
UNet++论文: 地址
热门标签
热门文章
- 1我的春招实习+秋招总结【前端开发】_前端找不到实习秋招是不是完了
- 2解决:fatal:unable to access‘https://github.com/xx/xx.git/‘:OpenSSL SSL_read:Connection was reset errno_fatal: unable to access
- 3数据中心GPU集群高性能组网技术分析
- 4LIama3 五一超级课堂 前置知识VScode 远程连接开发机_liama3 使用指南
- 5备忘: 使用langchain结合千问大模型,用本地知识库辅助AI生成代码_langchain和本地大语言模型 摘要提取
- 6PTA 7-9 树层次遍历_我们已知二叉树与其自然对应的树相比,二叉树中结点的左孩子对应树中结点的左孩子,
- 7MySQL数据库之索引_mysql 索引文件
- 8AI探索测试未来:人工智能与自动化测试的结合实战,文末实用干货自行领取!_面向未来的ai自动化测试工具
- 94.0 树莓派做下位机播放视频、控制电机舵机、超声波检测、paj7620手势传感器控制,树莓派串口通信等程序分析_树莓派 播放视频
- 10AITM2-0007 比光密度测定_aitm 2.0007下载
当前位置: article > 正文
[论文解读]UNet++解读 + 它是如何对UNet改进 + 作者的研究态度和方式(震撼)_unet后续改进
作者:小小林熬夜学编程 | 2024-05-26 09:37:09
赞
踩
unet后续改进
原文链接:https://blog.csdn.net/weixin_40519315/article/details/104457459
UNet++论文翻译:地址
UNet++源代码: 地址
UNet++作者在知乎上进行了解读,里面还有视频的讲解,深入人心.里面有一句话令我印象深刻,我总结下: 很多论文给出了他们建议的网络结构,其中包括非常多的细节,比如用什么卷积,用几层,怎么降采样,学习率多少,优化器用什么,这些都是比较直观的参数,其实这些在论文中给出参数并不见得是最好的,所以关注这些的意义不大,一个网络结构,我们真正值得关注的是它的设计给我们传达了什么信息,给我们引起了什么样的思考,所以我们应该要关注论文所传递的大方向,不要被论文中的细节局限了创造力, 而像这种细节参数的调整是属于比较朴素的深度学习方法论,很容易花费你很多时间,而最终并没有自身科研水平的提升,。这很有感触,很多时候急于发paper,改改里面参数啥的又发表,这样真的可以提高科研水平吗?我们应该从一个大的方向思考,而不是把精力花在这些意义不大的事情上.作者在分析UNet时是从一个大的方向上分析,首先提出疑问,实践验证,总结改进,重复上述过程...最后UNet++诞生了,虽然新的网络很快代替它,但是作者的这种研究态度和方式是值得学习的!
(建议先看他的知乎和视频,下面是我个人的学习笔记,总结作者的心路历程)
1、网红拓扑结构
编码和解码(encoder-decoder),早在2006年就被Hinton大神提出来发表在了nature上.当时这个结构提出的主要作用并不是分割,而是压缩图像和去噪声.后来把这个思路被用在了图像分割的问题上,也就是现在我们看到的FCN或者U-Net结构,在它被提出的三年中,有很多很多的论文去讲如何改进U-Net或者FCN,不过这个分割网络的本质的拓扑结构是没有改动的, 即下采样、上采样和skip connection.

这个结构真的一点毛病都没有吗?显然没有, 大家都在这个经典的结构上不断地去完善它. 在这三年中,U-Net得到的超过2500次的引用,FCN接近6000次的引用,大家都在做什么样的改进呢?如果让你在这个经典的结构基础上改进,你会去关注哪些点呢?
2、降采样和升采样
第一个问题: 降采样对于分割网络到底是不是必须的?问这个问题的原因就是,既然输入和输出都是相同大小的图,为什么要折腾去降采样一下再升采样呢?
理论回答是这样的: 降(下)采样的理论意义,它可以增加对输入图像的一些小扰动的鲁棒性,比如图像平移,旋转等,减少过拟合的风险,降低运算量,和增加感受野的大小。升(上)采样的最大的作用其实就是把抽象的特征再还原解码到原图的尺寸,最终得到分割结果。如下图所示:

作者认为,对于特征提取阶段,浅层结构可以抓取图像的一些简单的特征,比如边界,颜色,而深层结构因为感受野大了,而且经过的卷积操作多了,能抓取到图像的一些说不清道不明的抽象特征,讲的越来越玄学了,总之,浅有浅的侧重,深有深的优势.然后他再次提出疑问:多深才好?U-Net为什么只在4层以后才返回去?问题实际是这样的,下图所示,既然 X1,0 、X2,0、 X3,0 、X4,0所抓取的特征都很重要,为什么我非要降到 X4,0 层了才开始上采样回去呢?

