
- 1JSP连接数据库的几种方式_jsp中使用数据库常用的连接方式
- 2Linux系统下关于VITIS VISION库和OPENCV的使用_vitis hls vision 库
- 3LeetCode 101:和你一起你轻松刷题(C++)总篇章正在陆续更新_leetcode101
- 4Vue2教程详解三(表单输入绑定、过滤器、指令)_vue链接绑定过滤条件
- 5AI绘画SD入门教程:文生图基础用法(提示词)_ai sd 提示词
- 6java发送163邮箱email工具类_java 163邮箱
- 7【WEB逆向】关于tiktok参数msToken,X-Bogus,_signature生成
- 8如何利用大模型进行安全攻防:内附多个应用案例_安全检测渗透大模型
- 9快速查找对方IP经典技巧汇总
- 10python 根据答案 自动答题器_python根据题库答案自动答题
【MySQL精炼宝库】数据库的约束 | 表的设计 | 聚合查询 | 联合查询
赞
踩
目录
一、数据库约束
1.1 约束类型:
• NOT NULL:指示某列不能存储 NULL 值。
• UNIQUE:保证某列的每行必须有唯一的值。
• DEFAULT:规定没有给列赋值时的默认值。
• PRIMARY KEY:NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标 识,有助于更容易更快速地找到表中的一个特定的记录。
• FOREIGN KEY:保证一个表中的数据匹配另一个表中的值的参照完整性。
• CHECK(了解):保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略 CHECK子句。
1.2 案例演示:
• NULL约束:
创建表时,可以指定某列不为空,对应SQL脚本如下:
- -- 重新设置学生表结构
- DROP TABLE IF EXISTS student;
- CREATE TABLE student (
- id INT NOT NULL,
- sn INT,
- name VARCHAR(20),
- qq_mail VARCHAR(20)
- );
案例演示效果如下:

• UNIQUE:唯一约束 :
指定sn列为唯一的、不重复的,对应SQL脚本如下:
- -- 重新设置学生表结构
- DROP TABLE IF EXISTS student;
- CREATE TABLE student (
- id INT NOT NULL,
- sn INT UNIQUE,
- name VARCHAR(20),
