
- 1Android 蓝牙开发(二) --手机与蓝牙音箱配对,并播放音频_android 蓝牙耳机接受音频
- 2【链表经典面试题保姆级题解】什么?这八个最基本的链表面试题你还没有掌握?最短的时间内教会你!_链表为空怎么解决
- 3绕过Cloudflare五秒盾,穿云API抓取网页不再等待_五秒盾会检测ip吗
- 4UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xd2 in position 422: invalid continuation byte_syntaxerror: (unicode error) 'utf-8' codec can't d
- 5基于yolov5的苹果成熟度检测系统,可进行图像目标检测,也可进行视屏和摄像检测(pytorch框架)【python源码+UI界面+功能源码详解】_基于yolo的苹果成熟度识别
- 6第18届全国大学生智能汽车竞赛四轮车开源讲解【12】--写在最后_江科大智能小车
- 7什么是Kafka?有什么主要用途?_kafka作用
- 8java审批流创建及代码流程
- 9【记录】pip install git+https://github.com/XXX/XXX 报错
- 10整型提升和算术转换<C语言>
千元开发板,百万可能:OpenVINO™ 助力谷歌大语言模型Gemma 实现高速智能推理_openvino 开发板
赞
踩
作者:武卓博士,英特尔 AI 软件布道师
Intel® Processor (Products formerly known as Alder Lake-N) reference scripts
大型语言模型(LLM)正在迅速发展,变得更加强大和高效,使人们能够在广泛的应用程序中越来越复杂地理解和生成类人文本。谷歌的 Gemma 是一个轻量级、先进的开源模型新家族,站在 LLM 创新的前沿。然而,对更高推理速度和更智能推理能力的追求并不仅仅局限于复杂模型的开发,它扩展到模型优化和部署技术领域。OpenVINO™ 工具套件因此成为一股引人注目的力量,在这些领域发挥着越来越重要的作用。这篇博客文章深入探讨了优化谷歌的 Gemma 模型,并在不足千元的AI开发板上进行模型部署、使用 OpenVINO™ 加速推理,将其转化为能够更快、更智能推理的 AI 引擎。
