
AIGC 训练场景下的存储特征研究_aigc时代的云存储技术
赞
踩
云布道师
引言:在传统块存储大行其道的时代,需要针对很多行业的工作负载(Workload)进行调研,包含块大小、随机读、读写比例等等。知道行业的 Workload 对于预估业务的 I/OPS、时延、吞吐等性能有很好的指导意义,其次,也便于制定针对行业的存储配置最佳实践。
在今天这样以 AIGC 为代表的 AI 时代下,了解训练场景对于存储的具体诉求同样是至关重要的。本文将尝试解读 WEKA 的一个相关报告,来看看 AIGC 对于存储有哪些具体的性能要求。
一、LLM&AIGC 时代的计算架构特征
存储的变化都是基于计算和存储介质造就的。在最早的大型机时代是提供大型机适配的大硬盘。随着介质的变化,小型的硬盘和内存技术兴起,而商务报价的大幅下降,催生了阵列存储的产生,并且快速地替代了大硬盘。其后,随着关系型数据库这个上一个时代最值钱的数据库不断地发展,产生了各种的高端存储,架构也随着一些硬件技术的进步做了很多的演进,从 scale-up 到 scale-out,但是价格依然高昂。
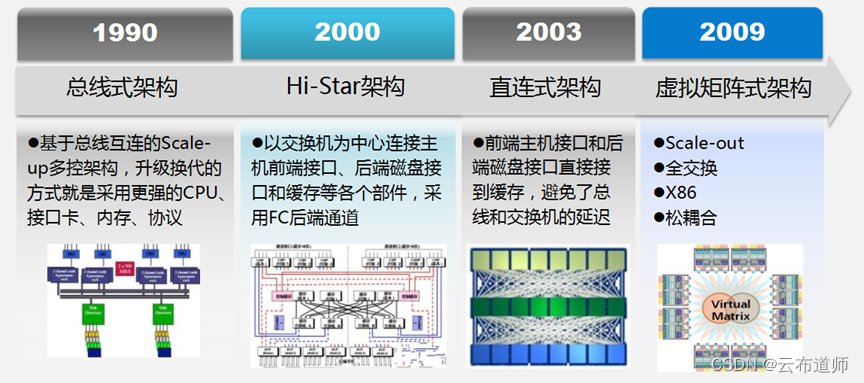
高端存储宣传的主要方向是高性能、高可靠、高扩展,以及各种名词堆上去的企业级存储平台。在企业存储的赛道之外,其实一直都有另一个赛道存在,那就是HPC(High performance computing) 存储,HPC 存储最初主要面向的是科研机构。
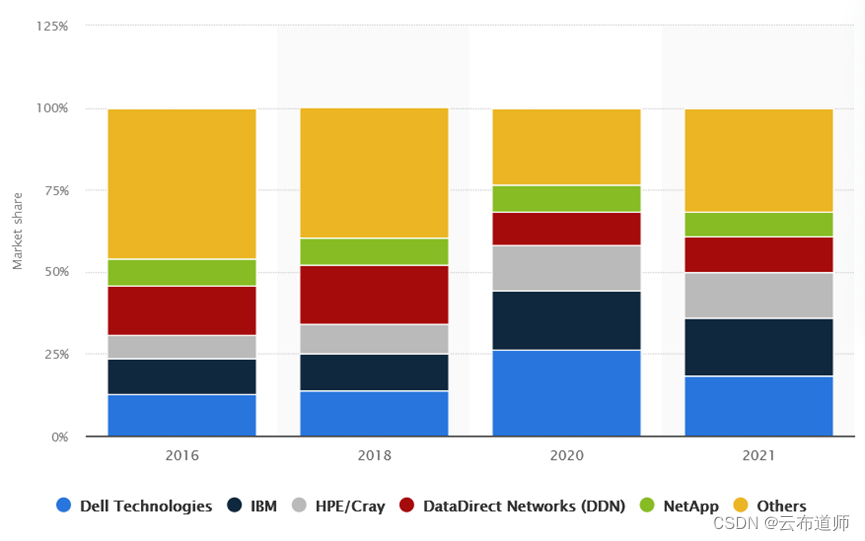
回到 20 年前,HPC 系统已经在处理几个 PB 的数据了,而在这个时代,产生的大数据技术或多或少也从这里得到了灵感。个人认为,Google 的三驾马车就是一个HPC+DBMS 的结合体,取了 HPC 架构的精华,构造了傻瓜式调用的并行处理框架MapReduce,然后将 DBMS 放弃了 ACID 的部分功能,构造出了 Bigtable 来适配互联网的业务。