3、网络要多深
提出疑问后, 作者开始做实验,为了验证多深才好,干脆每加一个深度(层次)就一个网络,然后测它们各自的分割表现,如下图所示,先不要看后两个UNet++,就看这个不同深度的U-Net的表现(黄色条形图),我们可以看出,不是越深越好吧,它背后的传达的信息就是,不同层次特征的重要性对于不同的数据集是不一样的,并不是说我设计一个4层的U-Net,就像原论文给出的那个结构,就一定对所有数据集的分割问题都最优。(备注:作者分别用了两个数据集:Electron Microscopy 和 Cell)

4、UNet++的萌芽
从上面的分析可见,不同数据集的最优的深度是不一样的, 但是总不能把所有不同深度的U-Net都训练一遍吧,这太耗时间了吧。如果给你一个数据集,训练你的网络,你并不知道网络要多深才算最优,也就是你并不知道不同深度的特征的重要性,那有没有办法设计一个网络使得它能够学习不同深度的特征的重要性呢?

我把图打出来就很简单了。

我们来看一看, 在这个网络里面你都可以找到1~4层的U-Net,它们全部都连在了一起. 这个结构的好处就是我不管你哪个深度的特征有效,我干脆都给你用上,让网络自己去学习不同深度的特征的重要性。第二个好处是它共享了一个特征提取器(我认为这说的是encoder),也就是你不需要训练一堆U-Net,而是只训练一个encoder,它的不同层次的特征由不同的decoder路径来还原。这个encoder依旧可以灵活的用各种不同的backbone来代替。
5、无法训练
可惜的是,上面这个网络结构是不能被训练的,原因在于,梯度不会经过这个红色的区域,由于这个区域和算loss function的地方(![]() )在反向传播时的路途是断开的。如下图所示
)在反向传播时的路途是断开的。如下图所示

如何解决无法训练这个问题?
- 第一个是用deep supervision,后面再说.
- 第二个解决方案是把结构改成这样子:

如果没有我上面说的那一堆话来盘逻辑,这个结构可能不那么容易想到,但是如果顺着思路一步一步的走,这个结构虽然不能说是显而易见,也算是顺理成章的.但是我提一句,这个结构由UC Berkeley的团队提出,发表在今年的CVPR上,是一个oral的论文,题目是"Deep Layer Aggregation"。他们在论文中给出的关于分割网络结构的改进,他们还做了其他的工作,包括分类,和边缘检测。但是主要的思路就是刚刚盘的那些,目标就是取整合各个不同层次的特征。
这只是一个题外话哦,我们继续来看这个结构,请问,你觉得这个结构又有什么问题?
为了回答这个问题,现在我们和UNet那个结构对比一下,不难发现这个结构强行去掉了U-Net本身自带的长连接。取而代之的是一系列的短连接。那么我们来看看U-Net引以为傲的长连接到底有什么优点。如下图:

作者认为,U-Net中的长连接是有必要的,它联系了输入图像的很多信息,有助于还原降采样所带来的信息损失.所以作者给出一个综合长连接和短连接的方案.
6、UNet++模型诞生
这个综合长连接和短连接的方案就是作者他们在MICCAI中发表的UNet++,也就是说这里的短连接是为了使模型能够得到训练,然后长连接是获得更多信息.

