
- 1BLE蓝牙笔记----数据包解析_pdu type
- 2【❤️考研、期末考、计算机二级❤️】C语言程序设计——第三章最简单的C程序设计 顺序程序设计_c语言程序设计题是怎么做的
- 3LLM-Blender: 用成对排序和生成融合集成大型语言模型_llm-blender: ensembling large language models with
- 4python 字典与集合详解_python 字典是集合
- 5实战Leetcode(四)
- 6MySQL命令行导入数据库_mysql导入数据库命令
- 7浅谈“全栈工程师需要掌握哪些技能”_全栈工程师要学什么
- 8操作系统实验三 观察Linux进程/线程的异步并发执行_并发count值计算
- 9探索未来:MetaSpore - 高效能AI计算框架的革新者
- 10安全笔记:渗透|Metasploit的MSF终端——理论_msf终端功能
屏蔽预训练模型的权重。 只训练最后一层的全连接的权重。_CNN模型合集 | 19 SENet...
赞
踩

SENet,胡杰(Momenta)在2017.9提出,通过显式地建模卷积特征通道之间的相互依赖性来提高网络的表示能力,SE块以微小的计算成本为现有的最先进的深层架构产生了显著的性能改进,SENet block和ResNeXt结合在ILSVRC 2017赢得第一名,Squeeze-and-Excitation Networks,作者源码核心思想:
- 提出背景:现有网络很多都是主要在空间维度方面来进行特征通道间的融合(如Inception的多尺度)。卷积核通常被看做是在局部感受野上,将空间上和特征维度上的信息进行聚合的信息聚合体。
- 特征重标定:通过学习的方式来自动获取到每个特征通道的重要程度(即feature map层的权重),以增强有用的特征,抑制不重要的特征。
- Squeeze:全局信息嵌入,全局平均池化成1*1
- Excitation:自适应调整,用两个全连接,训练参数W,得到每通道的权重s
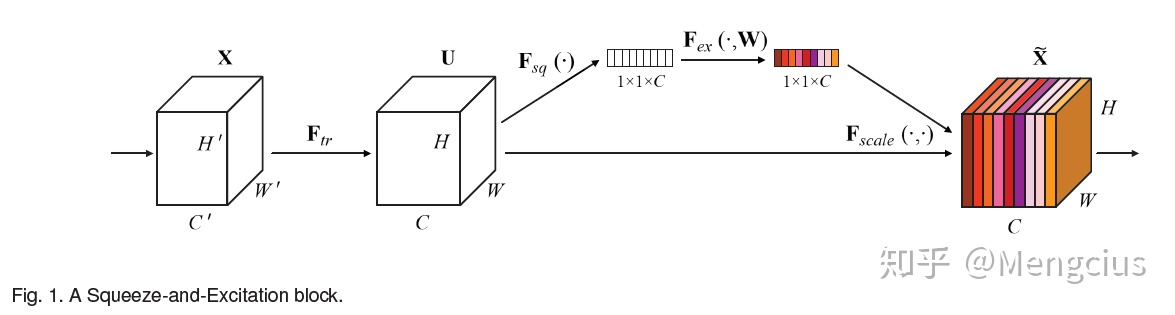
SE模块
- 总流程:X经过一系列传统卷积得到U,对U先做一个Global Average Pooling(Fsq),输出的1x1xC数据再经过两级全连接(Fex),最后用sigmoid限制到[0, 1]的范围,把这个值作为scale乘到U的C个通道上,输入到下级。
- Squeeze:顺着空间维度来压缩特征,就是在空间上做全局平均池化,每个通道的二维特征变成了一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的通道数相匹配。
- 用GAP是因为scale是对整个通道作用的,利用的是通道间的相关性,要屏蔽掉空间分布相关性的干扰。
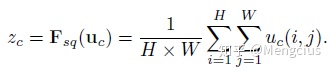
- Excitation:用2个全连接来实现 ,第一个全连接把C个通道压缩成了C/r个通道来降低计算量(后面跟了RELU,增加非线性并减少计算量),r是指压缩的比例一般取r=16;第二个全连接再恢复回C个通道(后面跟了Sigmoid归一化到0~1),Sigmoid后得到权重 s。s就是U中C个feature map的权重,通过训练的参数 w 来为每个特征通道生成权重s,其中参数 w 被学习用来显式地建模特征通道间的相关性。
- 用全连接是因为scale要基于全部数据集来训练得出,而不是基于单个batch,所以后面要加全连接层来进行训练。全连接层也融合了各通道的feature map信息。
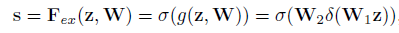
- Reweight(Scale):将 Excitation 的输出的权重看做是经过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,这就完成了在通道维度上的对原始特征的重标定。
- 低层级中scale的分布和输入的类别无关;靠后层级的scale大小和输入的类别强相关;在倒数第2层几乎所有的scale都饱和,大多数激活都接近于1,当所有激活都取值1时,SE块就会缩减为identity操作符;而最后一层的scale在不同的类上出现了类似的模式,不太重要。去掉最后阶段的SE块可以显著减少额外的参数计数,性能损失很小,因为越往后通道越多参数越大。

