- 1ubuntu安装vmware tools不起作用
- 219道ElasticSearch面试题(很全)_elastic 面试题
- 3项目管理职业发展前景怎么样?_项目经理行业发展前景
- 4AXI_UART调试说明-PS使用AXI_Uartlite拓展PL端串口资源_axi uart
- 5mysql千万级别的数据使用count(*)查询比较慢怎么解决?_mysql count统计数量很慢
- 6Java程序员可知为何公司宁花25K重新招人,也不花20K留住老员工?
- 7Linux 实操篇-网络配置_thinkpadlinuxping百度
- 8c++获取文件信息——_stat函数的使用__stat64i32
- 9VSCode下使用github初步_vscode github
- 10长度最小的子数组——滑动窗口法_长度最小的子数组滑动窗口
门控循环单元(GRU)_双向gru
赞
踩
矩阵连续乘积可以导致梯度消失或梯度爆炸的问题,这种梯度异常在实践中的意义:
-
我们可能会遇到这样的情况:早期观测值对预测所有未来观测值具有非常重要的意义。 考虑一个极端情况,其中第一个观测值包含一个校验和, 目标是在序列的末尾辨别校验和是否正确。 在这种情况下,第一个词元的影响至关重要。 我们希望有某些机制能够在一个记忆元里存储重要的早期信息。 如果没有这样的机制,我们将不得不给这个观测值指定一个非常大的梯度, 因为它会影响所有后续的观测值。
-
我们可能会遇到这样的情况:一些词元没有相关的观测值。 例如,在对网页内容进行情感分析时, 可能有一些辅助HTML代码与网页传达的情绪无关。 我们希望有一些机制来跳过隐状态表示中的此类词元。
-
我们可能会遇到这样的情况:序列的各个部分之间存在逻辑中断。 例如,书的章节之间可能会有过渡存在, 或者证券的熊市和牛市之间可能会有过渡存在。 在这种情况下,最好有一种方法来重置我们的内部状态表示。
在学术界已经提出了许多方法来解决这类问题。 其中最早的方法是”长短期记忆”(long-short-term memory,LSTM) (Hochreiter and Schmidhuber, 1997), 我们将在下一次讨论。 门控循环单元(gated recurrent unit,GRU) (Cho et al., 2014) 是一个稍微简化的变体,通常能够提供同等的效果, 并且计算 (Chung et al., 2014)的速度明显更快。 由于门控循环单元更简单,我们从它开始解读。
目录
1.门控隐状态
门控循环单元与普通的循环神经网络之间的关键区别在于: 前者支持隐状态的门控。 这意味着模型有专门的机制来确定应该何时更新隐状态, 以及应该何时重置隐状态。 这些机制是可学习的,并且能够解决了上面列出的问题。 例如,如果第一个词元非常重要, 模型将学会在第一次观测之后不更新隐状态。 同样,模型也可以学会跳过不相关的临时观测。 最后,模型还将学会在需要的时候重置隐状态。 下面我们将详细讨论各类门控。
1.1重置门和更新门
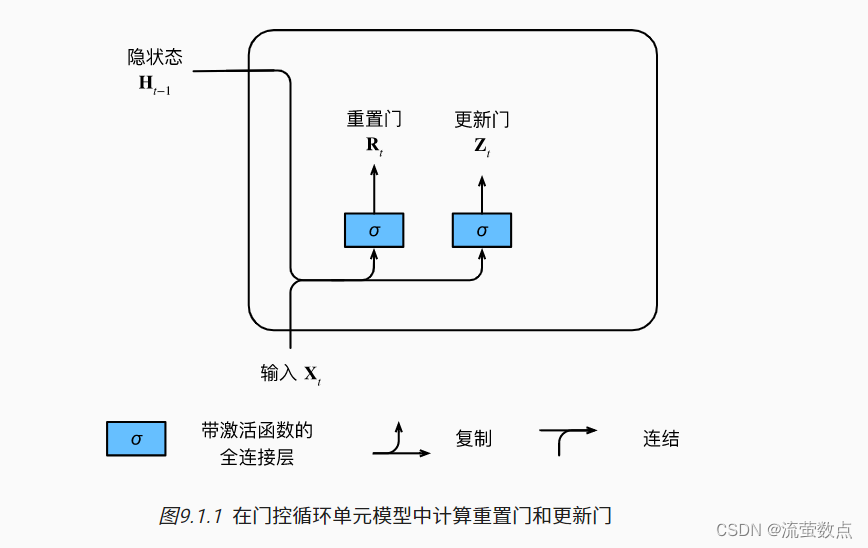
我们首先介绍重置门(reset gate)和更新门(update gate)。 我们把它们设计成(0,1)区间中的向量, 这样我们就可以进行凸组合。 重置门允许我们控制“可能还想记住”的过去状态的数量; 更新门将允许我们控制新状态中有多少个是旧状态的副本。