(UNet++和刚刚说的那个CVPR的论文结构也太像了吧,这个工作和UC Berkeley的研究是完全两个独立的工作,也算是一个美丽的巧合。UNet++在年初时思路就已经成型了,CVPR那篇是我们七月份开会的时候看到的,当时UNet++已经被录用了,所以相当于同时提出。另外,和CVPR的那篇论文相比,作者还有一个更精彩的点埋在后面说,刚刚也留了一个伏笔)
7、参数多了是导致UNet++比UNet好吗
UNet++的效果是比UNet好,从网络结构上看,说白了就是把原来空心的U-Net填满了
所以有人会认为是参数多了才导致效果好,而不是网络结构的增加.怎么反驳这个呢?
为了回答这个问题,同样作者又去做实验验证
作者的做法是强行增加U-Net里面的参数量,让它变宽,也就是增加它每个层的卷积核个数。由此,作者他们设计了一个叫wide U-Net的参考结构,先来看看UNet++的参数数量是9.04M,而U-Net是7.76M,多了差不多16%的参数,所以wide U-Net我们在设计时就让它的参数比UNet++差不多,并且还稍微多一点点,来证明效果好并不是无脑增加参数量带来的

显然,这个实验用到了控制变量法,为了证明不是参数量影响了模型的表现.所以增加U-Net参数使它变宽,即“wide” U-Net.这样这个“wide” U-Net就和UNet++的参数差不多,甚至还多了点.实验结果如下:

实验证明,UNet++性能的提升和参数量无直接关系,和网络结构有关.(不过这样“无脑”增加参数的实验,作者认为有点敷衍,应该还有更好的办法来完善这个实验,使它更有说服力,总之,作者这种研究思路和爱发现问题以及动手实验值得我学习)
另外,实验也证明了单纯地把网络变宽、把参数提上,对效果的提升并不大
8、简单解读UNet++
从上面分析下来,我们可以解读一下为什么UNet++好
解读1:显然它的优势是可以抓取不同层次的特征,将它们通过特征叠加的方式整合. 不同层次的特征,或者说不同大小的感受野,对于大小不一的目标对象的敏感度是不同的,比如,感受野大的特征,可以很容易的识别出大物体的,但是在实际分割中,大物体边缘信息和小物体本身是很容易被深层网络一次次的降采样和一次次升采样给弄丢的,这个时候就可能需要感受野小的特征来帮助.而UNet++就是拥有不同大小的感受野,所以效果好.
解读2:如果你横着看其中一层的特征叠加过程,就像一个去年很火的DenseNet的结构,非常的巧合,原先的U-Net,横着看就很像是Residual的结构,这个就很有意思了,UNet++对于U-Net分割效果提升可能和DenseNet对于ResNet分类效果的提升,原因如出一辙,因此,在解读中作者他们也参考了Dense Connection的一些优势,比方说特征的再利用等等.
以上说法不一各有各的,这些解读都是很直观的认识,其实在深度学习里面,某某结构效果优于某某结构的理由,或者你加这个操作比不加操作要好,很多时候是有玄学的味道在里头,也有大量的工作也在探索深度网络的可解释性。
9、深监督(Deep Supervision)
刚刚在讲本篇的第5节的时候留了一个伏笔,说这个结构在反向传播的时候, 如果只用最右边的一个loss来做的话, 中间部分会收不到过来的梯度,导致无法训练, 解决的办法除了用短连接的那个结构外,还有一个办法就是用深监督(deep supervision).如下图所示,具体的实现操作就是在图中 X0,1 、X0,2、 X0,3 、X0,4后面加一个1x1的卷积核,相当于去监督每个level,或者说监督每个分支的U-Net的输出。这样可以解决那个结构无法训练的问题.
虽然通过加入短连接解决了无法训练的问题,但是作者仍然把deep supervision加入到UNet++中,因为这会带来一个非常棒的优势,就是剪枝