当年的存储架构设计思路是为计算提供最快的存储层即HDD(当时还没有SSD加入到存储中,EMC主存储加SSD也到了08年左右)。由于HDD的限制,作业通常大小为尽可能多地加载到内存中,避免换出,并且需要检查点(checkpoint)以确保如果在加载或将作业写入HDD会发生什么样的问题,毕竟因为一个中间错误就去重新加载数据并重新开始任务所花费的计算时长太长了。
但是众所周知,HDD 是数据中心中最慢的部件,或者说存储是数据中心中最慢的部件。后来出现了 SSD,但是性能和成本是永恒的矛盾,于是分层存储就出现了。
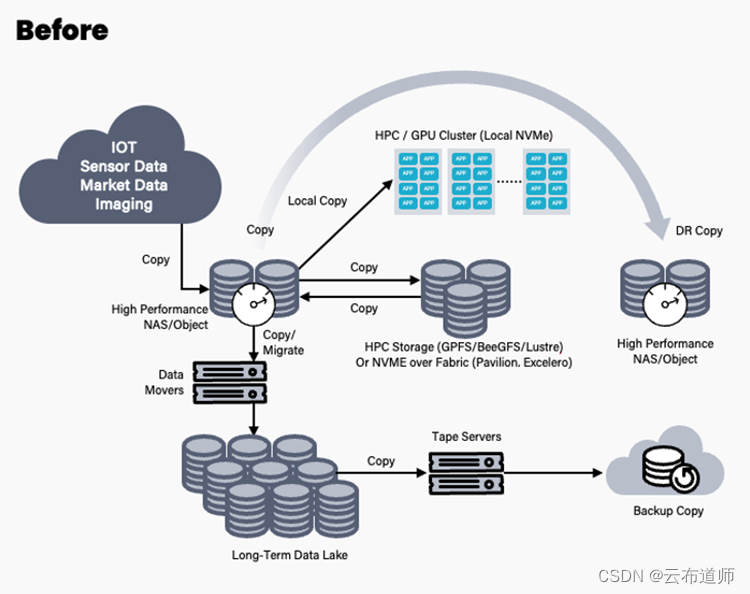
首先,从传感器或者其他领域获取到数据,存储到一个高性能的存储设备。这个存储设备首先必须是一个共享存储,毕竟HPC是采用多个计算节点并行的方式执行任务,因此一般都是文件存储或者对象存储(早期主要是文件存储,对象存储是这几年云时代的到来,很多数据上云的第一站需要跨越互联网,因此以对象存储来承载)。
其次,数据经过预处理之后加载到计算节点的本地 NVMe SSD 或者 Cache 中,上面这个图画得不一定精准,其实很多时候数据预处理之后写入到了并行文件系统中,比如说典型的 HPC 高性能存储并行文件系统(GPFS、BeeGFS、Lustre)。
最后,将数据进行相关的备份或者随着生命周期转冷。
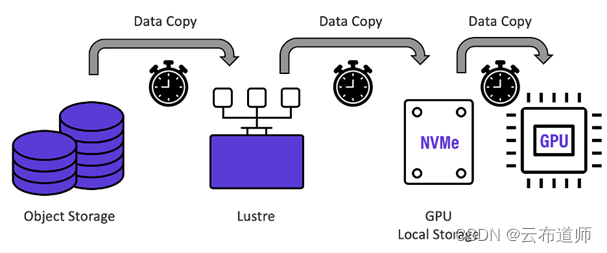
在 AI 的领域,可以说 AI 的训练其实是另一个基于 GPU 的 HPC。整个过程的数据流处理如下(这里面会有几个批次的 copy 工作)。从原始数据预处理到并行文件系统,从并行文件系统到 GPU 本地的 NVme SSD,从本地 NVMe 到显存。这几个过程不可避免,并且成为制约 AI 最大的性能瓶颈之一(另一个则是内存墙)。NVIDIA GPUDirect Storage 协议是一个可能的解题思路,可以跳过本地 NVMe SSD,但是存储系统本身的性能可能更是一个关键,毕竟通过网络的时延可能高于本地 NVMe SSD 的访问。
二、AIGC时代的存储主要挑战
