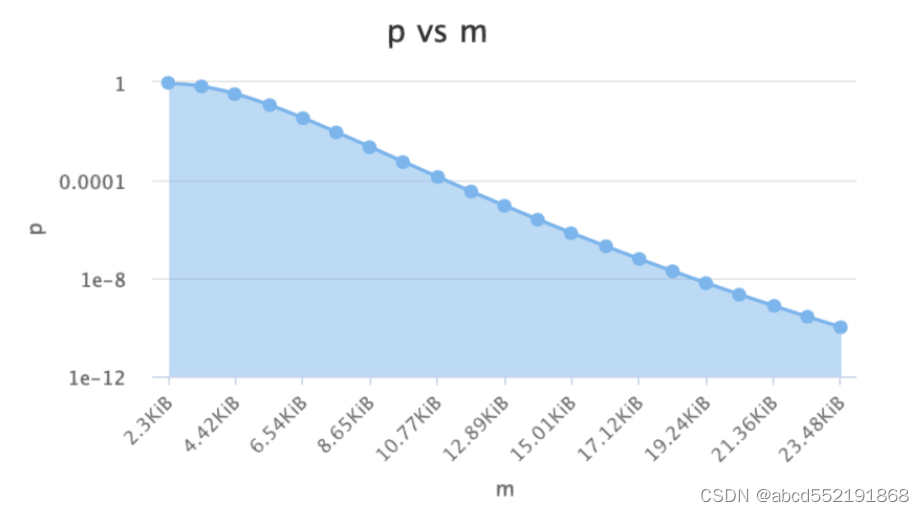
随着位图空间的增加,假阳率越来越小。
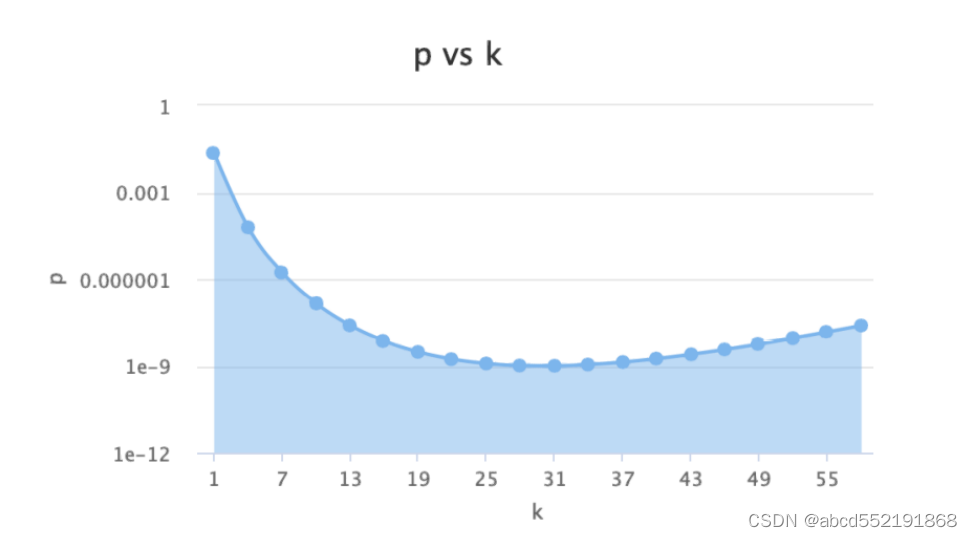
上图显示了哈希函数的个数和假阳率的关系,在哈希 函数没有超过31个的时候,假阳率越来越小,但是超过31的时候,假阳率越缓慢上升。具体的原因只需要了解31是质数,hash 随机分布性是最好的;
在实际使用布隆过滤器时,首先需要确定 n 和 p,通过上面的运算得出 m 和 k;通常可以在下面这个网站上选出合适的值:布隆过滤器的4个值的关系
构造哈希函数
一般情况下,确定个哈希函数的个数,就需要构造哈希函数,布隆过滤器通常需要选择多个哈希函数,那么我们不可能一个一个的去构造哈希函数,我们可以使用以下方法进行构造
#define MIX_UINT64(v) ((uint32_t)((v>>32)^(v)))
uint64_t hash1 = MurmurHash2_x64(key, len, Seed);
uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1));
for (i = 0; i < k; i++) // k 是hash函数的个数
{
Pos[i] = (hash1 + i*hash2) % m; // m 是位图的⼤⼩
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
其中k是哈希函数的个数,Pos[i]就是构造的每个哈希函数。
布隆过滤器代码
实现代码
#ifndef __MICRO_BLOOMFILTER_H__ #define __MICRO_BLOOMFILTER_H__ /** * * 仿照Cassandra中的BloomFilter实现,Hash选用MurmurHash2,通过双重散列公式生成散列函数,参考:http://hur.st/bloomfilter * Hash(key, i) = (H1(key) + i * H2(key)) % m * **/ #include <stdio.h> #include <stdlib.h> #include <stdint.h> #include <string.h> #include <math.h> #define __BLOOMFILTER_VERSION__ "1.1" #define __MGAIC_CODE__ (0x01464C42) /** * BloomFilter使用例子: * static BaseBloomFilter stBloomFilter = {0}; * * 初始化BloomFilter(最大100000元素,不超过0.00001的错误率): * InitBloomFilter(&stBloomFilter, 0, 100000, 0.00001); * 重置BloomFilter: * ResetBloomFilter(&stBloomFilter); * 释放BloomFilter: * FreeBloomFilter(&stBloomFilter); * * 向BloomFilter中新增一个数值(0-正常,1-加入数值过多): * uint32_t dwValue; * iRet = BloomFilter_Add(&stBloomFilter, &dwValue, sizeof(uint32_t)); * 检查数值是否在BloomFilter内(0-存在,1-不存在): * iRet = BloomFilter_Check(&stBloomFilter, &dwValue, sizeof(uint32_t)); * * (1.1新增) 将生成好的BloomFilter写入文件: * iRet = SaveBloomFilterToFile(&stBloomFilter, "dump.bin") * (1.1新增) 从文件读取生成好的BloomFilter: * iRet = LoadBloomFilterFromFile(&stBloomFilter, "dump.bin") **/ // 注意,要让Add/Check函数内联,必须使用 -O2 或以上的优化等级 #define FORCE_INLINE __attribute__((always_inline)) #define BYTE_BITS (8) #define MIX_UINT64(v) ((uint32_t)((v>>32)^(v))) #define SETBIT(filter, n) (filter->pstFilter[n/BYTE_BITS] |= (1 << (n%BYTE_BITS))) #define GETBIT(filter, n) (filter->pstFilter[n/BYTE_BITS] & (1 << (n%BYTE_BITS))) #pragma pack(1) // BloomFilter结构定义 typedef struct { uint8_t cInitFlag; // 初始化标志,为0时的第一次Add()会对stFilter[]做初始化 uint8_t cResv[3]; uint32_t dwMaxItems; // n - BloomFilter中最大元素个数 (输入量) double dProbFalse; // p - 假阳概率 (输入量,比如万分之一:0.00001) uint32_t dwFilterBits; // m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特数 uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函数个数 uint32_t dwSeed; // MurmurHash的种子偏移量 uint32_t dwCount; // Add()的计数,超过MAX_BLOOMFILTER_N则返回失败 uint32_t dwFilterSize; // 分配布隆过滤器的字节大小 dwFilterBits / BYTE_BITS unsigned char *pstFilter; // BloomFilter存储指针,使用malloc分配 uint32_t *pdwHashPos; // 存储上次hash得到的K个bit位置数组(由bloom_hash填充) } BaseBloomFilter; // BloomFilter文件头部定义 typedef struct { uint32_t dwMagicCode; // 文件头部标识,填充 __MGAIC_CODE__ uint32_t dwSeed; uint32_t dwCount; uint32_t dwMaxItems; // n - BloomFilter中最大元素个数 (输入量) double dProbFalse; // p - 假阳概率 (输入量,比如万分之一:0.00001) uint32_t dwFilterBits; // m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特数 uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函数个数 uint32_t dwResv[6]; uint32_t dwFileCrc; // (未使用)整个文件的校验和 uint32_t dwFilterSize; // 后面Filter的Buffer长度 } BloomFileHead; #pragma pack() /** * @brief _CalcBloomFilterParam 根据n,p计算BloomFilter的参数m,k * @param n * @param p * @param pm:布隆过滤器的m * @param pk:布隆过滤器的k */ static inline void _CalcBloomFilterParam(uint32_t n, double p, uint32_t *pm, uint32_t *pk) { /** * n - Number of items in the filter * p - Probability of false positives, float between 0 and 1 or a number indicating 1-in-p * m - Number of bits in the filter * k - Number of hash functions * * f = ln(2) × ln(1/2) × m / n = (0.6185) ^ (m/n) * m = -1 * ln(p) × n / 0.6185 , 这里有错误 * k = ln(2) × m / n = 0.6931 * m / n * darren修正: * m = -1*n*ln(p)/((ln(2))^2) = -1*n*ln(p)/(ln(2)*ln(2)) = -1*n*ln(p)/(0.69314718055995*0.69314718055995)) * = -1*n*ln(p)/0.4804530139182079271955440025 * k = ln(2)*m/n **/ uint32_t m, k, m2; // printf("ln(2):%lf, ln(p):%lf\n", log(2), log(p)); // 用来验证函数正确性 // 计算指定假阳(误差)概率下需要的比特数 m =(uint32_t) ceil(-1.0 * n * log(p) / 0.480453); // m = (m - m % 64) + 64; // 8字节对齐 // 计算哈希函数个数 double double_k = (0.69314 * m / n); // ln(2)*m/n // 这里只是为了debug出来看看具体的浮点数值 k = round(double_k); // 返回x的四舍五入整数值。 printf("orig_k:%lf, k:%u\n", double_k, k); *pm = m; *pk = k; return; } // 根据目标精度和数据个数,初始化BloomFilter结构 /** * @brief 初始化布隆过滤器 * @param pstBloomfilter 布隆过滤器实例 * @param dwSeed hash种子 * @param dwMaxItems 存储容量 * @param dProbFalse 允许的误判率 * @return 返回值 * -1 传入的布隆过滤器为空 * -2 hash种子错误或误差>=1 */ inline int InitBloomFilter(BaseBloomFilter *pstBloomfilter, uint32_t dwSeed, uint32_t dwMaxItems, double dProbFalse) { if (pstBloomfilter == NULL) return -1; if ((dProbFalse <= 0) || (dProbFalse >= 1))//假阳率 0-1 return -2; // 先检查是否重复Init,释放内存 if (pstBloomfilter->pstFilter != NULL) free(pstBloomfilter->pstFilter); if (pstBloomfilter->pdwHashPos != NULL) free(pstBloomfilter->pdwHashPos); memset(pstBloomfilter, 0, sizeof(BaseBloomFilter)); // 初始化内存结构,并计算BloomFilter需要的空间 pstBloomfilter->dwMaxItems = dwMaxItems; // 最大存储布隆过滤器的个数 pstBloomfilter->dProbFalse = dProbFalse; // 假阳率 pstBloomfilter->dwSeed = dwSeed; // hash种子 // 计算 m, k _CalcBloomFilterParam(pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, &pstBloomfilter->dwFilterBits, &pstBloomfilter->dwHashFuncs); // 分配BloomFilter的存储空间 pstBloomfilter->dwFilterSize = pstBloomfilter->dwFilterBits / BYTE_BITS; pstBloomfilter->pstFilter = (unsigned char *) malloc(pstBloomfilter->dwFilterSize); if (NULL == pstBloomfilter->pstFilter) return -100; // 哈希结果数组,每个哈希函数一个 pstBloomfilter->pdwHashPos = (uint32_t*) malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t)); if (NULL == pstBloomfilter->pdwHashPos) return -200; printf(">>> Init BloomFilter(n=%u, p=%e, m=%u, k=%d), malloc() size=%.2fMB, items:bits=1:%0.1lf\n", pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits, pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024, pstBloomfilter->dwFilterBits*1.0/pstBloomfilter->dwMaxItems); // 初始化BloomFilter的内存 memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize); pstBloomfilter->cInitFlag = 1; return 0; } // 释放BloomFilter inline int FreeBloomFilter(BaseBloomFilter *pstBloomfilter) { if (pstBloomfilter == NULL) return -1; pstBloomfilter->cInitFlag = 0; pstBloomfilter->dwCount = 0; free(pstBloomfilter->pstFilter); pstBloomfilter->pstFilter = NULL; free(pstBloomfilter->pdwHashPos); pstBloomfilter->pdwHashPos = NULL; return 0; } // 重置BloomFilter // 注意: Reset()函数不会立即初始化stFilter,而是当一次Add()时去memset inline int ResetBloomFilter(BaseBloomFilter *pstBloomfilter) { if (pstBloomfilter == NULL) return -1; pstBloomfilter->cInitFlag = 0; pstBloomfilter->dwCount = 0; return 0; } // 和ResetBloomFilter不同,调用后立即memset内存 inline int RealResetBloomFilter(BaseBloomFilter *pstBloomfilter) { if (pstBloomfilter == NULL) return -1; memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize); pstBloomfilter->cInitFlag = 1; pstBloomfilter->dwCount = 0; return 0; } /// /// 函数FORCE_INLINE,加速执行 /// // MurmurHash2, 64-bit versions, by Austin Appleby // https://sites.google.com/site/murmurhash/ FORCE_INLINE uint64_t MurmurHash2_x64 ( const void * key, int len, uint32_t seed ) { const uint64_t m = 