我们从构造这些门控开始。 图9.1.1 描述了门控循环单元中的重置门和更新门的输入, 输入是由当前时间步的输入和前一时间步的隐状态给出。 两个门的输出是由使用sigmoid激活函数的两个全连接层给出。

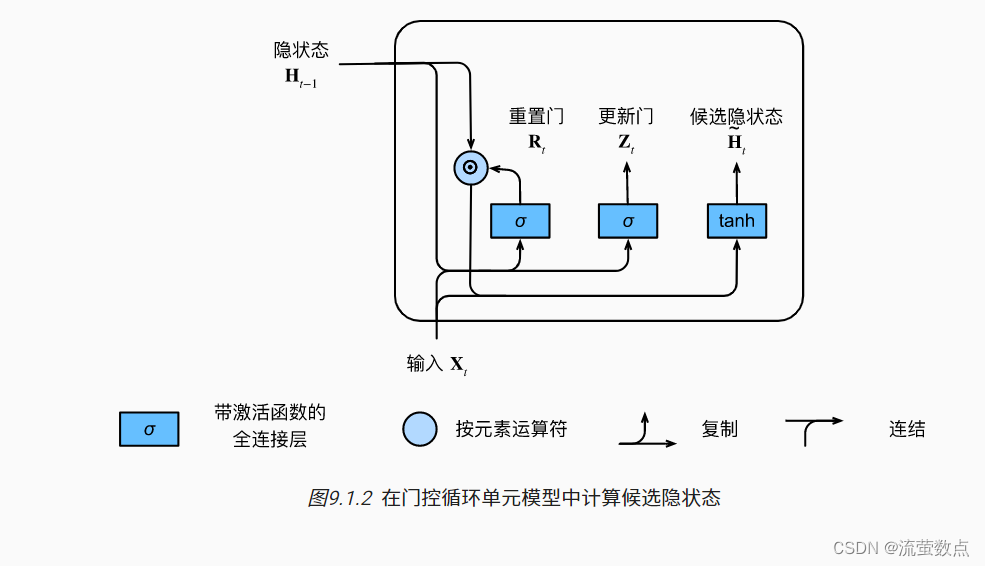
1.2候选隐状态

图9.1.2说明了应用重置门之后的计算流程.
1.3隐状态

这些设计可以帮助我们处理循环神经网络中的梯度消失问题, 并更好地捕获时间步距离很长的序列的依赖关系。 例如,如果整个子序列的所有时间步的更新门都接近于1, 则无论序列的长度如何,在序列起始时间步的旧隐状态都将很容易保留并传递到序列结束。
图9.1.3说明了更新门起作用后的计算流。
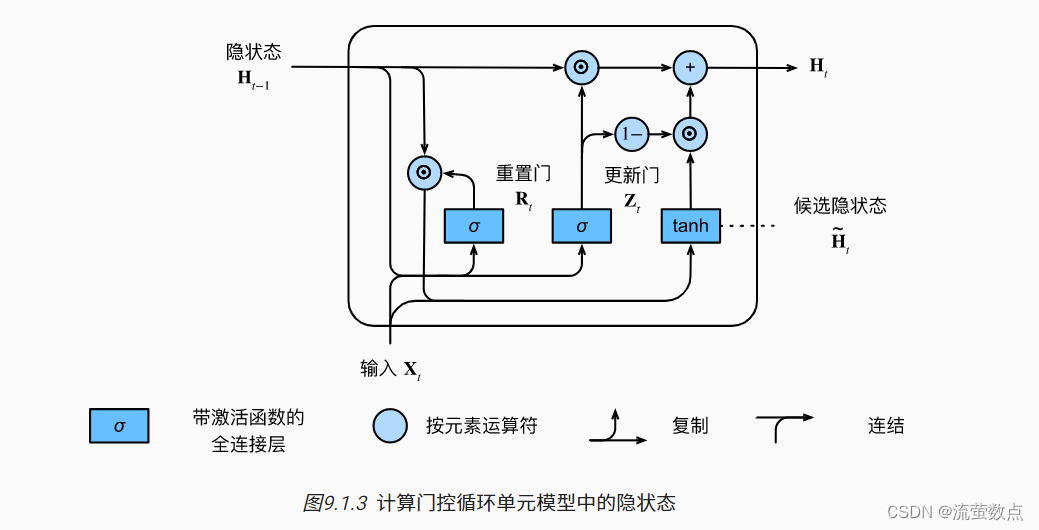
总之,门控循环单元具有以下两个显著特征:
-
重置门有助于捕获序列中的短期依赖关系;
-
更新门有助于捕获序列中的长期依赖关系。
2.从零开始实现
为了更好地理解门控循环单元模型,我们从零开始实现它。 首先,我们读取 8.5节中使用的时间机器数据集:
pip install mxnet==1.7.0.post1pip install d2l==0.15.0- from mxnet import np, npx
- from mxnet.gluon import rnn
- from d2l import mxnet as d2l
-
- npx.set_np()
-
- batch_size, num_steps = 32, 35
- train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
![]()
2.1初始化模型参数
下一步是初始化模型参数。 我们从标准差为0.01的高斯分布中提取权重, 并将偏置项设为0,超参数num_hiddens定义隐藏单元的数量, 实例化与更新门、重置门、候选隐状态和输出层相关的所有权重和偏置。
- def get_params(vocab_size, num_hiddens, device):
- num_inputs = num_outputs = vocab_size
-
- def normal(shape):
- return np.random.normal(scale=0.01, size=shape, ctx=device)
-
- def three():
- return (normal((num_inputs, num_hiddens)),
- normal((num_hiddens, num_hiddens)),
- np.zeros(num_hiddens, ctx=device))
-
- W_xz, W_hz, b_z = three() # 更新门参数
- W_xr, W_hr, b_r = three() # 重置门参数
- W_xh, W_hh, b_h = three() # 候选隐状态参数
- # 输出层参数
- W_hq = normal((num_hiddens, num_outputs))
- b_q = np.zeros(num_outputs, ctx=device)
- # 附加梯度
- params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