从微软的研究 Analyzing and Mitigating Data Stalls in DNN Training 中可以明显看出,dataset 在 SSD 情况下是否缓存住对于每个 epoch 的时间冲击并没有想象的那么大,但是如果存储性能太差,那么 epoch 的时间冲击将极大。当然这个是DNN 场景,在 LLM 大模型的 transformer 模型是否也会类似并不清晰。理论上,如果网络效果好,加之全闪存是可以逼近本地盘的效率(假设dataset cache率没有那么高)。
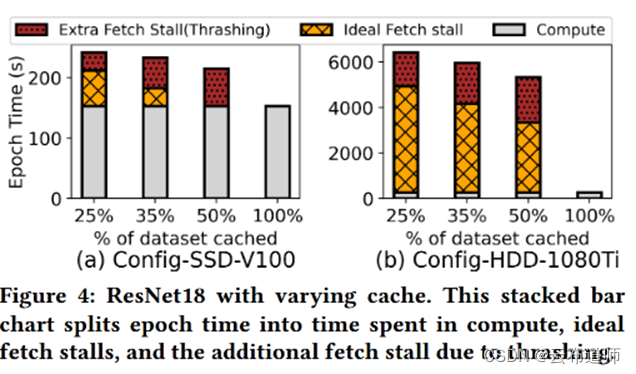
如果使用对象存储配合本地盘来做训练,也有一组测试数据,除了第一个 epoch 性能较差,其他的根本底盘差异并不大。(这里其实有点偷换概念,本质上后面的测试都是 cache 了)
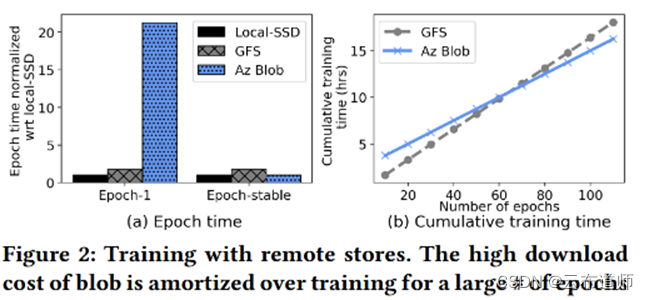
存储性能做到足够好,可以让大模型训练对存储不敏感,但是如果存储性能不好,则可能带来训练时长成倍地增长这个已经是个共识。针对 AI 训练尤其是大模型的训练,在存储上省钱将会大量浪费 GPU 算力。所以,在 GPU 算力紧张的时代,使用最高性能的存储是 AI 训练的基本原则。
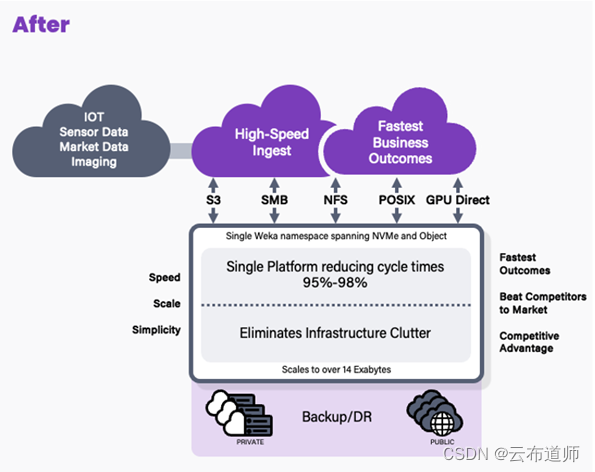
很多时候沿用了大数据提出的数据湖的概念,大数据领域的湖仓一体。在 AI 领域也是遵循这个概念,在数仓时代的相关数据流在 AI 时代其实一样存在。
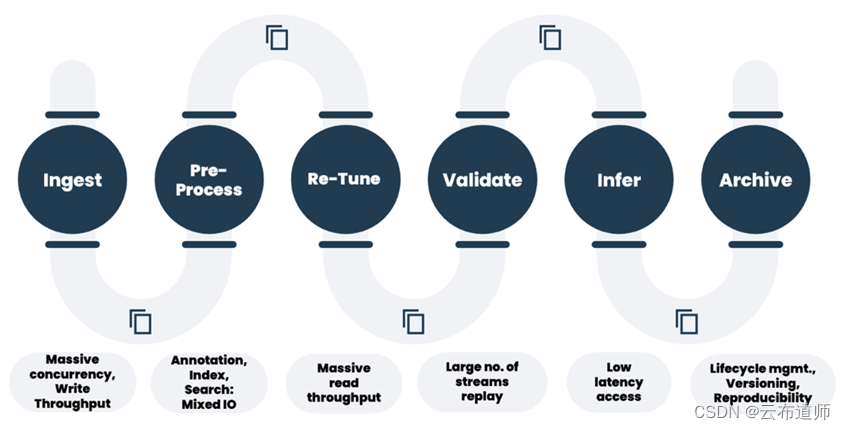
虽然当前的基础设施每年都在飞速地发生着变化,AI 模型也是日新月异,但是,整个数据流的架构并没有什么大的变化,还是大致遵循上面这个流程。而当下大模型公司的领先优势并不是算法上的精妙,而是工程上的架构设计以及先发优势,所以,一旦其他厂商加入,护城河将很快被填平。
三、LLM&AIGC 时代的元数据挑战
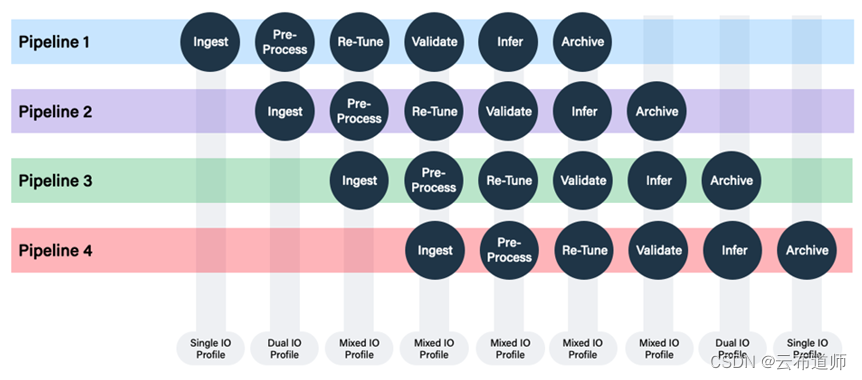
图片回到存储角度,大规模的训练带来的第一个挑战是混合 I/O 特征的需求,这个需求在集中存储、虚拟化存储、私有云存储时代都在不断地出现和完善。
