
- 1Tensorflow 环境配置与安装版本的选择_tensorflow各版本 安装需求
- 2小程序获取不到用户头像和昵称返回微信用户问题解决,即小程序授权获取用户头像规则调整的最新解决方案_微信小程序获取头像加载弹出
- 3平面切分- 蓝桥杯第十一届Python组第九题_平面切分摘要
- 4zabbix配置(三)之mysql监控_怎么查看zabbix的mysql配置
- 5jdk8銝要onematch_JDK8新特性详解 - 纯粹而又极致的光--木九天 - OSCHINA - 中文开源技术交流社区...
- 6无线瘦AP部署——Capwap隧道原理及故障:无线Capwap隧道技术原理_在瘦ap与ac通讯,中,我们规定了capwap的通信方式,那么capwap隧道的建立步骤中几步
- 7一、Docker:Linux/Windows在线安装Docker与命令大全总结_docker for windows installer
- 8洛谷刷题C++语言 | P5705 数字反转_输入一个不小于100且小于1000数字反转c语言
- 9校验输入大于0且可保留小数点后两位数的正则_正则大于0保留两位小数
- 10可信计算3.0工程初步pdf_查校 | 英国大学工业工程与运筹学专业40个授课硕士+研究Mphil/Phd 项目汇总...
Java基础 & 常见数据结构与算法 & 项目总结_java常用数据结构和基本算法
赞
踩
Java基础
1 Java基础必知必会
1.1 Java语言有哪些特点?
- 面向对象(封装,继承,多态);
- 平台无关性,平台无关性的具体表现在于,Java 是“一次编写,到处运行(Write Once,Run any Where)”的语言,因此采用 Java 语言编写的程序具有很好的可移植性,而保证这一点的正是 Java 的虚拟机机制。在引入虚拟机之后,Java 语言在不同的平台上运行不需要重新编译。
- 可靠性、安全性;
- 支持多线程。C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持;
- 支持网络编程并且很方便。Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便;
- 编译与解释并存;
1.2 说说你对Java面向对象的理解
参考:https://blog.csdn.net/bo123_/article/details/88605984
Java 是面向对象的编程语言,对象就是面向对象程序设计的核心。其基本思想是使用对象、类、继承、封装、多态等基本概念来进行程序设计。从现实世界中客观存在的事物(即对象)出发来构造软件系统,并且在系统构造中尽可能运用人类的自然思维方式。所谓对象就是真实世界中的实体,对象与实体是一一对应的,也就是说现实世界中每一个实体都是一个对象,它是一种具体的概念。对象有以下特点:
- 对象具有属性和行为。
- 对象具有变化的状态。
- 对象具有唯一性。
- 对象都是某个类别的实例。
- 一切皆为对象,真实世界中的所有事物都可以视为对象。
简单来说,我们自然世界中的每一个个体都是一个对象,而每一个个体又都不一样,有的黑皮肤,有的黄皮肤,有的白皮肤,有的长头发,有的短头发,高矮胖瘦各不相同。但是因为我们都有相同的一些特性,比如会讲话,有手有脚,有五官,是哺乳动物,正因为我们这些共同点,所以我们共同属于一个种类——人类。人类,就是人的总称,也是相似对象的一种抽象。
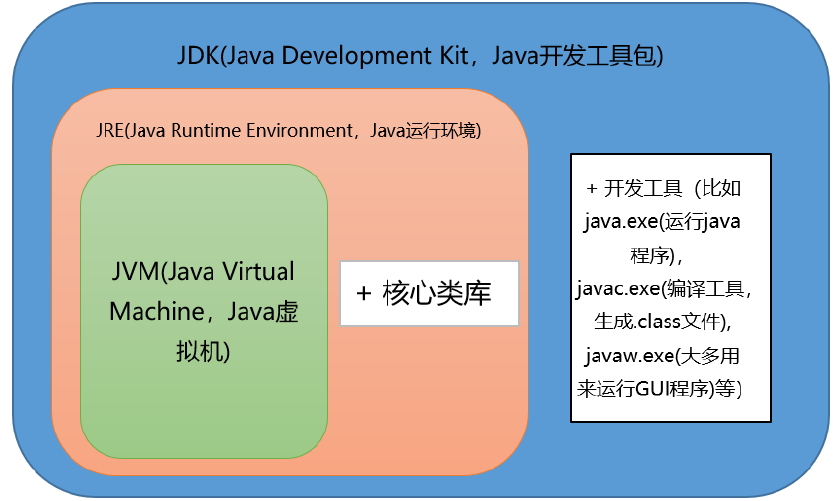
1.3 JVM、JRE和JDK的关系是什么?
- JDK是(Java Development Kit)的缩写,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。
- JRE是Java Runtime Environment缩写,它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。
- JDK包含JRE,JRE包含JVM。
1.4 什么是字节码?采用字节码的好处是什么?
Java之所以可以“一次编译,到处运行”,一是因为JVM针对各种操作系统、平台都进行了定制,二是因为无论在什么平台,都可以编译生成固定格式的字节码(.class文件)供JVM使用。因此,也可以看出字节码对于Java生态的重要性。
之所以被称之为字节码,是因为字节码文件由十六进制值组成,而JVM以两个十六进制值为一组,即以字节为单位进行读取。在Java中一般是用javac命令编译源代码为字节码文件,一个.java文件从编译到运行的示例如图所示。
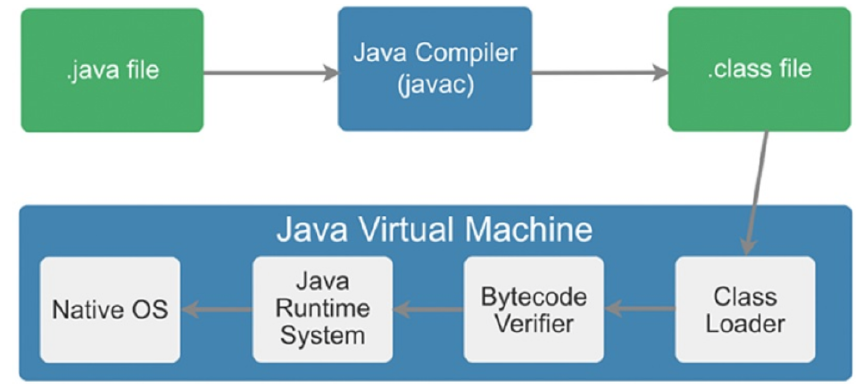
Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。
2 Java中的 数据类型 & 关键字
2.1 Java有哪些数据类型?
Java 语言的数据类型分为两种:基本数据类型和引用数据类型。
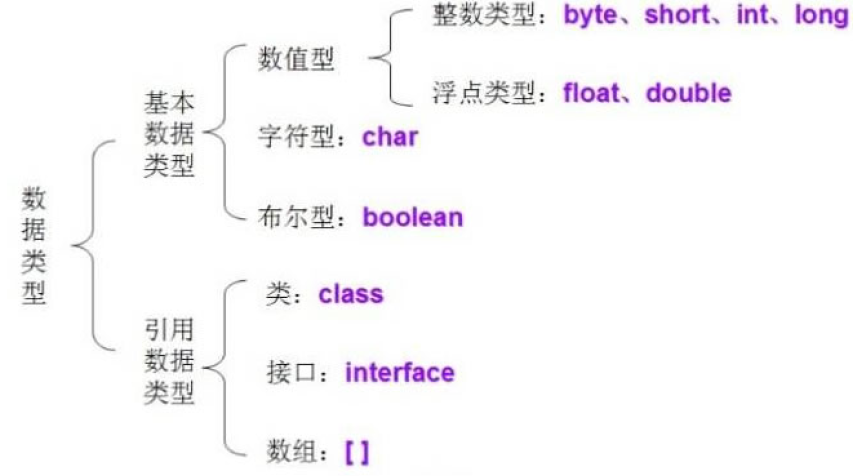
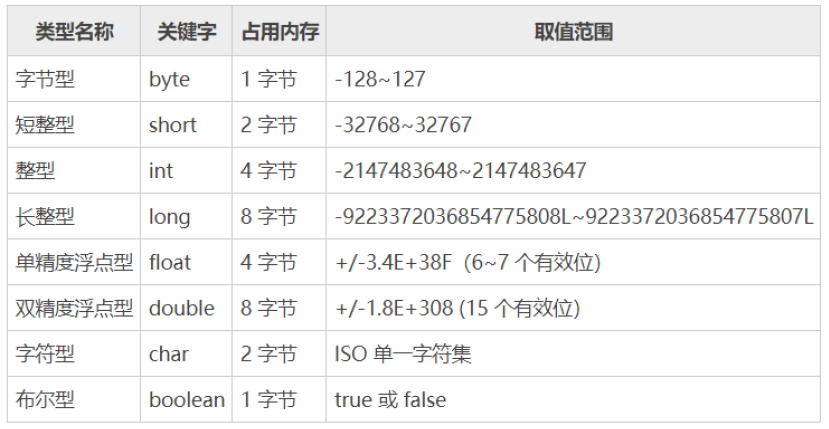
基本数据类型包括 boolean(布尔型)、float(单精度浮点型)、char(字符型)、byte(字节型)、short(短整型)、int(整型)、long(长整型)和 double (双精度浮点型)共 8 种,如下图所示。
引用数据类型建立在基本数据类型的基础上,包括数组、类和接口。引用数据类型是由用户自定义,用来限制其他数据的类型。另外,Java 语言中不支持 C++ 中的指针类型、结构类型、联合类型和枚举类型。
2.2 Java中的关键字
参考:https://blog.csdn.net/dianzijinglin/article/details/52251868
java中的修饰符分为类修饰符,字段修饰符,方法修饰符。
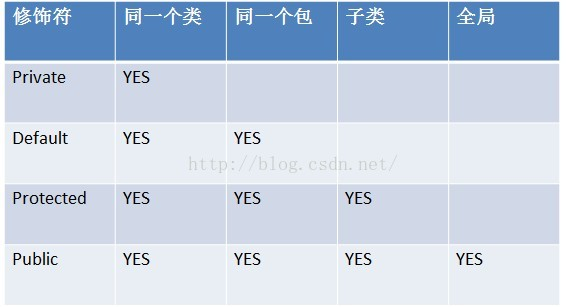
权限访问修饰符有public,protected,default,private,这四种级别的修饰符都可以用来 修饰类、方法和字段。
final修饰符
final的意思是不可变,他可以修饰类、字段、方法。
- 修饰类后类不能被扩展(extends),也就是不能被继承;
- 修饰字段后字段的值不能被改变,因此如果有final修饰字段,应该对字段进行手动初始化。
- 修饰方法后该方法不能被改变,也就是重写。
abstract修饰符
abstract是抽象的意思,用来修饰类和方法。
- 修饰类后,该类为抽象类,不能被实例化,必需进行扩展。
- 修饰方法后,该方法为抽象方法必须被子类重写(override)。
static修饰符
static用来修饰 内部类,方法,字段。
- 一般不能修饰类,但是可以修饰内部类。
- 被 修饰的内部类可以直接作为一个普通类来用,不需要创建一个外部类的实例;
- 而普通内部类的引用 需要创建一个外部类的实例。
- 修饰字段说明该字段属于类而不属于类实例。
- 修饰方法说明该方法属于类而不属于类实例。
public class StaticClassTest {
public static void main(String[] args) {
//静态内部类可以直接new
StaticInner si=new StaticInner();
//非静态内部类需创建一个父类的实例,方能new
StaticClassTest sct=new StaticClassTest();
Inner i=sct.new Inner();
}
class Inner{
}
static class StaticInner{
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2.3 静态变量、代码块、和静态方法的执行顺序
- 基本上代码块分为三种:static静态代码块、构造代码块、普通代码块
- 代码块执行顺序:静态代码块 ==》 构造代码块 ==》 构造函数 ==》 普通代码块
- 继承中代码块执行顺序:父类静态块 ==》 子类静态块 ==》 父类代码块 ==》 父类构造器 ==》 子类代码块 ==》 子类构造器
3 重载、重写、多态
3.1 Java中的多态
多态本质上多态分两种:
- 编译时多态(又称静态多态)
- 运行时多态(又称动态多态)
重载(overload)就是编译时多态的一个例子,编译时多态在编译时就已经确定,运行的时候调用的是确定的方法。
我们通常所说的多态指的都是运行时多态,也就是编译时不确定究竟调用哪个具体方法,一直延迟到运行时才能确定。这也是为什么有时候多态方法又被称为延迟方法的原因。
Java实现多态有 3 个必要条件:继承、重写和向上转型。
- 向上转型:在多态中需要 将子类的引用赋给父类对象 ,只有这样该引用才既能可以调用父类的方法,又能调用子类的方法。
3.2 构造器(constructor)是否可被重写(override)?
构造器不能被继承,因此不能被重写,但可以被重载。每一个类必须有自己的构造函数,负责构造自己这部分的构造。子类不会覆盖父类的构造函数,相反必须一开始调用父类的构造函数。
4 普通类、抽象类、接口
4.1 抽象类和接口的区别是什么?
抽象类
抽象类就是为了继承而存在的,如果你定义了一个抽象类,却不去继承它,那么等于白白创建了这个抽象类,因为你不能用它来做任何事情。
对于一个父类,如果它的某个方法在父类中实现出来没有任何意义,必须根据子类的实际需求来进行不同的实现,那么就可以将这个方法声明为abstract方法,此时这个类也就成为abstract类了。
包含抽象方法的类称为抽象类,但并不意味着抽象类中只能有抽象方法,它和普通类一样,同样可以拥有成员变量和普通的成员方法。
注意,抽象类和普通类的主要有三点区别:
- 抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public;
- 抽象类不能用来创建对象;
- 如果一个类继承于一个抽象类,则子类 必须实现 父类的抽象方法。如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。
在其他方面,抽象类和普通的类并没有区别。
接口
接口中可以含有 变量和方法,但是要注意:
- 接口中的 变量会被 隐式地指定为 public static final 变量(并且只能是public static final变量,用private修饰会报编译错误);
- 接口中的 方法 会被 隐式地指定为 public abstract 方法且只能是 public abstract 方法(用其他关键字,比如private、protected、static、 final等修饰会报编译错误),并且接口中所有的方法不能有具体的实现,也就是说,接口中的方法必须都是抽象方法。
从这里可以隐约看出接口和抽象类的区别,接口是一种极度抽象的类型,它比抽象类更加“抽象”,并且一般情况下不在接口中定义变量。
4.2 抽象类能使用 final 修饰吗?