此文使用了研扬科技针对边缘 AI 行业开发者推出的哪吒(Nezha)开发套件,以信用卡大小(85 x 56mm)的开发板-哪吒(Nezha)为核心,哪吒采用 Intel® N97 处理器(Alder Lake-N),最大睿频 3.6GHz,Intel® UHD Graphics 内核GPU,可实现高分辨率显示;板载 LPDDR5 内存、eMMC 存储及 TPM 2.0,配备 GPIO 接口,支持 Windows 和 Linux 操作系统,这些功能和无风扇散热方式相结合,为各种应用程序构建高效的解决方案,适用于如自动化、物联网网关、数字标牌和机器人等应用。售价 RMB 999起, 哪吒开发套件Nezha intel x86开发板板载Alder N97 可Win10/Ubuntu N97 4G+32G -JD

什么是 Gemma?
Gemma 是谷歌的一个轻量级、先进的开源模型家族,采用了与创建 Gemini 模型相同的研究和技术。它们以拉丁语单词 “Gemma” 命名,意思是“宝石”,是文本到文本的、仅解码器架构的 LLM,有英文版本,具有开放权重、预训练变体和指令调整变体。Gemma 模型非常适合各种文本生成任务,包括问答、摘要和推理。
Gemma 模型系列,包括 Gemma-2B 和 Gemma-7B 模型,代表了深度学习模型可扩展性和性能的分层方法。在本次博客中,我们将展示 OpenVINO™ 如何优化和加速 Gemma-2B-it 模型的推理,即 Gemma-2B 参数模型的指令微调后的版本。
利用 OpenVINO™ 优化和加速推理
优化、推理加速和部署的过程包括以下具体步骤,使用的是我们常用的 OpenVINO™ Notebooks GitHub 仓库 中的 254-llm-chatbot 代码示例。详细信息和完整的源代码可以在这里找到。
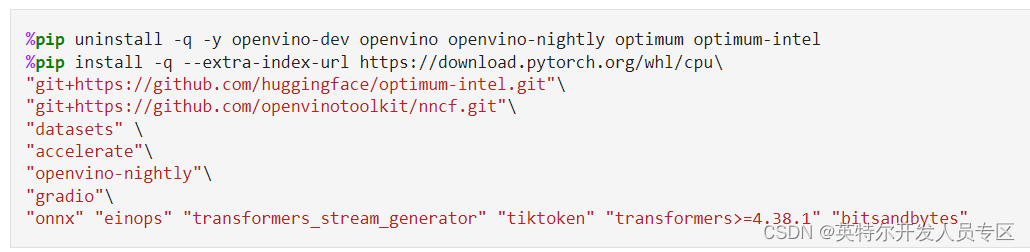
由安装必要的依赖包开始
运行 OpenVINO™ Notebooks 仓库的具体安装指南在这里。运行这个 254-llm-chatbot 的代码示例,需要安装以下必要的依赖包。
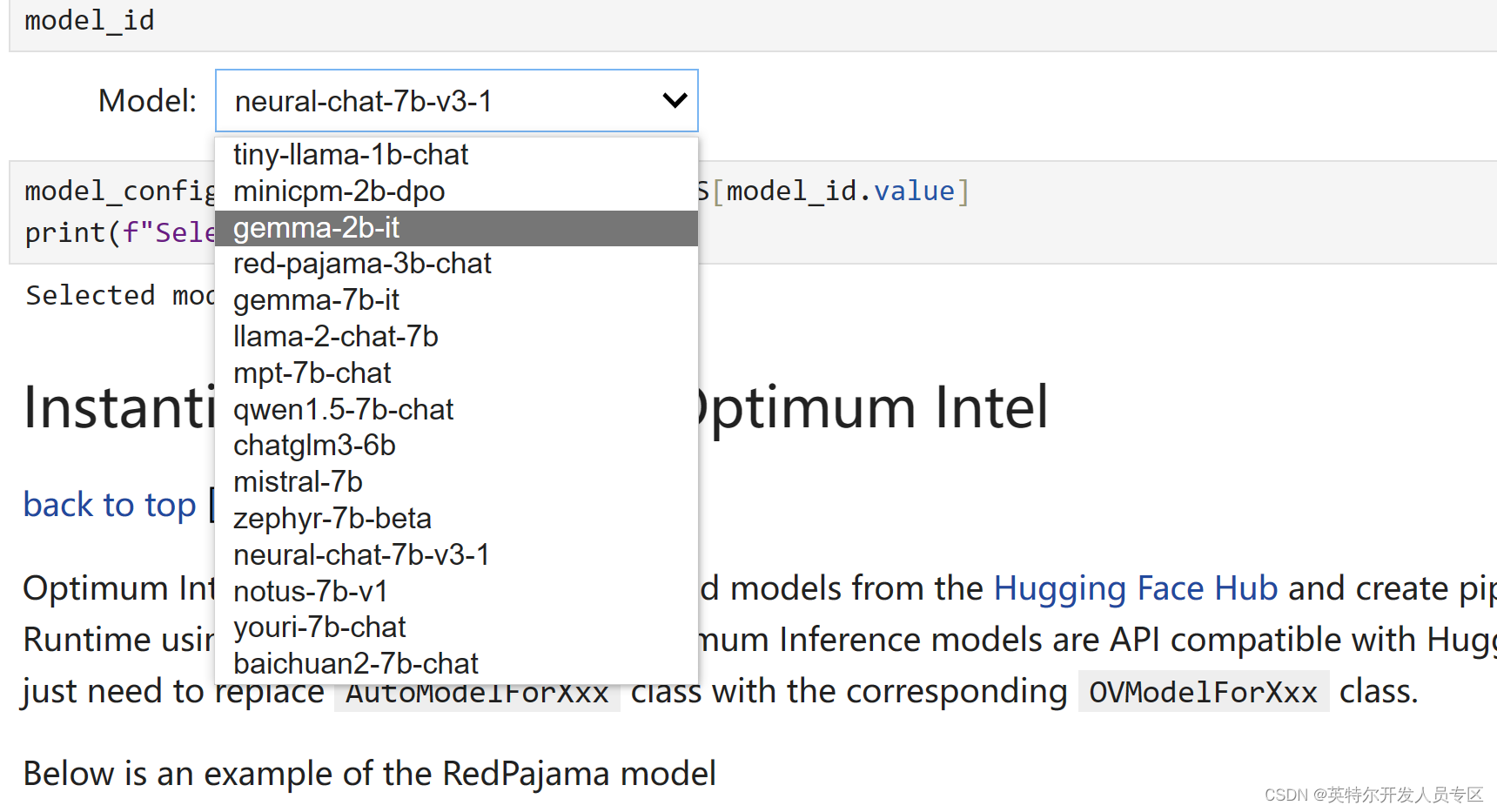
选择推理的模型
由于我们在 Jupyter Notebook 演示中提供了一组由 OpenVINO™ 支持的 LLM,您可以从下拉框中选择 “Gemma-2B-it” 来运行该模型的其余优化和推理加速步骤。当然,很容易切换到 “Gemma-7B-it” 和其他列出的型号。
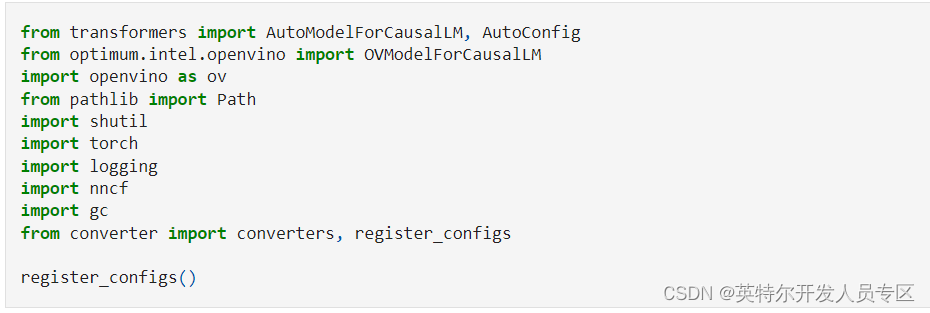
使用 Optimum Intel 实例化模型
