- 1一文带你直观感受,BPM管理系统如何在低代码平台实现搭建_.net bpm系统开发
- 2时频分析之STFT:短时傅里叶变换的原理与代码实现(非调用Matlab API)
- 3c++实现socket以json格式传输图片_c++ tcpip 传送 json \
- 4Mysql查询性能优化_update inner join select 优化
- 5axios 传递参数的方式(data 与 params 的区别)_axios post data
- 6从webstrom转到vscode(vscode插件推荐)_vscode webstorm插件
- 7《软件设计师教程:计算机网络浅了解计算机之间相互运运作的模式》
- 8c语言编程求所有四位可逆素数,四位可逆素数
- 9Cache-Control 的含义_@cachecontrol
- 10Github 2024-03-29 开源项目日报Top10_github ai 项目star top10
【HTTP下】总结{重定向/cookie/setsockopt/流操作/访问网页/总结}
赞
踩
1.请求头
- 一个网页含有诸多元素 每一个元素就是一个资源 浏览器想要访问某个网页 实际就是通过网络获得了一些在线资源 浏览器向服务端发送请求去获得一网页 本质是发起了多个请求 获得了多个资源 诸多资源组合在一起 形成你看到的网页 这也就是为什么在网络不好的时候 有的图片加载粗来了 有的还在转圈圈
- 假设一个网页由100个元素组成 那么浏览器就会向服务端发起101个请求,多出来的那个请求是请求网页 服务端就会创建多个线程把多个资源推给客户端
- http底层是基于tcp的
- 一次请求一次响应就关闭连接这是短连接==低效 http1.0只能支持
- 多次请求多次响应—一轮请求和响应再断开链接—长连接http1.1 默认支持
情景:老客户端访问新服务器;新客户端访问老服务器
开始进行请求和访问时 要协商进行长/短连接 Connection属性:keep-alive表示客户端支持长连接!浏览器构建的请求包含该字段,服务端识别后知道客户端可以支持的连接方式 然后服务端也返回一个该字段(我们模拟的没有实现该功能) 双方协商决定采用哪种连接。
短连接测试
通过在网页中添加不同的(相同的图片可能导致浏览器使用缓存而不构建新的请求)图片 看看服务端接收到了几个请求 来反映浏览器为了获取这个完整的网页发起了几个请求
rz/sz
在 Linux 环境中,rz 和 sz 这两个命令通常与 lrzsz 软件包相关,它们用于在终端中通过 Zmodem 协议进行文件传输。rz 命令用于接收文件,而 sz 命令用于发送文件。这些命令通常在终端仿真器(如 xterm, gnome-terminal 等)和串行连接(如 SSH 会话或串口连接)中使用,以在本地和远程系统之间传输文件。
关于 -E 选项,它不是 lrzsz 软件包中 rz 命令的标准选项。如果你在某个特定的环境或上下文中看到了 rz -E,这很可能是该环境或应用特有的用法或脚本。
要了解 rz 和 sz 命令的具体用法和选项,你可以查看它们的 man 页面(如果已安装):
bash
man rz
man sz
或者,如果你不确定这些命令是否已经安装在你的系统上,你可以尝试使用 which 或 command 命令来查找它们:
bash
which rz
which sz
或者
bash
command -v rz
command -v sz
如果 lrzsz 已经安装在你的系统上,这些命令应该会显示它们的路径。然后,你可以使用 man 命令查看相关的手册页面。
如果你在某个特定的应用或环境中看到 rz -E,并且不确定它的含义,最好的做法是查阅该应用或环境的文档,或者在相关的社区、论坛中寻求帮助。
最后,需要注意的是,lrzsz 和其相关的 rz 和 sz 命令可能不是所有 Linux 发行版都默认安装的。如果你找不到这些命令,你可能需要使用包管理器(如 apt, yum, dnf, pacman 等)来安装 lrzsz 软件包。
2.cookie

http协议默认是无状态的。目前我们手写的http服务器,刷新一下浏览器,还要重新获取资源,人家成熟的服务器,是如何不再重新加载资源?比如b站,进去要先登录,换了一个新的网页,他是怎么直到你仍处于登陆状态而不让你再次登录的?或者关闭了该网页/该浏览器/关机 再次访问 他不在让你重新登录了
回答
http对登录用户的会话保持功能
首次访问浏览器 注册+登录 成功登陆后 服务端返回重定向内容 让你跳转到首页让你去访问b站 与此同时 他还会返回多个(账号和密码可能是分开的cookie,分别保存)Set-Cookie(我们手写测试服务端是自己添加的cookie响应,实际上是服务端捕获用户输入创建cookie然后以响应的方式返回客户端,客户端保存,下次请求时自动携带):usrname=xxx pswd=xxx给浏览器,浏览器会在客户端创建一个cookie文件存放该信息,下一次通过该浏览器访问b站时会自动携带该cookie的内容 即虽然你没有显示输入账号密码 但是底层依然经过了浏览器发送账号密码请求服务端识别认证的这一过程 有的浏览器会设置记忆cookie的时间即一段时间后再次访问仍要显示输入账号密码,因为cookie失效了
cookie的保存
- 内存级:客户端浏览器是一个进程 进程malloc一个空间用来存放cookie 只要浏览器不关闭,访问b站的其他连接时 它不会让你重新登录 因为由cookie 的存在。但是一旦浏览器关闭 cookie失效 。
- 文件级:cookie保存在磁盘上(浏览器安装路径) 关闭了浏览器 下次再访问b站 依然有记忆功能
目前浏览器出于安全考虑 通常是内存级的

安全问题1.cookie盗取被人冒充身份2.个人信息泄露
cookie的设置是为了方便用户使用的 但是 一旦账号密码被记录 就有可能被盗取的风险 如果通过某种技术手段 把你的浏览器的cookie文件偷取 那么坏人就可以通过该文件以你的身份访问对应的资源如:盗号。更重要的,cookie不仅保存了账号密码,如果保存了其他信息,那么个人隐私是不是就泄露了!把密码输入到“网络”“计算机”中 实际上 并没有绝对的安全!
