
- 1杭电1004题c语言答案,杭电1004题
- 2win10+Python3.7.3+OpenCV3.4.1入门学习(十二 图像轮廓)————12.5 轮廓拟合_最佳拟合方式连接轮廓
- 3DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
- 4VS Code上,QT基于cmake,qmake的构建方法(非常详细)_vscode qt cmake
- 5laravel 使用 vue 和 element
- 61、工具准备:pycharm 和通义灵码_通义灵码 pycharm
- 7java 部署智能合约_java使用web3j调用部署在以太坊上solidity编写的智能合约
- 8PostgreSQL 数据库配置可远程访问_postgresql ip访问
- 9java.lang.IncompatibleClassChangeError异常的正确解决办法,亲测有效,嘿嘿嘿!!!java.lang.IncompatibleClassChangeError异常
- 10Ubuntu git代理修改后,git clone失败Could not resolve proxy: proxy.server.com 重置代理方法_ubuntu22 cound not resolve proxy
扩散模型的发展过程梳理 多个扩散模型理论知识总结/DDPM去噪扩散概率/IDDPM/DDIM隐式去噪/ADM/SMLD分数扩散/CGD条件扩散/Stable Diffusion稳定扩散/LM_adm和ddpm
赞
踩
前言
1.最近发现自己光探索SDWebUI功能搞了快两个月,但是没有理论基础后面科研路有点难走,所以在师兄的建议下,开始看b站视频学习一下扩散模型,好的一看一个不吱声,一周过去了写个博客总结一下吧,理理思路。不保证下面的内容完全正确,只能说是一个菜鸟的思考和理解,有大佬有正确的理解非常欢迎评论告知,不要骂我不要骂我。
2.这里推荐up主,deep_thoughts投稿视频-deep_thoughts视频分享-哔哩哔哩视频 (bilibili.com)
我觉得对于学习而言只有学到了和没学到的差别,以前可能更多的是直接阅读文献,但如果有这样好的学者录个视频带你精读论文是比你自己埋头苦读五百年好太多太多了,学习有时候真的要讲方法和技巧,说白了就是要聪明点,有捷径为什么不走, 真是笨!再强调一点,提到的论文直接搜都可以在arXiv里找到,就不用另附论文链接了。
一、DDPM 去噪扩散概率模型
1. 论文及视频
DDPM是扩散模型的开山之作,《Denoising Diffusion Probabilistic Models》,附一下up主的论文原理讲解和pytorch代码讲解视频。54、Probabilistic Diffusion Model概率扩散模型理论与完整PyTorch代码详细解读_哔哩哔哩_bilibili
DDPM在直接上手学SD功能的时候完全不了解不知道,甚至以为SD那篇才是开篇之作,原来人家这里早有痕迹了。
2. 扩散过程
DDPM是所有扩散模型的基础,主要是分为两个过程,前向扩散过程和反向去噪过程,我们需求的是反向去噪过程,给定一张高斯噪声图片就能通过反向一步一步迭代来生成我们所需的目标样本,但是得到反向过程需要先训练,就要了解前向过程。

