
- 1SpringBoot整合MyBatis-Plus
- 2FPGA工程师面试题解析与深度探讨_fpga面试题 项目细节
- 3uni-app(15)— uni-app中组件的创建以及组件的生命周期函数_uniapp函数式组件
- 4软件测试之BUG篇(定义,创建,等级,生命周期)_软件测试面试题:bug的生命周期?
- 5字节跳动面试挂在2面,复盘后,决定二战....._字节跳动二面
- 6笔记-cs224n(基于深度学习的自然语言处理)_cs224n和cs224d的区别
- 7云服务器SQL数据库端口1433访问不了?------三步设置教你快速开放云数据库端口_iis服务中的1433端口,无法在局域网中访问
- 82024年AI辅助研发:科技创新的引擎_ai研发辅助
- 9Python 基于 Django 的漏洞扫描系统,附源码_利用python语言实现一个漏洞扫描系统,需包括以下功能:
- 10安装Apache Flink的步骤
EM算法(Expectation Maximization Algorithm)详解_maximum likelihood expectation maximization algori
赞
踩
EM算法(Expectation Maximization Algorithm)详解
- 主要内容
- EM算法简介
- 预备知识
- 极大似然估计
- Jensen不等式
- EM算法详解
- 问题描述
- EM算法推导
- EM算法流程
- EM算法优缺点以及应用
1、EM算法简介
EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),所以算法被称为EM算法(Expectation Maximization Algorithm)。EM算法受到缺失思想影响,最初是为了解决数据缺失情况下的参数估计问题,其算法基础和收敛有效性等问题在Dempster,Laird和Rubin三人于1977年所做的文章Maximum likelihood from incomplete data via the EM algorithm中给出了详细的阐述。其基本思想是:首先根据己经给出的观测数据,估计出模型参数的值;然后再依据上一步估计出的参数值估计缺失数据的值,再根据估计出的缺失数据加上之前己经观测到的数据重新再对参数值进行估计,然后反复迭代,直至最后收敛,迭代结束。
EM算法作为一种数据添加算法,在近几十年得到迅速的发展,主要源于当前科学研究以及各方面实际应用中数据量越来越大的情况下,经常存在数据缺失或者不可用的的问题,这时候直接处理数据比较困难,而数据添加办法有很多种,常用的有神经网络拟合、添补法、卡尔曼滤波法等等,但是EM算法之所以能迅速普及主要源于它算法简单,稳定上升的步骤能非常可靠地找到“最优的收敛值”。随着理论的发展,EM算法己经不单单用在处理缺失数据的问题,运用这种思想,它所能处理的问题更加广泛。有时候缺失数据并非是真的缺少了,而是为了简化问题而采取的策略,这时EM算法被称为数据添加技术,所添加的数据通常被称为“潜在数据”,复杂的问题通过引入恰当的潜在数据,能够有效地解决我们的问题。
2、预备知识
介绍EM算法之前,我们需要介绍极大似然估计以及Jensen不等式。
2.1 极大似然估计
(1)举例说明:经典问题——学生身高问题