解决
拓展题外
有的手机会让你指纹验证再让你使用之前记录的密码–在安全性和方便性之间的妥协
session
redis
Redis(Remote Dictionary Server)是一个开源的使用ANSI C语言编写的、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。它具备以下主要功能和特性:
高速缓存:作为一种高性能的缓存系统,Redis将数据存储在内存中,以提供快速的读写访问。这使得Redis非常适用于缓存数据库查询结果、热门文章、用户会话等场景。
发布与订阅:Redis支持发布与订阅模式,可以实现消息的发布和订阅。发布者将消息发送到指定的频道,订阅者可以订阅感兴趣的频道并接收发布的消息。
事务支持:Redis支持事务,可以将一组操作原子性地执行。通过MULTI、EXEC、WATCH等命令,可以保证一系列操作的原子性,类似于数据库的事务。
数据持久化:Redis提供了两种数据持久化方式,即RDB(Redis Database)快照和AOF(Append-Only File)日志。这确保了即使在系统崩溃的情况下,数据也不会丢失。
Lua脚本支持:Redis内置了Lua脚本引擎,可以编写和执行Lua脚本。通过Lua脚本,可以在服务器端实现复杂的原子操作,提供更灵活的功能扩展。
此外,Redis支持多种基本数据结构,包括String(字符串)、Hash(散列)、List(列表)、Set(集合)和Sorted Set(有序集合)。这些数据结构使得Redis能够处理各种复杂的数据操作场景。
总的来说,Redis以其高性能、丰富的功能和灵活的扩展性,成为了许多企业和开发者在处理大量数据时的首选工具。无论是用于缓存、消息队列、实时分析还是其他场景,Redis都能提供出色的性能和可靠性。
session文件
Session文件是指服务器端用来存储用户信息的文件,通常以session ID的形式存储在客户端的Cookie中,用于在用户访问网站时保持用户状态及数据。Session文件是被序列化了的文件,其格式一般为“变量名|类型:长度:值”,并用分号隔开每个变量,有些信息如长度和类型是可以省略的。
在Web开发中,服务器可以为每个用户浏览器创建一个会话对象(session对象),每个客户端用户访问时,服务器都为每个用户分配一个唯一的会话ID(Session ID)。Session的作用主要是用于保存每个用户的专用信息,这些信息保存在Web服务器中,其数据量可大可小。Session的生存期是用户持续请求时间再加上一段时间(一般是20分钟左右),当Session超时或被关闭时将自动释放保存的数据信息。
在Java中,可以使用Servlet API提供的HttpSession接口来创建并管理Session。Session的创建过程通常包括用户发送请求到服务器并携带Session标识符(通常是通过Cookie或URL参数传递),服务器根据Session标识符来查找或创建对应的Session,然后将Session标识符发送给客户端以便在后续的请求中识别用户。
此外,对于应用服务器而言,开启Web容器的Session复制功能可以在集群中的服务器之间同步Session对象,确保每台服务器上都保存所有用户的Session信息,从而防止因某台机器宕机导致的Session数据丢失。
如需更深入地了解Session文件及其应用,建议查阅相关的Web开发文档或咨询专业的技术人员。
session安全机制
- 服务端创建了诸多session文件 用来存储用户的登录的时间状态账号密码
文件内容在redis集群中维护(session文件是有很多的 先描述在组织!) - 服务端首次接收到客户端的账号密码会创建一个session文件 文件用sessionId来在该服务器内唯一标识 然后将id返回给客户端 客户端在cookie文件中保存的就是id。
- 这样使得个人信息无法泄露 即便有人盗取id通过你的身份访问资源 但是他无法知道你的信息是什么 账号密码由服务端维护 与浏览器相比 一个公司的服务端安全性要高得多
个人信息通过session机制能防止泄露 那么cookie被盗取这一行为可避免吗
不可避免!尽管服务器再好 使用浏览器的小白仍然是不可控因素 小白点击非法链接 使得不法分子捕获cookie
sessionId由服务器统一管理分配 可能存在一下几种防范:
- 服务端识别到间隔很短的两次客户端请求访问的地区发生变化 立马设置对应的sessionId为无效 即便客户端发来请求 此时也无法通过原身份访问
- 同一账号在不同的地区登录 需要重新输入密码
即用户及客户端的行为合法性是不可预测的 只能通过服务端用一些手段来尽可能地维护客户端安全问题
理解
- Set-Cookie选项是服务端构建的响应报头中的属性告知浏览器这是你曾经向我发送的账户信息 浏览器可以根据该属性保留到cookie文件里

- cookie是浏览器发起的http请求包含的属性 这是浏览器曾经发送给服务端的账户信息 如今浏览器构建请求时不用用户输入 自动携带该属性访问服务端 服务端接收到后发现浏览器携带该属性如果该属性的信息匹配 则不用用户输入密码 直接转到主页
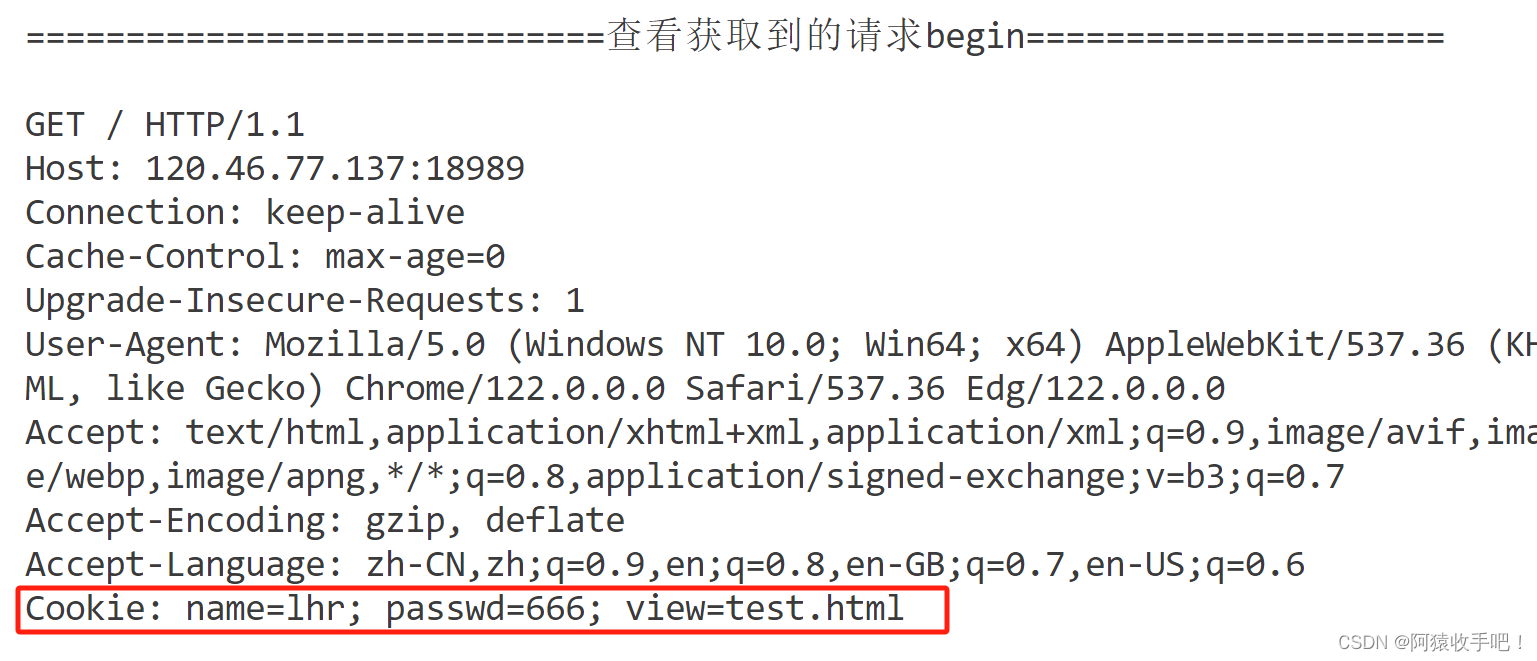
- 如果我们在浏览器的cookie文件里删除掉信息 则下次登录要重新输入
- 在百度页面我们在url后添加
?name=xxx百度会刷新该页 表明你提交的信息提交到了该页面 实际上提交时我们都是通过表单提交的 get就是拼到url后 post是在请求正文中
第一次请求没有携带cookie
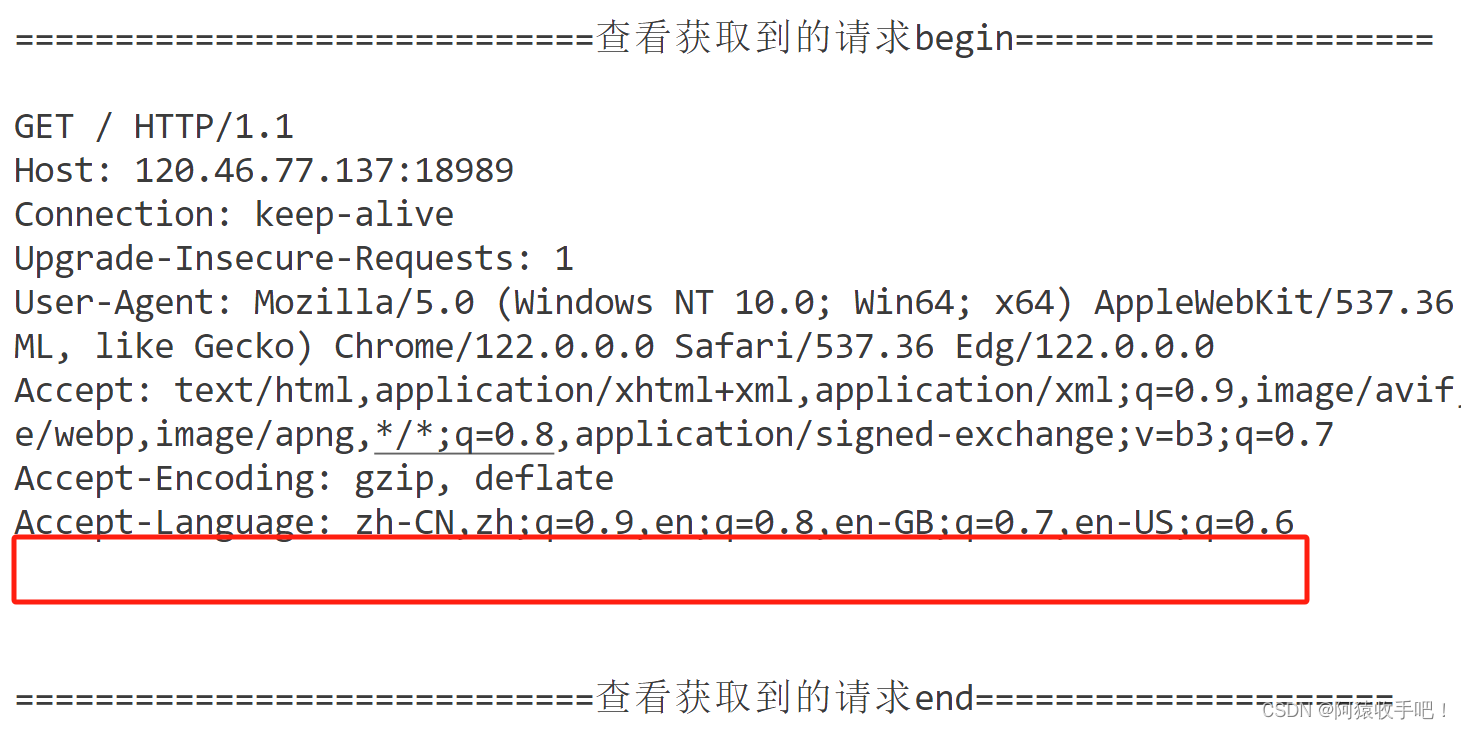
构建的响应返回了Set-Cookie 模拟浏览器输入了账号密码 服务端识别解析后返回

第二次请求自动携带
3.vim跳转/搜索
跳转到一个单词
