
- 1数据分析——分群思维、RFM实现用户分群
- 2Python NumPy中使用argsort方法进行排序_argsort降序
- 3FPGA-06FPGA动态数码管显示_4'd0
- 4现代IT基础设施与运维技术全览-云计算与数据中心技术栈
- 5sumo的简单应用_SUMO学习入门(一)SUMO介绍
- 6pytest实现多进程与多线程运行超好用的插件_pytest多线程并发用例
- 7Hadoop学习笔记: 分布式数据库 HBase_hbase的物理模型
- 8如何解决Cannot execute /home/hadoop/hadoop/libexec/hadoop-config.sh._cannot execute hadoop-config.sh
- 9SpringBoot该怎么使用Neo4j_springboot neo4j 关系
- 10告别迷茫!AI绘画工具初学者指南(小白解惑篇)_哩布哩布ai官网
驱动Llama 2提升效果的关键是什么?_llama2语音识别
赞
踩
去年,ChatGPT为全球人工智能的发展打开了新纪元。大语言模型(LLM)瞬间成为各大互联网公司争相追捧和追逐的蛋糕。全球进入到生成式大语言模型的军备赛中。当大家沉浸于讨论ChatGPT的的收费标准,是“$0.002 per 1k tokens”,每1000个tokens需要花费0.002美元,是否值得投资的时候....

LLM 新纪元
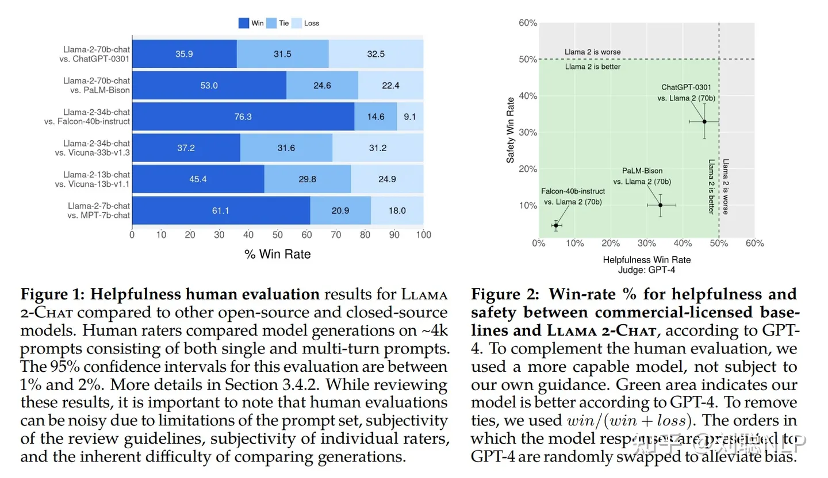
近期,Llama 2打开了AI大模型全球共享的新格局。此版本包括模型权重和用于预训练和微调的Llama语言模型的起始代码,参数范围从70亿到700亿。Llama 2相比上一代,不仅用了更多的训练数据,而且context length直接翻倍,达到了4096。如图所示,Llama 2与目前主流的模型在人类的评判下是占据上风的。这个评测包括了在上下文长度为 4K 下的单轮与多轮对话。评测结果更加让人期待其落地到各行各业的效果。
Meta 同时表示将与微软云服务 Azure 合作,向全球开发者首发基于 Llama 2 模型的云服务。此外,高通计划从 2024 年开始在旗舰智能手机和 PC 上提供基于 Llama 2 的 AI 实现,使开发人员能够利用骁龙平台的 AI 功能引入新的生成式 AI 应用。阿里云、华为云和亚马逊也纷纷表示将 Llama2 集成到自己的云服务平台。使得 Llama 2 一下成为全球互联网公司争相追捧的新星。
Llama 2 模型效果提升的关键
模型效果提升的关键其实还是——数据,数据就如同成就Llama 2、ChatGPT等高楼大厦的台阶。
Llama 2不仅仅是在训练数据量的层面相比上一代Llama 1增加了40%,而且在数据来源和丰富性上也有了很大的改善。虽然论文没有对其使用的数据一一罗列,从Llama的官网可以看出其数据合作商众多,而海天瑞声是唯一一家中国企业。
海天瑞声拥有资深的行业背景,卓越的数据生产能力。作为中国最早从事Al训练数据解决方案提供商之一,致力于为AI企业、研发机构提供多语言、跨域、跨模态的人工智能训练数据及相关数据服务,涵盖语音识别、语音合成、计算机视觉、自然语言等多个核心领域,覆盖全球近200个主要语种及方言,全方位助力AI前沿项目的全球商业落地。
大规模中文多轮对话数据集
当前中文对话领域,公开数据集往往量少、分布有偏、价格昂贵甚至不能商用。这就导致大模型在中文对话方面的能力,相比英文对话总是略显不足。尤其是在一些需要比较深入的中文语言理解能力的对话场景,无论开源还是闭源的大模型,往往都表现不佳。
基于以上痛点,海天瑞声发布符合中国人语言表达习惯的超大规模中文多轮对话数据集——DOTS-NLP-216。
这是一个符合中国人表达习惯的自然对话数据集,共计约1,0000,000轮,上亿级token,包含正式&非正式风格对话,使用偏口语化自然表达。覆盖工作、生活、校园等场景,及金融、教育、娱乐、体育、汽车、科技等领域。
在数据集构成上,DOTS-NLP-216包含了对真实场景的对话采集,和高度还原真实场景的模拟对话这两种方式,来兼顾了分布的代表性、多样性和样本规模。
样例:

欢迎访问海天瑞声官网,了解更多「中文千万轮对话语料库 DOTS-NLP-216」详情。