- qq_mail VARCHAR(20)
- );
案例演示效果如下:

• DEFAULT:默认值约束:
指定插入数据时,name列为空,默认值unkown,对应SQL脚本:
- -- 重新设置学生表结构
- DROP TABLE IF EXISTS student;
- CREATE TABLE student (
- id INT NOT NULL,
- sn INT UNIQUE,
- name VARCHAR(20) DEFAULT 'unkown',
- qq_mail VARCHAR(20)
- );
案例演示效果如下:

• PRIMARY KEY:主键约束:
指定id列为主键,对应SQL脚本如下:
- -- 重新设置学生表结构
- DROP TABLE IF EXISTS student;
- CREATE TABLE student (
- id INT NOT NULL PRIMARY KEY,
- sn INT UNIQUE,
- name VARCHAR(20) DEFAULT 'unkown',
- qq_mail VARCHAR(20)
- );
对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用最大值+1。
SQL脚本:
- -- 主键是 NOT NULL 和 UNIQUE 的结合,可以不用 NOT NULL
- id INT PRIMARY KEY auto_increment,
由于不加上 auto_increment 的主键和前面的哪几种约束报错差不多这里就不再演示,这里只演示加上 auto increment 的情况。
案例演示效果如下:

• FOREIGN KEY:外键约束:
外键用于关联其他表的主键或唯一键,对应SQL脚本语法:
foreign key (字段名) references 主表(列)
案例演示:
为了方便叙述这里关联的表就采用 primary_key里面的案例:
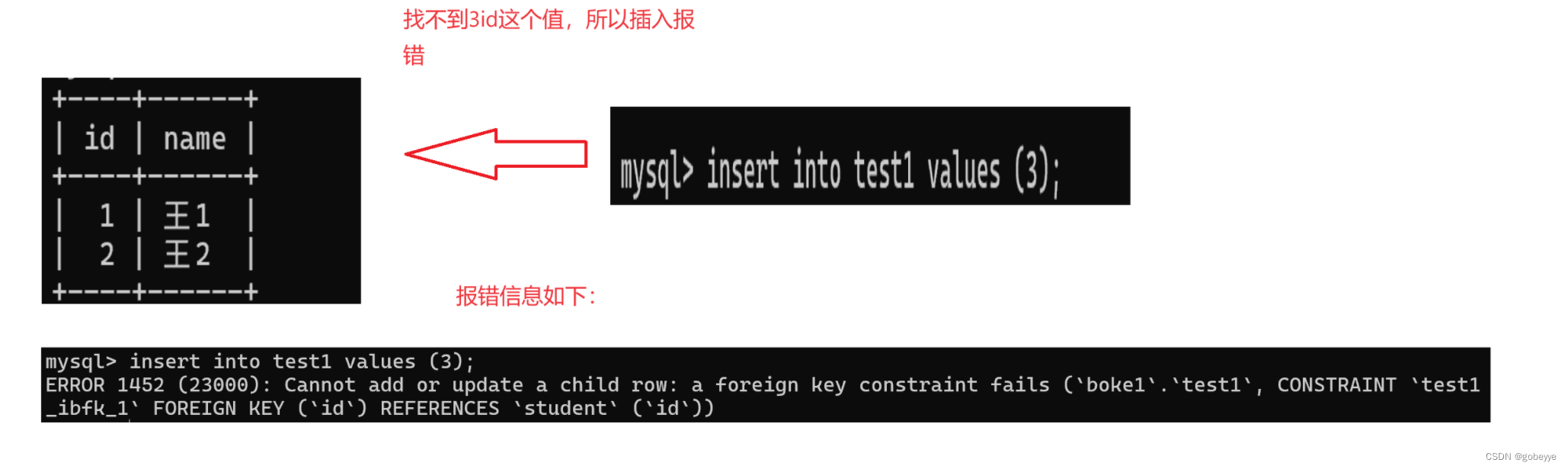
至于CHECK了解即可这里就就不演示了。
二、表的设计
数据库中表的设计有三大范式:
2.1 一对一:
一句话梳理:一个学生只能有一个账号,一个账号只能属于一个学生。

2.2 一对多:
一句话梳理:一个学生只能属于一个班级,一个班级可以有多个学生。

2.3 多对多:
一句话梳理:一个学生可以选择多个课程,一个课程可以被多个学生选择。
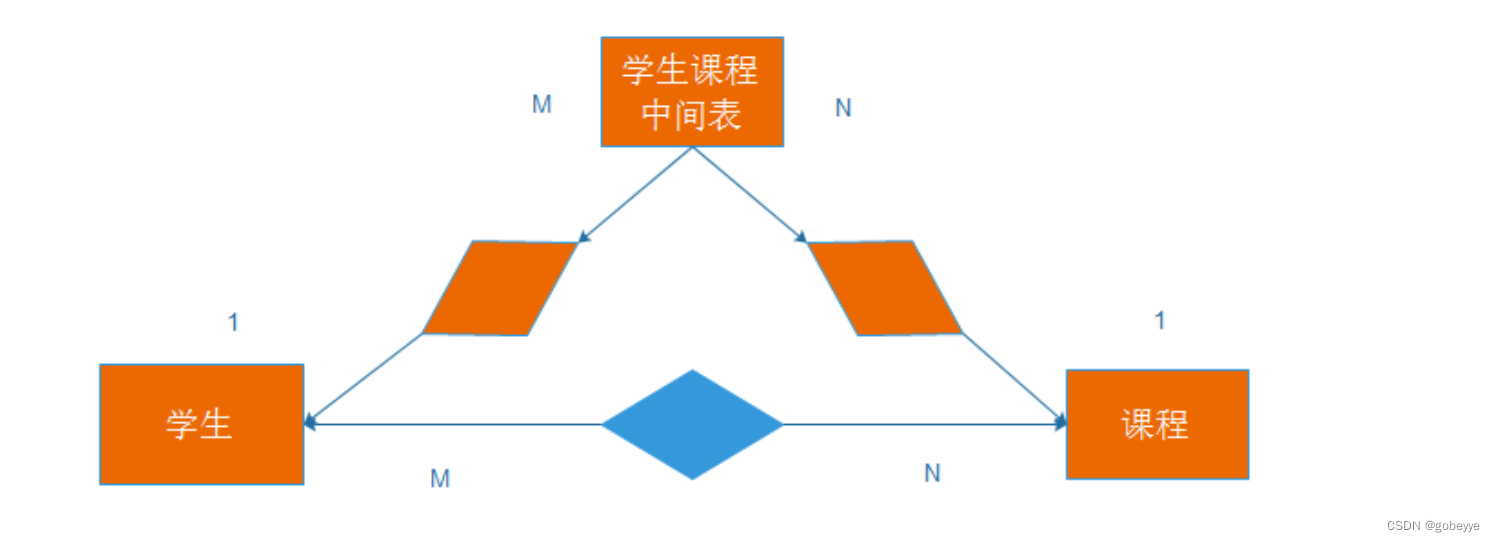
2.4 内容小结:
• 一对一的表:随便在一个表中建立一个合适的外键即可把两个表关联起来。