不能,定义抽象类就是让其他类继承的,如果定义为 final 该类就不能被继承,这样彼此就会产生矛盾,所以 final 不能修饰抽象类
5 equals() 、== 、hashCode()
5.1 equals() 和 == 的区别?
== 常用于相同的基本数据类型之间的比较,也可用于相同类型的对象之间的比较
- 如果== 比较的是基本数据类型,那么比较的是两个基本数据类型的值是否相等;
- 如果== 是比较的两个对象,那么比较的是两个对象的引用,也就是判断两个对象是否指向了同一块内存区域;
equals方法主要用于两个对象之间,检测一个对象是否等于另一个对象
看一看Object类中equals方法的源码:
public boolean equals(Object obj) {
return (this == obj);
}
- 1
- 2
- 3
它的作用也是判断两个对象是否相等,般有两种使用情况:
- 情况1:类没有覆盖equals()方法。则通过equals()比较该类的两个对象时,等价于通过 == 比较这两个对象。
- 情况2:类覆盖了equals()方法。一般,我们都覆盖equals()方法来比较两个对象的内容是否相等,若它们的内容相等,则返回true(即,认为这两个对象相等)。
5.2 什么是hashCode?
hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode()函数。hashcode是一个native方法 。
/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
*/
- 1
- 2
- 3
- 4
- 5
hashCode() 的作用是获取 哈希码,也称为 散列码 ;它实际上是返回一个 int整数 。
- 这个哈希码的作用是确定该对象在哈希表中的索引位置。
- 散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
5.3 hashCode()方法的作用?为什么要有hashCode()方法?
以 HashMap如何检查重复 为例子来说明为什么要有 hashCode:
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
- 1
- 2
- HashMap中是如何判断两个Key是否相同?
- p.hash == hash :比较两个hash值是否相等。
- (k = p.key) == key :比较两个key的地址值是否相等。
- key != null && key.equals(k):能够执行到这里说明两个key的地址值不相等,那么先判断后添加的key是否等于null,如果不等于null再调用equals方法判断两个key的内容是否相等。
如果两个hash值不相等,则说明key不是重复的;如果hash相同,那么会进一步比较 == 或 equals() 。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
5.4 hashCode()、equals()两种方法是什么关系?
- 如果两个对象的hashcode()返回值一样,其equals()返回结果不一定一样。
- 如果两个对象的hashcode()返回值不一样,其equals()返回结果一定不一样。
- 如果两个对象的equals()返回值一样,其hashcode()返回结果一定一样。
- 如果两个对象的equals()返回值不一样,其hashcode()返回结果不一定不一样。
5.5 为什么重写 equals 方法必须重写 hashcode 方法?
- 判断的时候先根据hashcode进行的判断,相同的情况下再根据equals()方法进行判断。如果只重写了equals方法,而不重写hashcode的方法,会造成hashcode的值不同,而equals()方法判断出来的结果为true。
- 在Java中的一些容器中,不允许有两个完全相同的对象,插入的时候,如果判断相同则会进行覆盖。这时候如果只重写了equals()的方法,而不重写hashcode的方法,Object中hashcode是根据对象的存储地址转换而形成的一个哈希值。这时候就有可能因为没有重写hashcode方法,造成相同的对象散列到不同的位置而造成对象的不能覆盖的问题。
6 String、StringBuffer、StringBuilder
6.1 什么是不可变对象?好处是什么?
不可变对象 指对象一旦被创建,状态就不能再改变,任何修改都会创建一个新的对象 ,如 String、Integer及其它包装类.不可变对象最大的好处是线程安全。
6.2 介绍一下String、StringBuffer、StringBuilder
String、StringBuffer、StringBuilder
String类中使用字符数组保存字符串,因为有“final”修饰符,所以 string对象是不可变的。对于已经存在的String对象的修改都是重新创建一个新的对象,然后把新的值保存进去。
/** The value is used for character storage. */
private final char value[];
- 1
- 2
StringBuilder与StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串,这两种对象都是 可变的。
char[] value;
- 1
6.3 String、StringBuffer、StringBuilder是否线程安全?
- String中的对象是不可变的,也就可以理解为常量,显然线程安全。
- StringBuilder是非线程安全的。
- StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。
@Override public synchronized StringBuffer append(String str) { toStringCache = null; super.append(str); return this; }- 1
- 2
- 3
- 4
- 5
- 6
如果只是在单线程中使用字符串缓冲区,那么StringBuilder的效率会更高些。值得注意的是StringBuilder是在JDK1.5版本中增加的。以前版本的JDK不能使用该类。
6.4 String为什么要设计成不可变的?(重要 重要 重要)
便于实现字符串池(String pool)
- 在Java中,由于会大量的使用String常量,如果每一次声明一个String都创建一个String对象,那将 会造成极大的空间资源的浪费。
- Java提出了String pool的概念,在堆中开辟一块存储空间String pool,当初始化一个String变量时,如果该字符串已经存在了,就不会去创建一个新的字符串变量,而是会返回已经存在了的字符串的引用。
多线程安全
在并发场景下,多个线程同时读一个资源,是安全的,不会引发竞争,但对资源进行写操作时是不安全的,不可变对象不能被写,所以保证了多线程的安全。
避免安全问题
在网络连接和数据库连接中字符串常常作为参数,例如,网络连接地址URL,文件路径path,反射机制所需要的String参数。其不可变性可以保证连接的安全性。如果字符串是可变的,黑客就有可能改变字符串指向对象的值,那么会引起很严重的安全问题。
加快字符串处理速度
由于String是不可变的,保证了hashcode的唯一性,于是在创建对象时其hashcode就可以放心的缓存了,不需要重新计算。这也就是Map喜欢将String作为Key的原因,处理速度要快过其它的键对象。所以HashMap中的键往往都使用String。
总体来说,String不可变的原因要包括 设计考虑,效率优化,以及安全性 这三大方面。
6.5 什么是字符串常量池?它里面存的是引用还是对象?
参考:http://tangxman.github.io/2015/07/27/the-difference-of-java-string-pool/
java中常量池的概念主要有三个: 全局字符串常量池, class文件常量池, 运行时常量池。我们现在所说的就是全局字符串常量池。
JVM为了提升性能和减少内存开销,避免字符的重复创建,其维护了一块特殊的内存空间,即字符串池。当需要使用字符串时,先去字符串池中查看该字符串是否已经存在,如果存在,则可以直接使用,如果不存在,初始化,并将该字符串放入字符串常量池中。
字符串常量池的位置也是随着JDK版本的不同而位置不同。
- 在jdk1.6中,常量池的位置在永久代(方法区)中,此时常量池中存储的是 对象;
- 在jdk1.7中,常量池的位置在堆中,此时,常量池存储的就是 引用 了;
- 在jdk1.8中,永久代(方法区)被元空间取代了。
在jdk1.7及其以后,全局字符串池里的内容是在类加载完成,经过验证,准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中(记住:string pool中存的是引用值而不是具体的实例对象,具体的实例对象是在堆中开辟的一块空间存放的)。
在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个哈希表,里面存的是驻留字符串(也就是我们常说的用双引号括起来的)的引用(而不是驻留字符串实例本身),也就是说在堆中的某些字符串实例被这个StringTable引用之后就等同被赋予了”驻留字符串”的身份。这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。
6.6 String str="2"与 String str=new String(“2”)一样吗?new String(“aaa”);创建了几个字符串对象?TODO TODO
- String a = “aaa”;, 程序运行时会在字符串常量池中查找”aaa”字符串
- 若没有,会将”aaa”字符串放进常量池,再将其地址赋给a;
- 若有,将找到的”aaa”字符串的地址赋给a。
- 使用
String b = new String("aaa");,程序会在堆内存中开辟一片新空间存放新对象,同时会将”aaa”字符串放入常量池,相当于创建了两个对象,无论常量池中有没有”aaa”字符串,程序都会在堆内存中开辟一片新空间存放新对象。
@Test
public void test(){
// String a = "2";
// String b = "2";
// System.out.println(a == b); // 1.7 true
String a = new String("2");
String b = "2";
System.out.println(a == b); // 1.7 false
String s = new String("2");
s.intern();
String s2 = "2";
System.out.println(s == s2); // 1.6 false 1.7 false
String s3 = new String("3") + new String("3");
s3.intern();
String s4 = "33";
System.out.println(s3 == s4); // 1.6 false 1.7 true
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
运行结果:
jdk6
false
false
jdk7
false
true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
6.6.1 intern()函数说明
intern()函数 :intern函数的作用是将对应的符号常量进入特殊处理,在JDK1.6以前 和 JDK1.7以后有不同的处理:
- 在JDK1.6中,intern的处理是 先判断字符串常量是否在字符串常量池中
- 如果存在直接返回该常量;
- 如果没有找到,则将该字符串常量加入到字符串常量区,也就是在字符串常量区建立该常量。
- 在JDK1.7中,intern的处理是 先判断字符串常量是否在字符串常量池中
- 如果存在直接返回该常量;
- 如果没有找到,说明该字符串常量在堆中,则处理是把堆区该对象的引用加入到字符串常量池中,以后别人拿到的是该字符串常量的引用,实际存在堆中。
6.6.2 new String(“2”) == “2”分析 & new String(“2”)创建了几个对象?
String s = new String("2");
s.intern();
String s2 = "2";
System.out.println(s == s2); // 1.6 false 1.7 false
- 1
- 2
- 3
- 4
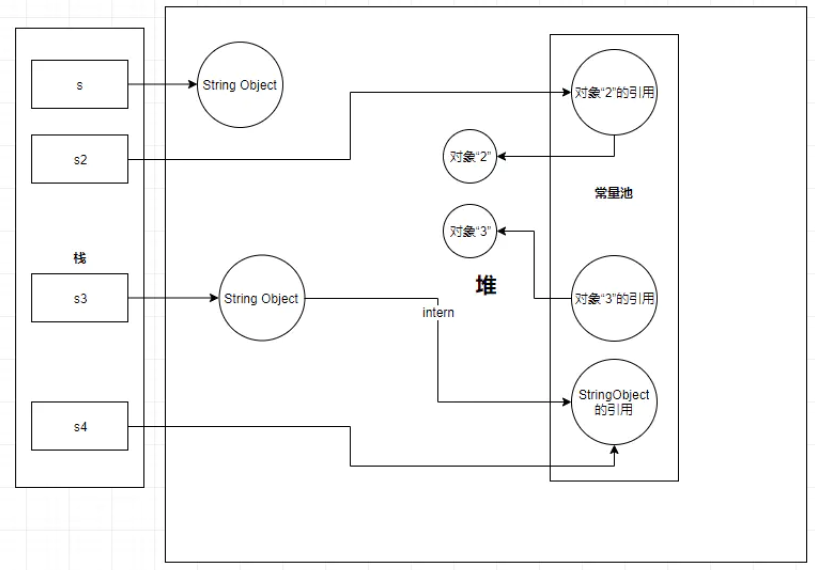
- String s = new String(“2”); 创建了两个对象:
- 一个在堆中的StringObject对象;
- 一个是在堆中的“2”对象,并在常量池中保存“2”对象的引用地址。
- s.intern();: 在常量池中寻找与s变量内容相同的对象,发现已经存在内容相同对象“2”,返回对象“2”的引用地址。
- String s2 = “2”;:使用字面量创建,在常量池寻找是否有相同内容的对象,发现有,返回对象“2”的引用地址。
- System.out.println(s == s2); 从上面可以分析出,s变量和s2变量地址指向的是不同的对象,所以返回false
6.6.3 “33” == new String(“3”) + new String(“3”) & new String(“3”) + new String(“3”)创建了几个对象
- String s3 = new String(“3”) + new String(“3”); 创建了两个对象:
- 一个在堆中的StringObject对象;
- 一个是在堆中的“3”对象,并在常量池中保存“3”对象的引用地址。中间还有2个匿名的newString(“3”)我们不去讨论它们。
- s3.intern(); 在常量池中寻找与s3变量内容相同的对象,没有发现“33”对象,将s3对应的StringObject对象的地址保存到常量池中,返回StringObject对象的地址。
- String s4 = “33”; 使用字面量创建,在常量池寻找是否有相同内容的对象,发现有,返回其地址,也就是StringObject对象的引用地址。
6.7 String 是最基本的数据类型吗?
不是。Java 中的基本数据类型只有 8 个 :byte、short、int、long、float、double、char、boolean;除了基本类型(primitive type),剩下的都是引用类型(referencetype),Java 5 以后引入的枚举类型也算是一种比较特殊的引用类型。
6.8 在使用 HashMap 的时候,用 String 做 key 有什么好处?
HashMap 内部实现是通过 key 的 hashcode 来确定 value 的存储位置,因为字符串是不可变的,所以当创建字符串时,它的 hashcode 被缓存下来,不需要再次计算,所以相比于其他对象更快。
7 自动装箱 & 自动拆箱
7.1 包装类型是什么?基本类型和包装类型有什么区别?
Java 为每一个基本数据类型都引入了对应的包装类型(wrapper class),int 的包装类就是 Integer。从 Java 5 开始引入了自动装箱/拆箱机制
- 把基本类型转换成包装类型的过程叫做装箱(boxing);
- 把包装类型转换成基本类型的过程叫做拆箱(unboxing)。
Java 为每个原始类型提供了包装类型:
- 原始类型: boolean,char,byte,short,int,long,float,double
- 包装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
基本类型和包装类型的区别主要有以下 几点:
- 包装类型可以为 null,而基本类型不可以;
- 包装类型可用于泛型,而基本类型不可以;
- 基本类型比包装类型更高效。输入基本类型在栈中直接存储的具体数值,而包装类型则存储的是堆中的引用。 很显然,相比较于基本类型而言,包装类型需要占用更多的内存空间。
7.2 解释一下自动装箱和自动拆箱?
