
热门标签
热门文章
- 1与 Josh Bloch 探讨 Java 未来
- 2Docker 实战:使用 Docker Desktop 在 MacOS 上安装 Docker_mac docker desktop
- 3通过域名访问文件共享服务器,域名访问共享文件夹
- 4《我十年的程序员生涯》系列之二:我写BITLOK的这七年
- 5java操作RabbitMQ添加队列、消费队列和三个交换机_java amqptemplate动态创建交换机 队列 和发送消息
- 6三分钟搞懂git patch 补丁的使用,小学生也能看懂
- 7MySQL数据库——存储过程练习
- 8【idea】idea 中 git 分支多个提交合并一个提交到新的分支_idea中已经push到远端的提交记录合并成一个
- 9创建repo服务器及使用_repo init -u ssh:
- 10vscode git 切换和隐藏分支_vscode切换分支
当前位置: article > 正文
Hadoop运行wordcount实例任务卡在job running的多种情况及解决方法_hadoop运行wordcount卡住了
作者:小小林熬夜学编程 | 2024-06-01 06:28:29
赞
踩
hadoop运行wordcount卡住了
第一种:配置问题
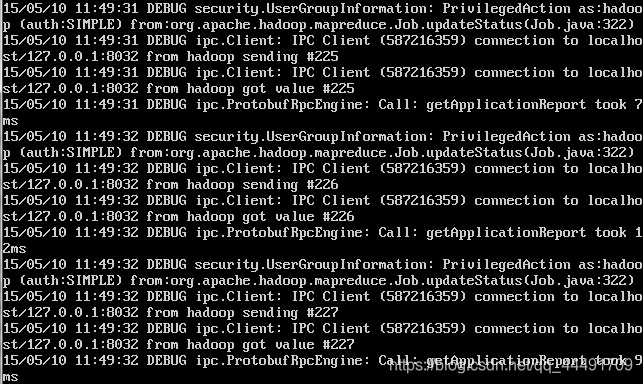
这是别人的图片,据楼主排查解决是因为hosts配置问题…
现象:各种无法运行、启动
解决办法:
1、修改日志级别
export HADOOP_ROOT_LOGGER=DEBUG,console
查看下详细信息,定位到具体问题解决
第二种:服务器问题

**现象:**运行到job时卡住不动
**原因:**服务器配置低下,内存小或磁盘小
**解决办法:**修改yarn.site.xml配置
<!--每个磁盘的磁盘利用率百分比--> <property> <name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name> <value>95.0</value> </property> <!--集群内存--> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <!--调度程序最小值-分配--> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value> </property> <!--比率,具体是啥比率还没查...--> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
除了服务器集群配置低,也有可能是服务器被攻击或恶意程序占用内存Hadoop的MapReduce进程卡住job/云服务器被矿工挖矿
戏剧的是,我今天还遇到一种情况…现象也是Map后卡在Job,原因是:我运行了计算圆周率程序,刚开始测试没问题后手贱执行1000次,掷10000次…Map过程还好,Job开始便无法运行…
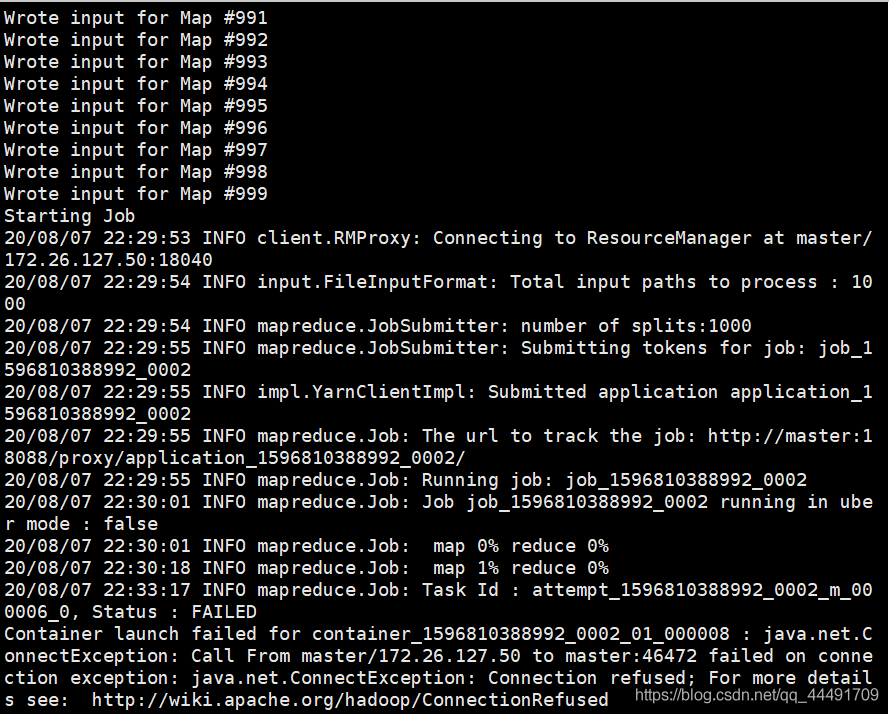
可能是任务太大了,可以尝试换小的执行
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar pi 20 20
- 1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/656403
推荐阅读
相关标签