10、剪枝
同时引出三个问题:
为什么UNet++可以被剪枝如何剪枝好处在哪里

我们来看看为什么可以剪枝,这张图特别的精彩。关注被剪掉的这部分,你会发现,在测试的阶段,由于输入的图像只会前向传播,扔掉这部分对前面的输出完全没有影响的,而在训练阶段,因为既有前向,又有反向传播,被剪掉的部分是会帮助其他部分做权重更新的。即测试时,剪掉部分对剩余结构不做影响,训练时,剪掉部分对剩余部分有影响。这就是第一个问题的回答.
因为在深监督的过程中,每个子网络的输出都其实已经是图像的分割结果了,所以如果小的子网络的输出结果已经足够好了,我们可以随意的剪掉那些多余的部分
接着, 我们把每个剪完剩下的子网络根据它们的深度命名为UNet++ L1,L2,L3,L4,后面会简称为L1~L4.
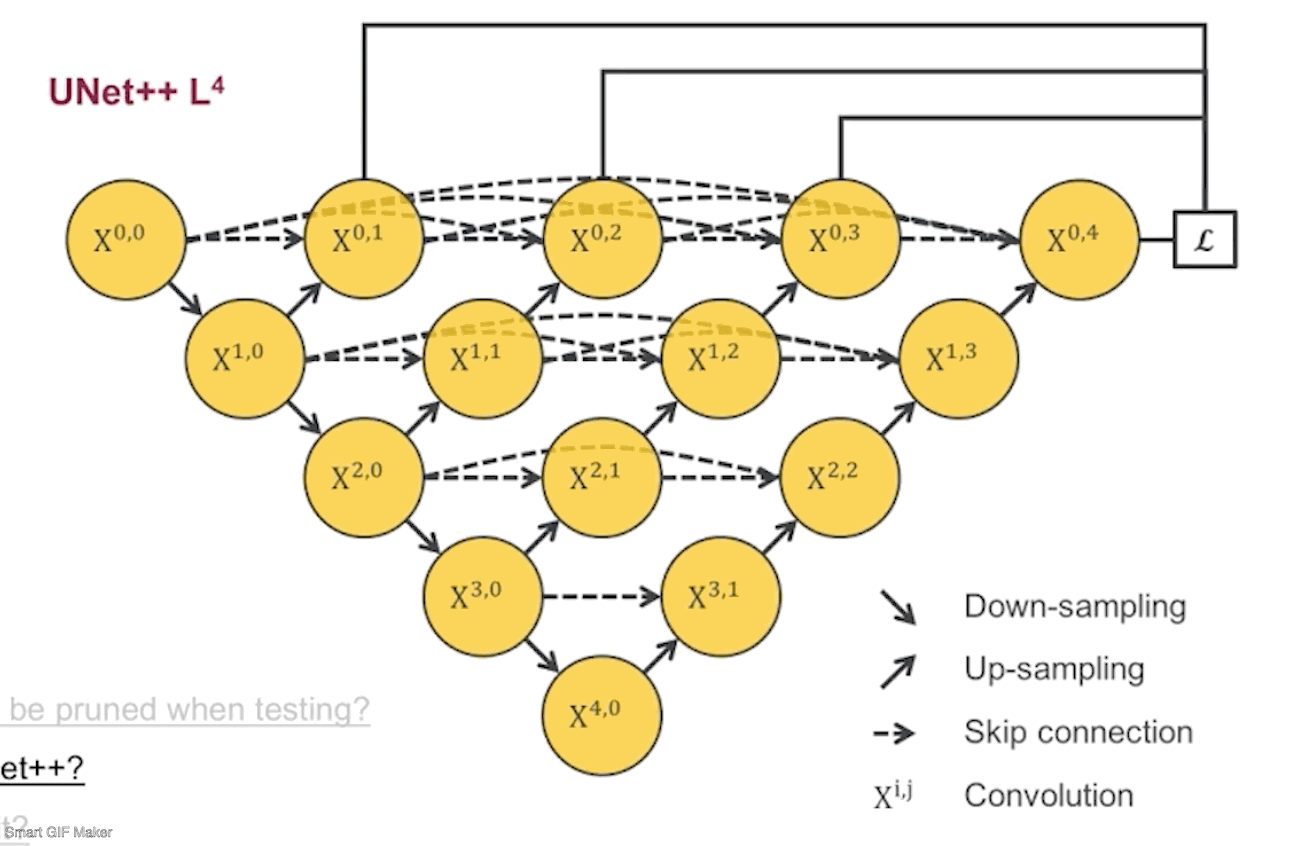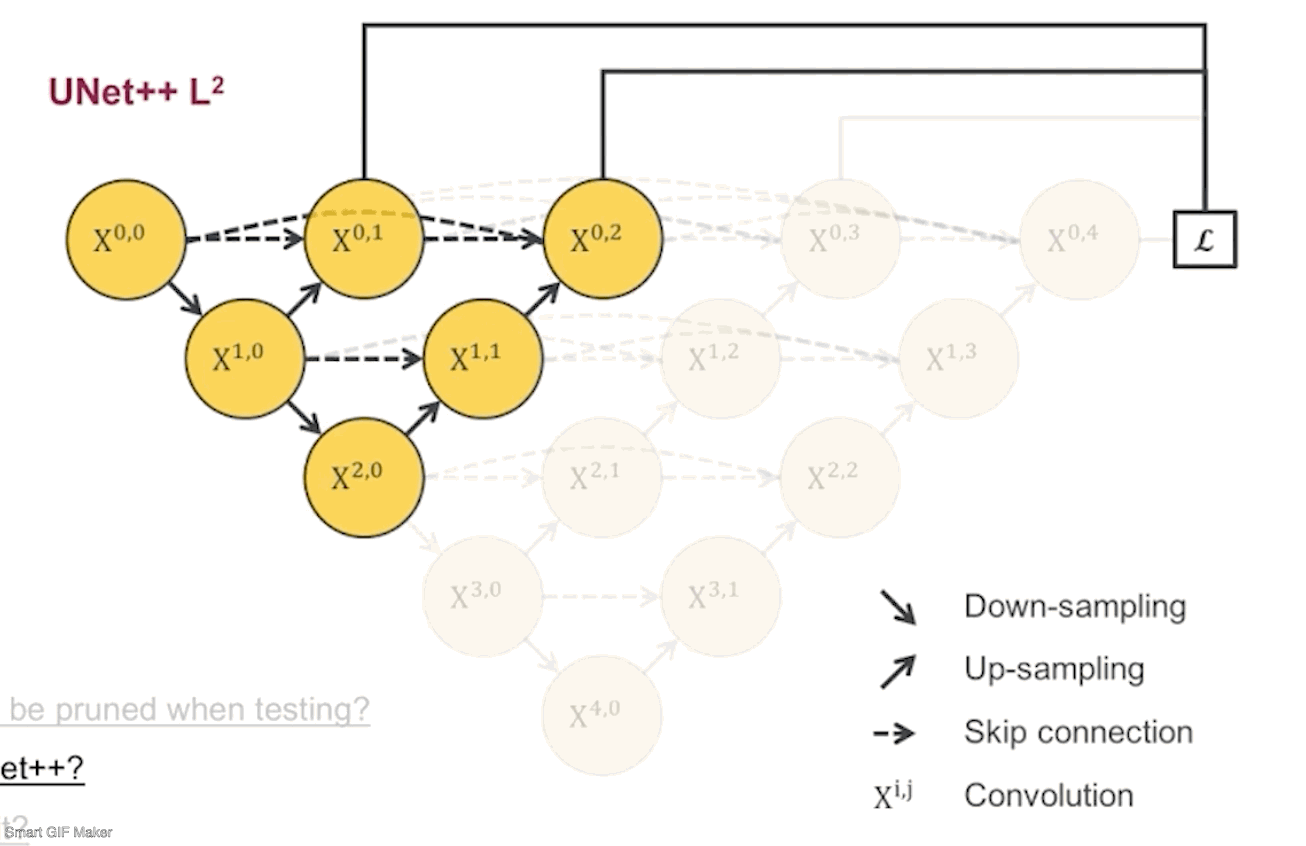