其次是针对元数据的管理,这个才是这个时代的难题。以前用树形的分布式文件系统,一般可以处理十亿百亿级的文件,之后在互联网时代为了处理海量的文件,使用了对象存储的KV架构,不再追求文件树形架构因此也没有目录、文件夹这个概念。很多云厂商的对象存储已经可以做到几千到上万的 QPS。
而在 AI 处理场景下,不管是当前的大语言模型、图片类模型,训练的语料经常是大量的小文件,小文件下的元数据处理经常会被忽略,其实很多时候元数据的 QPS 大于数据的 QPS。
在预处理期间,ingest 数据被处理到模型训练期望能够使用的状态。这可能涉及注释/标记、图像缩放、对比度平滑、索引等。当您有多个研究人员/科学家处理相同的数据时,每个人可能需要以不同的方式预处理数据,这取决于他们打算训练或重新调整模型的内容。即使使用相同的数据集,每个研究人员执行的预处理步骤之间也存在巨大差异。其结果是一个用于预处理的混合 I/O 环境,最多可占用 epoch 训练时间的50%。(这是一个很可怕的结果)
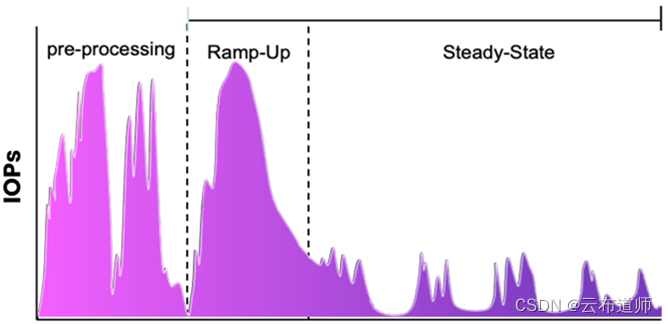
I/O 的影响是巨大的。当访问大量小文件(LOSF)时,不仅会遇到 I/O Blender 问题,而且现在还会有数百万个文件操作,读取和写入,其中 I/O大小和操作各不相同。
以一个使用 TensorFlow 在 ImageNet 上进行深度学习的客户为例(训练数据库包含 1400 万张图片):
阶段1:预处理函数在读取、修改和写回数据时,会对与之关联的小文件进行大量写入。当这种预处理与系统中的所有其他 I/O 混合在一起时,将再次遇到 I/O 混合器问题,但有一点不同:可能会耗尽系统中的写缓存,并陷入必须执行额外 I/O 来刷缓存到持久化层的恶性循环,从而导致系统速度降低,并延长完成这些元数据密集型流水线阶段所需的时间。
阶段2:对元数据产生巨大影响的第二个阶段是深度学习训练阶段。这往往是较少的写密集型,但有很多随机读取小文件。数据处理通常遵循以下一些变化:
●整个数据集的随机子集上的 mini-batch 和重复
●对每个 mini-batch 进行训练
●整个数据集的完整历元处理,通常以随机顺序进行(就是一个典型 shuffle)
●设置某种形式的超参数来控制过程(例如,所需的精度,epochs的数量等)