自动装箱:将基本数据类型重新转化为对象
// 声明一个Integer对象,用到了自动的装箱:解析为:Integer num = Integer.valueOf(9);
Integer num = 9;
- 1
- 2
9是属于基本数据类型的,原则上它是不能直接赋值给一个对象Integer的。但jdk1.5 开始引入了自动装箱/拆箱机制,就可以进行这样的声明,自动将基本数据类型转化为对应的封装类型,成为一个对象以后就可以调用对象所声明的所有的方法。
自动拆箱:将对象重新转化为基本数据类型
/ /声明一个Integer对象
Integer num = 9;
// 进行计算时隐含的有自动拆箱
System.out.print(num--);
- 1
- 2
- 3
- 4
因为 对象时不能直接进行运算的,而是要转化为基本数据类型后才能进行加减乘除。
7.3 int 和 Integer 有什么区别?
- Integer是int的包装类;int是基本数据类型;
- Integer变量必须实例化后才能使用;int变量不需要;
- Integer实际是对象的引用,指向此new的Integer对象;int是直接存储数据值 ;
- Integer的默认值是null;int的默认值是0。
7.4 两个new生成的Integer变量的对比
由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
7.5 Integer变量和int变量的对比
Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)。
int a = 10000;
Integer b = new Integer(10000);
Integer c=10000;
System.out.println(a == b); // true
System.out.println(a == c); // true
- 1
- 2
- 3
- 4
- 5
7.6 非new生成的Integer变量和new Integer()生成变量的对比 (重要)
非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。
- 因为非new生成的Integer变量指向的是java常量池中的对象;
- 而new Integer()生成的变量指向堆中新建的对象。
两者在内存中的地址不同。
Integer b = new Integer(10000);
Integer c=10000;
System.out.println(b == c); // false
- 1
- 2
- 3
7.7 两个非new生成的Integer对象的对比 (重要)
对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false。
Integer i = 100;
Integer j = 100;
System.out.print(i == j); //true
Integer i = 128;
Integer j = 128;
System.out.print(i == j); //false
- 1
- 2
- 3
- 4
- 5
- 6
当值在 -128 ~ 127之间时,java会进行自动装箱,然后会对值进行缓存,如果下次再有相同的值,会直接在缓存中取出使用。缓存是通过Integer的内部类IntegerCache来完成的。当值超出此范围,会在堆中new出一个对象来存储。
/**
* (1)在-128~127之内:静态常量池中cache数组是static final类型,cache数组对象会被存储于静态常量池中。
* cache数组里面的元素却不是static final类型,而是cache[k] = new Integer(j++),
* 那么这些元素是存储于堆中,只是cache数组对象存储的是指向了堆中的Integer对象(引用地址)
* (2)在-128~127 之外:新建一个 Integer对象,并返回。
*/
public static Integer valueOf(int i) {
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high) {
return IntegerCache.cache[i + (-IntegerCache.low)];
}
return new Integer(i);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
8 反射相关内容
8.1 什么是反射?
反射是在运行状态中:
- 对于任意一个类,都能够知道这个类的所有属性和方法;
- 对于任意一个对象,都能够调用它的任意一个方法和属性;
这种动态获取的信息以及动态调用对象的方法的功能称为 Java 语言的反射机制。
8.2 Java反射API有几类?
- Class 类:反射的核心类,可以获取类的属性,方法等信息。
- Field 类:Java.lang.reflect 包中的类,表示类的成员变量,可以用来获取和设置类之中的属性值。
- Method 类:Java.lang.reflect 包中的类,表示类的方法,它可以用来获取类中的方法信息或者执行方法。
- Constructor 类:Java.lang.reflect 包中的类,表示类的构造方法。
8.3 如何获取反射中的Class对象?
-
Class.forName(“类的路径”);当你知道该类的全路径名时,你可以使用该方法获取 Class 类对象。
Class clz = Class.forName("java.lang.String");- 1
-
类名.class。这种方法只适合在编译前就知道操作的 Class。
Class clz = String.class;- 1
-
对象名.getClass()
String str = new String("Hello"); Class clz = str.getClass();- 1
- 2
-
如果是基本类型的包装类,可以调用包装类的Type属性来获得该包装类的Class对象。
8.4 反射创建一个对象的步骤
使用反射获取一个对象的步骤:
- 获取类的 Class 对象实例
Class clz = Class.forName("com.zhenai.api.Apple");- 1
- 根据 Class 对象实例获取 Constructor 对象
Constructor appleConstructor = clz.getConstructor();- 1
- 使用 Constructor 对象的 newInstance 方法获取反射类对象
Object appleObj = appleConstructor.newInstance();- 1
而如果要调用某一个方法,则需要经过下面的步骤:
- 获取方法的 Method 对象
Method setPriceMethod = clz.getMethod("setPrice", int.class);- 1
- 利用 invoke 方法调用方法
setPriceMethod.invoke(appleObj, 14);- 1
8.5 反射机制的原理是什么?
Class actionClass=Class.forName(“MyClass”);
Object action=actionClass.newInstance();
Method method = actionClass.getMethod(“myMethod”,null);
method.invoke(action,null);
- 1
- 2
- 3
- 4
- 1、反射获取类实例 Class.forName(),并没有将实现留给了java,而是交给了jvm去加载!主要是先获取 ClassLoader, 然后调用 native 方法,获取信息,加载类则是回调 java.lang.ClassLoader。最后,jvm又会回调 ClassLoader 进类加载!
- 2、newInstance() 主要做了三件事:
- 权限检测,如果不通过直接抛出异常;
- 查找无参构造器,并将其缓存起来;
- 调用具体方法的无参构造方法,生成实例并返回。
- 3、获取Method对象
- 上面的Class对象是在加载类时由JVM构造的,JVM为每个类管理一个独一无二的Class对象,
这份Class对象里维护着该类的所有Method,Field,Constructor的cache,这份cache也可以被称作根对象。 - 每次getMethod获取到的Method对象都持有对根对象的引用,因为一些重量级的Method的成员变量(主要是MethodAccessor),我们不希望每次创建Method对象都要重新初始化,于是所有代表同一个方法的Method对象都共享着根对象的MethodAccessor,每一次创建都会调用根对象的copy方法复制一份。
- 上面的Class对象是在加载类时由JVM构造的,JVM为每个类管理一个独一无二的Class对象,
- 4、调用invoke()方法。调用invoke方法的流程如下:
- 调用Method.invoke之后,会直接去调MethodAccessor.invoke。MethodAccessor就是上面提到的所有同名method共享的一个实例,由ReflectionFactory创建;
- 创建机制采用了一种名为inflation的方式(JDK1.4之后):如果该方法的累计调用次数<=15,会创建出NativeMethodAccessorImpl,它的实现就是直接调用native方法实现反射;如果该方法的累计调用次数>15,会由java代码创建出字节码组装而成的MethodAccessorImpl。(是否采用inflation和15这个数字都可以在jvm参数中调整)
9 泛型
参考:https://blog.csdn.net/qq_41701956/article/details/123473592
9.1 什么是泛型?
Java 泛型(generics)是 JDK 5 中引入的一个新特性,泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。
泛型的本质是参数化类型,即给类型指定一个参数,其在编译时才确定具体的参数。这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
9.2 为什么要使用泛型?
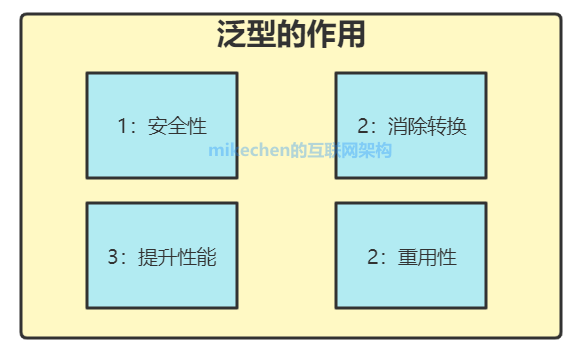
泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
9.3 如何使用泛型 TODO
泛型有三种使用方式,分别为:泛型类、泛型接口和泛型方法。
- 泛型类:把泛型定义在类上
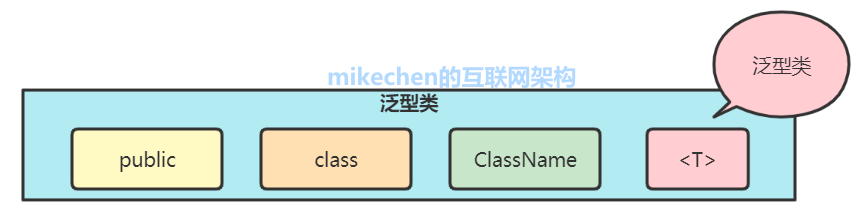
public class 类名 <泛型类型1,...> { }- 1
- 2
9.4 泛型通配符的使用 TODO
9.5 泛型的实现原理
泛型本质是将数据类型参数化,它通过擦除的方式来实现,即编译器会在编译期间「擦除」泛型语法并相应的做出一些类型转换动作。
10 java中的异常
10.1 Error 和 Exception 区别是什么?
Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类 Exception (异常)和 Error (错误)。
Exception 和 Error 二者都是 Java 异常处理的重要子类,各自都包含大量子类。
- Exception:程序本身可以处理的异常,可以通过 catch 来进行捕获,通常遇到这种错误,应对其进行处理,使应用程序可以继续正常运行。
- Exception 又可以分为:运行时异常(RuntimeException, 又叫非受检查异常)和非运行时异常(又叫受检查异常) 。
- Error:Error 属于程序无法处理的错误 ,我们没办法通过 catch 来进行捕获。
- 例如,系统崩溃,内存不足,堆栈溢出等,编译器不会对这类错误进行检测,一旦这类错误发生,通常应用程序会被终止,仅靠应用程序本身无法恢复。
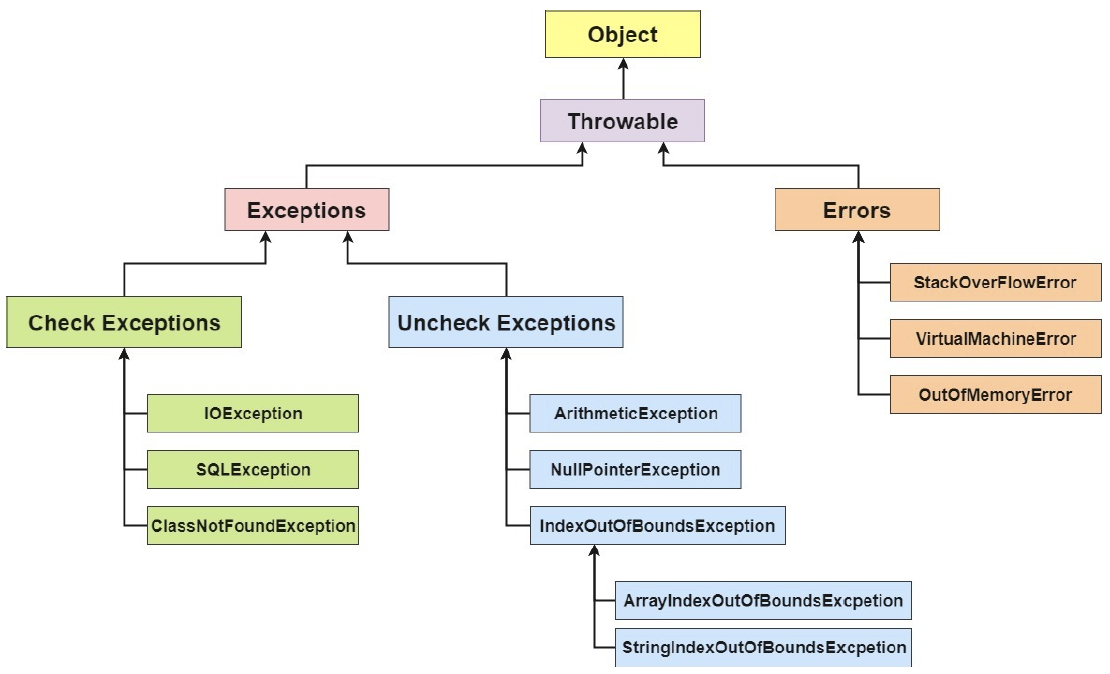
10.2 非受检查异常(运行时异常)和受检查异常(一般异常)区别是什么?