我们需要调查我们学校的男生和女生的身高分布。 假设你在校园里随便找了100个男生和100个女生。他们共200个人。将他们按照性别划分为两组,然后先统计抽样得到的100个男生的身高。假设他们的身高是服从正态分布的。但是这个分布的均值
问题:我们知道样本所服从的概率分布的模型和一些样本,需要求解该模型的参数。如图1

图1
我们已知的有两个:样本服从的分布模型、随机抽取的样本;我们未知的有一个:模型的参数。根据已知条件,通过极大似然估计,求出未知参数。总的来说:极大似然估计就是用来估计模型参数的统计学方法。
(2)如何估计
问题数学化:设样本集
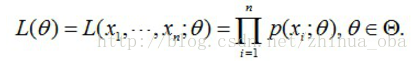
这个概率反映了,在概率密度函数的参数是
(3)求最大似然函数估计值的一般步骤
首先,写出似然函数:
然后,对似然函数取对数:
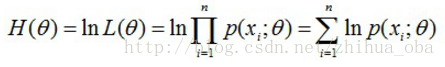
接着,对上式求导,令导数为0,得到似然方程;
最后,求解似然方程,得到的参数
2.2 Jensen不等式
设
Jensen不等式表述如下:如果
例如,图2中,实线
注:
1、Jensen不等式应用于凹函数时,不等号方向反向。当且仅当
2、关于凸函数,百度百科中是这样解释的——“对于实数集上的凸函数,一般的判别方法是求它的二阶导数,如果其二阶导数在区间上非负,就称为凸函数(向下凸)”。关于函数的凹凸性,百度百科中是这样解释的——“中国数学界关于函数凹凸性定义和国外很多定义是反的。国内教材中的凹凸,是指曲线,而不是指函数,图像的凹凸与直观感受一致,却与函数的凹凸性相反。只要记住“函数的凹凸性与曲线的凹凸性相反”就不会把概念搞乱了”。关于凹凸性这里,确实解释不统一,博主暂时以函数的二阶导数大于零定义凸函数,此处不会过多影响EM算法的理解,只要能够确定何时
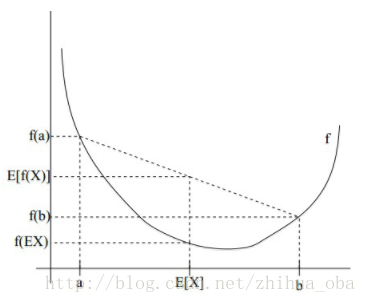
图2
3、EM算法详解
3.1 问题描述
我们目前有100个男生和100个女生的身高,共200个数据,但是我们不知道这200个数据中哪个是男生的身高,哪个是女生的身高。假设男生、女生的身高分别服从正态分布,则每个样本是从哪个分布抽取的,我们目前是不知道的。这个时候,对于每一个样本,就有两个方面需要猜测或者估计: 这个身高数据是来自于男生还是来自于女生?男生、女生身高的正态分布的参数分别是多少?EM算法要解决的问题正是这两个问题。如图3:

图3
3.2 EM算法推导
样本集
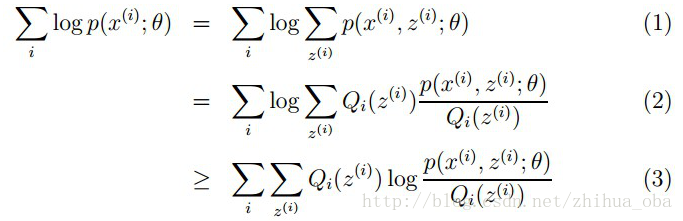
其中,(1)式是根据
这里简单介绍一下(2)式到(3)式的转换过程:由于
上述过程可以看作是对
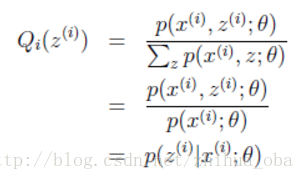
至此,我们推出了在固定其他参数
3.3 EM算法流程
初始化分布参数
E步骤:根据参数
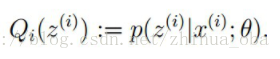
M步骤:将似然函数最大化以获得新的参数值:
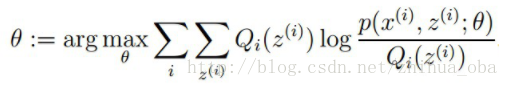
4、EM算法优缺点以及应用
优点:简介中已有介绍,这里不再赘述。
缺点:对初始值敏感:EM算法需要初始化参数
EM算法的应用:k-means算法是EM算法思想的体现,E步骤为聚类过程,M步骤为更新类簇中心。GMM(高斯混合模型)也是EM算法的一个应用,感兴趣的小伙伴可以查阅相关资料。