在 Vim 编辑器中,如果你想跳转到文件中一个特定单词的下一个或上一个出现位置,你可以使用 Vim 的搜索功能。这里有一些方法可以帮助你实现这个目的:
普通模式搜索:
按下 / 键,然后输入你想查找的单词,接着按下 Enter 键。Vim 会将光标移动到该单词的下一个出现位置。
如果你想反向查找(即查找上一个出现位置),可以按下 ? 键,然后输入单词并按下 Enter。
在搜索结果中,你可以使用 n 键来查找下一个匹配项,N 键来查找上一个匹配项。
使用 * 和 # 键:
将光标移动到你想查找的单词上。
按下 * 键,Vim 会将光标移动到该单词的下一个出现位置。
按下 # 键,Vim 会将光标移动到该单词的上一个出现位置。
跨文件搜索:
如果你想在整个项目中查找一个单词,你可以使用 Vim 的 :grep 命令结合外部搜索工具(如 ag, rg 或 grep)。首先,你需要配置 Vim 以使用这些工具。然后,你可以使用 :grep <单词> 命令来搜索。
另一个选择是使用 Vim 的插件,如 cscope 或 ag.vim,它们提供了更强大的跨文件搜索功能。
使用插件增强功能:
Vim 的插件生态系统非常丰富,有很多插件可以帮助你更高效地查找和跳转到单词。例如,YouCompleteMe 插件提供了强大的自动补全和导航功能。
记住,Vim 是一个高度可配置的编辑器,你可以根据自己的需要调整其行为和快捷键。如果你经常需要查找和跳转到特定单词,考虑将常用的搜索命令映射到更方便的快捷键上,以提高工作效率。
最后,虽然 Vim 提供了强大的文本处理功能,但对于复杂的代码导航和查找任务,集成开发环境(IDE)可能更为适合。IDE 通常提供了更直观和强大的代码导航工具,以及代码补全、重构和其他高级功能。
跳转到变量定义
在 Vim 编辑器中,如果你想跳转到变量的定义,你通常需要使用标签(tags)文件,这通常是通过 ctags 工具生成的。然而,对于变量来说,情况有点复杂,因为变量可能不像函数那样有明确的“定义”。变量可能只是被声明或赋值在某个地方。
如果你有一个 tags 文件,并且该变量在文件中被标记为一个标签(这取决于你的编程语言和 ctags 的配置),那么你可以使用 Vim 的跳转功能。通常,你可以使用 Ctrl+] 来跳转到标签的定义。
但是,对于变量来说,这种方法可能并不总是有效,因为不是所有的变量都会被 ctags 标记为标签。
另一种方法是使用 Vim 的搜索功能来查找变量的使用或声明。你可以使用以下命令:
:grep 命令结合外部工具(如 ag, rg 或 grep)来搜索整个项目。
使用 Vim 的内置搜索功能,如 /(正向搜索)或 ?(反向搜索)来在当前文件中查找变量。
使用 Vim 的全局搜索功能,如 :vimgrep 或 :grep(如果配置了外部搜索工具)来在整个项目中查找。
如果你经常需要查找变量的定义或引用,你可能想要考虑使用专门的静态代码分析工具或集成开发环境(IDE),这些工具通常提供了更强大的导航和查找功能。
在 Vim 中,你还可以考虑使用插件来增强这些功能,比如使用 cscope 或 YouCompleteMe 等插件,它们可以提供更智能的跳转和补全功能。
最后,记住 Vim 是一个非常强大的文本编辑器,它的功能可以通过配置和插件进行高度定制。如果你发现 Vim 的默认功能不满足你的需求,不妨探索一下 Vim 的社区和插件生态,看看是否有更适合你工作流程的解决方案。
xshell中Vim编辑器跳转到函数定义
在Xshell中的Vim编辑器中,想要跳转到函数定义,你可以按照以下步骤操作:
首先,确保你已经安装了ctags工具。在Ubuntu系统中,你可以通过执行sudo apt-get install ctags命令来安装它。
然后,在你的项目工程目录下(即源文件目录)执行ctags -R *命令。这将会生成一个tags文件,该文件包含了项目中所有函数和变量的标签信息。
接下来,打开你想要编辑的源文件,并将光标移动到你想跳转的函数调用处。然后,按下组合键ctrl + ],Vim就会根据tags文件中的信息,跳转到该函数定义的位置。
如果你想从函数定义处跳回到函数调用处,你可以使用组合键ctrl + o。
需要注意的是,如果你的Vim编辑器在按下ctrl + ]时提示“E433: No tags file”,那么可能是因为Vim没有找到tags文件。你可以在你的~/.vimrc配置文件中添加以下设置来指定tags文件的路径:
vim
set tags=./tags,./TAGS,tags;,TAGS;
set autochdir
- 1
- 2
添加完毕后,你需要重新加载配置文件或者重启Vim编辑器,使设置生效。
这样,你就可以在Xshell中的Vim编辑器中方便地跳转到函数定义了。
4.setsockopt
在Linux网络编程中,setsockopt函数用于设置与某个套接字(socket)关联的选项。这些选项控制套接字的各种行为,如接收缓冲区大小、广播行为、是否使用TCP_NODELAY等。
setsockopt函数的原型如下:
c
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
参数说明:
sockfd:要设置选项的套接字的文件描述符。
level:指定选项中解释的级别。对于套接字选项,通常设置为SOL_SOCKET。但是,有些选项可以在不同的级别上设置,例如IP选项可以在IPPROTO_IP级别上设置。
optname:要设置的选项的名称。
optval:指向包含选项值的缓冲区的指针。
optlen:optval缓冲区的大小。
以下是一些常见的setsockopt选项示例:
设置接收缓冲区大小:
c
int bufsize = 8192; // 8KB buffer
setsockopt(sockfd, SOL_SOCKET, SO_RCVBUF, &bufsize, sizeof(bufsize));
设置TCP_NODELAY(禁用Nagle算法):