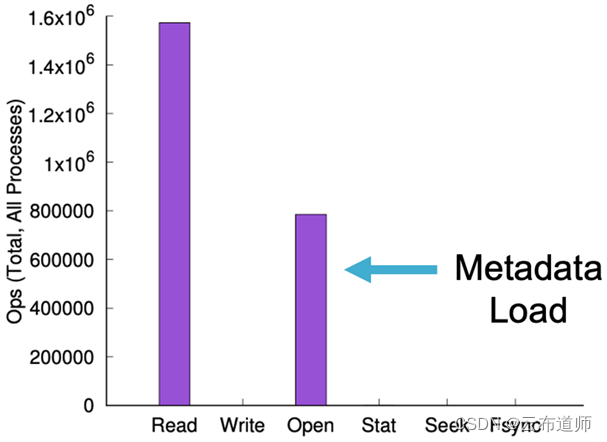
在这个过程会导致大量文件打开、文件统计信息以及更多不显示为传统 I/O 的信息。在下面的图表中,可以看到 WEKA 客户在 ImageNet 上使用 TensorFlow 进行训练的示例,训练数据库包含 1400 万张图像。在此训练期间,30% 的读取是文件打开(open)。这种开销表示深度学习训练和 ResNet-50 类型的迁移学习负载,读取比例一般在 25-75% 之间,具体取决于部署的训练类型和文件大小。这种“隐藏 I/O”会在数据平台上产生开销,随着工作负载的增加,开销会变得更大。设想一个1000 万次读取的 I/O 环境,在此基础上您需要额外处理 500 万次元数据 I/O。(这个就是典型的元数据隐藏)
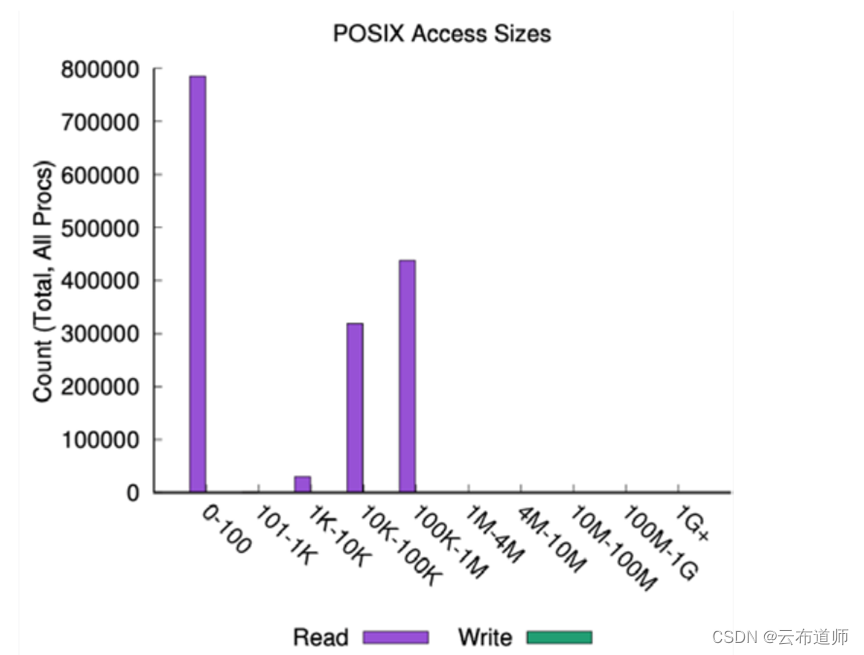
文件的大小也很重要。在同一个 TensorFlow 管道中,WEKA 发现数据大小要么非常小(小于100字节),要么是 10 KB-1 MB 的中等大小。由于文件大小的差异,数据平台需要能够同时处理非常小的随机 I/O 和顺序 I/O,以加快训练的epoch时间。其实当前看到大多数大模型训练都是以小 I/O 为主。
四、LLM&AIGC 时代的 I/O 特征分析
首先看一个自然语言处理(NLP)例子。这家 GenAI 客户正在构建人工智能模型,以支持语音转文本(voice-to-text)和语音转操作(voice-to-action)功能。
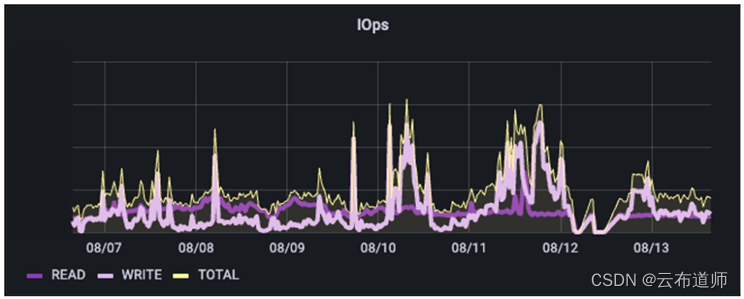
在此环境中,可以看到这是一个完全混合的混合 I/O 管道,由相对一致的读取数量和写入时的 I/O 峰值组成(读写是同时发生的)。这些信息可以映射到后端服务器的负载情况。
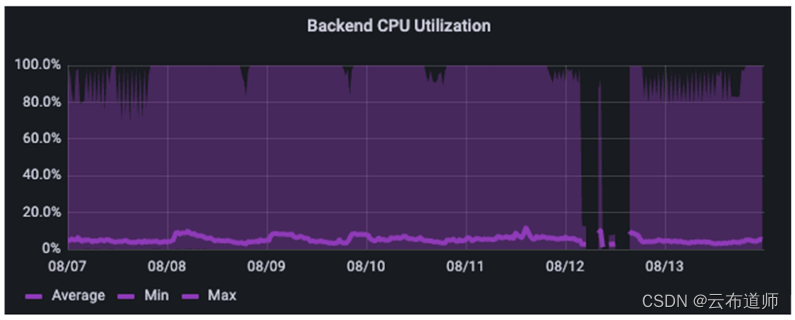
深紫色和浅紫色表示最大利用率和平均利用率。这显示了该客户的AI管道的强烈突发性。如果只看平均值,会认为系统未充分利用率约为 5%。实际情况是,它每隔几分钟就会出现剧烈的波动,导致其利用率经常达到 80-100%。(这在自动驾驶和AI场景非常的常见,对于共享的云存储集群来说,如何来处理这种场景的性能突发以及资源争用,并且最大化地利用资源是个比较复杂的问题。集群的QoS管理是云存储厂商需要不断下功夫的地方)。