11 Java中的I/O模型: BIO、NIO、AIO
11.1 三种模型介绍
-
I/O 模型简单的理解:就是
用什么样的通道进行数据的发送和接收,很大程度上决定了程序通信的性能。 -
Java共支持3种网络编程模型/IO模式:
BIO、NIO、AIO。 -
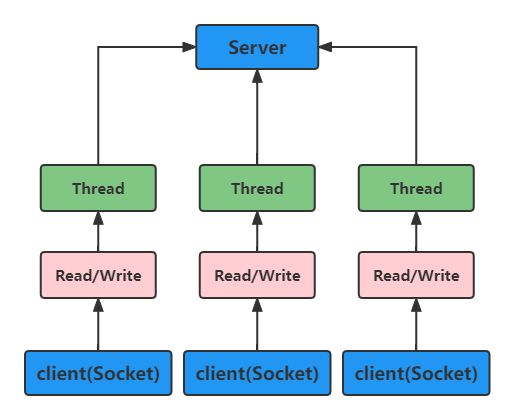
Java BIO:同步并阻塞(传统阻塞型),服务器实现模式为一个连接对应一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。
-
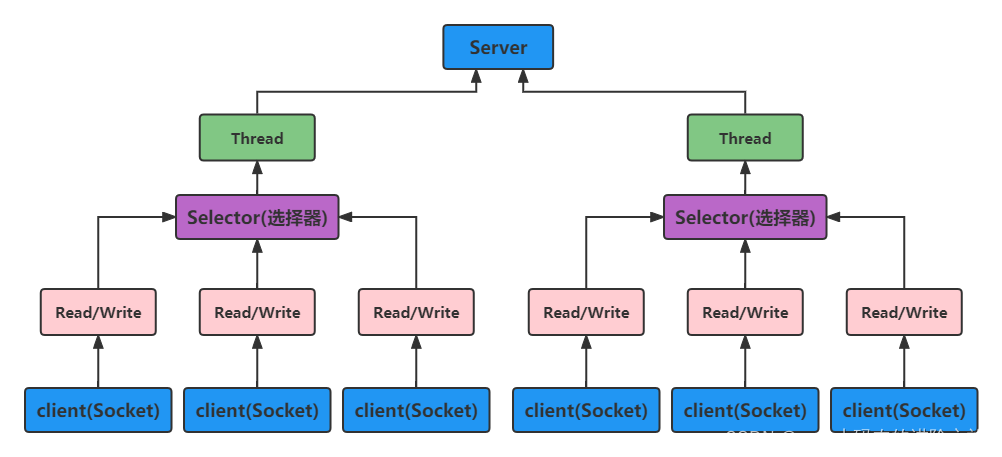
Java NIO:同步非阻塞,服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求就进行处理。
-
Java AIO(NIO.2):异步非阻塞,AIO 引入异步通道的概念,采用了Proactor 模式,简化了程序编写,有效的请求才启动线程,它的特点是:先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用。
11.3 BIO、NIO、AIO适用场景分析
BIO、NIO、AIO适用场景分析
- BIO方式适用于
连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序简单易理解。 - NIO方式适用于
连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,弹幕系统,服务器间通讯等。编程比较复杂,JDK1.4开始支持。 - AIO方式适用于
连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
11.2 NIO 与 BIO 比较
- BIO 以
流的方式处理数据,而 NIO 以块的方式处理数据,块 I/O 的效率比流 I/O 高很多; - BIO 是
阻塞的,NIO 则是非阻塞的 - BIO基于
字节流和字符流进行操作,而 NIO 基于Channel(通道)和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(选择器)用于监听多个通道的事件(比如:连接请求,数据到达等),因此使用单个线程就可以监听多个客户端通道
12 double、float精度丢失问题以及BigDecimal
12.1 说说double、float的精度丢失问题
System.out.println(4.0 - 3.6);
- 1
运行结果:0.3999999999999999
这种舍入误差的主要原因是浮点数值采用二进制系统表示,而在二进制系统中,无法精确的表示分数1/10,就像是十进制无法精确的标识1/3(0.333333…)一样。
计算过程解析
将十进制的 4.0 转换成 二进制,将十进制的 3.6 转换成二进制:
- 4.0转为二进制:100
- 3.6转二进制:11.100110011001…(一直循环除不尽)

3.6 转换成二进制,就类似于 1除以3一样,是除不尽。所以 System.out.println(4.0 - 3.6); 就会输出 0.3999999999999999
12.2 用BigDecimal类解决精度丢失的问题
BigDecimal 可以实现对浮点数的运算,不会造成精度丢失。通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 BigDecimal 来做的。
BigDecimal a = new BigDecimal("1.0");
BigDecimal b = new BigDecimal("0.9");
BigDecimal c = new BigDecimal("0.8");
BigDecimal x = a.subtract(b);
BigDecimal y = b.subtract(c);
System.out.println(x); /* 0.1 */
System.out.println(y); /* 0.1 */
System.out.println(Objects.equals(x, y)); /* true */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
14 懒汉式 & 饿汉式
14.1 懒汉式
懒汉式:双重锁检查机制
public class Singleton {
private static volatile Singleton singleton;
private Singleton() {}
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这里涉及到两个常见问题:
问题一:为什么要 double-check?去掉第二次的 check 行不行?
有两个线程同时调用 getInstance 方法,并且 singleton 是空的:
- 首先两个两个线程都可以通过第一个 if;
- 然后遇到了 synchronized 锁的保护;
- 假设线程 1 先抢到锁,并进入了第二个 if ,那么线程 1 就会创建新实例,然后退出synchronized 代码块;
- 接着才会轮到线程 2 进入 synchronized 代码块,并进入第二层 if,此时线程 2 会发现 singleton 已经不为 null,所以直接退出 synchronized 代码块,这样就保证了没有创建多个实例。
假设没有第二层 if,那么线程 2 也可能会创建一个新实例,这样就破坏了单例,所以第二层 if 肯定是需要的。
而对于第一个 check 而言,如果去掉它,那么所有线程都只能串行执行,效率低下,所以两个 check 都是需要保留。
问题二:为什么要加volatile?
这是因为 new 一个对象的过程,其实并不是原子的,至少包括以下这 3 个步骤:
- 步骤一:给 singleton 对象分配内存空间;
- 步骤二:调用 Singleton 的构造函数等,来进行初始化;
- 步骤三:把 singleton 对象指向在第一步中分配的内存空间,而在执行完这步之后,singleton 对象就不再是 null 了。
这里需要留意一下这 3 个步骤的顺序,因为指令重排,所以上面所说的三个步骤的顺序,并不是固定的。虽然看起来是 1-2-3 的顺序,但是在实际执行时,也可能发生 1-3-2 的情况,也就是说,先把 singleton 对象指向在第一步中分配的内存空间,再调用。
如果发生了 1-3-2 的情况,线程 1 首先执行新建实例的第一步,也就是分配单例对象的内存空间,然后线程 1 因为被重排序,所以去执行了新建实例的第三步,也就是把 singleton 指向之前的内存地址,在这之后对象不是 null,可是这时第 2 步并没有执行。假设这时线程 2 进入 getInstance 方法,由于这时 singleton 已经不是 null 了,所以会通过第一重检查并直接返回 singleton 对象并使用,但其实这时的 singleton 并没有完成初始化,所以使用这个实例的时候会报错。
最后,线程 1“姗姗来迟”,才开始执行新建实例的第二步——初始化对象,可是这时的初始化已经晚了,因为前面已经报错了。
使用volatile可以防止刚讲到的重排序的发生,也就避免了拿到没完成初始化的对象。
14.2 饿汉式
public class Singleton {
//定义一个私有的静态的 Singleton 变量,并进行初始化赋值(创建一个对象给变量赋值)
private static Singleton singleton = new Singleton();
//私有空参数构造方法,不让用户直接创建对象
private Singleton(){}
//定义一个公共的静态方法,返回 Singleton 对象
public static Singleton getInstance(){
return singleton;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
public class Singleton {
private static Singleton singleton;
static {
singleton = new Singleton();
}
private Singleton() {}
public static Singleton getInstance() {
return singleton;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
15 Java中的值传递和引用传递(重要)
15.1 值传递与引用传递的概念
程序设计语言中有关参数传递给方法(或函数)的两个专业术语:
- 按值调用(call by value)
- 按引用调用(call by reference)
按值调用表示方法接收的是调用着提供的值,而按引用调用则表示方法接收的是调用者提供的变量地址(如果是C语言的话来说就是指针啦,当然java并没有指针的概念)。
这里我们需要注意的是一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值,这句话相当重要,这是按值调用与引用调用的根本区别。
java中并不存在引用调用,这点是没错的,因为java程序设计语言确实是采用了按值调用,即call by value。也就是说方法得到的是所有参数值的一个拷贝,方法并不能修改传递给它的任何参数变量的内容。
详细参考:https://blog.csdn.net/vtopqx/article/details/107339897
15.2 值传递举例 - 基本数据类型
/**
* java中的按值调用
*/
public class CallByValue {
private static int x=10;
public static void updateValue(int value){
value = 3 * value;
}
public static void main(String[] args) {
System.out.println("调用前x的值:"+x);
updateValue(x);
System.out.println("调用后x的值:"+x);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行程序,结果如下:
调用前x的值:10
调用后x的值:10
- 1
- 2
可以看到x的值并没有变化,接下来我们一起来看一下具体的执行过程:
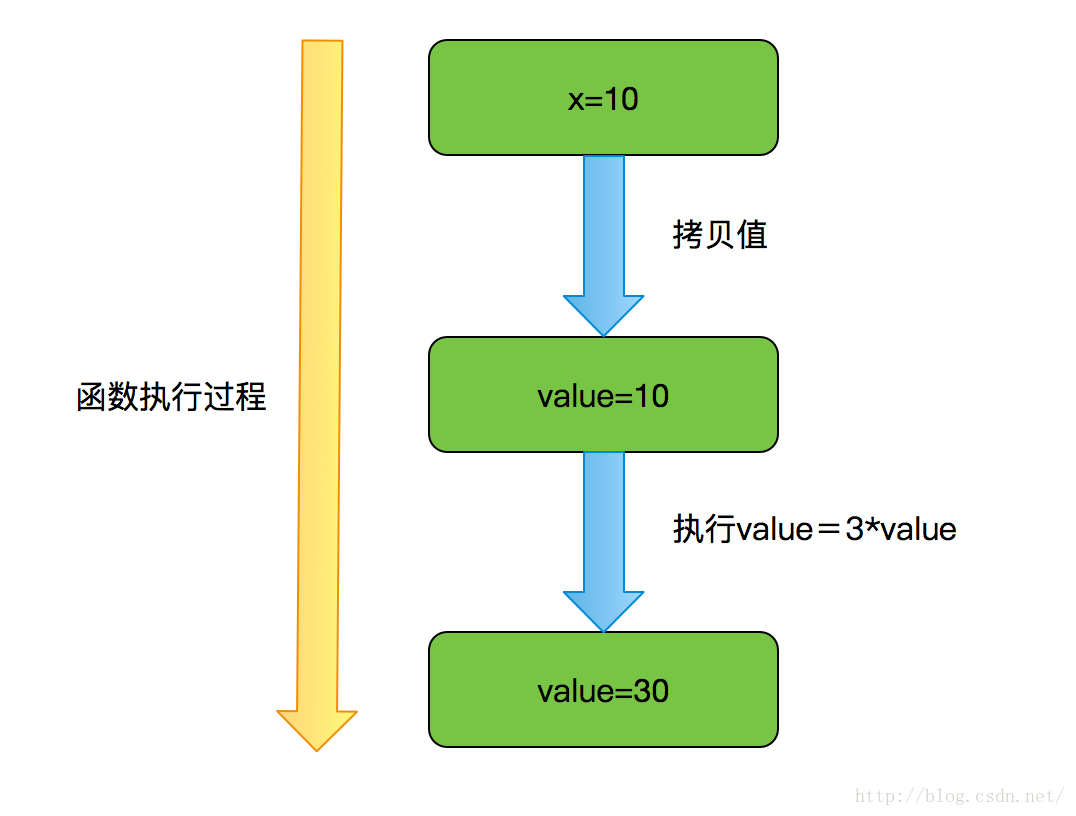
分析:
- value被初始化为x值的一个拷贝(也就是10);
- value被乘以3后等于30,但注意此时x的值仍为10;