• 一对多的表:先建立 1 的那个表设个主键,再建立多的表并再多的表中建立外键关联起 1 的表。
• 多对多的表:这个只能再建立一个新表把两个表联系起来,例如:在学生表和课程表这个多对多的表中我们可以建立一个成绩表把它们关联起来,在成绩表中要设置两个外键分别关联两个表。
三、新增
• SQL脚本语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...案例演示:
案例:创建一张用户表,设计有name姓名、id编号、sex性别、mobile手机号字段。需要把已有的学生数据复制进来,可以复制的字段为name、id。
- -- 创建用户表
- DROP TABLE IF EXISTS test_user;
- CREATE TABLE test_user (
- id INT primary key auto_increment,
- name VARCHAR(20) comment '姓名',
- age INT comment '年龄',
- email VARCHAR(20) comment '邮箱',
- sex varchar(1) comment '性别',
- mobile varchar(20) comment '手机号'
- );
案例演示效果如下:

四、查询
4.1 聚合查询:
4.1.1 聚合函数:
常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有:
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
[ ]里面的代表可以省略.
案例演示:
• COUNT
- -- 统计班级共有多少同学
- SELECT COUNT(*) FROM student;
- SELECT COUNT(0) FROM student;
- -- 统计班级收集的 qq_mail 有多少个,qq_mail 为 NULL 的数据不会计入结果
- SELECT COUNT(qq_mail) FROM student;
注意:如果count里面的列里面的值全部为NULL的话不计数。
• SUM
- -- 统计数学成绩总分
- SELECT SUM(math) FROM exam_result;
- -- 不及格 < 60 的总分,没有结果,返回 NULL
- SELECT SUM(math) FROM exam_result WHERE math < 60;
• AVG
- -- 统计平均总分
- SELECT AVG(chinese + math + english) 平均总分 FROM exam_result;