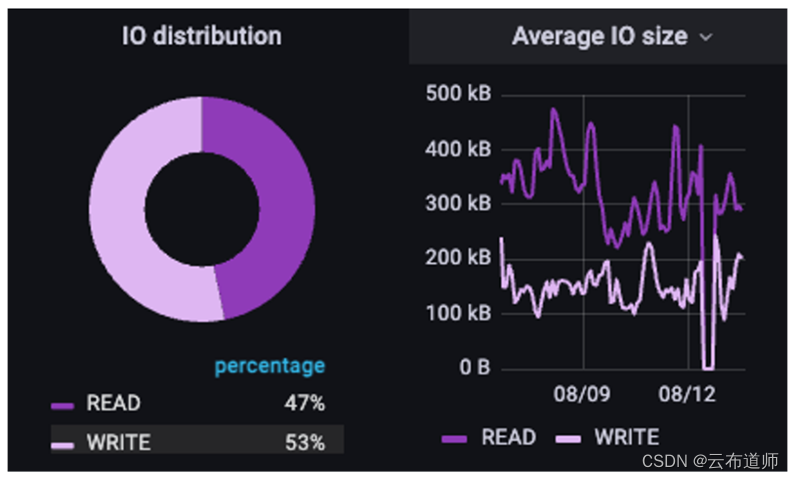
对于这个 NLP 业务来说,读/写比例是 47/53,但值得注意的是 I/O 大小:读 I/O 大(300-500K),写 I/O 小(100-200K)。在本例中,客户获取了通常小于100 k的小样本,将它们 append 到一个较大的文件中,并对该文件进行阅读,就好像它是一个流一样。但为什么写的都是小 I/O 呢?这不仅是 GenAI 和 AI 工作负载的共同主题,也是许多 HPC 工作负载的共同主题:Checkpoint。
Checkpointing
当运行长时间的培训或操作作业时,检查点是确保在发生故障时有一个“checkpoint”的方法。故障可能是任何硬件,其中运行作业的服务器出现硬件故障,也可能是 GenAI 工作流中的错误,其中功能嵌入到层中但未完成。检查点允许您恢复作业的状态,但也可以用于停止模型训练,评估,然后重新启动,而无需从头开始。检查点涉及将作业或内存状态写入存储器。在内存转储的情况下,这可以是大量的数据,或者在 AI 嵌入/训练检查点的情况下,这可以是较小的增量步骤。在这两种情况下,延迟都是一个重要的关键指标,因为写操作所花费的时间越长,作业必须等待的时间就越长。
上面这个图里面的小 I/O 写主要发生在层的 checkpoint。
接下来,看看 AI/ML 模型开发环境。在这个用例中,客户正在构建 NLP 和 ML 函数的组合,以实现 text-text and text-action 功能。这种数据管道更加隔离,重叠较少,因为它们还没有满负载运行。在这里可以看到,混合 I/O,读/写比例大概为48%/52%。此外,读取的 I/O 大小往往大于写入。
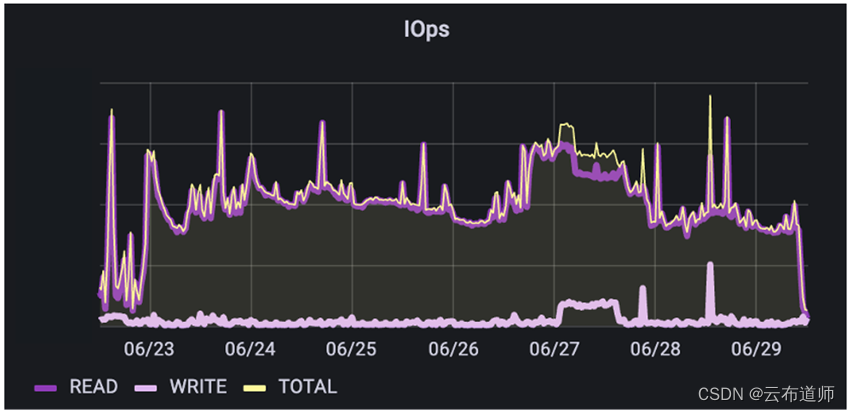
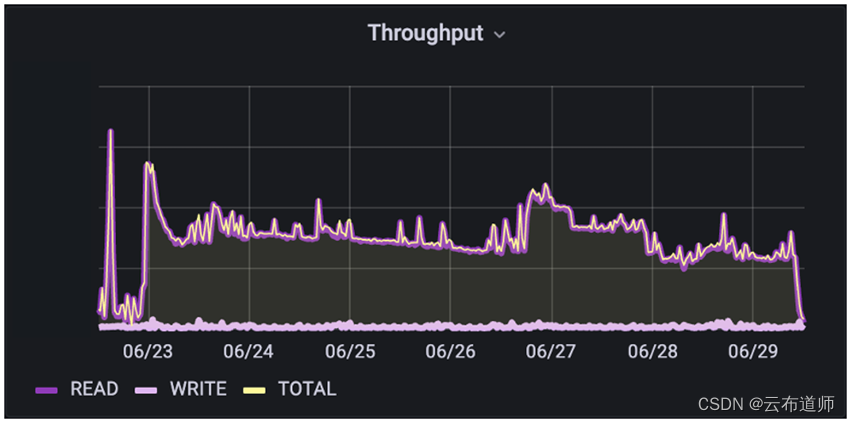