- 这个方法结束后,参数变量value不再使用,被回收。
结论:当传递方法参数类型为基本数据类型(数字以及布尔值)时,一个方法是不可能修改一个基本数据类型的参数。
15.3 值传递举例 - 引用数据
声明一个User对象类型:
public class User {
private String name;
private int age;
public User(String name, int age) {
this.name=name;
this.age=age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
执行类如下:
/**
* java中的按值调用
*/
public class CallByValue {
private static User user=null;
public static void updateUser(User student){
student.setName("Lishen");
student.setAge(18);
}
public static void main(String[] args) {
user = new User("zhangsan",26);
System.out.println("调用前user的值:"+user.toString());
updateUser(user);
System.out.println("调用后user的值:"+user.toString());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行结果如下:
调用前user的值:User [name=zhangsan, age=26]
调用后user的值:User [name=Lishen, age=18]
- 1
- 2
很显然,User的值被改变了,也就是说方法参数类型如果是引用类型的话,引用类型对应的值将会被修改,下面我们来分析一下这个过程:
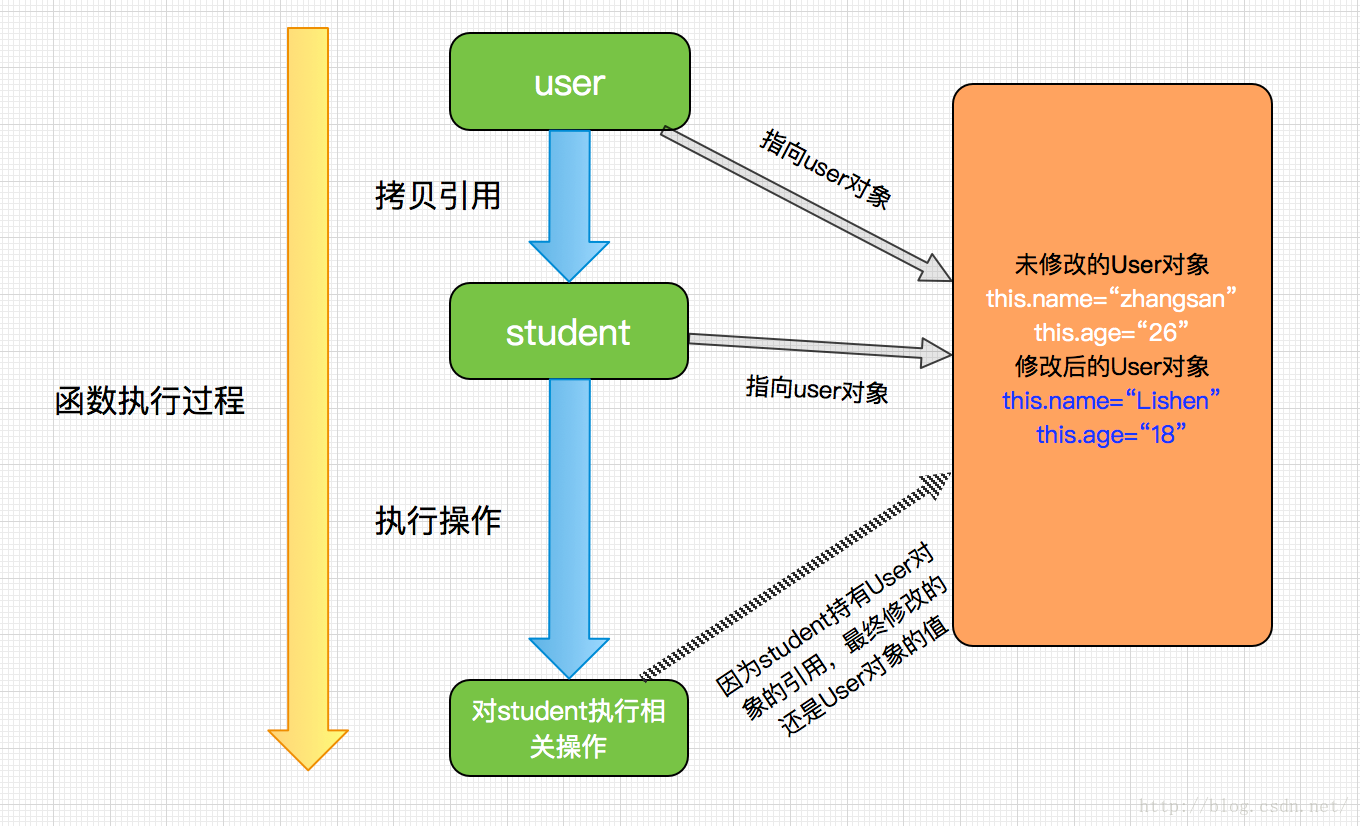
过程分析:
- student变量被初始化为user值的拷贝,这里是一个对象的引用;
- 调用student变量的set方法作用在这个引用对象上,user和student同时引用的User对象内部值被修改;
- 方法结束后,student变量不再使用,被释放,而user还是没有变,依然指向User对象。
结论:当传递方法参数类型为引用数据类型时,一个方法将修改一个引用数据类型的参数所指向对象的值。
虽然到这里两个数据类型的传递都分析完了,也明白的基本数据类型的传递和引用数据类型的传递区别,前者将不会修改原数据的值,而后者将会修改引用所指向对象的值。可通过上面的实例我们可能就会觉得java同时拥有按值调用和按引用调用啊,可惜的是这样的理解是有误导性的,虽然上面引用传递表面上体现了按引用调用现象,但是java中确实只有按值调用而没有按引用调用。到这里估计不少人都蒙逼了,下面我们通过一个反例来说明(回忆一下开头我们所说明的按值调用与按引用调用的根本区别)。
/**
* java中的按值调用
*/
public class CallByValue {
private static User user=null;
private static User stu=null;
/**
* 交换两个对象
* @param x
* @param y
*/
public static void swap(User x,User y){
User temp =x;
x=y;
y=temp;
}
public static void main(String[] args) {
user = new User("user",26);
stu = new User("stu",18);
System.out.println("调用前user的值:"+user.toString());
System.out.println("调用前stu的值:"+stu.toString());
swap(user,stu);
System.out.println("调用后user的值:"+user.toString());
System.out.println("调用后stu的值:"+stu.toString());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
我们通过一个swap函数来交换两个变量user和stu的值,在前面我们说过,如果是按引用调用那么一个方法可以修改传递引用所对应的变量值,也就是说如果java是按引用调用的话,那么swap方法将能够实现数据的交换,而实际运行结果是:
调用前user的值:User [name=user, age=26]
调用前stu的值:User [name=stu, age=18]
调用后user的值:User [name=user, age=26]
调用后stu的值:User [name=stu, age=18]
- 1
- 2
- 3
- 4
我们发现user和stu的值并没有发生变化,也就是方法并没有改变存储在变量user和stu中的对象引用。swap方法的参数x和y被初始化为两个对象引用的拷贝,这个方法交换的是这两个拷贝的值而已,最终,所做的事都是白费力气罢了。在方法结束后x,y将被丢弃,而原来的变量user和stu仍然引用这个方法调用之前所引用的对象。
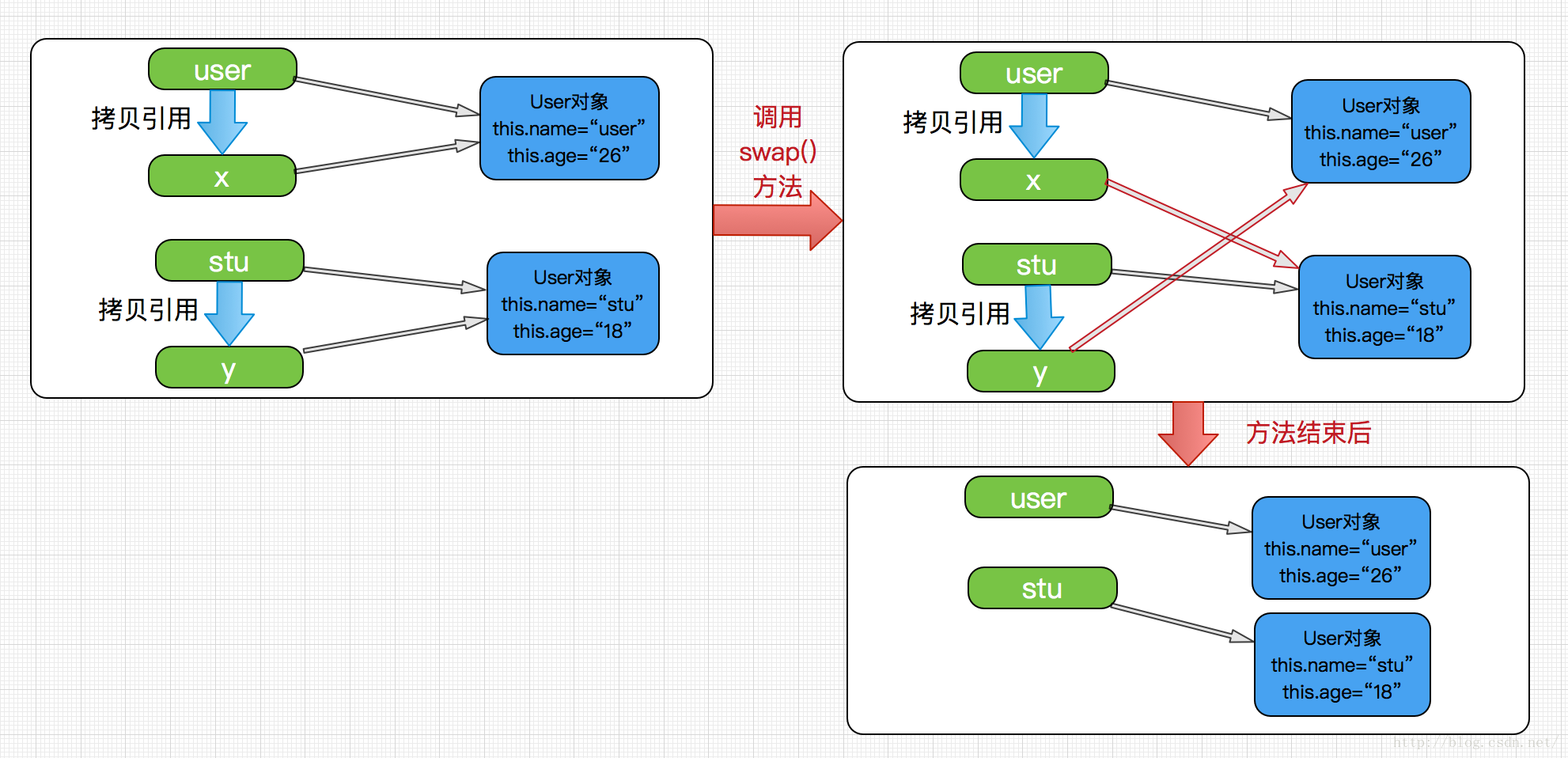
这个过程也充分说明了java程序设计语言对对象采用的不是引用调用,实际上是对象引用进行的是值传递,当然在这里我们可以简单理解为这就是按值调用和引用调用的区别,而且必须明白即使java函数在传递引用数据类型时,也只是拷贝了引用的值罢了,之所以能修改引用数据是因为它们同时指向了一个对象,但这仍然是按值调用而不是引用调用。
15.4 总结
- 一个方法不能修改一个基本数据类型的参数(数值型和布尔型)。
- 一个方法可以修改一个引用所指向的对象状态,但这仍然是按值调用而非引用调用。
- 上面两种传递都进行了值拷贝的过程。
16 Object类中的常用方法
hashcode、equals、wait、wait(long)、notify、notifyAll、finalize、getClass、toString、clone
16.1 notify()和notifyAll()的区别
notify() 和 notifyAll() 都是 Object 对象用于通知处在等待该对象的线程的方法。
- void notify(): 唤醒一个正在等待该对象的线程。
- void notifyAll(): 唤醒所有正在等待该对象的线程。
notify 可能会导致死锁,而 notifyAll 则不会
任何时候只有一个线程可以获得锁,也就是说只有一个线程可以运行 synchronized 中的代码使用 notifyall, 可以唤醒 所有处于 wait 状态的线程,使其重新进入锁的争夺队列中,而 notify 只能唤醒一个。
wait() 应配合 while 循环使用,不应使用 if ,务必在 wait() 调用前后都检查条件,如果不满足,必须调用notify() 唤醒另外的线程来处理,自己继续 wait() 直至条件满足再往下执行。
notify() 是对 notifyAll() 的一个优化,但它有很精确的应用场景,并且要求正确使用。不然可能导致死锁。正确的场景应该是 WaitSet 中等待的是相同的条件,唤醒任一个都能正确处理接下来的事项,如果唤醒的线程无法正确处理,务必确保继续 notify() 下一个线程,并且自身需要重新回到 WaitSet 中。
16.2 clone()、深拷贝、浅拷贝(重要 重要)
浅拷贝
- 浅拷贝是指我们拷贝出来的对象内部的引用类型变量和原来对象内部引用类型变量是同一引用(指向同一对象)。
- 但是我们拷贝出来的对象和新对象不是同一对象。
- 简单来说,新(拷贝产生)、旧(元对象)对象不同,但是内部如果有引用类型的变量,新、旧对象引用的都是同一引用。
深拷贝
- 深拷贝:全部拷贝原对象的内容,包括内存的引用类型也进行拷贝
clone()
-
Object类中的clone()方法是 protected 关键字修饰的本地方法(使用native关键字修饰),我们完成克隆需要重写该方法。
-
注意:按照惯例重写的时候一个要将protected修饰符修改为public,这是JDK所推荐的做法,但是我测试了一下,复写的时候不修改为public也是能够完成拷贝的。但是还是推荐写成public。
-
我们重写的clone方法一个要实现Cloneable接口。虽然这个接口并没有什么方法,但是必须实现该标志接口。如果不实现将会在运行期间抛出:CloneNotSupportedException异常
-
Object中本地clone()方法,默认是浅拷贝
clone()浅拷贝
package cn.cupcat.java8;
public class Person implements Cloneable{
private String name;
private int age;
private int[] ints;
public int[] getInts() {
return ints;
}
public Person(String name, int age, int[] ints) {
this.name = name;
this.age = age;
this.ints = ints;
}
public void setInts(int[] ints) {
this.ints = ints;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 默认实现
* */
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
public class CloneTest {
@Test
public void test() throws CloneNotSupportedException {
int[] ints = {1,2,3};
String name = "zhangxiangyang";
int age = 23;
Person person = new Person("zhangxiangyang",age,ints);
System.out.print("一:克隆前: age = "+ age + "... name = "+ name + " 数组:");
for (int i : ints){
System.out.print(i + " ");
}
System.out.println();
//拷贝
Person clonePerson = (Person) person.clone();
int clonePersonAge = clonePerson.getAge();