• MAX
- -- 返回英语最高分
- SELECT MAX(english) FROM exam_result;
• MIN
- -- 返回 > 70 分以上的数学最低分
- SELECT MIN(math) FROM exam_result WHERE math > 70;
4.1.2 GROUP BY子句:
• SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
一定要记住上面这句话非常重要。
对于SQL脚本:
select column1, sum(column2), .. from table group by column1,column3;案例:
1. 准备测试表及数据:职员表,有id(主键)、name(姓名)、role(角色)、salary(薪水)。
- create table emp(
- id int primary key auto_increment,
- name varchar(20) not null,
- role varchar(20) not null,
- salary numeric(11,2)
- );
- insert into emp(name, role, salary) values
- ('马云','服务员', 1000.20),
- ('马化腾','游戏陪玩', 2000.99),
- ('孙悟空','游戏角色', 999.11),
- ('猪无能','游戏角色', 333.5),
- ('沙和尚','游戏角色', 700.33),
- ('隔壁老王','董事长', 12000.66);
2. 查询每个角色的最高工资、最低工资和平均工资 。
select role,max(salary),min(salary),avg(salary) from emp group by role;案例效果如下:
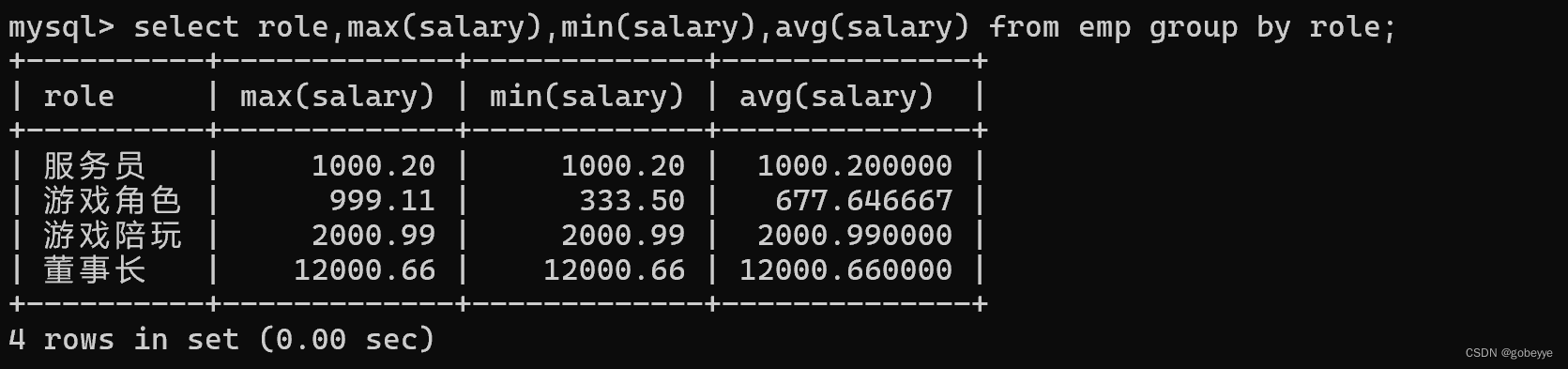
如果查询的组不是分组的依据列话且不再聚合函数里面,那么得到的数据没有一点实际意义。
4.1.3 HAVING:
• GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用 HAVING。
案例演示:
显示平均工资低于1500的角色和它的平均工资。
对应SQL脚本:
- select role,max(salary),min(salary),avg(salary) from emp group by role
- having avg(salary)<1500;