c
int flag = 1;
setsockopt(sockfd, IPPROTO_TCP, TCP_NODELAY, &flag, sizeof(flag));
设置广播:
c
int broadcast = 1;
setsockopt(sockfd, SOL_SOCKET, SO_BROADCAST, &broadcast, sizeof(broadcast));
设置重用地址(允许立即重用本地地址和端口号):
c
int reuse = 1;
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse));
注意:并非所有选项都适用于所有类型的套接字或所有协议。例如,某些选项可能仅对TCP套接字有意义,而其他选项可能仅对UDP套接字有意义。因此,在调用setsockopt之前,请确保您了解其选项和预期的行为。
最后,setsockopt函数在成功时返回0,在失败时返回-1并设置errno以指示错误。因此,您应该始终检查setsockopt的返回值以确保成功。
被重用的意思
允许立即重用本地地址和端口号通常与网络编程中的SO_REUSEADDR和SO_REUSEPORT套接字选项有关,尤其是在像TCP这样的面向连接的协议中。以下是关于这两个选项的解释,包括它们的意义和用途:
SO_REUSEADDR
意义:允许套接字绑定到一个已经在使用(或最近使用过但仍在TIME_WAIT状态)的本地地址和端口上。
目的:在服务器程序重新启动或服务器进程崩溃后,能够立即重启并监听相同的端口,而不需要等待之前的连接完全关闭(这可能需要几分钟,尤其是在TIME_WAIT状态下)。
作用:
加速服务器重启过程。
在某些情况下,防止因地址已被使用而导致的“Address already in use”错误。
允许多个服务器进程(通常在不同的IP地址或不同的网络接口上)绑定到相同的端口。
SO_REUSEPORT
意义:允许多个套接字绑定到同一个本地地址和端口上。
目的:在多进程或多线程服务器中,使得多个服务器进程/线程可以共享相同的端口,而每个进程/线程都能接收到客户端的连接。
作用:
提高服务器的可扩展性和性能,因为多个进程/线程可以并行处理连接。
在负载均衡环境中,使得多个后端服务器可以监听同一个前端IP和端口,而流量可以在这些服务器之间自动分配。
在某些操作系统中,SO_REUSEPORT还可以与快速回收和分发套接字(也称为“套接字接受加速”)相结合,以减少接收新连接时的系统开销。
注意:虽然这些选项在某些情况下很有用,但它们也可能带来一些潜在的问题,如端口冲突、数据混乱等。因此,在使用这些选项时,需要仔细考虑并测试您的应用程序以确保其正确性和稳定性。
5.流操作
5.1定位读取指针
这段代码是使用C++的std::istream(通常与std::ifstream一起使用)来操作一个输入流(如文件)的示例。代码的目的是获取输入流(在这里是in)的长度(以字节为单位),然后重置到流的开始位置。
下面是代码的详细解释:
in.seekg(0, std::ios_base::end);
这行代码将输入流in的读取指针(get pointer)移动到流的末尾。std::ios_base::end是一个枚举值,表示流的末尾。当你将偏移量设置为0并指定std::ios_base::end时,你实际上是在说“移动到流的末尾”。
2. auto len = in.tellg();
tellg函数返回当前读取指针的位置(以字节为单位)。因为在上一步中我们已经将读取指针移动到了流的末尾,所以tellg现在返回的是整个流的长度(以字节为单位)。这个值被存储在变量len中。
3. in.seekg(0, std::ios_base::beg);
这行代码将读取指针重置回流的开始位置。std::ios_base::beg是一个枚举值,表示流的开始。现在,你可以从流的开始位置重新读取数据。
这段代码通常用于在读取文件之前先确定文件的大小,或者在你需要多次遍历同一个文件时,将读取指针重置到文件的开始位置。
注意:这段代码假设流是支持seek操作的,如文件流。如果你尝试在不支持seek的流(如std::cin)上使用seekg和tellg,结果可能是未定义的。
5.2ifstram::read()
std::ifstream的read接口用于从文件中读取指定数量的字节。它有两个参数:一个是指向要存储数据的缓冲区的指针,另一个是要读取的字节数。这个接口通常用于读取二进制文件,因为它按字节进行读取,而不考虑任何特定的文本编码或换行符。
下面是如何使用std::ifstream的read接口的一个例子:
cpp
#include
#include
#include
int main() {
std::ifstream in(“example.bin”, std::ios::binary);
if (!in.is_open()) {
std::cerr << “Failed to open file” << std::endl;
return 1;
}
// 定位到文件末尾以获取文件大小
in.seekg(0, std::ios::end);
std::streamsize len = in.tellg();
in.seekg(0, std::ios::beg);
// 分配足够的空间来存储文件内容
std::vector<char> buffer(len);
// 读取文件内容到buffer中
in.read(buffer.data(), len);
// 检查是否读取了所有字节
if (in.gcount() != len) {
std::cerr << "Failed to read entire file" << std::endl;
return 1;
}
// 此时buffer包含了文件的所有内容
// 可以在这里处理buffer中的数据...