0xc6a4a7935bd1e995; const int r = 47; uint64_t h = seed ^ (len * m); const uint64_t * data = (const uint64_t *)key; const uint64_t * end = data + (len/8); while(data != end) { uint64_t k = *data++; k *= m; k ^= k >> r; k *= m; h ^= k; h *= m; } const uint8_t * data2 = (const uint8_t*)data; switch(len & 7) { case 7: h ^= ((uint64_t)data2[6]) << 48; case 6: h ^= ((uint64_t)data2[5]) << 40; case 5: h ^= ((uint64_t)data2[4]) << 32; case 4: h ^= ((uint64_t)data2[3]) << 24; case 3: h ^= ((uint64_t)data2[2]) << 16; case 2: h ^= ((uint64_t)data2[1]) << 8; case 1: h ^= ((uint64_t)data2[0]); h *= m; }; h ^= h >> r; h *= m; h ^= h >> r; return h; } // 双重散列封装 FORCE_INLINE void bloom_hash(BaseBloomFilter *pstBloomfilter, const void * key, int len) { //if (pstBloomfilter == NULL) return; int i; uint32_t dwFilterBits = pstBloomfilter->dwFilterBits; uint64_t hash1 = MurmurHash2_x64(key, len, pstBloomfilter->dwSeed); uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1)); for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++) { pstBloomfilter->pdwHashPos[i] = (hash1 + i*hash2) % dwFilterBits; } return; } /** * @brief BloomFilter_Add 向BloomFilter中新增一个元素 * @param pstBloomfilter * @param key:要插入的key * @param len[in]:key的长度 * @return 成功返回0,当添加数据超过限制值时返回1提示用户 */ FORCE_INLINE int BloomFilter_Add(BaseBloomFilter *pstBloomfilter, const void * key, int len) { if ((pstBloomfilter == NULL) || (key == NULL) || (len <= 0)) return -1; int i; if (pstBloomfilter->cInitFlag != 1) { // Reset后没有初始化,使用前需要memset memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize); pstBloomfilter->cInitFlag = 1; } // hash key到bloomfilter中 bloom_hash(pstBloomfilter, key, len); for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++) { SETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]); } // 增加count数 pstBloomfilter->dwCount++; if (pstBloomfilter->dwCount <= pstBloomfilter->dwMaxItems) return 0; else return 1; // 超过N最大值,可能出现准确率下降等情况 } // 检查一个元素是否在bloomfilter中 // 返回:0-存在,1-不存在,负数表示失败 FORCE_INLINE int BloomFilter_Check(BaseBloomFilter *pstBloomfilter, const void * key, int len) { if ((pstBloomfilter == NULL) || (key == NULL) || (len <= 0)) return -1; int i; bloom_hash(pstBloomfilter, key, len); for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++) { // 如果有任意bit不为1,说明key不在bloomfilter中 // 注意: GETBIT()返回不是0|1,高位可能出现128之类的情况 if (GETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]) == 0) return 1; } return 0; } /* 文件相关封装 */ // 将生成好的BloomFilter写入文件 inline int SaveBloomFilterToFile(BaseBloomFilter *pstBloomfilter, char *szFileName) { if ((pstBloomfilter == NULL) || (szFileName == NULL)) return -1; int iRet; FILE *pFile; static BloomFileHead stFileHeader = {0}; pFile = fopen(szFileName, "wb"); if (pFile == NULL) { perror("fopen"); return -11; } // 先写入文件头 stFileHeader.dwMagicCode = __MGAIC_CODE__; stFileHeader.dwSeed = pstBloomfilter->dwSeed; stFileHeader.dwCount = pstBloomfilter->dwCount; stFileHeader.dwMaxItems = pstBloomfilter->dwMaxItems; stFileHeader.dProbFalse = pstBloomfilter->dProbFalse; stFileHeader.dwFilterBits = pstBloomfilter->dwFilterBits; stFileHeader.dwHashFuncs = pstBloomfilter->dwHashFuncs; stFileHeader.dwFilterSize = pstBloomfilter->dwFilterSize; iRet = fwrite((const void*)&stFileHeader, sizeof(stFileHeader), 1, pFile); if (iRet != 1) { perror("fwrite(head)"); return -21; } // 接着写入BloomFilter的内容 iRet = fwrite(pstBloomfilter->pstFilter, 1, pstBloomfilter->dwFilterSize, pFile); if ((uint32_t)iRet != pstBloomfilter->dwFilterSize) { perror("fwrite(data)"); return -31; } fclose(pFile); return 0; } // 从文件读取生成好的BloomFilter inline int LoadBloomFilterFromFile(BaseBloomFilter *pstBloomfilter, char *szFileName) { if ((pstBloomfilter == NULL) || (szFileName == NULL)) return -1; int iRet; FILE *pFile; static BloomFileHead stFileHeader = {0}; if (pstBloomfilter->pstFilter != NULL) free(pstBloomfilter->pstFilter); if (pstBloomfilter->pdwHashPos != NULL) free(pstBloomfilter->pdwHashPos); // pFile = fopen(szFileName, "rb"); if (pFile == NULL) { perror("fopen"); return -11; } // 读取并检查文件头 iRet = fread((void*)&stFileHeader, sizeof(stFileHeader), 1, pFile); if (iRet != 1) { perror("fread(head)"); return -21; } if ((stFileHeader.dwMagicCode != __MGAIC_CODE__) || (stFileHeader.dwFilterBits != stFileHeader.dwFilterSize*BYTE_BITS)) return -50; // 初始化传入的 BaseBloomFilter 结构 pstBloomfilter->dwMaxItems = stFileHeader.dwMaxItems; pstBloomfilter->dProbFalse = stFileHeader.dProbFalse; pstBloomfilter->dwFilterBits = stFileHeader.dwFilterBits; pstBloomfilter->dwHashFuncs = stFileHeader.dwHashFuncs; pstBloomfilter->dwSeed = stFileHeader.dwSeed; pstBloomfilter->dwCount = stFileHeader.dwCount; pstBloomfilter->dwFilterSize = stFileHeader.dwFilterSize; pstBloomfilter->pstFilter = (unsigned char *) malloc(pstBloomfilter->dwFilterSize); if (NULL == pstBloomfilter->pstFilter) return -100; pstBloomfilter->pdwHashPos = (uint32_t*) malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t)); if (NULL == pstBloomfilter->pdwHashPos) return -200; // 将后面的Data部分读入 pstFilter iRet = fread((void*)(pstBloomfilter->pstFilter), 1, pstBloomfilter->dwFilterSize, pFile); if ((uint32_t)iRet != pstBloomfilter->dwFilterSize) { perror("fread(data)"); return -31; } pstBloomfilter->cInitFlag = 1; printf(">>> Load BloomFilter(n=%u, p=%f, m=%u, k=%d), malloc() size=%.2fMB\n", pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits, pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024); fclose(pFile); return 0; } #endif

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
测试代码
#include "bloomfilter.h" #include <stdio.h> #define MAX_ITEMS 4000 // 设置最大元素 #define ADD_ITEMS 1000 // 添加测试元素 #define P_ERROR 0.0000001 // 设置误差 int main(int argc, char** argv) { printf(" test bloomfilter\n"); // 1. 定义BaseBloomFilter static BaseBloomFilter stBloomFilter = {0}; // 2. 初始化stBloomFilter,调用时传入hash种子,存储容量,以及允许的误判率 InitBloomFilter(&stBloomFilter, 0, MAX_ITEMS, P_ERROR); // 3. 向BloomFilter中新增数值 char url[128] = {0}; for(int i = 0; i < ADD_ITEMS; i++){ sprintf(url, "https://0voice.com/%d.html", i); if(0 == BloomFilter_Add(&stBloomFilter, (const void*)url, strlen(url))){ // printf("add %s success", url); }else{ printf("add %s failed", url); } memset(url, 0, sizeof(url)); } // 4. check url exist or not const char* str = "https://0voice.com/0.html"; if (0 == BloomFilter_Check(&stBloomFilter, str, strlen(str)) ){ printf("https://0voice.com/0.html exist\n"); } const char* str2 = "https://0voice.com/10001.html"; if (0 != BloomFilter_Check(&stBloomFilter, str2, strlen(str2)) ){ printf("https://0voice.com/10001.html not exist\n"); } // 5. free bloomfilter FreeBloomFilter(&stBloomFilter); getchar(); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
分布式一致性 hash
产生背景
由于数据量的巨大,不可能某种应用将所有的数据存储在一台服务器上,比如,举个简单的例子,不知道你有没有想过,微信用户已经达到了几亿,微信用户的基本信息及其聊天记录等信息不可能存在存储在一台服务器上,但是应该如何将这些数据存储到不同的服务器上,当我们登录时,微信客户端又是登录到具体的服务器的呢,其实这都是分布式系统的功劳。分布式系统涉及到很多其他方面的知识,我们今天只是简单聊聊如何将关键字映射到不同的节点(插入节点信息),并根据关键字从不同的节点获取相关的信息(查询节点信息)。
举个例子:我们有三台缓存服务器编号node0、node1、node2,现在有 3000 万个key,希望可以将这些个 key 均匀的缓存到三台机器上,你会想到什么方案呢?我们可能首先想到的方案是:取模算法hash(key)% N,即:对 key 进行 hash 运算后取模,N 是机器的数量;
这样,对 key 进行 hash 后的结果对 3 取模,得到的结果一定是 0、1 或者 2,正好对应服务器node0、node1、node2,存取数据直接找对应的服务器即可,简单粗暴,完全可以解决上述的问题;
取模算法虽然简单,但是在集群扩容和收缩时却有一定的局限性:因为在生产环境中根据业务量的大小,调整服务器数量是常有的事;从而导致服务器数量 N 发生变化后hash(key)% N计算的结果也会随之变化!