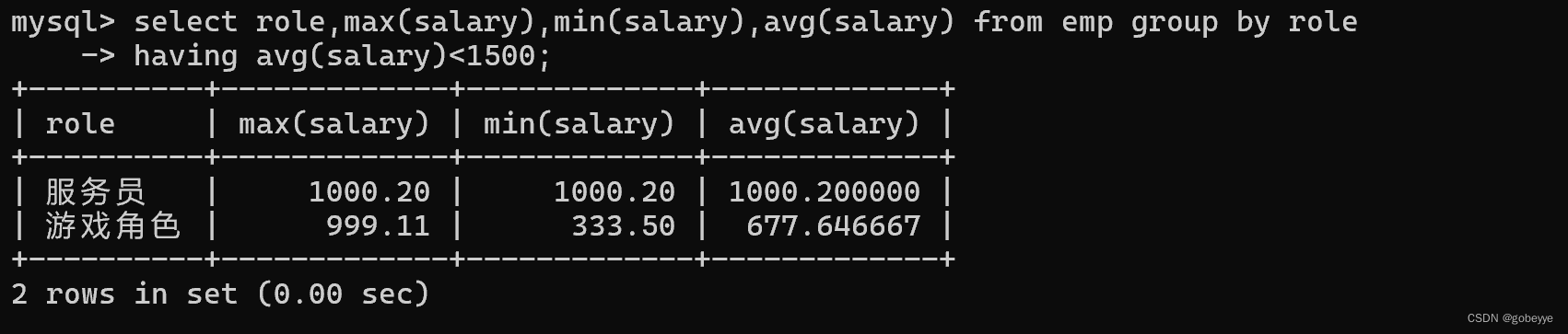
4.2 联合查询:
联合查询可以说是本节内容的最重要部分。
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积:
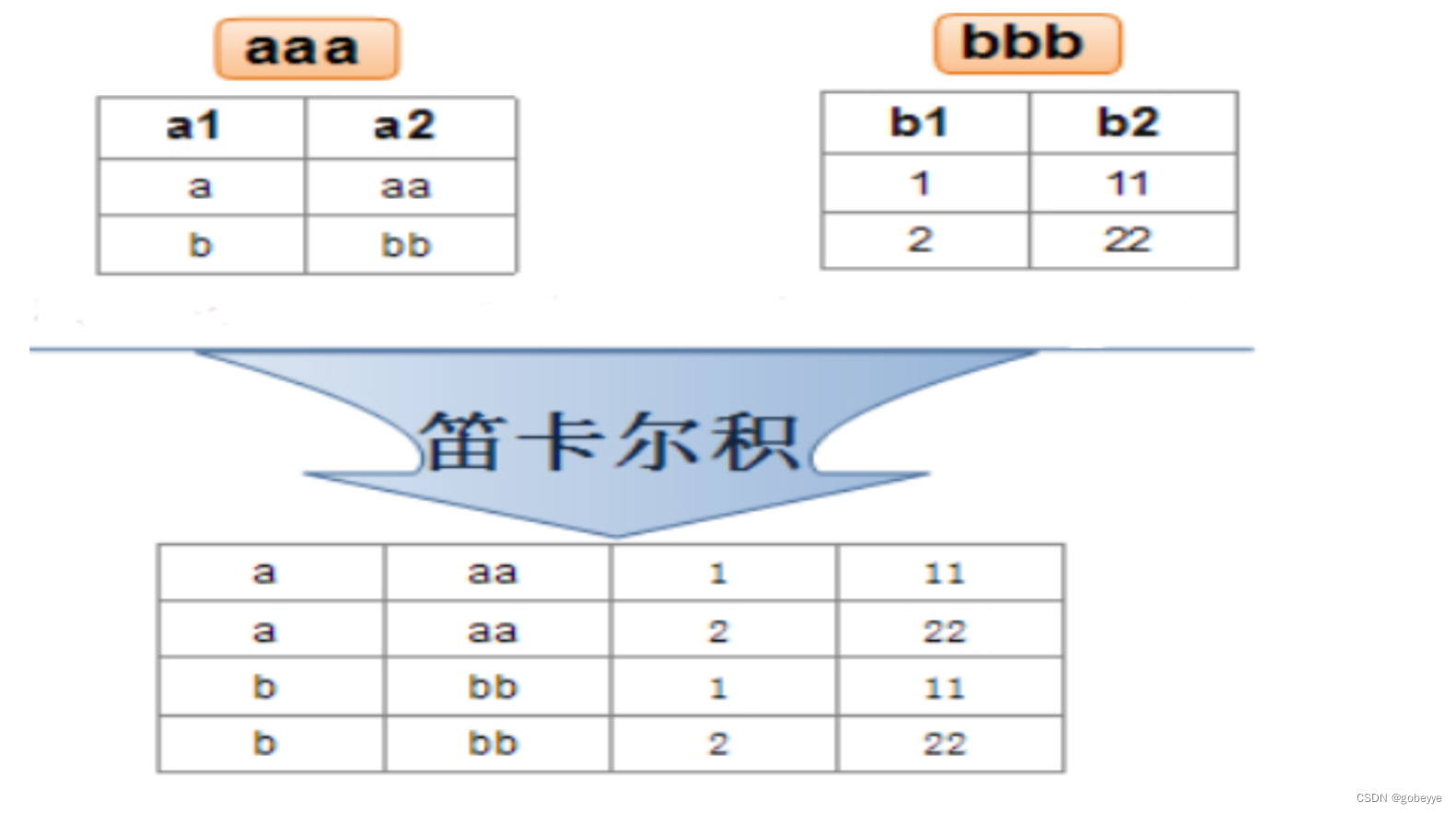
注意:关联查询可以对关联表使用别名。
• 初始化测试数据:
- insert into classes(name, `desc`) values
- ('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
- ('中文系2019级3班','学习了中国传统文学'),
- ('自动化2019级5班','学习了机械自动化');
- insert into student(sn, name, qq_mail, classes_id) values
- ('09982','黑旋风李逵','xuanfeng@qq.com',1),
- ('00835','菩提老祖',null,1),
- ('00391','白素贞',null,1),
- ('00031','许仙','xuxian@qq.com',1),
- ('00054','不想毕业',null,1),
- ('51234','好好说话','say@qq.com',2),
- ('83223','tellme',null,2),
- ('09527','老外学中文','foreigner@qq.com',2);
- insert into course(name) values
- ('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
- insert into score(score, student_id, course_id) values
- -- 黑旋风李逵
- (70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
- -- 菩提老祖
- (60, 2, 1),(59.5, 2, 5),
- -- 白素贞
- (33, 3, 1),(68, 3, 3),(99, 3, 5),
- -- 许仙
- (67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
- -- 不想毕业
- (81, 5, 1),(37, 5, 5),
- -- 好好说话
- (56, 6, 2),(43, 6, 4),(79, 6, 6),