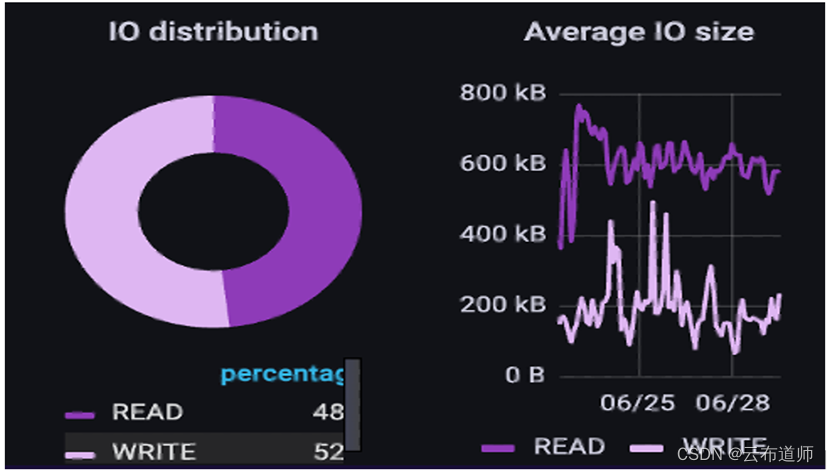
这里最重要的是所有预处理对 I/O 模式的影响。由于获取数据在构建到H5文件之前进行了大量的预处理以规范化数据,因此读取的 I/O 范围要窄得多,并且更可预测。这是在做大量的前期预处理工作使训练 I/O 更容易,或者做更少的工作并使训练 I/O 变得更加可变和难以处理之间的权衡。
最后,如果看一个图像识别训练的例子,其中已经完成了自动图像预处理,(注意这与之前描述的元数据例子不同,客户没有说明这是TensorFlow还是PyTorch),看到客户正在做一个经典的隔离环境,只是为了在图像训练中读取。但在他们目前的运营规模下,他们决定将训练与所有其他工作流程隔离开来,而不是每天将图像批量传输到存储集群进行训练。
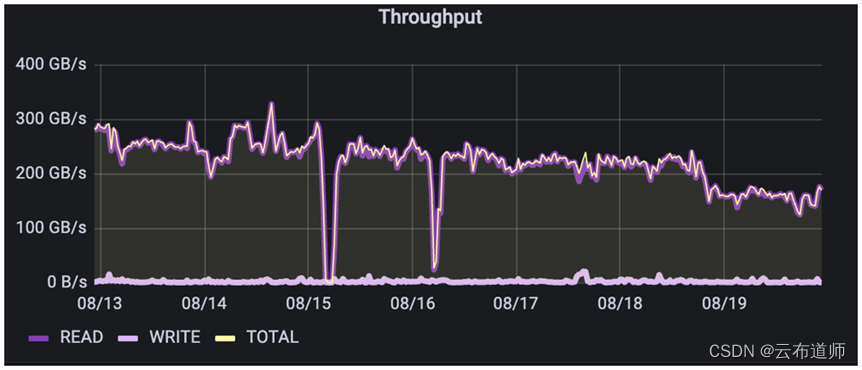
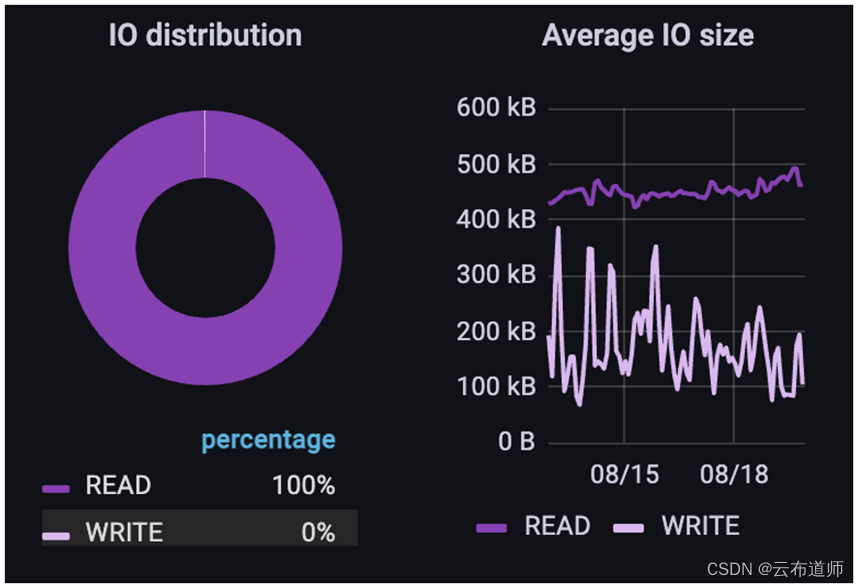
正如预期的那样,总体吞吐量由大小非常一致的读取控制。然而,写入差异很大。这些写操作大多是对文件的元数据更新、进程数据的回写和 checkpoint 操作。正如之前所指出的,监测的数据展示出了实际的数据传输,虽然这些写入的所有元数据操作都不会显示为数据传输,但它们可能会对训练模型的性能产生重大影响。
五、阿里云存储的典型 AI 训练解决方案
结合上文的分析,可以清晰地看到:
首先,在 AI 训练场景中需要一个低时延,高 QPS 和高吞吐的并行共享文件系统。
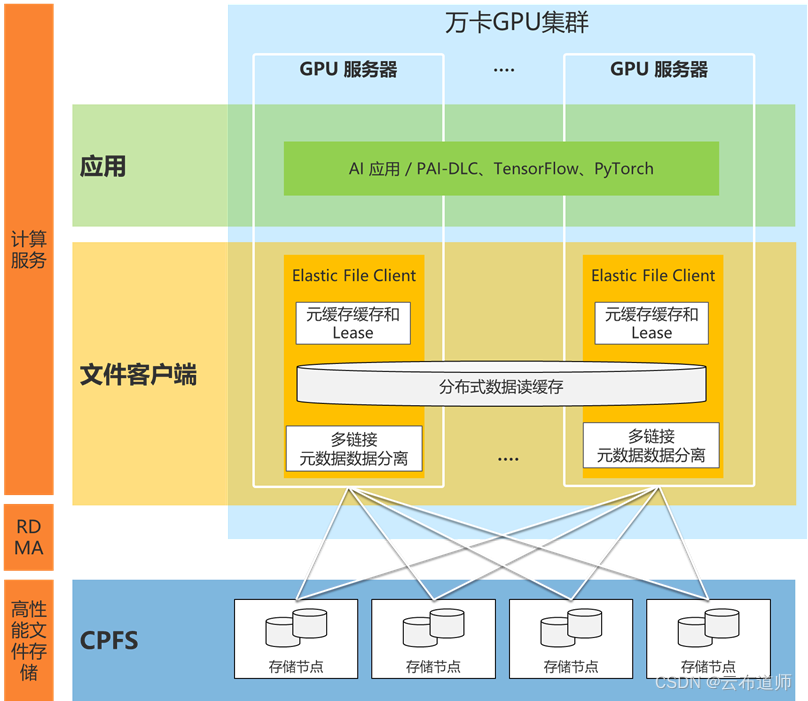
阿里云文件存储 CPFS 有几个关键的优势:
高性能元数据操作:客户端创新的lease机制和元数据缓存,元数据查询操作无需跨越网络,提升操作速度 10 倍,媲美本地 EXT4 性能
大规模训练稳定性:EFC 客户端支持链接层高可用,链路问题秒级别切换;客户端元数据和数据流分离,避免数据大压力下元数据操作卡顿。
其次,在传统的 HPC 架构里,高性能存储和大容量存储分离部署和维护,所有训练数据在高性能存储中清洗、训练、试用;数据转冷后流转到冷存储(手动&工具)。