大致想法是如图,在用文字来讲讲。
1)前向扩散
该过程是给定X0原始样本然后通过每一步逐层随机加高斯噪声来使得最后的XT变成一个符合标准分布的样本~N(0,1),这里的加噪过程是符合马尔科夫链的,也就是说未来Xt只与当前Xt-1有关,与之前的X0都无关,但因为是随机加的高斯噪声,符合高斯分布,所以整个前向过程都可以通过一系列计算得到,Xt可以通过t、X0计算得来,有了Xt,同样计算就能得出Xt-1,知道了Xt和Xt-1之后,就能得出前向过程Xt-1到Xt的后验概率q,q也是服从高斯分布的,然后贝叶斯公式推导起来,得到q的均值、方差公式,公式只有对固定参数的计算,这些是设置的固定值不是要求通过迭代优化的,所以整个前向过程是不含参数不需要用网络训练的过程;
2)反向去噪
该过程的目的就是给定一张高斯噪声图片即Xt,然后用模型比如NN模型来预测出一个Xt到Xt-1之间的p条件概率,因为加噪过程是一步步慢慢加噪的,所以近似的p也是服从高斯分布,这里目标函数loss就是要使得这个p和q之间的差值越来越小,越接近越好,这样才可以还原出原始X0。论文设计了三种loss:1)直接对p、q进行KL散度,优化过程就是最小化这个loss,对qp进行其实对它们的均值进行预测,这里有几种预测或者说求解的方法(线性加权),不展开讲了;2)对预测的原始X0进行KL散度;3)第三种是论文推荐的,就是说预测噪声,大概的思路就是前向过程X0、t可以求出Xt,所以有个关系式表示出这三者之间的关系,转换成等式加个噪声就可以,把这个等式在代入之前推导的目标函数中,得出一个新的loss即Lsimple,最后实验证明预测噪声的方法生成质量最好也最快。反向去噪的过程是含参的过程,需要网络一步步迭代优化,使得两个分布越来越接近,或者说loss最小化。
3. 网络架构U-Net
DDPM常用的训练网络是U-Net,这里也跑去再温习了一遍U-Net网络的原理,《U-Net: Convolutional Networks for Biomedical Image Segmentation》56、U-Net用于图像分割以及人声伴奏分离原理代码讲解_哔哩哔哩_bilibili
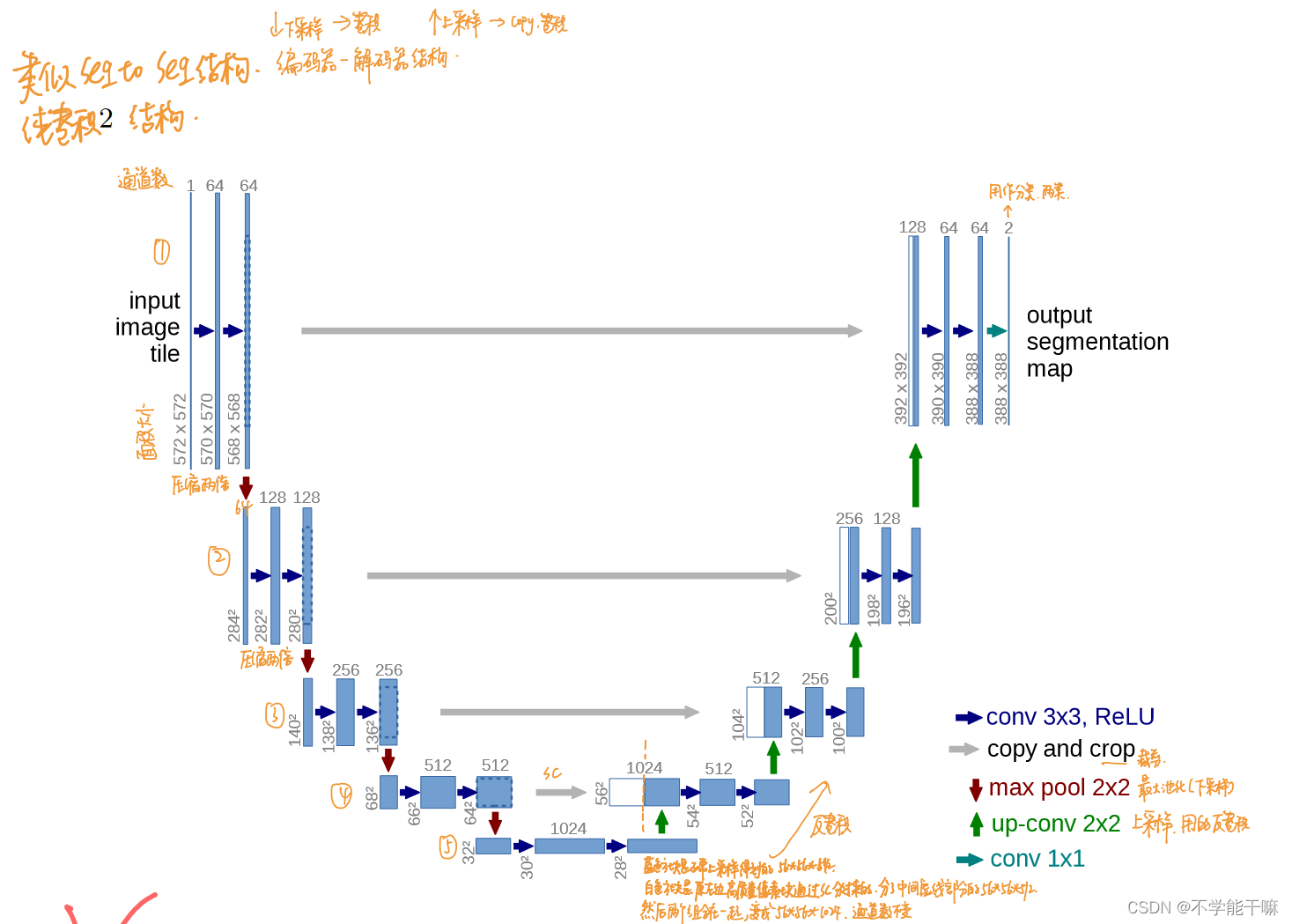
这个网络重点就是这张示例图,是编码器-解码器的过程,通过卷积、上下采样、最大池化以及跳跃连接的方式,学习图像特征的同时也保留高层特征信息不丢失。
二、IDDPM
1. 论文及视频
《Improved Denoising Diffusion Probabilistic Models》,这篇是在DDPM的基础上进行改进,58、Improved Diffusion的PyTorch代码逐行深入讲解_哔哩哔哩_bilibili
2. 改进点
1)引入了Noise Schedule算法来对网络比如U-Net预测的噪声进行优化处理,以前是在每步训练中都应用固定的噪声水平,Noise Schedule使得模型可以使用不同的噪声水平可以在不同阶段学习到更多的细节信息,统筹生成进度,是一种更灵活的噪声策略;