- -- tellme
- (80, 7, 2),(92, 7, 6);

为了方便叙述下面给出内连接和外连接在集合角度上的示意图:

4.2.1 内连接:
SQL脚本语法:
- select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
- select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
案例演示:
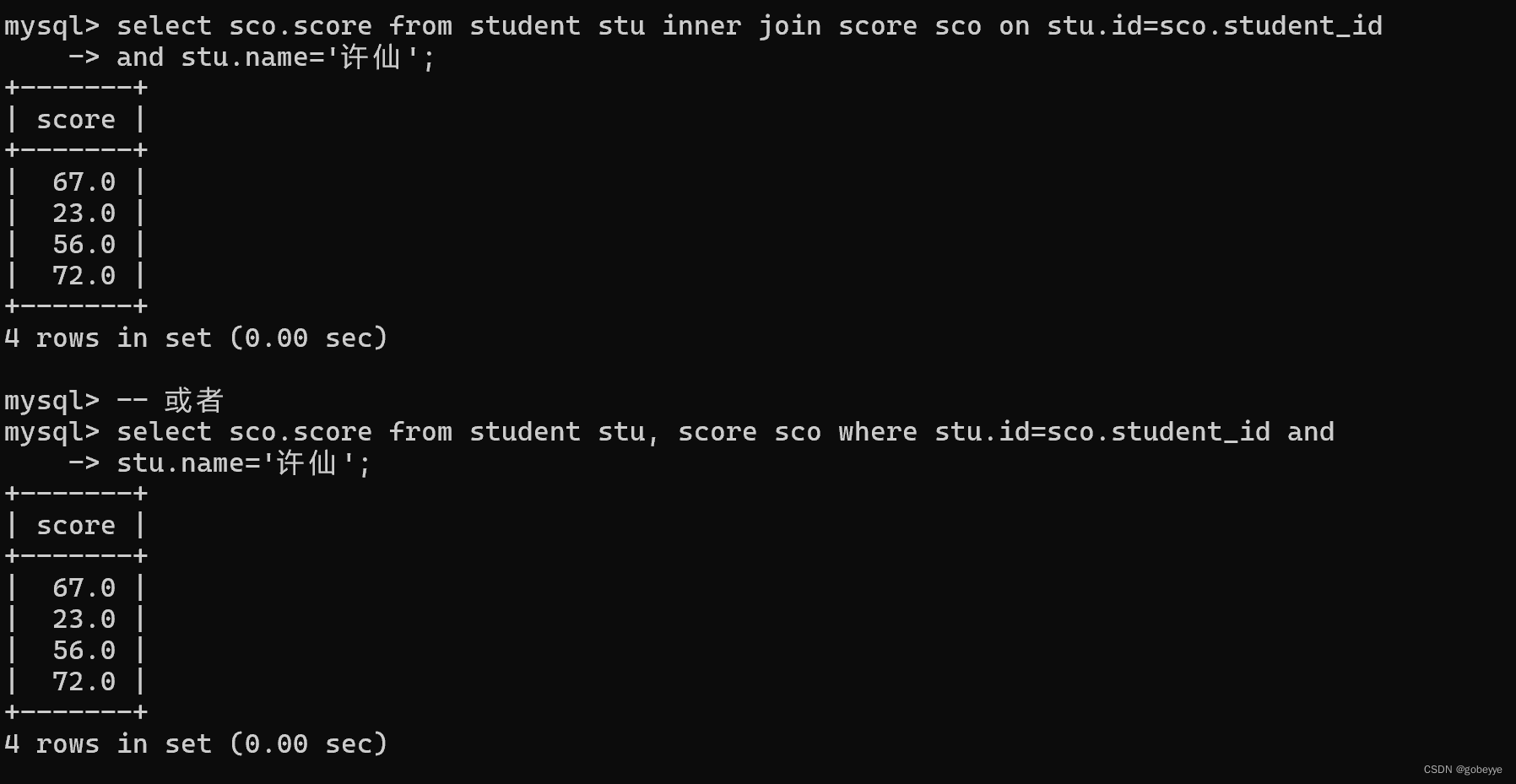
• 查询“许仙”同学的成绩
两种SQL语句是一样的。
- select sco.score from student stu inner join score sco on stu.id=sco.student_id
- and stu.name='许仙';
- -- 或者
- select sco.score from student stu, score sco where stu.id=sco.student_id and
- stu.name='许仙';
4.2.2 外连接:
• 外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完 全显示我们就说是右外连接。
SQL脚本语法:
- -- 左外连接,表1完全显示
- select 字段名 from 表名1 left join 表名2 on 连接条件;
- -- 右外连接,表2完全显示
- select 字段 from 表名1 right join 表名2 on 连接条件;
案例:查询所有同学的成绩,及同学的个人信息,如果该同学没有成绩,也需要显示。
- -- “老外学中文”同学 没有考试成绩,也显示出来了
- select * from student stu left join score sco on stu.id=sco.student_id;
- -- 对应的右外连接为:
- select * from score sco right join student stu on stu.id=sco.student_id;
案例结果如下:
由于结果有点多故截取了中间的一点无用数据。

4.2.3 自连接:
• 自连接是指在同一张表连接自身进行查询。
自连接一般用于特殊场景,可以把行的比较转换成列的比较(MySQL只能进行列的比较)。
案例:
显示所有“计算机原理”成绩比“Java”成绩高的成绩信息。
- SELECT
- stu.*,
- s1.score Java,
- s2.score 计算机原理