- for param in params:
- param.attach_grad()
- return params
2.2定义模型
现在我们将定义隐状态的初始化函数init_gru_state。 与 8.5节中定义的init_rnn_state函数一样, 此函数返回一个形状为(批量大小,隐藏单元个数)的张量,张量的值全部为零。
- def init_gru_state(batch_size, num_hiddens, device):
- return (np.zeros(shape=(batch_size, num_hiddens), ctx=device), )
现在我们准备定义门控循环单元模型, 模型的架构与基本的循环神经网络单元是相同的, 只是权重更新公式更为复杂。
- def gru(inputs, state, params):
- W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
- H, = state
- outputs = []
- for X in inputs:
- Z = npx.sigmoid(np.dot(X, W_xz) + np.dot(H, W_hz) + b_z)
- R = npx.sigmoid(np.dot(X, W_xr) + np.dot(H, W_hr) + b_r)
- H_tilda = np.tanh(np.dot(X, W_xh) + np.dot(R * H, W_hh) + b_h)
- H = Z * H + (1 - Z) * H_tilda
- Y = np.dot(H, W_hq) + b_q
- outputs.append(Y)
- return np.concatenate(outputs, axis=0), (H,)
2.3训练与预测
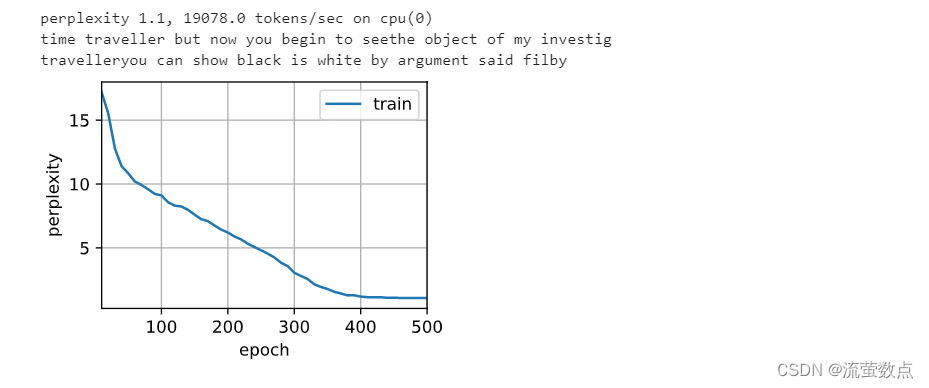
训练和预测的工作方式与 8.5节完全相同。 训练结束后,我们分别打印输出训练集的困惑度, 以及前缀“time traveler”和“traveler”的预测序列上的困惑度。
- vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
- num_epochs, lr = 500, 1
- model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
- init_gru_state, gru)
- d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
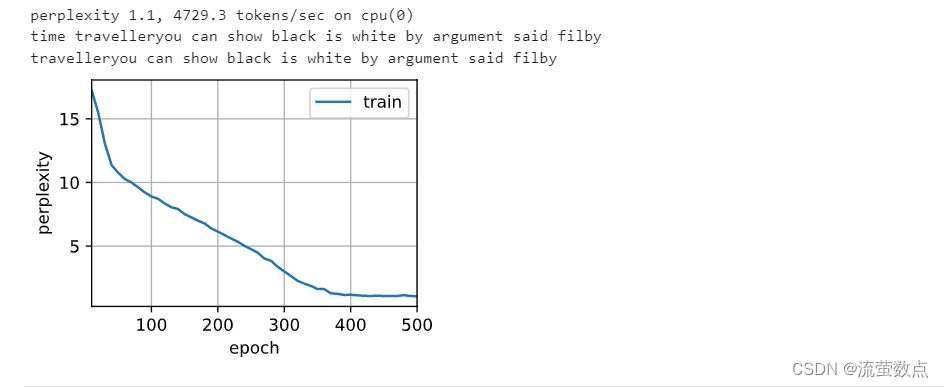
2.4简洁实现
高级API包含了前文介绍的所有配置细节, 所以我们可以直接实例化门控循环单元模型。 这段代码的运行速度要快得多, 因为它使用的是编译好的运算符而不是Python来处理之前阐述的许多细节。
- gru_layer = rnn.GRU(num_hiddens)
- model = d2l.RNNModel(gru_layer, len(vocab))
- d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)