而云原生时代的AI训练数据路径出现了明显的差异:分散的存储转化到数据湖,数据入口从训练高性能存储转化为对象存储底座。数据入湖后第一时间进入对象存储(数据湖存储底座);训练数据需要从对象存储进行自动化加载(部分厂商推荐客户使用跳板机映射或者开源主机缓存软件进行手动加载)。
因此,并行文件系统或分布式 Cache 自动加载数据湖对象存储是云原生AI基础设施的关键能力需求。
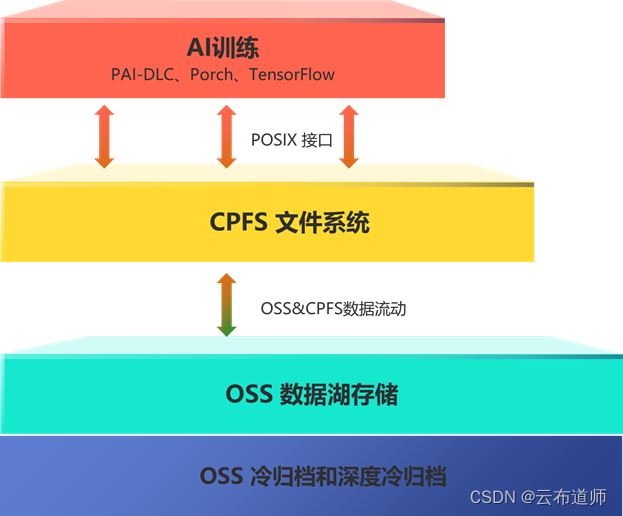
阿里云存储提供完整的数据管理解决方案,提供全面的数据流动能力:
高效数据流动:数据块粒度流动,多并发技术可实现百 Gbps 流动性能;
极速同步:事件驱动的高效元数据同步,OSS 数据变动在 CPFS 中分钟级可见;
多种模式:支持配合任务调度预加载或随 I/O 读取 Lazyload;
结束语
AI 训练过程中,随着流程的复杂以及并行度的加剧,I/O 的特征是一个非常混杂的场景,读写以及 I/O 大小都是弹性多变的,并且除了数据 I/O 还有大量的隐藏的元数据 I/O,很多时候会被忽略,但是它对于性能影响更大。AI 过程对于 I/O 最敏感的是时延而不是吞吐。低延迟是系统整体性能的主要指标,因为它会影响每个操作。整体延迟越低,AI 流程就越快进入模型工作流中的下一个迭代周期。
注:
1、本文相关截图、性能分析等数据出自以下公开报告https://www.weka.I/O/wp-content/uploads/files/resources/2023/09/I/O-profiles-gen-ai-pipelines.pdf
2、Analyzing and Mitigating Data Stalls in DNN Training
https://arxiv.org/abs/2007.06775
3、High performance computing (HPC) storage systems vendor market share worldwide in 2021
https://www.statista.com/statistics/802712/worldwide-top-hpc-storage-system-supplier/