- FROM
- score s1
- JOIN score s2 ON s1.student_id = s2.student_id
- JOIN student stu ON s1.student_id = stu.id
- JOIN course c1 ON s1.course_id = c1.id
- JOIN course c2 ON s2.course_id = c2.id
- AND s1.score < s2.score
- AND c1.NAME = 'Java'
- AND c2.NAME = '计算机原理';

4.2.4 子查询:
• 子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。
子查询是把多个sql嵌套成了一个sql,这个写法在实际开发中要慎重使用,因为这种写法违背编程中的基本思想原则化繁为简(子查询是化简为繁)。
• 单行子查询:返回一行记录的子查询
案例:查询与“不想毕业” 同学的同班同学
- select * from student where classes_id=(select classes_id from student where
- name='不想毕业');
• 多行子查询:返回多行记录的子查询
案例:查询“语文”或“英文”课程的成绩信息
- select * from score where course_id in (select id from course where
- name='语文' or name='英文');
可以使用多列包含:
案例:查询重复的分数
- SELECT
- *
- FROM
- score
- WHERE
- ( score, student_id, course_id ) IN ( SELECT score, student_id,
- course_id FROM score GROUP BY score, student_id, course_id HAVING
- count( 0 ) > 1 );
• 在from子句中使用子查询:子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个 子查询当做一个临时表使用。
1.查询所有比“中文系2019级3班”平均分高的成绩信息:
- -- 获取“中文系2019级3班”的平均分,将其看作临时表
- SELECT
- avg( sco.score ) score
- FROM
- score sco
- JOIN student stu ON sco.student_id = stu.id