String clonePersonName = clonePerson.getName();
int[] ints1 = clonePerson.getInts();
System.out.print("二:克隆后: age = "+ clonePersonAge + "... name = "+ clonePersonName + " 数组: ");
for (int i : ints1){
System.out.print(i + " ");
}
System.out.println();
//修改:
ints1[0] = 50;
//修饰
clonePerson.setName("666666666");
age = person.getAge();
name = person.getName();
System.out.println();
System.out.print("三:修改后原对象: age = "+ age + "... name = "+ name + "数组 ");
for (int i : ints){
System.out.print(i + " ");
}
System.out.println();
System.out.println("四:person == clonePerson ? "+ (person == clonePerson ));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
一:克隆前: age = 23... name = zhangxiangyang 数组:1 2 3
二:克隆后: age = 23... name = zhangxiangyang 数组: 1 2 3
三:修改后原对象: age = 23... name = zhangxiangyang数组 50 2 3
四:person == clonePerson ? false
- 1
- 2
- 3
- 4
- 5
- 6
- 通过四输出 person == clonePerson ? false 可以看出,克隆以后的对象已经和以前不是同一对象了。因为其引用是不同的。
- 通过分析一、二可以看出我们的拷贝成功执行了,并且拷贝的数据也都正确
- 通过分析三,我们修改了拷贝后对象的name、ints, 发现原对象中的ints也跟着修改了,因此可以证明拷贝后的对象和原对象的ints数组指向了同一引用。
ints1[0] = 50; //修饰 clonePerson.setName("666666666");- 1
- 2
- 3
- 我们发现同时也修改了拷贝对象name属性,为什么那么原对象中的name属性没有发生改变呢?而且String类型也是引用类型呀? 这是因为有字符串常量池
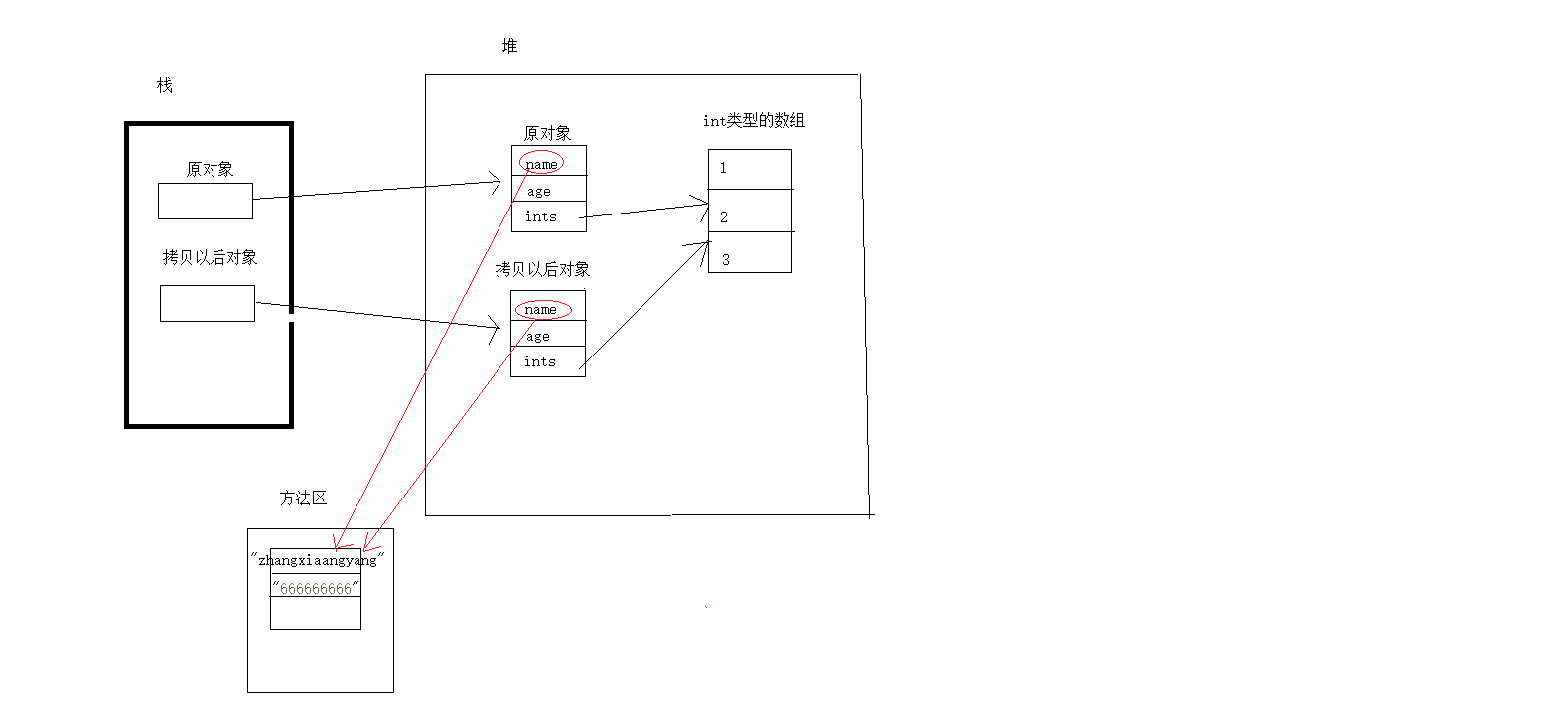
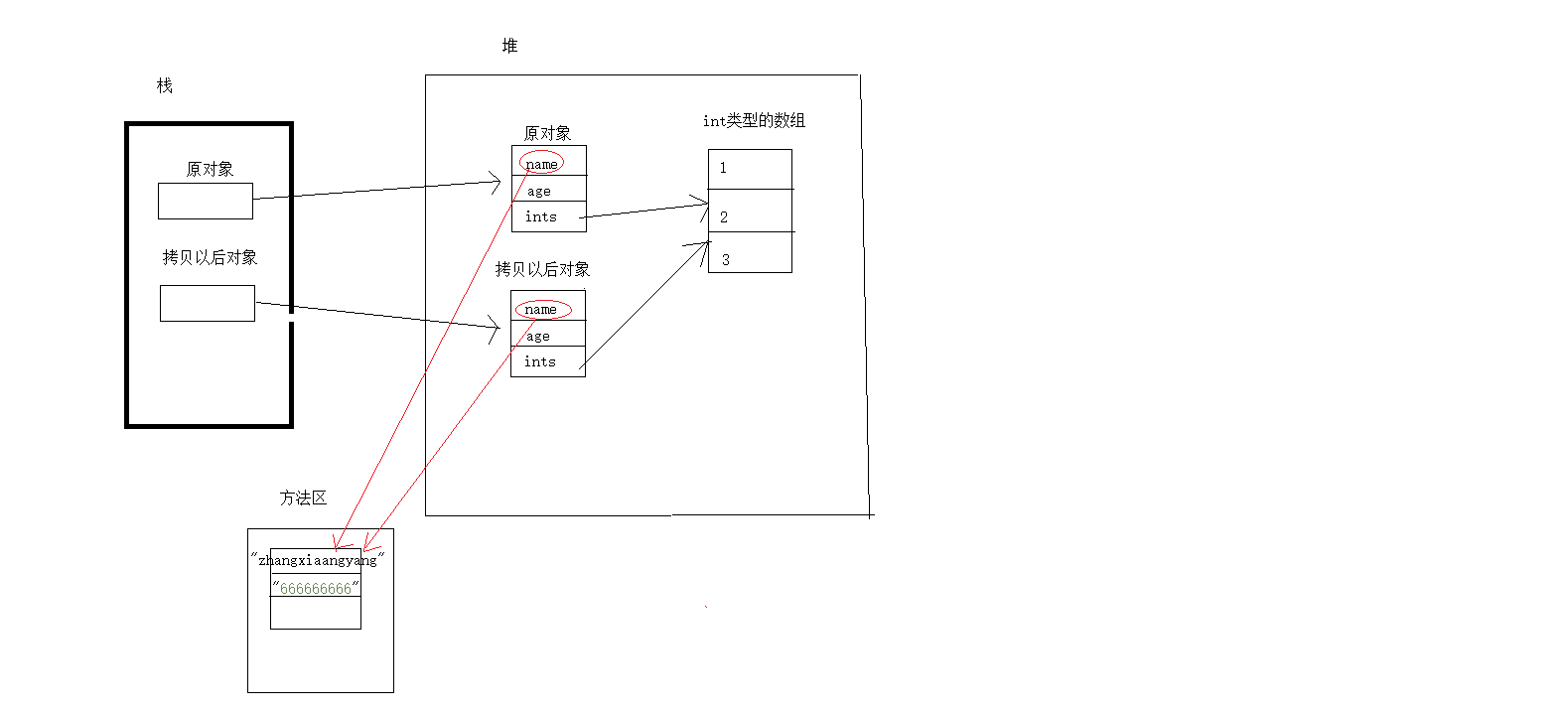
- 通过以上总结,我们得出结论:clone()方法的默认实现是浅拷贝
clone()深拷贝
/**
* 深拷贝
* */
@Override
public Object clone() throws CloneNotSupportedException {
Person person = new Person(name,age);
int[] ints = new int[this.ints.length];
System.arraycopy(this.ints,0,ints,0,ints.length);
person.setInts(ints);
return person;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
其他基础知识
main函数中的args参数有什么作用?
args的作用:在程序启动时可以用来指定外部参数
举例:打开idea中的项目配置编辑框
在环境临时配置一栏,设置运行时的服务端口为8989
-D:表示向运行类传参
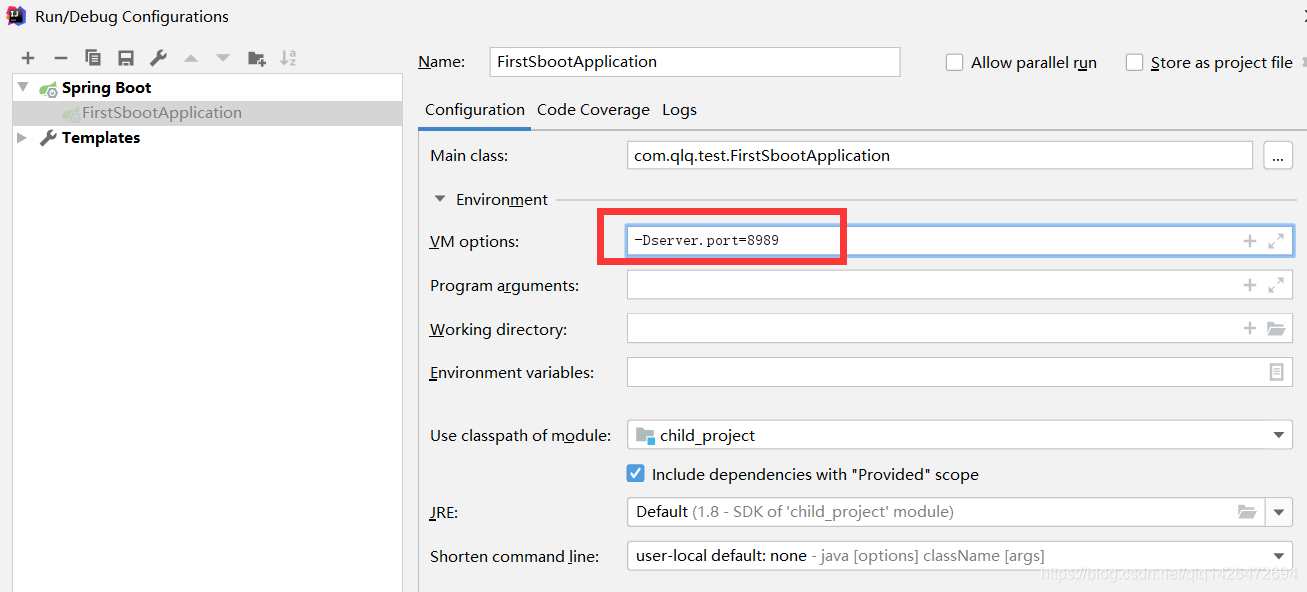
这样就能覆盖启动的程序中原本设置好的服务端口了。为什么能在程序启动过程中用临时传参覆盖掉原本代码中默认的配置,就是因为这个server.port=8989 能够通过args参数传给主函数
或者在jar包启动运行的时候,通过java -jar jar包名 [参数] 将这个参数传递给main函数的args
jdk1.8的新特性
- Lambda表达式
- Stream API
Arrays.sort()的底层
- 数量非常小的情况下(就像上面说到的,少于47的),插入排序等可能会比快速排序更快。 所以数组少于47的会进入插入排序。
- 快排数据
越无序越快(加入随机化后基本不会退化),平均常数最小,不需要额外空间,不稳定排序。 - 归排速度稳定,常数比快排略大,需要额外空间,稳定排序。
所以大于或等于47或少于286会进入快排,而在大于或等于286后,会有个小动作:“// Check if the array is nearly sorted”。这里第一个作用是先梳理一下数据方便后续的归并排序,第二个作用就是即便大于286,但在降序组太多的时候(被判断为没有结构的数据,The array is not highly structured,use Quicksort instead of merge sort.),要转回快速排序。
JDK动态代理实现织入
动态代理: 利用Java的反射技术(Java Reflection),在运行时创建一个实现某些给定接口的新类(也称“动态代理类”)及其实例(对象),代理的是接口(Interfaces),不是类(Class),也不是抽象类。在运行时才知道具体的实现,spring aop就是此原理。
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
- 1
- 2
- 3
newProxyInstance,方法有三个参数:
- loader: 用哪个类加载器去加载代理对象
- interfaces:动态代理类需要实现的接口
- h:动态代理方法在执行时,会调用h里面的invoke方法去执行
静态变量、实例变量、局部变量 是否线程安全
- 静态变量、实例变量 不是线程安全的
- 局部变量:栈帧,是线程安全的
hash冲突的解决方案
解决Hash冲突方法有:开放定址法、再哈希法、链地址法(拉链法)、建立公共溢出区。HashMap中采用的是 链地址法 。
开放定址法也称为再散列法,基本思想就是,如果p=H(key) 出现冲突时,则以p 为基础,再次hash, p1=H§ ,如果p1再次出现冲突,则以p1为基础,以此类推,直到找到一个不冲突的哈希地址pi 。 因此开放定址法所需要的hash表的长度要大于等于所需要存放的元素,而且因为存在再次hash,所以只能在删除的节点上做标记,而不能真正删除节点。再哈希法(双重散列,多重散列),提供多个不同的hash函数,当R1=H1(key1) 发生冲突时,再计算R2=H2(key1) ,直到没有冲突为止。 这样做虽然不易产生堆集,但增加了计算的时间。链地址法(拉链法),将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第i个单元中,查找、插入和删除主要在同义词链表中进行。链表法适用于经常进行插入和删除的情况。建立公共溢出区,将哈希表分为公共表和溢出表,当溢出发生时,将所有溢出数据统一放到溢出区。
线程间通信的方式 & 线程有几种状态 TODO
JDBC执行流程(7步)
- 引包:在执行JDBC前,首先我们要导入MySQL jar包
- 加载驱动
Class.forName(“com.mysql.jdbc.Driver”);- 1
- 建立连接
connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/test", "root", "root");- 1
- 创建语句
statement = connection.createStatement();- 1
- 执行语句
resultSet= statement.executeQuery(sql);- 1
- 对结果进行处理
rowMapper.rowMapper(resultSet);- 1
- 释放资源
finally { if (resultSet!=null) { try { resultSet.close(); } catch (SQLException e) { e.printStackTrace(); } } if (statement!=null) { try { statement.close(); } catch (SQLException e) { e.printStackTrace(); } } if (connection!=null) { try { connection.close(); } catch (SQLException e) { e.printStackTrace(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
快速查询
多个线程顺序打印、哲学家就餐问题:并发编程之模式篇
JDBC连接流程::JDBC获取数据库连接
Servlet工作流程:JavaWeb三大组件之Servlet详解
SSO的token实现方式:最近看了看使用Token令牌的方式实现SSO(单点登录)
参考:https://blog.csdn.net/qq_36389060/article/details/123893425
设计模式
参考:https://blog.csdn.net/lgxzzz/article/details/124970034
常见 数据结构 & 算法
1 常见排序算法
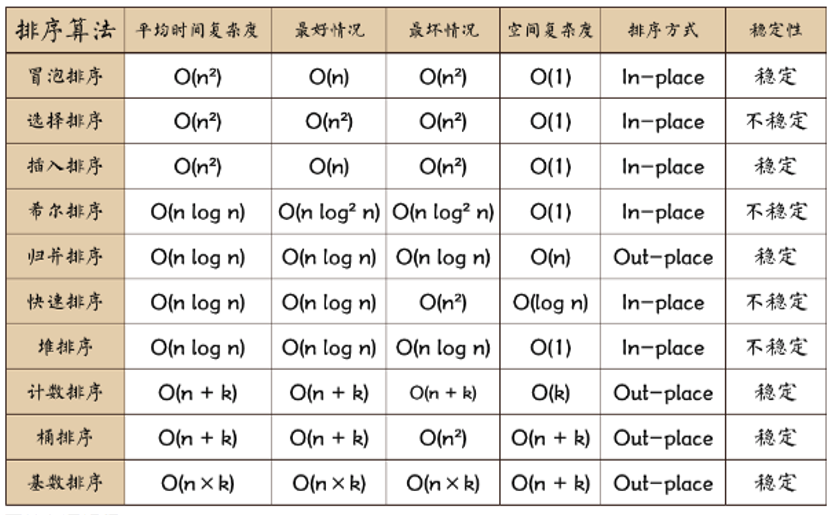
- 稳定:如果a原本在b前面,而 a = b,排序之后a任然在b的前面
- 不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;
- In-place: 不占用额外内存
- Out-place: 占用额外内存
1.1 冒泡排序
-
原理:比较两个相邻的元素,将值大的元素交换到右边
-
思路:依次比较相邻的两个数,将比较小的数放在前面,比较大的数放在后面。
- 第一次比较:首先比较第一和第二个数,将小数放在前面,将大数放在后面。
- 比较第2和第3个数,将小数 放在前面,大数放在后面。
- …
- 如此继续,知道比较到最后的两个数,将小数放在前面,大数放在后面,重复步骤,直至全部排序完成
- 在上面一趟比较完成后,
最后一个数一定是数组中最大的一个数,所以在比较第二趟的时候,最后一个数是不参加比较的。 - 在第二趟比较完成后,倒数第二个数也一定是数组中倒数第二大数,所以在第三趟的比较中,