嵌入到现有网络中
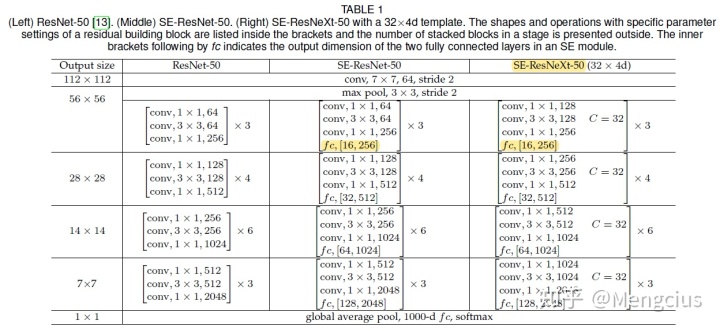
SE 模块可以嵌入到现在几乎所有的网络结构中,左图是将 SE 模块嵌入到 Inception 结构;右图是将 SE 嵌入到 ResNet 模块中,在 Addition 前对分支上 Residual 的特征进行了特征重标定,否则如果对 Addition 后主支上的特征进行重标定,由于在主干上存在 0~1 的 scale 操作,在网络较深 BP 优化时就会在靠近输入层容易出现梯度消散的情况,导致模型难以优化。

fc后面的内括号表示SE模块中两个完全连接的层的输出维度。
论文测试结果
在所有的结构上SENet要比非SENet的准确率更高出1%左右,而计算复杂度上只是略微有提升(增加的主要是全连接层,全连接层其实主要还是增加参数量,对速度影响不会太大)。在MobileNet上提升更高。而且SE块会使训练和收敛更容易。CPU推断时间的基准测试:224×224的输入图像,ResNet-50 164ms,SE-ResNet-50 167ms。

在ImageNet上不同尺寸的比较。SENet-154实质上是一个 SE-ResNeXt-152(64x4d),并做了一些其他修改和训练优化上的小技巧。可以看出 SENet 获得了迄今为止在 single-crop 上最好的性能。