2)使用了新的训练策略,DDPM通常采用预训练和微调,IDDPM加入了Refinement Stage 一个额外训练阶段,更长的训练时间、更小的学习率、更强的梯度惩罚,使得模型可以生成更高质量的样本;
3)使用了一种改进的优化算法SGLD(Stochastic Gradient Langevin Dynamics),DDPM是通过随机梯度下降SGD进行模型训练。
学习得不够细致,但其实目前大多数的论文代码不是按照原始DDPM来改的,而是基于IDDPM这篇论文来改的,还是有很多的知识点需要重视,也需要更关注它的代码。
三、ADM 自回归去噪扩散模型
1. 论文及视频
《Autoregressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting》,用于序列预测的扩散模型。看完视频也没怎么看懂,给人一种打白工的感觉(可恶!)57、Autoregressive Diffusion Model自回归扩散模型用于序列预测论文讲解_哔哩哔哩_bilibili
2. 模型流程
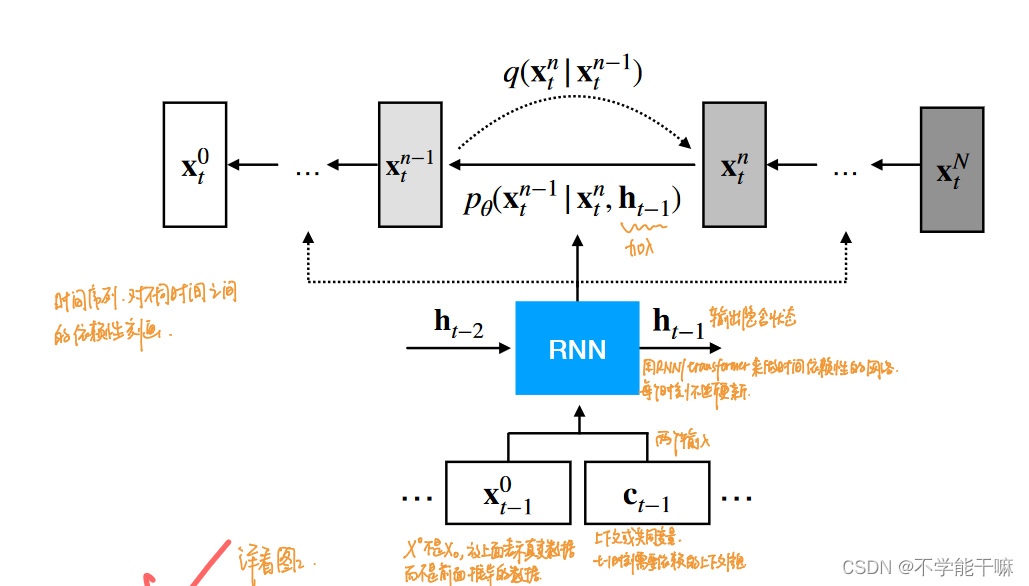

AMD主要是RNN+DDPM, 针对的是时间序列预测任务、信号处理啊啥的,和我的研究关系不大。但是看图稍微讲讲,左图很明显,是在反向去噪过程过加入RNN,RNN的输入是Xt-1,然后Ct-1表示基于Xt-1的上下文信息,然后模型会输出一个隐含状态ht-1,然后会把这个ht-1也加入到给定的Xt求Xt-1中,持续作用下去,右图是核心伪代码,也可以看出h也进入了计算式中。
四、SMLD 分数扩散模型
1. 论文及视频
《SCORE-BASED GENERATIVE MODELING THROUGH STOCHASTIC DIFFERENTIAL EQUATIONS》
62、Score Diffusion Model分数扩散模型理论与完整PyTorch代码详细解读_哔哩哔哩_bilibili
63、必看!概率扩散模型(DDPM)与分数扩散模型(SMLD)的联系与区别_哔哩哔哩_bilibili
2. 模型流程
貌似后续对于扩散用这个分数的比较多,引入了这个分数、评分、分数网络等一系列知识点。SMLD分数扩散模型是基于求解随机微分方程来建模,loss的计算也是基于此设计的分数目标函数,是用预测的原始X0来计算的loss。DDPM是一步一步逐步地去加噪声,而SMLD是给X0加不同量级的噪声来训练一个分数网络,使得XT~N(0,σ^2),ODE采样。此外还有一些知识点,NCSN/SDEs/郎之万采样,都是比较生涩的东西,后续搞明白了再编辑。
五、DDIM 扩散隐式去噪模型
1. 论文及视频
《DENOISING DIFFUSION IMPLICIT MODELS》,算是除了DDPM之外更需要多关注的论文和模型,是在DDPM基础上一个较大的突破。
64、扩散模型加速采样算法DDIM论文精讲与PyTorch源码逐行解读_哔哩哔哩_bilibili
2. 模型原理