// 关闭文件
in.close();
return 0;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
}
在这个例子中,我们首先使用std::ifstream的seekg和tellg函数来确定文件的大小。然后,我们创建一个std::vector来存储文件的内容,并使用read函数来读取文件。最后,我们检查gcount函数返回的读取字节数是否与预期的文件大小相匹配。
请注意,read函数不会添加任何终止字符(如null终止符)到读取的数据中,所以你需要确保在后续处理这些数据时考虑到这一点。如果你正在处理文本文件,并且想要按行读取,那么使用std::getline可能会更加方便。但是,如果你正在处理二进制数据,那么read函数是更合适的选择。
6.总结
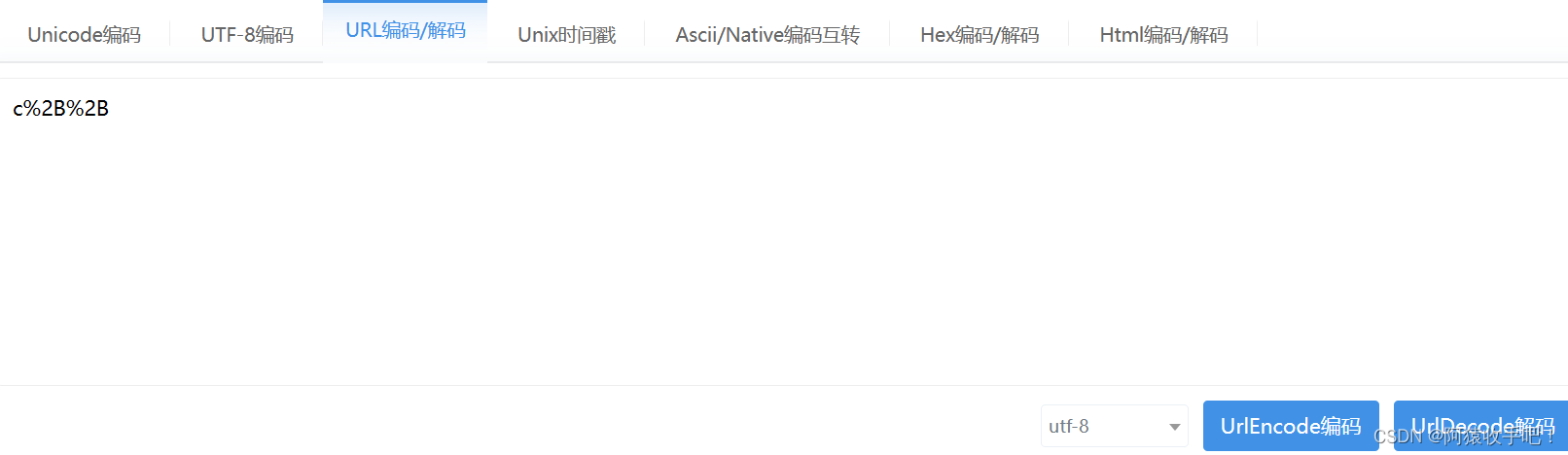
6.1 百度搜索框搜索功能字符
- 网上有现成的decode/encode代码 直接用 做了解即可
- 浏览器对输入框的信息编码 交给服务器的就是编码后的数据 服务端拿到数据后在解码
- 在线转换工具
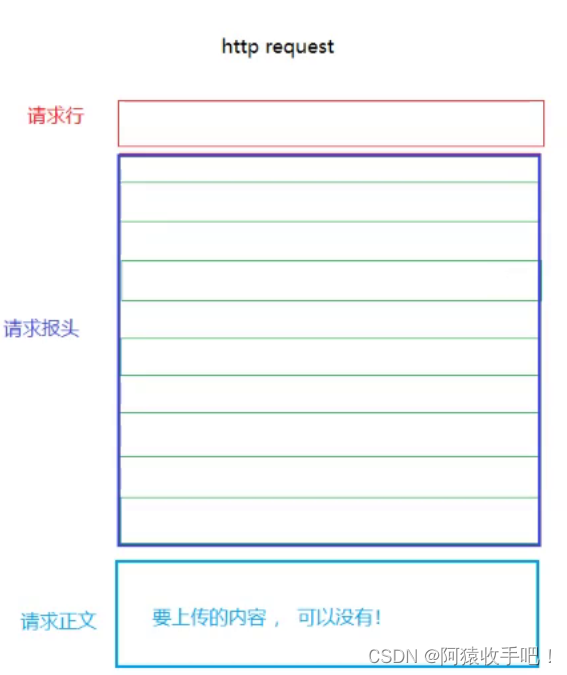
6.2请求

uri
csdn好文
URI、URL和URN都是在网络环境中用于标识和定位资源的重要概念,以下是它们的基本解释和区别:
URI(Uniform Resource Identifier):统一资源标识符。它是一个用于标识某一互联网资源名称的字符串。URI允许用户对任何资源(包括本地和互联网)通过特定的协议进行交互操作。URI由包括确定语法和相关协议的方案所定义。Web上可用的每种资源,如HTML文档、图像、视频片段、程序等,都由一个URI进行定位。
URL(Uniform Resource Locator):统一资源定位符。它是URI的一种形式,专门用于标识和定位互联网上的资源。URL的主要作用是定位和访问互联网上的资源,这些资源可以是网页、图片、视频、文档或其他文件。一个URL通常由多个部分组成,包括协议、主机名、端口号、路径和查询参数等。
URN(Uniform Resource Name):统一资源名。它也是一种URI,用于在互联网上唯一地标识和引用资源,与资源的位置和访问方式无关。URN是一种持久性的标识符,它的目的是提供一个稳定的命名机制,使资源能够长期存在,并且在被移动或复制到不同的位置或系统时仍能被正确地找到和访问。
总的来说,URI是一个更广泛的概念,它包括了URL和URN等不同类型的资源标识符。URL是URI的一种特殊形式,专门用于定位和访问互联网上的资源,而URN则更注重于资源的唯一标识和引用,与资源的位置和访问方式无关。这些概念在网络编程、Web开发、搜索引擎等领域中都有广泛的应用。
请求和响应的第一行都有http版本
- 低版本客户端访问高版本服务器 服务器识别到 只给低版本客户端返回它这个版本能够支持的数据
- 低版本客户端访问高版本服务器 服务器识别到 提示客户端 您需要升级了 不升级无法使用此项功能!