另外,服务器的一个节点挂掉也是常有的事情,计算公式从hash(key)% N变成了hash(key)% (N-1),结果会发生变化,此时想要访问一个 key,这个 key 的缓存位置大概率会发生改变,那么之前缓存 key 的数据也会失去作用与意义;但是在生产线上我们又不可能修改代码,这样就会导致所有映射到挂掉节点的key失效,这样就会操作缓存的雪崩(常见的情况就是我们无法登录服务器或者无法注册的情况),这样就会使得我们的系统完全不具备高可用性和扩展性,为了解决这个问题,出现了分布式一致hash,当节点挂掉时和添加节点时,对系统的影响很小,对用户来说完全感觉不到。分布式一致hash解决节点的动态变化和负载均衡的问题
分布式哈希定义
一致性哈希算法是一种用于分布式系统中的数据分片和负载均衡的算法。它将整个哈希空间划分为一个环,并且每个节点在这个环上都有一个对应的位置。当需要读写某个数据时,先将其进行哈希运算得到一个哈希值,然后根据这个哈希值在环上找到对应的节点,从而实现数据的定位。
一致性哈希算法的优点在于:当新增或删除节点时,只会影响到环上的一小部分节点,因此不会像传统的哈希算法那样造成大量的数据迁移和重新分片。同时,由于节点数较多,请求可以被更好地平均分配,从而实现了负载均衡的效果。
另外,一致性哈希算法还可以通过增加虚拟节点来解决节点不均衡的问题,从而进一步提高负载均衡的效果。
算法详解
一致性hash主要包括以下内容
1 哈希环: 将数据的键值哈希到一个固定的范围内,通常是一个环形空间。我们可以将这2^32 个值抽象成一个圆环 ,圆环的正上方的点代表 0,顺时针排列,以此类推:1、2、3…直到2的32次方-1,而这个由 2 的 32 次方个点组成的圆环统称为hash环;
2 节点: 将节点的标识符哈希到环形空间上的一个位置,每个节点在环上占据一个位置。
3 数据分布: 将数据的键值哈希到环形空间上的一个位置,然后按照顺时针方向找到第一个节点,将数据存储在该节点上。
4.节点动态变化: 当节点动态变化时,只需要对受影响的数据进行重新哈希,将其映射到新的节点上即可,无需对整个数据集进行重新分配。
5.负载均衡: 由于节点在环上均匀分布,因此可以实现负载均衡,将数据均匀地分布在不同的节点上,避免单个节点的负载过高。
6.容错性: 由于节点在环上均匀分布,当某个节点发生故障时,只会影响其前一个节点到故障节点之间的数据,其他数据不会受到影响。
下图为分布式哈希算法的圆环图。
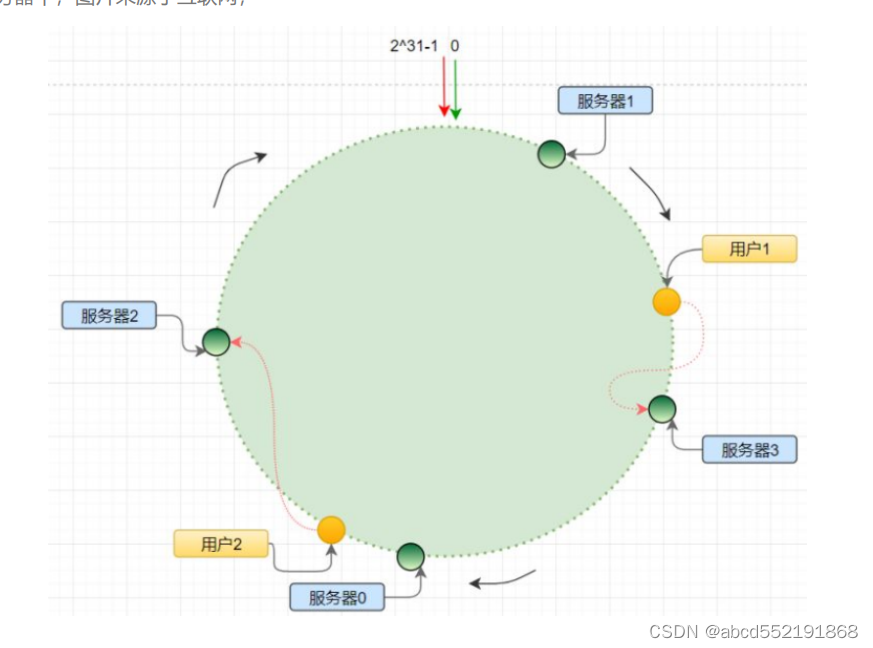
