
- 1golang游戏服务器项目,基于Golang的游戏服务器框架nucleus开发日记(一)
- 2物联网控制APP入门专题(四)---使用android studio制作一个控制页面的APP框架_腾讯x5收费
- 3乳腺癌组织病理图像分类_免疫组化图像数据库
- 4雪舞_五星大饭店续集轻雪舞
- 5双非二本如何入职腾讯?只需要做好这些准备就能进大厂?_怎么入职腾讯
- 6混合A*算法(Hybrid A*)
- 7vueX(私有模块总结)_vuex models
- 8FPGA及其应用_fpga应用场景
- 9Chatbot/ChatGPT之类的AI聊天网站分享
- 10NSError異常 errorCode参照_ns error net timeout
大模型时代5个最顶级的向量数据库_开源向量数据库推荐
赞
踩
大家好,数字时代推动我们进入了由人工智能和机器学习为主导的时代,向量数据库已经成为存储、搜索和分析高维数据向量的不可或缺的工具,本文将介绍5个顶级的向量数据库。
1.Chroma

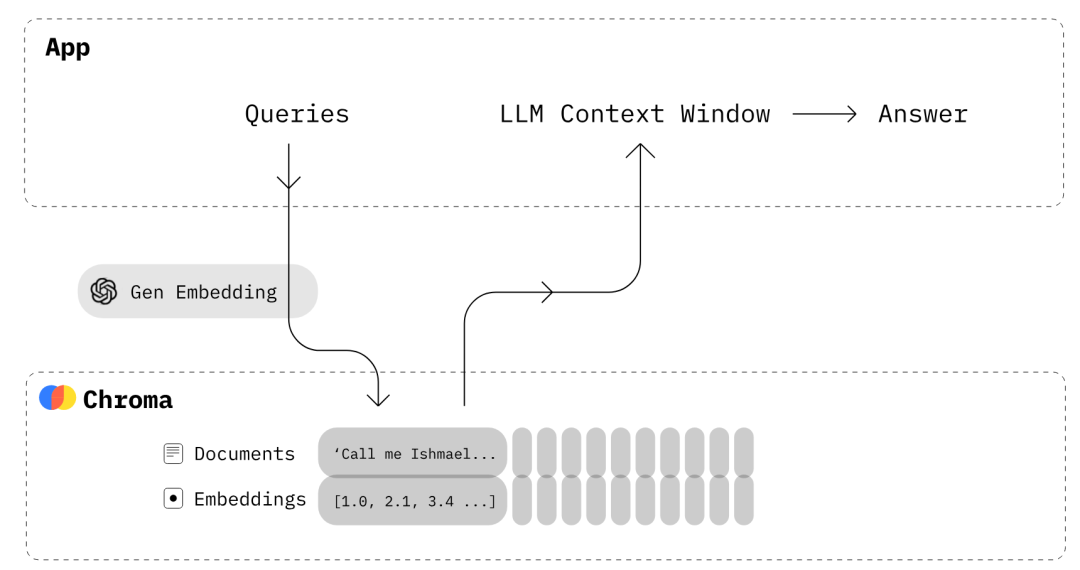
使用ChromaDB构建LLM应用程序
Chroma是开源嵌入数据库。Chroma使知识、事实和技能可插入LLM从而轻松构建LLM应用程序,可以便捷地管理文本文档、将文本转换为嵌入内容,以及进行相似性搜索。
主要功能:
-
功能丰富:查询、过滤、密度估计和许多其他功能
-
LangChain(Python和JavScript),LlamaIndex,可用支持
-
在Python notebook中运行的相同API可扩展到生产集群
2.Pinecone


Pinecone向量数据库
Pinecone是一个托管向量数据库平台,专门用于解决与高维数据相关的独特挑战。Pinecone拥有尖端的索引和搜索功能,使数据工程师和数据科学家能够构建和实施大规模的机器学习应用程序,进行有效地处理和分析高维数据。主要特点包括:
-
全面管理的服务
-
高度可扩展
-
实时数据接收
-
低延迟搜索
-
与LangChain的集成
3.Weaviate

Weaviate向量数据库体系结构
Weaviate是一个开源的向量数据库。它支持存储来自工程师喜爱的ML模型的数据对象和向量嵌入,并无缝扩展到数十亿个数据对象中。Weaviate的一些关键功能是:
-
速度:Weaviate可以在短短几毫秒内从数百万个物体中快速搜索十个最近的邻居。
-
灵活性:使用Weaviate,可以在导入过程中向量化数据,也可以上传自己的数据,利用与OpenAI、Cohere、HuggingFace等平台集成的模块。
-
从原型到大规模生产,Weaviate强调可扩展性、复制和安全性。
-
超越搜索:除了快速向量搜索,Weaviate还提供推荐、总结和神经搜索框架集成。
4.Faiss

Faiss是Facebook创建的向量搜索开源库
Faiss是一个开源库,用于快速搜索相似性和密集向量的聚类。它包含能够在不同大小的向量集内进行搜索的算法,甚至是那些可能超过RAM容量的向量集。此外,Faiss还提供了用于评估和调整参数的辅助代码。
虽然它主要是用C++编写的,但完全支持Python/NumPy集成,一些关键算法也可用于GPU执行。Faiss的主要开发由Meta的基础人工智能研究小组负责。
5.Qdrant

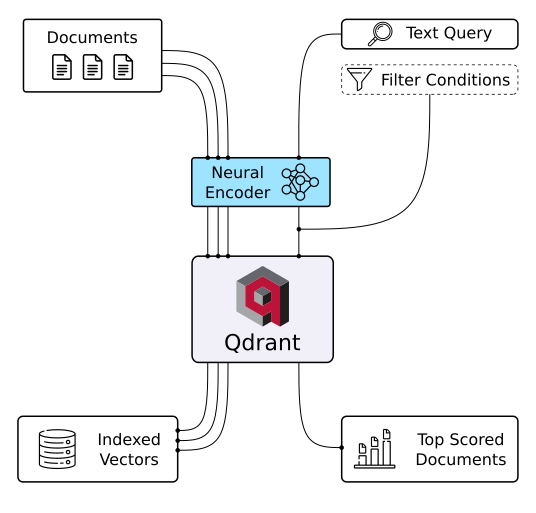
Qdrant向量数据库
Qdrant是一个向量数据库,也是进行向量相似性搜索的工具。它作为API服务运行,能够搜索最接近的高维向量。使用Qdrant,可以将嵌入或神经网络编码器转换为用于匹配、搜索、推荐等任务的综合应用程序。以下是Qdrant的一些关键功能:
-
通用API:为各种语言提供OpenAPI v3规范和现成的客户端。
-
速度和精度:使用自定义HNSW算法进行快速准确的搜索。
-
高级过滤:允许根据相关矢量有效载荷进行结果过滤。
-
多样化的数据类型:支持字符串匹配、数值范围、地理位置等。
-
可扩展性:具有水平扩展功能的云原生设计。
-
效率内置Rust,通过动态查询规划优化资源使用。