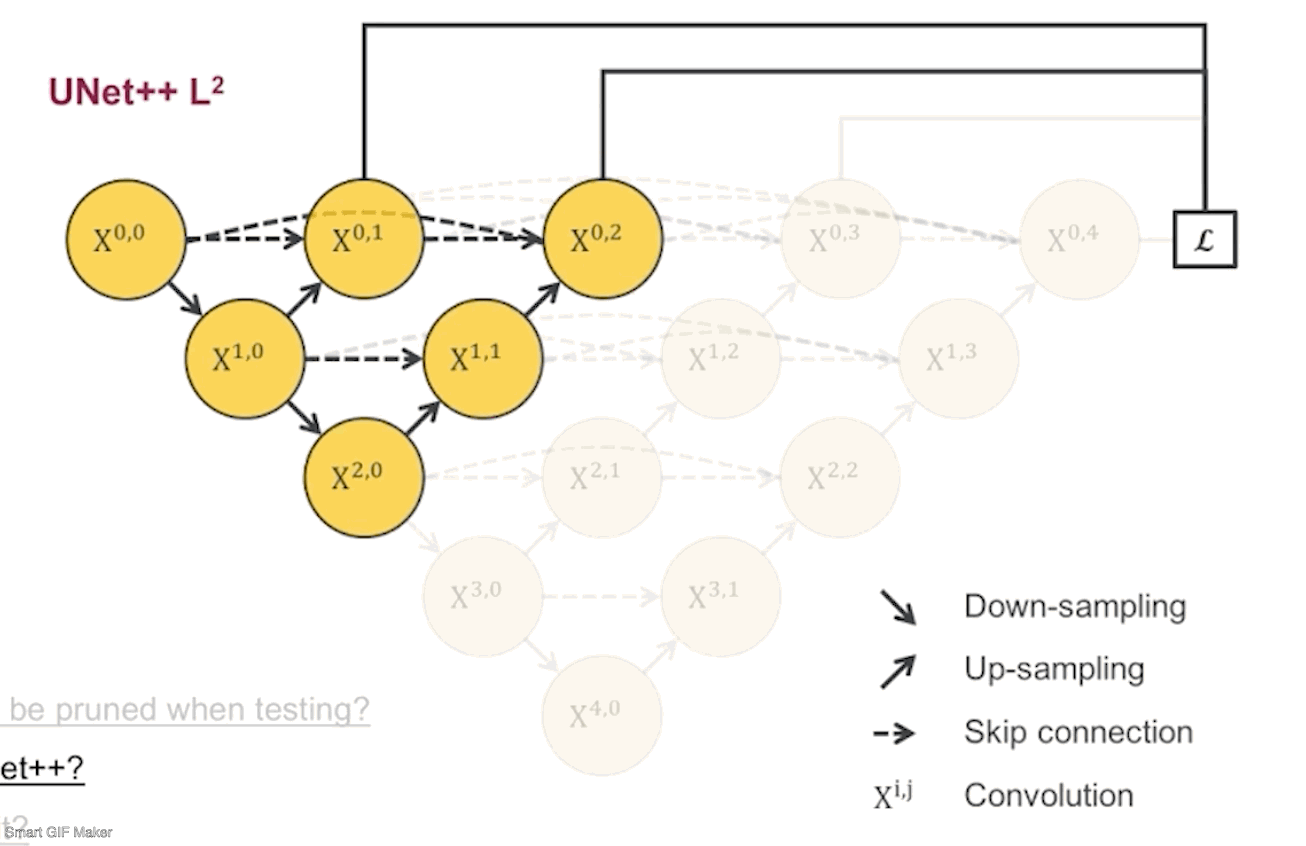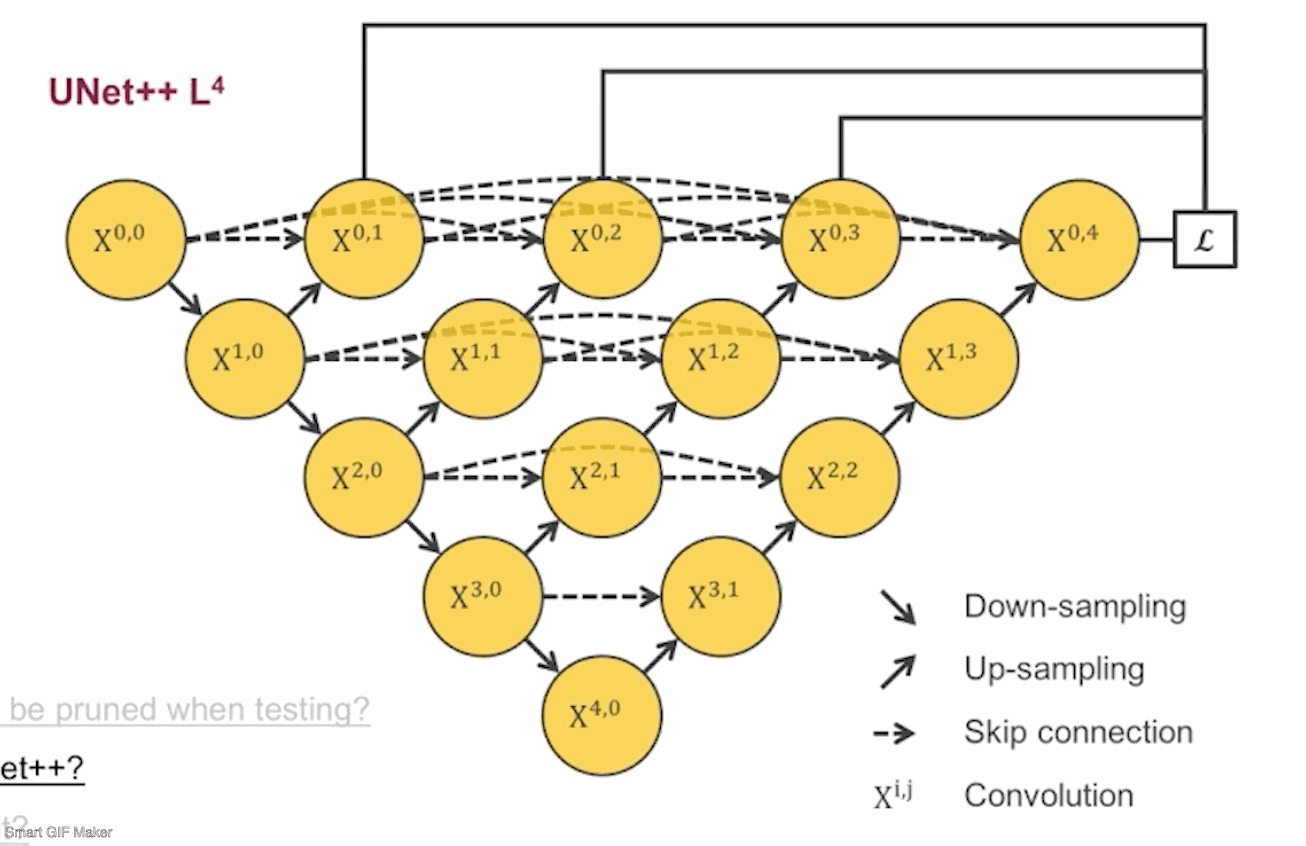
第二个问题是如何去决定剪多少。因为在训练模型的时候会把数据分为训练集,验证集和测试集,训练集上是一定拟合的很好的,测试集是我们不能碰的,所以我们会根据子网络在验证集的结果来决定剪多少(所谓的验证集就是从训练集中分出来的数据,用来监测训练过程用的)。下面是监督各个子网络在验证集下运行的效果:

先看看L1~L4的网络参数量,差了好多,L1只有0.1M,而L4有9M,也就是理论上如果L1的结果我是满意的,那么模型可以被剪掉的参数达到98.8%。不过根据我们的四个数据集,L1的效果并不会那么好,因为太浅了嘛。但是其中有三个数据集显示L2的结果和L4已经非常接近了,也就是说对于这三个数据集,在测试阶段,我们不需要用9M的L4网络,用0.5M的L2网络就足够了。
这也再一次回答了,网络需要多深合适这个问题,这幅图是不是就一目了然。网络的深度和数据集的难度是有关系的,这四个数据集当中,第二个,也就是息肉分割是最难的,大家可以看到纵坐标,它代表分割的评价指标,越大越好,其他都能达到挺高的,但是唯独息肉分割只有在30左右,对于比较难的数据集,可以看到网络越深,它的分割结果是在不断上升的。对于大多数比较简单的分割问题,其实并不需要非常深,非常大的网络就可以达到很不错的精度了。
那我们回答第三个问题,剪枝有什么好处?
横坐标代表的是在测试阶段,单显卡12G的TITAN X (Pascal)下,分割一万张图需要的时间。我们可以看到不同的模型大小,测试的时间差好多。如果比较L2和L4的话,就差了三倍之多。

对于测试的速度,用这一幅图会更清晰。我们统计了用不同的模型,1秒钟可以分割多少的图。如果用L2来代替L4的话,速度确实能提升三倍。
剪枝应用最多的就是在移动手机端了,根据模型的参数量,如果L2得到的效果和L4相近,模型的内存可以省18倍。还是非常可观的数目。
关于剪枝的这部分作者认为是对原先的U-Net的一个很大的改观,原来的结构过于刻板,并且没有很好的利用不用层级的特征。
11、总结
简单的总结一下,UNet++的第一个优势就是精度的提升,这个应该是它整合了不同层次的特征所带来的,第二个是灵活的网络结构配合深监督,让参数量巨大的深度网络在可接受的精度范围内大幅度的缩减参数量。
作者给我们带来了非常饱满的心路历程, 这个过程我们学到了要想设计出更强的结构,你得首先明白这个结构,甚至它的原型(如U-Net)设计背后的心路历程。
(从认识原型,到分析它的组成,到批判性的解读,再到改进思路的形成,实验设计,自问自答 ,这是我在这个作者身上学到的做研究的范式)
reference
1、UNet++作者批判UNet https://zhuanlan.zhihu.com/p/44958351
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/626166
推荐阅读
相关标签