分布式哈希算法本质上也是一种取模算法;不过,不同于上边按服务器数量取模,一致性 hash 是对固定值 2^32 取模;
算法为: 将服务器根据ip执行hash(ip) ,最终会得到一个 [0, 2^32-1] 之间的一个无符号整型,这个整数代表服务器的编号;多个服务器都通过这种方式在 hash 环上映射一个点来标识该服务器的位置;当用户操作某个 key,通过同样的算法生成一个值,沿环顺时针定位某个服务器,那么该 key 就在该服务器中;
- 1
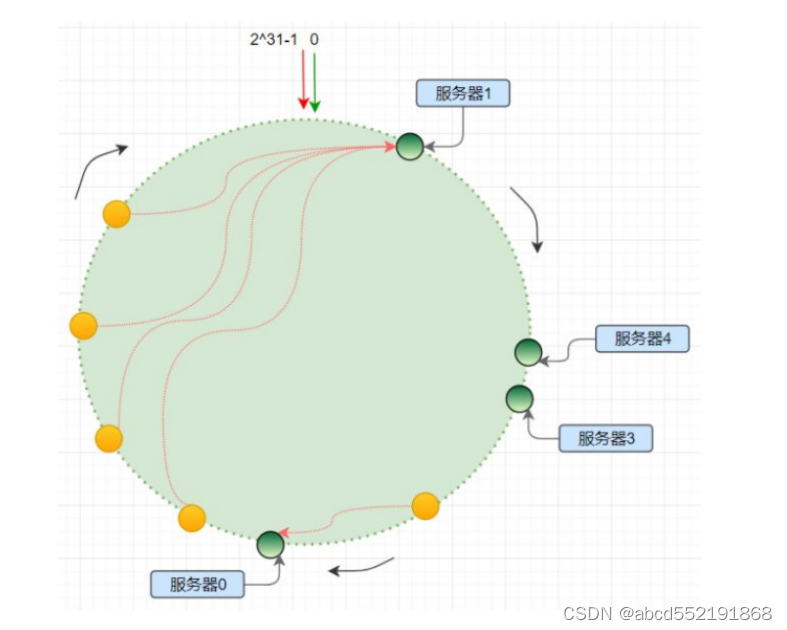
hash 偏移
hash 算法得到的结果是随机的,不能保证服务器节点均匀分布在哈希环上;分布不均匀造成请求访问不均匀,服务器承受的压力不均匀;特别是服务器数量少的情况下,更容易出现这种情况,如下图所示
虚拟节点
既然hash偏移很多时候是因为节点过少造成的,增加了虚拟节点的概念;理论上,哈希环上节点数越多,数据分布越均衡;为每个服务节点计算多个哈希节点(虚拟节点);通常做法是, hash(“IP:PORT:seqno”);
举例来说,本来只有3个节点(假如ip分别为192.168.1.1,192.168.1.2,192.168.1.3,端口号分别为20,30,40) ,如果我们想生成3000个节点(每个节点1000个),那么可以得到192.168.1.1:20:1~192.168.1.1:20:1000 1000个节点,192.168.1.2:30:1 ~ 192.168.1.2:30:1000 1000个节点,192.168.1.3:40:1 ~ 192.168.1.3:40:1000 1000个节点。同样将这些节点映射到hashh环上,假如某个key映射到192.168.1.3:40:20,那么我们得到key映射到192.168.1.3这个节点上。
C语言实现
待插入代码
总结
hash算法用于从海量数据中查询某个key对应的数据是否存在,查询时间复杂度为O(1).
布隆过滤器是hash算法的一个应用,当需要在内存中存储大量的数据时,布隆过滤器无需存储节点的key,也能知道查询的关键字是否存在。从而解决了海量数据的查询操作。
一致性哈希是一种用于分布式系统中数据负载均衡的算法。在分布式系统中,多个服务器节点需要负责处理不同的请求,但由于每个请求的负载大小不同,因此会导致服务器节点的负载不平衡,一些节点可能会过度负载,而另一些节点则占用较少的资源。这就需要一种算法来平衡各个节点之间的负载。这就是一致性哈希解决的问题