- 公司更新客户端时 一般不会全部更新 害怕出现问题 如果新版本的客户端有问题 公司让所有地区的客户端都升级 这就会有影响 通常先升级一部分 测试一下 这就要求服务端能够服务新老版本的客户端
请求内容里有GET /favicon.ico HTTP/1.1
GET /favicon.ico HTTP/1.1 是一个HTTP请求行的示例,用于从Web服务器请求名为 favicon.ico 的文件。这里详细解释每个部分:
GET:这是一个HTTP方法,用于请求指定的资源。GET 方法通常用于从服务器检索(或“获取”)数据。
/favicon.ico:这是请求的资源的路径。favicon.ico 是一个传统的文件名,通常用于包含网站的图标(也称为“favicon”)。这个文件通常位于网站的根目录下,但也可以位于其他位置。
HTTP/1.1:这指定了HTTP协议的版本。HTTP/1.1 是目前互联网上广泛使用的HTTP协议版本。与HTTP/1.0相比,HTTP/1.1包含了许多改进,如持久连接(允许一个TCP连接上进行多个HTTP请求/响应)、流水线技术(允许同时发送多个请求而不必等待响应)、虚拟主机支持等。
完整的HTTP请求可能还包含其他行,如请求头(Request Headers),它们提供了关于请求的更多信息,如用户代理(User-Agent)、接受的语言(Accept-Language)等。然而,GET /favicon.ico HTTP/1.1 只是请求行本身。
当浏览器加载一个网页时,它通常会尝试从该网页的根目录(或其他配置的位置)获取 favicon.ico 文件,以便在浏览器的标签页、地址栏或收藏夹中显示网站的图标。如果服务器上没有这个文件,或者浏览器无法找到它,那么浏览器可能会使用一个默认的图标或不显示图标。
6.3访问网页
telnet和浏览器都是一个客户端 用客户端构建一个http请求去访问服务端 服务端接收到请求 构建一个响应返回 客户端接收到这个响应 对其进行解析 把响应中的正文部分 显示在浏览器上 正文是文本就显示文本 是网页就显示网页。如果是网页 对整个网页源代码解析 只输出body部分 不输出头部
我们模拟实现的http服务端 在接收到请求后 把请求输出到了stdin上 所以每收到一个请求 显示器上就会多一条记录
Fiddler抓包原理(梯子的原理类似)

postman直接作为客户端构建请求
6.4接口inet_ntop
inet_ntop是一个函数,用于将网络字节序的二进制IP地址转换为可读的字符串格式。
具体来说,inet_ntop函数可以将IP地址从“点分十进制”或“二进制整数”形式转换为人类可读的字符串形式。其函数原型如下:
c
#include <arpa/inet.h>
const char* inet_ntop(int af, const void* src, char* dst, socklen_t size);
参数说明:
af:地址族,可以是AF_INET(IPv4)或AF_INET6(IPv6)。
src:指向要转换的二进制地址的指针,可以是struct in_addr(对于IPv4)或struct in6_addr(对于IPv6)类型。
dst:指向存储转换后的字符串的缓冲区的指针。
size:dst指向的内存块的大小。
返回值:
如果转换成功,则返回指向dst的指针。
如果转换失败,则返回NULL,并设置errno。
通常情况下,可以使用INET_ADDRSTRLEN或INET6_ADDRSTRLEN宏定义来指定缓冲区大小。这个函数在网络编程和调试中非常有用,因为它可以帮助开发人员更容易地查看和处理IP地址。
6.5User-Agent/Accept
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.7
User-Agent 和 Accept 是HTTP请求头中的两个字段,用于描述发出HTTP请求的客户端(如Web浏览器)的特性以及它可以接受的内容类型。下面是对您给出的这两个请求头的详细解释:
User-Agent:
- 标识一个客户端是否合法/有效 反爬:不是有效的客户端禁止爬
- 浏览器上搜索一个软件 默认选中的是windows版 原因就是浏览器构建的http请求中包含了客户端操作系统版本
User-Agent 字段包含有关客户端软件(如Web浏览器)的信息,这样服务器就可以根据这些信息返回适当的响应。在您的例子中,User-Agent 字符串表明:
客户端操作系统是 Windows 10,64位版本。
