- 1初识Windows8应用商店开发
- 2spring框架学习记录(1)
- 3《ClickHouse企业级应用:入门、进阶与实战》5 ClickHouse函数_clickhouse进阶
- 4git多人协作用户权限配置_gitshare权限
- 5使用微软Phi-3-mini模型快速创建生成式AI应用_phi3 本地 部署 安装 csdn
- 6如何部署一个chat copilot服务_copilot本地化部署
- 7关于pytorch模型猫狗图片识别 以及代码和数据集_pytorch猫狗识别
- 8多个API接口
- 9如何在mysql中执行sql脚本文件_mysql执行sql文件
- 10在Ubuntu上搭建并通过systemctl和Nginx管理Minecraft Java版服务器
【大数据】分布式数据库HBase下载安装教程
赞
踩

目录
1.下载安装
HBase和Hadoop之间有版本对应关系,之前用的hadoop是3.1.3,选择的HBase的版本是2.2.X。
下载地址:
配置环境变量:
之前在PATH中已经配置了JAVA的环境变量,直接用:隔开,追加一个hbase的环境变量
export JAVA_HOME=/jdk/jdk8 export PATH=$JAVA_HOME/bin:$PATH:/hbase/hbase-2.2.2/bin export CLASSPATH="."
刷新环境变量:
source /etc/profile
查看是否生效:
hbase version

2.配置
HBASE有三种模式:
-
单机模式
-
伪分布式模式
-
分布式模式
分布式模式太吃机器性能了,学习来说的话伪分布式模式就够了。本文将会讲解单机模式和伪分布式模式的配置。
运行HBase的前置环境:
-
JDK
-
对应版本的Hadoop
-
SSH
以上环境在我们之前安装hadoop的时候就已经安装过了,此处不再赘述。
2.1.启动hadoop
我用的Windows的wsl版本的ubuntu,所以没有用systemctl命令,而是用service命令来直接启动服务。
hbase依赖于hdfs,所以要先启动hdfs,hdfs依赖于ssh,所以最先启动ssh。
service start ssh ./sbin/start-dfs.sh
2.2.单机模式
在HBase的单机模式下,所有HBase组件(包括HMaster、HRegionServer以及ZooKeeper)都运行在一个JVM进程中,且不依赖于Hadoop的HDFS,而是直接使用本地文件系统来存储数据。
HBase的配置文件所在位置:
vi /hbase/hbase-2.2.2/conf/hbase-env.sh
配置如下内容:
export JAVA_HOME=/jdk/jdk8/ #设置JDK路径 export HBASE_MANAGES_ZK=true #HBASE本身自带一个zookeeper,设置使用自带的zookeeper,而不是外界的
配置
vi /hbase/hbase-2.2.2/conf/hbase-site.xml
设置rootdir,用来存储hbase的数据,不设置数据的存储路径的话,每次重启hbase都会丢数据。
<configuration> <property> <name>hbase.rootdir</name> <value>file:///usr/local/hbase/hbase-tmp</value> </property> </configuration>
启动HBase:
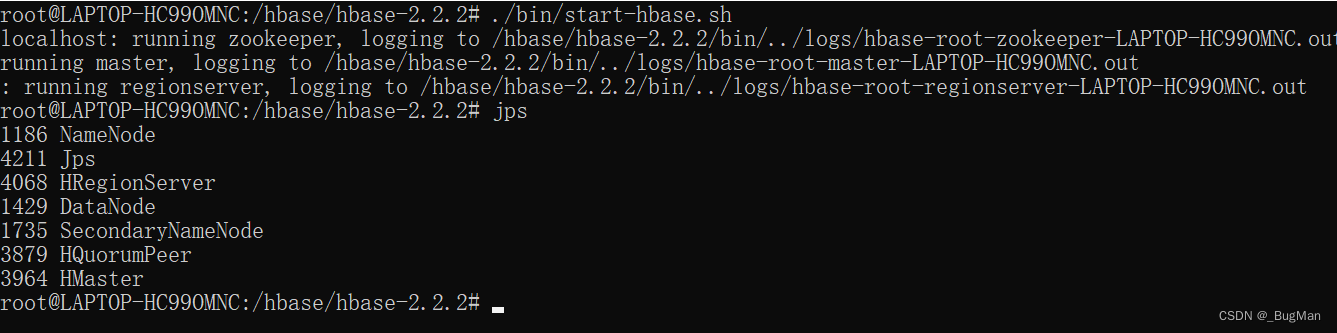
./bin/start-hbase.sh
进入交互式界面:
./bin/hbase shell
在交互式界面可以指向hbase的命令:

list指令查看所有,exit命令退出交互式界面,stop-hbase.sh关闭hbase:

2.3.伪分布式集群
伪分布式模式模拟了分布式环境,但实际上所有HBase组件(包括HMaster、多个HRegionServer以及ZooKeeper)仍然运行在同一台物理机器上,但是每个组件都在各自的JVM进程中运行。此外,伪分布式模式会使用Hadoop的HDFS作为底层存储,这意味着数据会被分布在本地文件系统的不同目录中,模拟了分布式存储的效果。
配置hbase-env.sh:
export HBASE_CLASSPATH=/hadoop/hadoop-3.1.3/etc/hadoop/ #配置hadoop的配置文件路径,挂载到hdfs上
配置hbase-site.xml:
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://localhost:9000/hbase</value> </property> #开启分布式模式 <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> </configuration>
再启动可以看到:
HBase相关组件启动了