最后两个数是不参与比较的。 - 依次类推,每一趟比较次数减少依次
-
最好情况:
有可能第二趟就是有序的了,如果一趟冒泡没发生交换就继续进行了 O(n)。
// 优化 O(n)
// 有可能第二趟就是有序的了,如果一趟冒泡没发生交换就继续进行了
public void Bubble2(int[] nums) {
boolean flag = false;
for (int i = 0; i < nums.length - 1; i++) {
for (int j = 0; j < nums.length - 1 - i; j++) {
if (nums[j] > nums[j+1]) {
flag = true;
int temp = nums[j];
nums[j] = nums[j+1];
nums[j+1] = temp;
}
}
if (flag == false) {
break;
} else {
flag = false;
System.out.println(Arrays.toString(nums));
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
1.2 插入排序
public void sort(int[] nums) {
for (int i = 1; i < nums.length; i++) {
for (int j = i; j > 0 ; j--) {
// 和前面数据比较,小于则插入
if (nums[j] < nums[j-1]) {
int temp = nums[j-1];
nums[j-1] = nums[j];
nums[j] = temp;
}
}
}
for (int num : nums) {
System.out.print(num+" ");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
1.3 选择排序
选择排序思路
- 第一趟从n个元素的数据序列中选出关键字最 小/大 的元素并放在最 前/后 位置;
- 下一趟从n-1个元素中选出最 小/大 的元素并放在最 前/后 位置。
- 以此类推,经过n-1趟完成排序。
// 选择排序
public void selectSort(int[] nums) {
for (int i = 0; i < nums.length - 1; i++) {
int minIndex = i;
int min = nums[i];
for (int j = i + 1; j < nums.length; j++) {
if (min > nums[j]) {
min = nums[j];
minIndex = j;
}
}
// 交换
if (minIndex != i) {
nums[minIndex] = nums[i];
nums[i] = min;
}
System.out.println(Arrays.toString(nums));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
1.4 快速排序
1.4.1 普通快排
快速排序步骤
- 选出一个key,一般是最左边或是最右边的;
- 定义一个begin和一个end,begin从左向右走,end从右向左走。(
需要注意的是:若选择最左边的数据作为key,则需要end先走;若选择最右边的数据作为key,则需要bengin先走); - 在走的过程中,若end遇到小于key的数,则停下,begin开始走,直到begin遇到一个大于key的数时,将begin和right的内容交换,end再次开始走,如此进行下去,直到begin和end最终相遇,此时将相遇点的内容与key交换即可。(
选取最左边的值作为key); 此时key的左边都是小于key的数,key的右边都是大于key的数;- 将key的左序列和右序列再次进行这种单趟排序,如此反复操作下去,直到左右序列只有一个数据,或是左右序列不存在时,便停止操作,此时此部分已有序
//快速排序 hoare版本(左右指针法)
void QuickSort(int* arr, int begin, int end)
{
//只有一个数或区间不存在
if (begin >= end)
return;
int left = begin;
int right = end;
//选左边为key
int keyi = begin;
while (begin < end)
{
//右边选小 等号防止和key值相等 防止顺序begin和end越界
while (arr[end] >= arr[keyi] && begin < end)
{
--end;
}
//左边选大
while (arr[begin] <= arr[keyi] && begin < end)
{
++begin;
}
//小的换到右边,大的换到左边
swap(&arr[begin], &arr[end]);
}
swap(&arr[keyi], &arr[end]);
keyi = end;
//[left,keyi-1]keyi[keyi+1,right]
QuickSort(arr, left, keyi - 1);
QuickSort(arr,keyi + 1,right);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
1.4.2 快排加入大量数据重复怎么优化?三相切割快速排序(三路快排)
《算法》一书提到了非常好的解决办法:三相切割快速排序。
- 原来是二路切割,也就是分为比pivot大,或者小于等于pivot的。这回
多了个等于pivot了。
// QuickSort
public class Fun{
public static int[] arr = {7,12,13,5,8,8,23,13,8};
public static void main(String[] args) {
int high = arr.length - 1, low = 0;
quickSort(low, high);
for(int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + ",");
}
}
public static void quickSort(int start, int end) {
if(start >= end)
return;
else {
int temp = arr[start];
int index = start + 1, low = start, high = end;
while(index <= high) {
if(temp > arr[index]) swap(low++,index++);
else if(temp < arr[index]) swap(high--,index);
else index++;
}
quickSort(start, low - 1);
quickSort(high + 1, end);
}
}
public static void swap(int t1, int t2){
int temp;
temp = arr[t1];
arr[t1]= arr[t2];
arr[t2] = temp;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
1.5 堆排序 (一颗顺序存储的完全二叉树)
参考:https://www.cnblogs.com/chengxiao/p/6129630.html
1.5.1 堆的概念
堆是一棵顺序存储的完全二叉树。
- 小根堆:每个结点的值都小于或等于其左右孩子结点的值。
- 大根堆:每个结点的值都大于或等于其左右孩子结点的值。
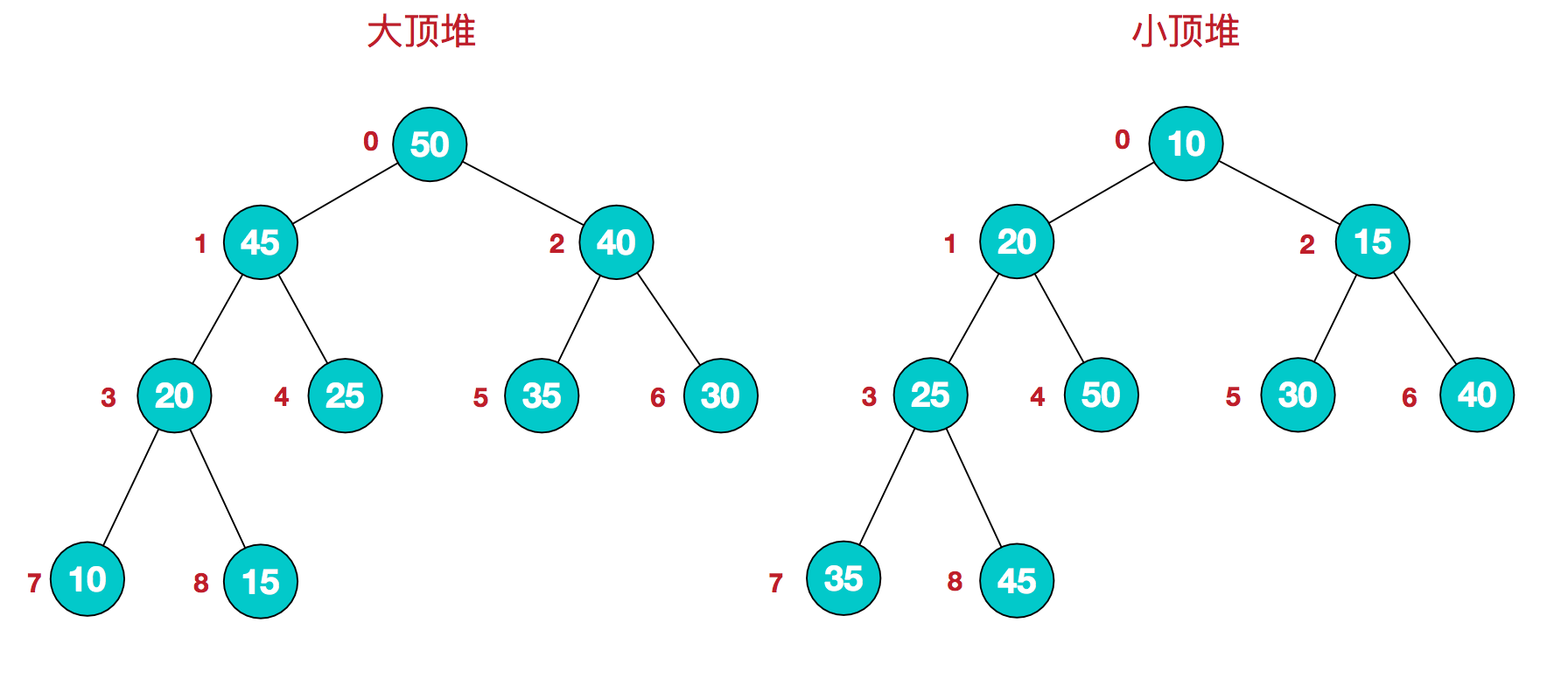
同时,我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子

该数组从逻辑上讲就是一个堆结构,我们用简单的公式来描述一下堆的定义就是: - 大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
- 小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
1.5.2 堆排序基本思想及步骤
堆排序的基本思想是:
- 将无需序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆(一般升序采用大顶堆,降序采用小顶堆);
- 将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
- 然后将剩余n-1个元素重新构造成一个堆,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
图解说明
假设给定无序序列结构如为{4,6,8,6,9}
步骤一 :首先将无序序列构造成大顶堆
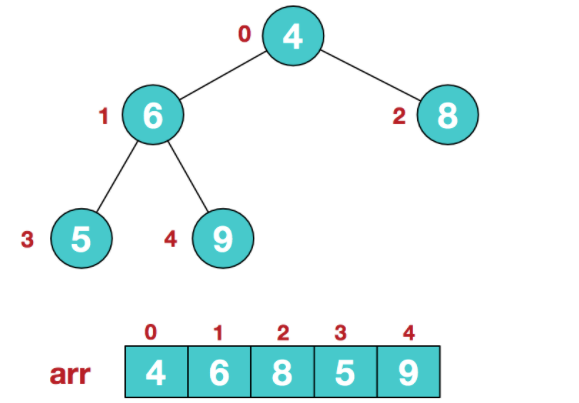
步骤二:构造初始堆 。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。
- 此时我们
从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。
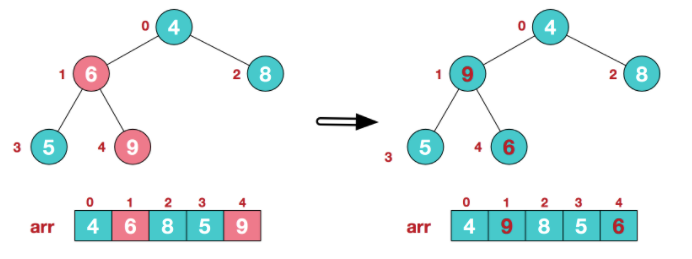
- 找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换。
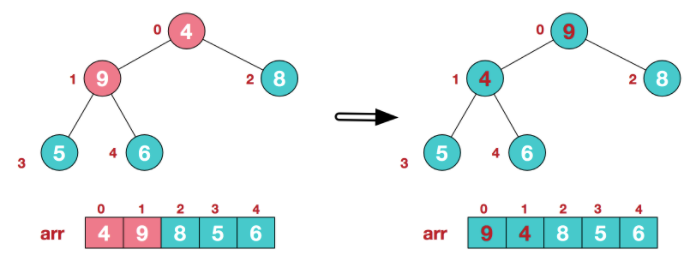
- 这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。此时,我们就将一个无需序列构造成了一个大顶堆。
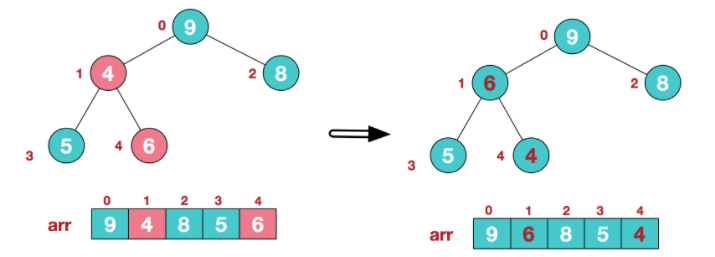
步骤三 :将 堆顶元素 与 末尾元素 进行 交换 ,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
- 将堆顶元素9和末尾元素4进行交换
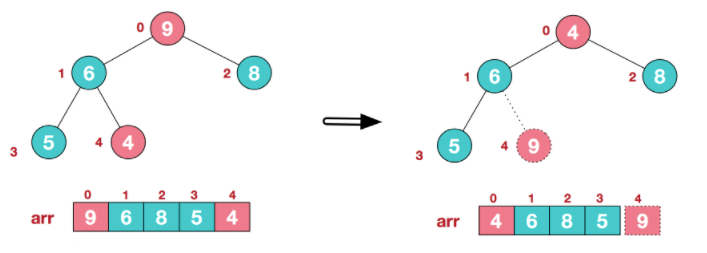
- 重新调整结构,使其继续满足堆定义
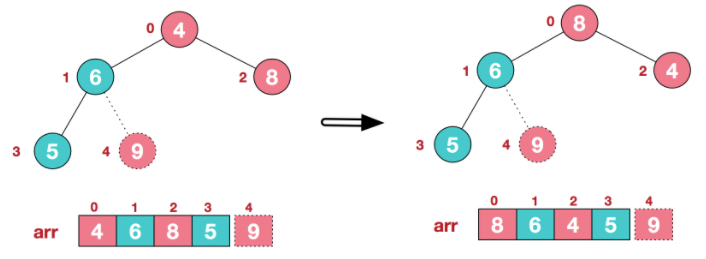
- 再将堆顶元素8与末尾元素5进行交换,得到第二大元素8。
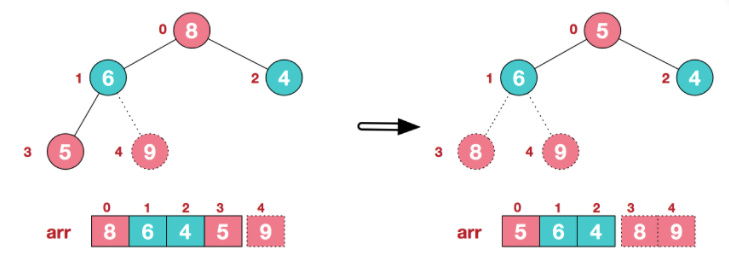
后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
1.5.3 代码实现
/**
* Created by chengxiao on 2016/12/17.