DDIM是为了提高采样速度等原因出现的,当时DDPM虽然生成质量和GAN打成平手或者优于GAN,但是出图的速度是远远不如GAN的,所以诞生了DDIM扩散隐式去噪模型。DDIM突破的点在于改变了前向扩散模型的方式,这里结果的得出也是基于分数模型发现的,所以先学学分数模型是有必要的。原DDPM的前向扩散过程是马尔科夫链的形式,虽然计算啥的比较方便也不含参,但是你的样本后面的结果必须要等前面结果出来才能进行计算,未来与当前状态有关,就是要等前面出了结果才能计算后面,所以导致采样速度不OK,出一张图要十几分钟,黄花菜都凉了。所以DDIM根据分数模型分析出前向扩散模型其实不需要真的符合马尔科夫链的形式,将其改为非马尔科夫链,反向扩散那些都不变,所以可以继续延续使用DDPM的loss,改变的只是前向q(Xt|X0),然后利用respacing替换这个技巧来提高采样速度,这个技巧大概就是说在迭代过程中,不用等到所有步骤都完成才开始采样,而是在每步迭代时只更新部分样本,在下一步只用这些部分样本来进行新的更新,采取只用短的子序列来采样,这样采样速度就提上去了。
而且通过计算得出,其实DDIM是更一般化的DDPM,它的公式loss、q啥的在特定情况下取值就是DDPM的形式,所以其实DDIM更具有普遍性。
3. 客观判断指标 IS/FID
另外,上面64的视频不仅讲解了DDIM,也讲了两个客观性指标来分析生成式模型的好坏,即IS(Inception Score)和FID(Fréchet Inception Distance),前者是将生成图像直接进行一个评测,是内部的比较,值越大越好,后者是将生成图像和真实图像作对比,会与外部比较,值越小越好。一般来说对于生成模型的好坏判断,两者都会进行计算,综合看待两个值来判断模型好坏。
六、CGD 条件扩散模型
1. 论文及视频
CGD,Classifier Guided Diffusion,《Diffusion Models Beat GANs on Image Synthesis》66、Classifier Guided Diffusion条件扩散模型论文与PyTorch代码详细解读_哔哩哔哩_bilibili
2. 模型原理
条件扩散模型的创新在于在DDPM的基础上额外加了一个分类器,感觉有点SD的影子了。具体来说就是guided diffusion加入了一个标签,本身DDPM是无条件的扩散模型,这里的CGD就是有条件的扩散,引入一个分类器网络,前向扩散过程不只是单纯的加噪声而是将噪声和标签作为输入,其他的不变,所以导致反向p的均值计算变了,公式里多了一个额外的g偏移量,使得模型生成更具语义上正确性的图像,SD文生图的前身?
七、Diffusion-LM 基于扩散模型的语言模型
1. 论文及视频
《Diffusion-LM Improves Controllable Text Generation》
67、DiffusionLM 基于扩散模型的语言模型论文原理精讲_哔哩哔哩_bilibili
2. 模型原理
与DDPM不同,语言模型没有涉及到图像或者其他类型的生成,就是用来做可控的文本生成任务的,是纯文本生成模型,比如你输入“今天天气很”到训练好的LM模型里,然后模型就会给出几个可能得预测结果,比如“好”“热”“不好”等,这样来生成连贯的文本序列,和图像没啥关系,就不多说了。
八、SD Stable Diffusion 稳定扩散模型!!!