Optimum Intel 是 Hugging Face Transformers 和 Diffuser 库与 OpenVINO™ 之间的接口,用于加速 Intel 体系结构上的端到端流水线。接下来,我们将使用 Optimum Intel 从 Hugging Face Hub 加载优化模型,并创建流水线,使用 Hugging Face API 以及 OpenVINO™ Runtime 运行推理。在这种情况下,这意味着我们只需要将 AutoModelForXxx 类替换为相应的 OVModelForXxx 类。
权重压缩
尽管像 Gemma-2B 这样的 LLM 在理解和生成类人文本方面变得越来越强大和复杂,但管理和部署这些模型在计算资源、内存占用、推理速度等方面带来了关键挑战,尤其是对于这种不足千元级的AI开发板等客户端设备。权重压缩算法旨在压缩模型的权重,可用于优化模型体积和性能。
我们的 Jupyter 笔记本电脑使用 Optimum Intel 和 NNCF 提供 INT8 和 INT4 压缩功能。与 INT8 压缩相比,INT4 压缩进一步提高了性能,但预测质量略有下降。因此,我们将在此处选择 INT4 压缩。

我们还可以比较模型权重压缩前后的模型体积变化情况。

选择推理设备和模型变体
由于 OpenVINO™ 能够在一系列硬件设备上轻松部署,因此还提供了一个下拉框供您选择将在其上运行推理的设备。考虑到内容使用情况,我们将选择 CPU 作为推理设备。

运行聊天机器人
现在万事具备,在这个 Notebook 代码示例中我们还提供了一个基于 Gradio 的用户友好的界面。现在就让我们把聊天机器人运行起来吧。
OpenVINO™ 助力谷歌大语言模型
小结:
整个的步骤就是这样!现在就开始跟着我们提供的代码和步骤,动手试试用 OpenVINO™ ™![]() 在哪吒开发板上运行基于大语言模型的聊天机器人吧。
在哪吒开发板上运行基于大语言模型的聊天机器人吧。
关于英特尔 OpenVINO™ 工具套件的详细资料,包括其中我们提供的三百多个经验证并优化的预训练模型的详细资料,请您点击https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html
除此之外,为了方便大家了解并快速掌握 OpenVINO™ 的使用,我们还提供了一系列开源的 Jupyter notebook demo。
运行这些 notebook,就能快速了解在不同场景下如何利用 OpenVINO™ 实现一系列、包括计算机视觉、语音及自然语言处理任务。
OpenVINO™ notebooks 的资源可以在 GitHub 下载安装:https://github.com/openvinotoolkit/openvino_notebooks 。