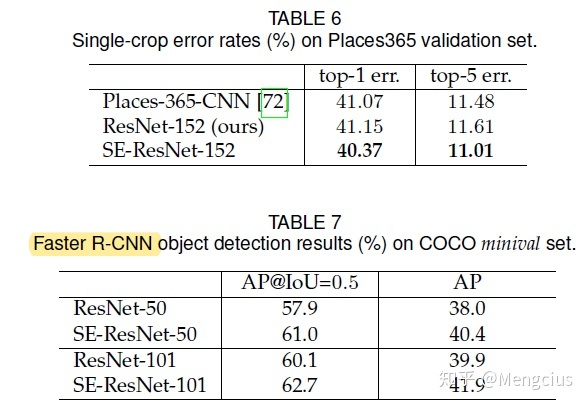
在场景分类和目标检测上的效果。
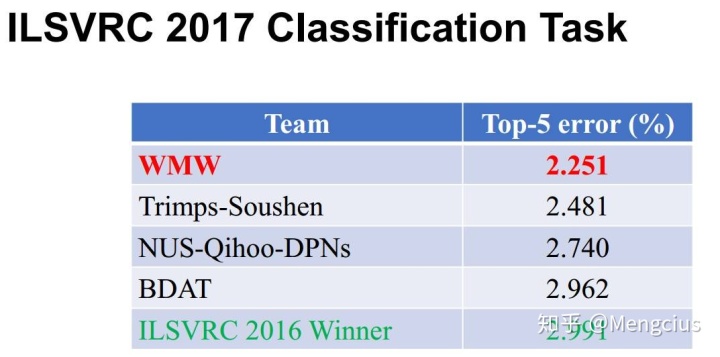
在 ILSVRC 2017 竞赛中,SENet-154在测试集上获得了 2.251% Top-5 错误率。对比于去年第一名的结果 2.991%, 我们获得了将近 25% 的精度提升。
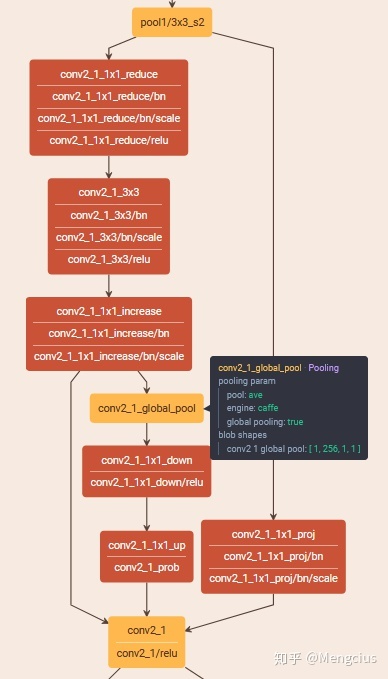
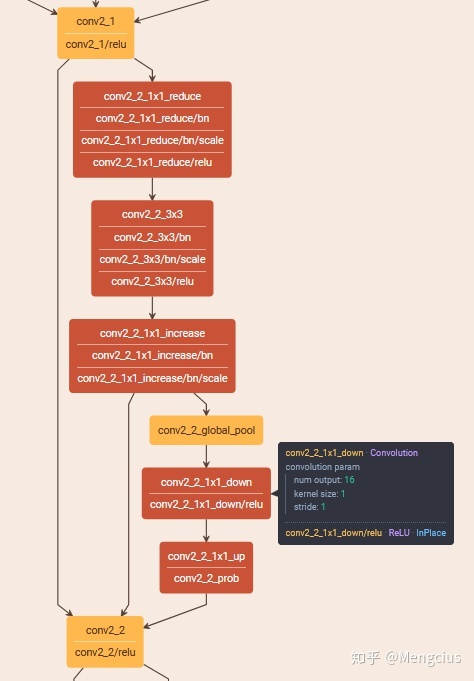
caffe可视化
SENet-154.prototxt
参考
作者课件 翻译 公式参考
作者源码(caffe): https://github.com/hujie-frank/SENet(有模型)
SENet-Tensorflow推理: https://github.com/taki0112/SENet-Tensorflow
SENet-PyTorch训练: https://github.com/miraclewkf/SENet-PyTorch
MXNet训练: https://github.com/bruinxiong/SENet.mxnet
另外在我的主页中还能看到其他系列专栏:【OpenCV图像处理】【斯坦福CS231n笔记】