- JOIN classes cls ON stu.classes_id = cls.id
- WHERE
- cls.NAME = '中文系2019级3班';
案例结果如下:

2.查询成绩表中,比以上临时表平均分高的成绩:
- SELECT
- *
- FROM
- score sco,
- (
- SELECT
- avg( sco.score ) score
- FROM
- score sco
- JOIN student stu ON sco.student_id = stu.id
- JOIN classes cls ON stu.classes_id = cls.id
- WHERE
- cls.NAME = '中文系2019级3班'
- ) tmp
- WHERE
- sco.score > tmp.score;
案例结果如下:

4.2.5 合并查询:
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION 和UNION ALL时,前后查询的结果集中,字段需要一致。
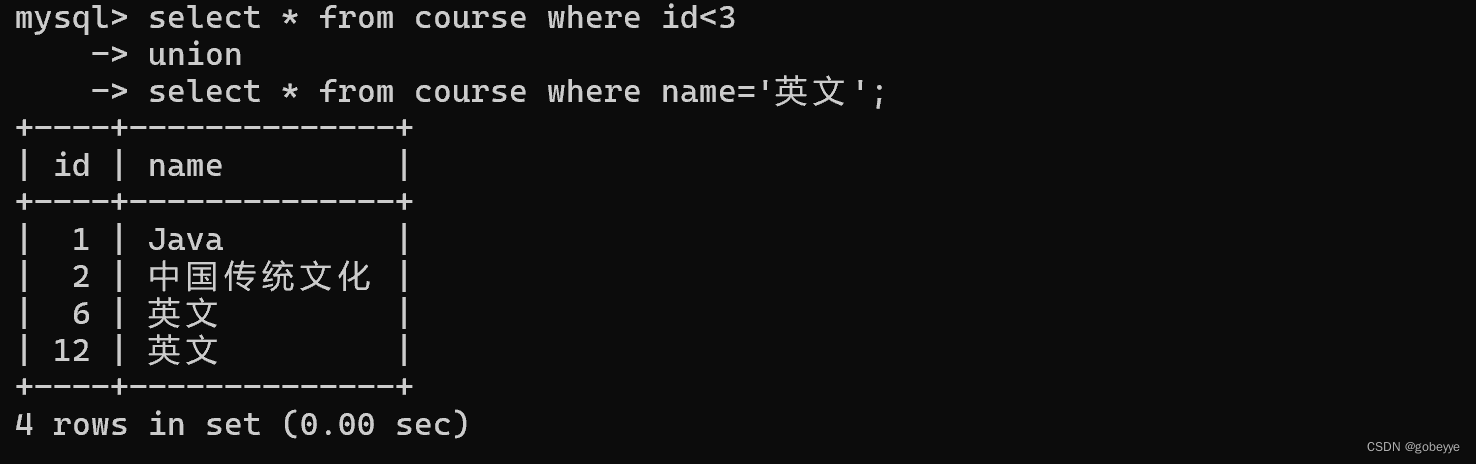
• union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
案例:查询id小于3,或者名字为“英文”的课程:
- select * from course where id<3
- union
- select * from course where name='英文';
问题:使用where里面的条件语句也可以做到,为什么还要union呢?
解答:union 允许你从不同的多个表分别查询,只要每个表查询的结果集合列的类型和个数匹配,都能合并。
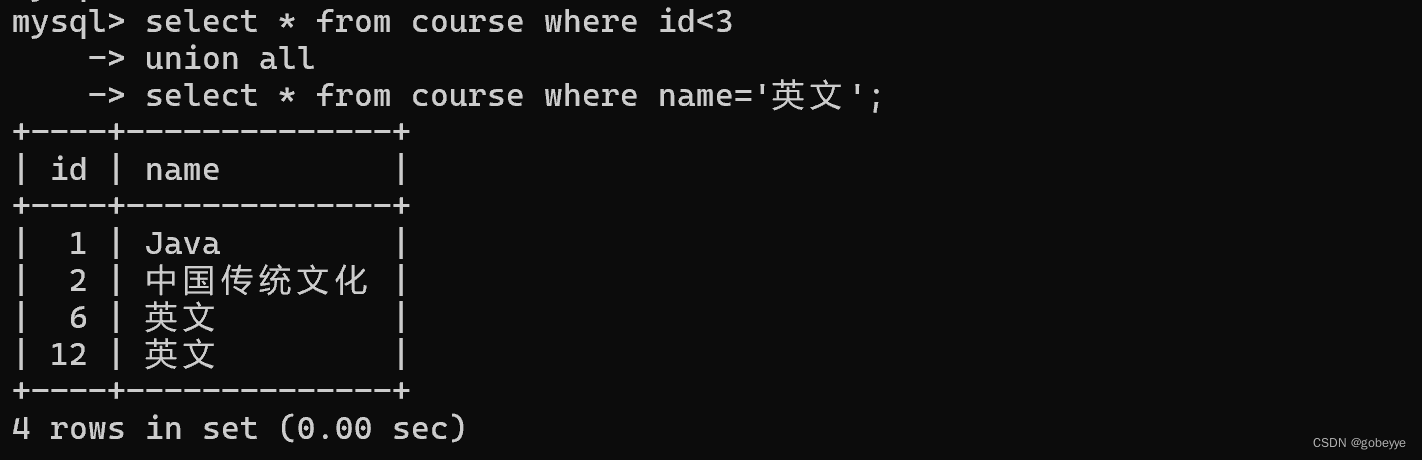
• union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
案例:查询id小于3,或者名字为“Java”的课程
- -- 可以看到结果集中出现重复数据Java
- select * from course where id<3
- union all
- select * from course where name='英文';
结语:
其实写博客不仅仅是为了教大家,同时这也有利于我巩固知识点,和做一个学习的总结,由于作者水平有限,对文章有任何问题还请指出,非常感谢。如果大家有所收获的话还请不要吝啬你们的点赞收藏和关注,这可以激励我写出更加优秀的文章。