浏览器是基于 Apple 的 WebKit 渲染引擎,这通常意味着它是基于 Chromium 的浏览器。
浏览器明确标识为 Chrome 和 Microsoft Edge,并且它们的版本都是 122.0.0.0(虽然这看起来像一个占位符或测试版本,因为通常Chrome和Edge的版本号不会完全匹配并且包含更多的细节)。
AppleWebKit/537.36 是 WebKit 渲染引擎的一个版本,它是 Safari 浏览器和许多基于 Chromium 的浏览器(如 Chrome 和 Edge)的基础。
KHTML, like Gecko 是历史遗留信息,用于兼容旧的网站或服务器。
Accept
Accept 字段告诉服务器客户端(如Web浏览器)期望接收到的响应类型。在您的例子中,Accept 字段表明客户端可以接受以下类型的内容:
text/html:HTML文档。
application/xhtml+xml, application/xml:XHTML和XML文档。
image/avif, image/webp, image/apng:不同类型的图像格式。
/:任何类型的内容。这里的 q=0.8 表示这种“通配符”类型的权重稍低(0.8),意味着客户端更喜欢前面明确列出的内容类型。
application/signed-exchange;v=b3;q=0.7:一种支持内容缓存和内容交付的协议,用于提高页面加载速度和安全性。这里的 q=0.7 表示它的权重略低于其他明确列出的内容类型。
总之,这些请求头字段帮助服务器了解客户端的特性和需求,以便返回适当的响应。
6.6自己构建的响应vs百度的响应
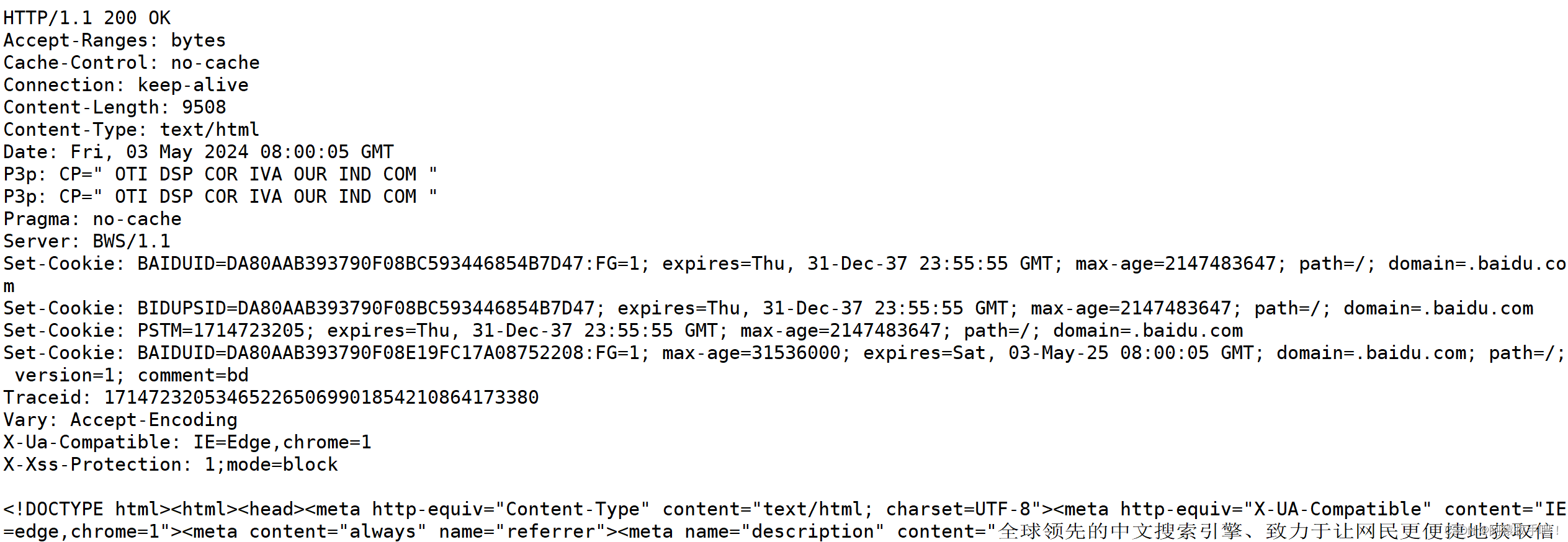
6.7客户端行为

客户端没有发起连接 服务端接受到了连接 实际上是浏览器可能每隔一段时间发起上次相同的连接刷新页面 以保持数据的实时性
6.8GET/POST
传参时 可以通过html中的输入框提交 也可以get方法下 显示在?后面使用key=value&key=value的方式
get/GET
在HTTP请求中,GET 是一种方法(或称为动词),用于请求指定的资源。而在HTML表单()中,method 属性可以用来指定当表单被提交时所使用的HTTP方法,其中get(注意在HTML中是小写)是其中的一种选择。
HTTP GET 请求
HTTP GET 请求用于从服务器检索(或“获取”)信息。GET 请求会将参数附加到URL的查询字符串中,并发送给服务器。这些参数以“名/值”对的形式出现,并用“&”字符分隔。例如:
GET /search?keyword=apple&page=1 HTTP/1.1
Host: www.example.com
在这个例子中,keyword=apple&page=1 就是查询字符串,包含了两个参数:keyword 和 page。
HTML 表单中的 GET 方法
在HTML表单中,method 属性决定了当表单被提交时所使用的HTTP方法。如果method 被设置为 get(注意是小写),那么表单的数据将会作为查询字符串附加到表单的action URL后面,并发送一个GET请求到服务器。
例如:
html
GET /search?keyword=apple&page=1 HTTP/1.1
Host: www.example.com
…
注意事项
安全性:由于GET请求将数据作为查询字符串发送到服务器,因此这些数据可能会被记录在浏览器历史、服务器日志或网络代理中。因此,对于包含敏感信息(如密码)的表单,通常不建议使用GET方法。相反,应该使用POST方法。
URL长度限制:由于URL长度有限制(尽管这个限制因浏览器和服务器而异),所以使用GET方法提交的表单数据也受到这个限制。如果表单数据过大,可能需要考虑使用POST方法或其他技术来传输数据。
幂等性:GET请求是幂等的,这意味着多次执行相同的GET请求不会产生不同的结果(除了可能的缓存失效)。这对于搜索引擎和其他需要频繁访问资源的系统来说是一个重要的特性。
理解
HTTP协议中的GET和POST是两种主要的请求方法,它们在HTTP请求中扮演着不同的角色,主要用于定义客户端(如Web浏览器)如何与服务器进行通信。
GET方法:
主要用于请求指定的资源。
请求的数据会附加在URL之后,并以查询字符串的形式出现。
因为数据是附加在URL上的,所以它的长度有限制(由浏览器和服务器共同决定)。
GET请求是可以被缓存的。