1. 论文
终于讲到最后的重点的了!!!《High-Resolution Image Synthesis with Latent Diffusion Models》
这个up主没有专门分个视频讲,但其实原理和DDPM大差不离,是一种改进的DDPM模型,但是由于设计了SDWebUI,使用率是很高的,衍生出了很多功能。
2. 模型架构
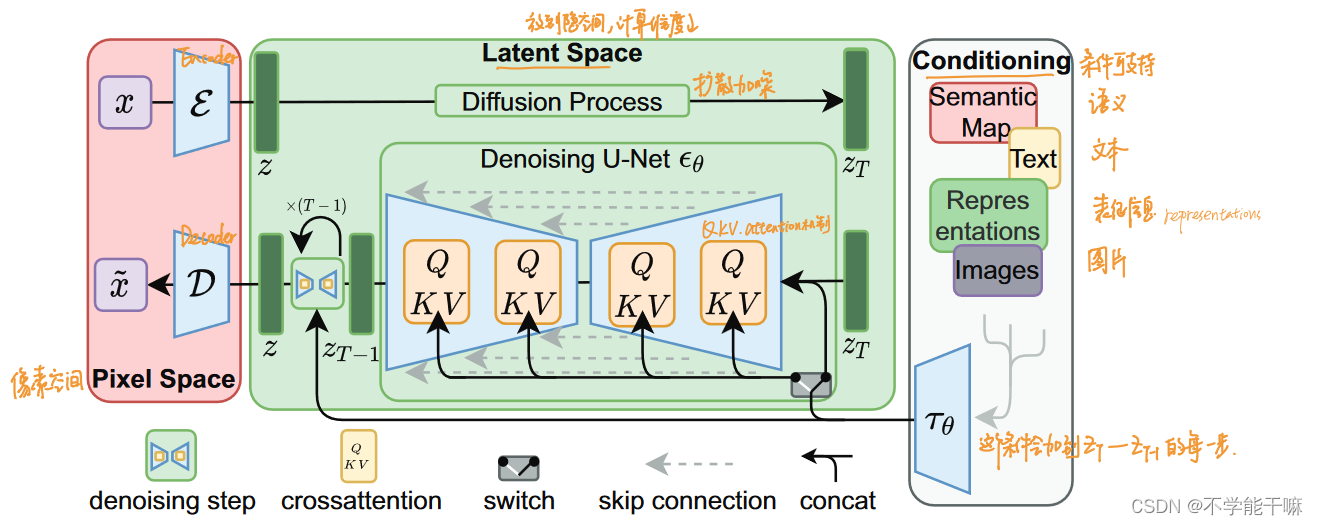 论文里的这张图可以充分的说明SD的训练流程,SD的创新点就在于中间绿色部分的Latent Space,是把前向扩散过程、反向U-Net编码解码过程等等这些东东都放到了这隐空间去完成,里面的数据被映射成潜在的向量,是低维表示,包含数据的重要特征和结构,通过在这个隐空间去调整这些潜在变量,提高模型的灵活性和表达能力,更多样更可控,再加上旁边引入的conditioning条件,这个条件包括语义、文本、表征信息、图片,然后输入到隐空间的反向过程的每一步中,以此实现对生成样本特征的精确控制。条件这里也可以看出文生图、图生图等等功能的影子。
论文里的这张图可以充分的说明SD的训练流程,SD的创新点就在于中间绿色部分的Latent Space,是把前向扩散过程、反向U-Net编码解码过程等等这些东东都放到了这隐空间去完成,里面的数据被映射成潜在的向量,是低维表示,包含数据的重要特征和结构,通过在这个隐空间去调整这些潜在变量,提高模型的灵活性和表达能力,更多样更可控,再加上旁边引入的conditioning条件,这个条件包括语义、文本、表征信息、图片,然后输入到隐空间的反向过程的每一步中,以此实现对生成样本特征的精确控制。条件这里也可以看出文生图、图生图等等功能的影子。
深入浅出完整解析Stable Diffusion(SD)核心基础知识 - 知乎 (zhihu.com)
最后总结一下,扩散模型的基础是DDPM,训练过程为前向扩散和反向去噪的过程,其他的扩散模型都是在此基础上进行改进或者说针对某个任务来修改。这个理论学起来比较繁琐,但是希望对我后面训练SD模型会有一些帮助?
之后就接着总结一下多模态的部分东东:CLIP/BLIP~多模态 CLIP/BLIP/BLIP-2论文理论知识总结-CSDN博客