GET请求应该只用于从服务器获取数据,而不应该用于修改服务器上的数据。
POST方法:
主要用于向指定的资源提交数据。
请求的数据会放在HTTP请求的消息体中。
相比GET请求,POST请求没有数据长度的限制。
POST请求是不可以被缓存的。
POST请求通常用于向服务器提交数据(如表单数据),这些数据可能会被服务器用来更新资源或执行其他操作。
HTML表单与GET/POST方法的关系:
在HTML中,标签的method属性用于定义表单数据提交时使用的HTTP方法。默认情况下,这个属性是GET,但你可以将其更改为POST。
当使用GET方法提交表单时,表单的数据会被附加到URL之后,并以查询字符串的形式发送到服务器。
当使用POST方法提交表单时,表单的数据会放在HTTP请求的消息体中发送到服务器。
二者之间的联系:
GET和POST都是HTTP协议中定义的方法,它们决定了如何发送HTTP请求。
在HTML表单中,你可以通过改变标签的method属性来选择使用GET还是POST方法来提交表单数据。
选择哪种方法取决于你的需求:如果你只是从服务器获取数据,那么使用GET方法是合适的;如果你需要向服务器提交数据(如用户输入、上传文件等),那么使用POST方法可能更为合适。
参数提交给谁
- 提交给action指定的资源x 如果资源x是一个程序 那么服务端可以这么做:fork子进程接收这些参数去进程替换为x来执行 比如这个程序可能把提交的参数存入数据库
- 提交给某个网页
- http请求是浏览器构建的 如果http服务端编写的页面有post方法的form表单 那么浏览器通过该表单提交时 http请求的方法就成了POST(实验验证) 其他情况一般都是GET
代码测试
根目录是一个表单方法是geit时

访问根目录会发起一个http请求
提交参数会发起一个GET请求 get方法参数会拼接在url后 post会放在正文里且http请求变为POST
点击提交按钮后 会转到action指向的页面
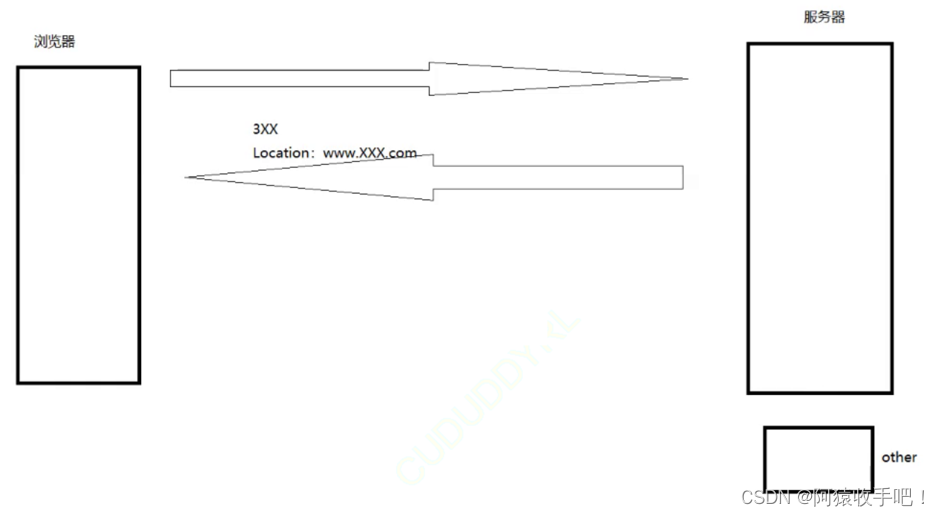
7.重定向
实际上你需要告诉浏览器你的正文是什么 如果不告诉 浏览器也会解析你的正文 临时重定向有302/307 但可能他们实现的效果不同 有的可能是改变了请求方法如get-》post 即便定了标准 公司创造浏览器实际的行为也可能不同 ==》 不是那么严格
图示
让服务器指导浏览器 让浏览器访问新的地址
一旦访问 / ,直接就会跳转到qq网页
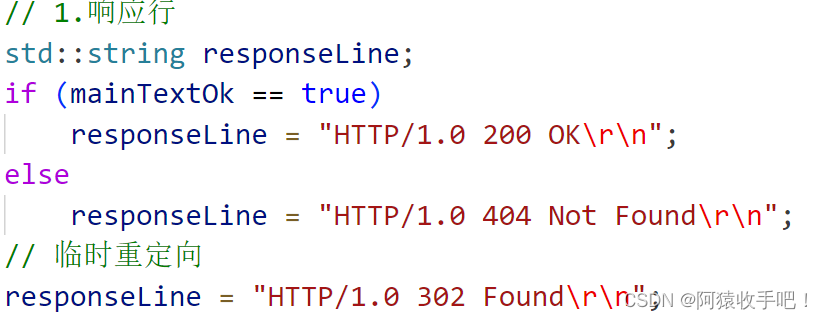
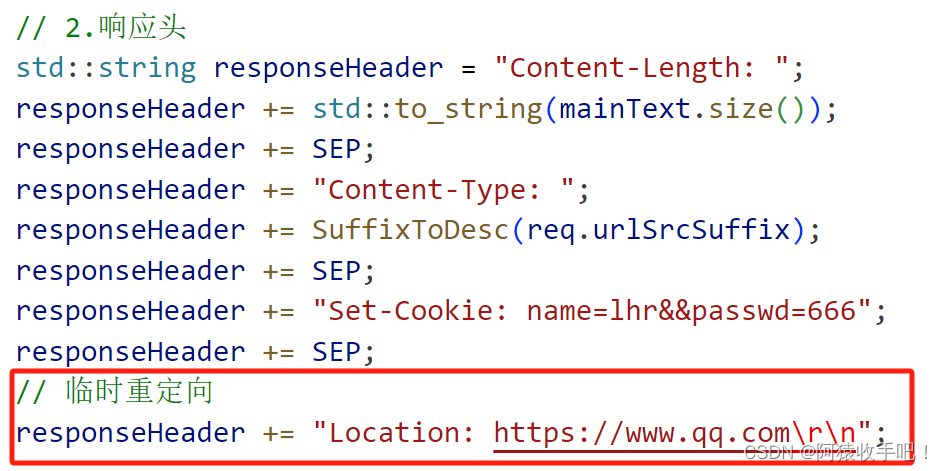
理解
- 临时重定向:浏览器要访问的资源x当前处于维护状态 当浏览器发起一个访问x的请求 服务器收到后发现x正在维护 就会返回浏览器一个3xx状态码+一个新的网址w 表示浏览器可以去w下访问他要的资源(服务器提前把x的资源拷贝到了w)浏览器获取到3xx和w后 发起二次请求获取w 这些过程都是BS自己做的 我们能看到的是:之前我们想访问x网址 输入x网址浏览器显示x的资源 如今输入x网址 自动跳转到一个新的网址显示的仍是我们想要的资源。临时的含义:x某一天可能维护好了 此时输入x网址浏览器显示x的资源表示该重定向不用了 原来的可以访问 还是去访问原来的
- 永久重定向:x不是在维护 而是永远也不用x了 只要浏览器访问x 就自动跳转到w
- 当然,服务端也可以这么设置:当一个网址需要重定向 在重定向前 可以返回浏览器一个页面【您访问的当前页面失效,5s后为您自动跳转到新的网址】
- 日常应用:首页点击登陆自动跳转到qq登录,输入完毕后在跳转回去。
8.解析url后缀
8.1图片
这种情况浏览器只会发起一次请求 因为一次请求获得html资源后 第二次浏览器请求获得该图片资源 第三次浏览器发现要获取的图片是一样的图片 浏览器直接去自己的缓存里获取不再向服务端发起请求

上面讲到 长连接和短链接 浏览器发送的请求表明它支持长连接 但是我们的模拟服务端代码只实现了短连接功能 即 浏览器每获取一个资源都要发起一个请求
9.cookie
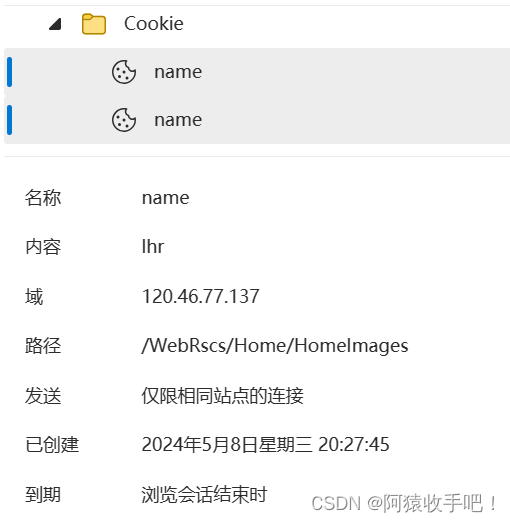
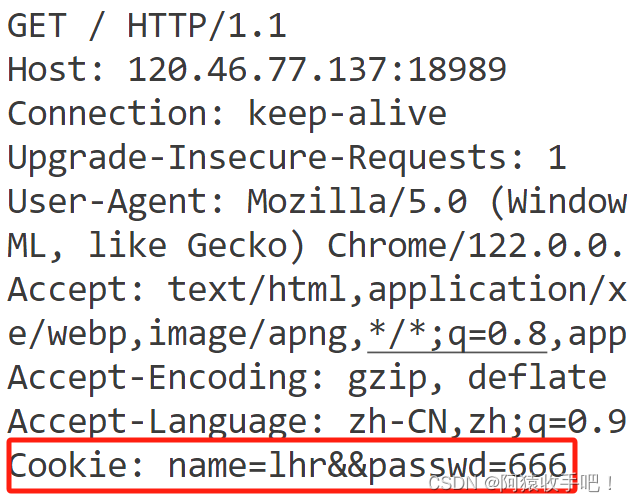
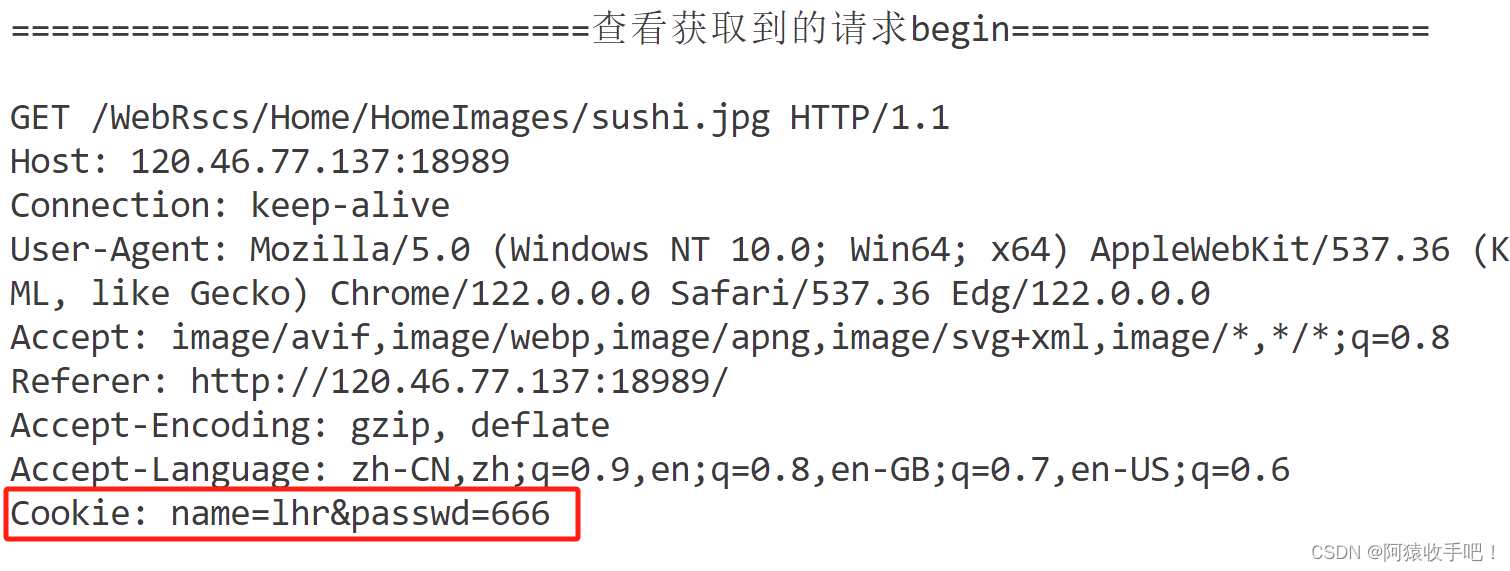
有一个小bug无伤大雅:当再次访问该页面时 浏览器访问该页面时构建的请求中包含两份相同的cookie


以下是测试