* 堆排序demo
*/
public class HeapSort {
public static void main(String []args){
int []arr = {9,8,7,6,5,4,3,2,1};
sort(arr);
System.out.println(Arrays.toString(arr));
}
public static void sort(int []arr){
//1.构建大顶堆
for(int i=arr.length/2-1;i>=0;i--){
//从第一个非叶子结点从下至上,从右至左调整结构
adjustHeap(arr,i,arr.length);
}
//2.调整堆结构+交换堆顶元素与末尾元素
for(int j=arr.length-1;j>0;j--){
swap(arr,0,j);//将堆顶元素与末尾元素进行交换
adjustHeap(arr,0,j);//重新对堆进行调整
}
}
/**
* 调整大顶堆(仅是调整过程,建立在大顶堆已构建的基础上)
* @param arr
* @param i
* @param length
*/
public static void adjustHeap(int []arr,int i,int length){
int temp = arr[i];//先取出当前元素i
for(int k=i*2+1;k<length;k=k*2+1){//从i结点的左子结点开始,也就是2i+1处开始
if(k+1<length && arr[k]<arr[k+1]){//如果左子结点小于右子结点,k指向右子结点
k++;
}
if(arr[k] >temp){//如果子节点大于父节点,将子节点值赋给父节点(不用进行交换)
arr[i] = arr[k];
i = k;
}else{
break;
}
}
arr[i] = temp;//将temp值放到最终的位置
}
/**
* 交换元素
* @param arr
* @param a
* @param b
*/
public static void swap(int []arr,int a ,int b){
int temp=arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
2 各种树
2.1 二叉树
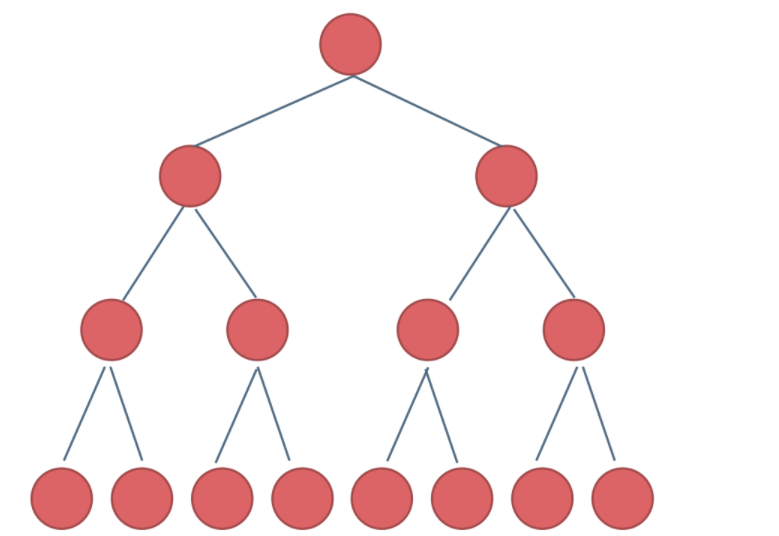
2.1.1 满二叉树
满二叉树:如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。
如图所示:
这棵二叉树为满二叉树,也可以说深度为k,有2^k-1个节点的二叉树。
2.1.2 完全二叉树
完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2^(h-1) 个节点。
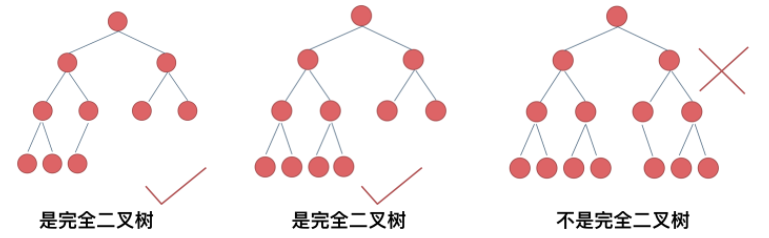
优先级队列其实是一个堆,堆就是一棵完全二叉树,同时保证父子节点的顺序关系。
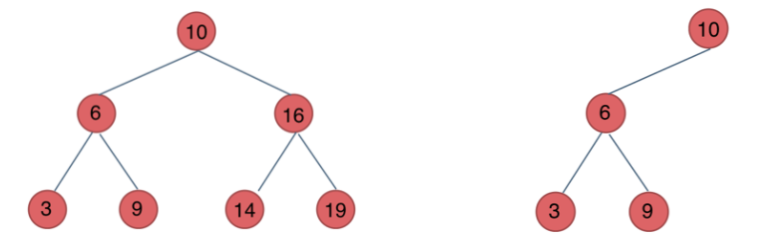
2.1.3 二叉搜索树
前面介绍的树,都没有数值的,而二叉搜索树是有数值的了,二叉搜索树是一个有序树。
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树
2.1.4 平衡二叉搜索树
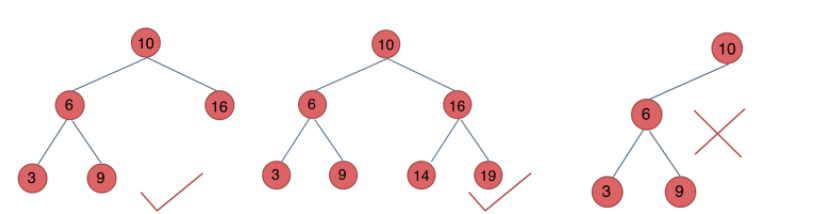
平衡二叉搜索树:又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:在符合二叉查找树的条件下,它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
2.2 B树 和 B+树
2.2.1 BTree
BTree的特点
BTree又叫 多路平衡搜索树 ,一颗m叉的BTree特性如下:
- 树中每个节点最多包含m个孩子。
- 除根节点与叶子节点外,每个节点至少有[ceil(m/2)]个孩子。
ceil为向上取整 - 若根节点不是叶子节点,则至少有两个孩子。
- 所有的叶子节点都在同一层。
- 每个非叶子节点由n个key与n+1个指针组成,其中[ceil(m/2)-1] <= n <= m-1
BTree作用
B-Tree是为磁盘等外存储设备设计的一种平衡查找树。因此在讲B-Tree之前先了解下磁盘的相关知识。
系统从磁盘读取数据到内存时是以 磁盘块(block) 为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。
InnoDB存储引擎中有 页(Page)的概念, 页是其磁盘管理的最小单位 。InnoDB存储引擎中 默认每个页的大小为16KB,可通过参数innodb_page_size将页的大小设置为4K、8K、16K,在MySQL中可通过如下命令查看页的大小:
mysql> show variables like 'innodb_page_size'
- 1
而系统一个磁盘块的存储空间往往没有这么大,因此InnoDB每次申请磁盘空间时都会是若干地址连续磁盘块来达到页的大小16KB。InnoDB在把磁盘数据读入到磁盘时会以页为基本单位,在查询数据时如果一个页中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘I/O次数,提高查询效率。
BTree查询数据的过程
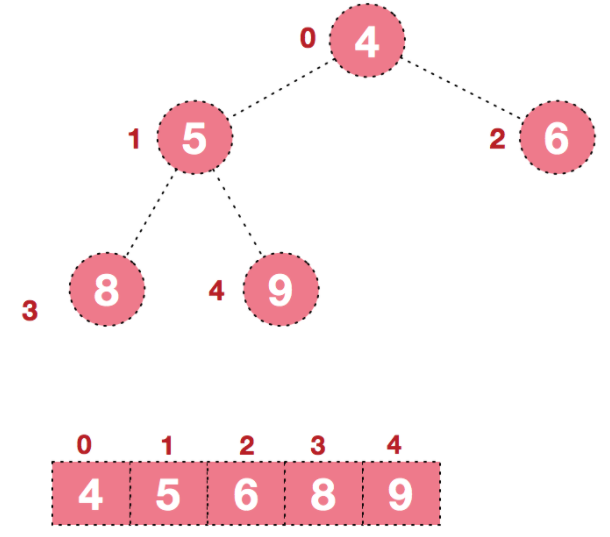
B-Tree结构的数据可以让系统高效的找到数据所在的磁盘块。为了描述B-Tree,首先定义一条记录为一个二元组[key, data] ,key为记录的键值,对应表中的主键值,data为一行记录中除主键外的数据。对于不同的记录,key值互不相同。B-Tree中的每个节点根据实际情况可以包含大量的关键字信息和分支,如下图所示为一个 3阶的B-Tree :
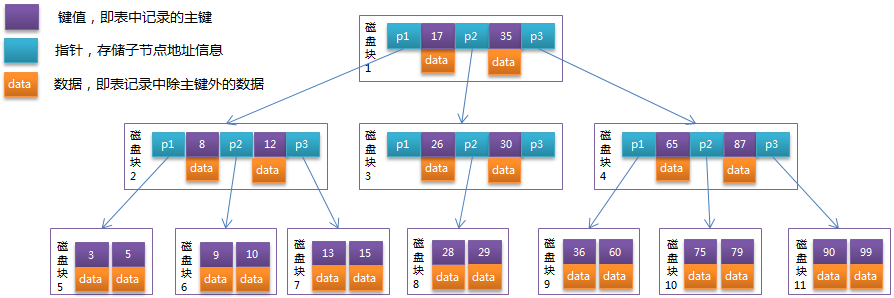
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个关键词划分成的三个范围域 对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
模拟查找关键字29的过程:
- 根据根节点找到磁盘块1,
读入内存。【磁盘I/O操作第1次】 - 比较关键字29在区间(17,35),找到磁盘块1的指针P2。
- 根据P2指针找到磁盘块3,
读入内存。【磁盘I/O操作第2次】 - 比较关键字29在区间(26,30),找到磁盘块3的指针P2。
- 根据P2指针找到磁盘块8,
读入内存。【磁盘I/O操作第3次】 在磁盘块8中的关键字列表中找到关键字29。
分析上面过程,发现 需要3次磁盘I/O操作,和3次内存查找操作 。由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。而 3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。B-Tree相对于AVLTree缩减了节点个数,使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。
2.2.2 B+Tree
B+Tree的特点
- n叉B+Tree最多含有n个key,而BTree最多含有n-1个key。
B+Tree的叶子节点保存所有的key信息,依key大小顺序排列。所有的非叶子节点都可以看作是key的索引部分。
MySQL中B+Tree相对于BTree的特点
- 非叶子节点只存储键值信息。
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
由于B+Tree只有叶子节点保存key信息,查询任何key都要从root走到叶子。所以B+Tree的查询效率更加稳定。
B+Tree的查询流程
将上一节中的B-Tree优化,由于B+Tree的非叶子节点只存储键值信息,假设每个磁盘块能存储4个键值及指针信息,则变成B+Tree后其结构如下图所示:
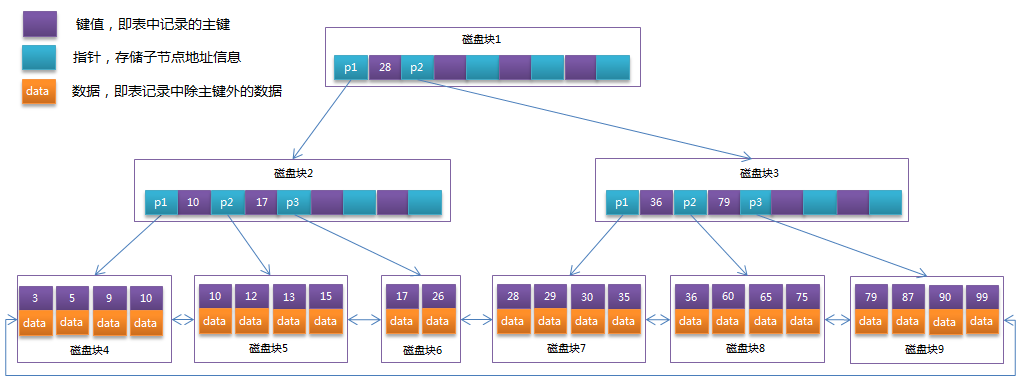
通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点 (啥意思????????),而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:
- 一种是对于主键的范围查找和分页查找;
- 另一种是从根节点开始,进行随机查找。
可能上面例子中只有22条数据记录,看不出B+Tree的优点,下面做一个推算:InnoDB存储引擎中页的大小为16KB
- B+Tree:一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(
因为是估值,为方便计算,这里的K取值为 10 ^ 3)。也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿条记录(啥意思,为啥是相乘????????)。 - BTree:假设指针不占用空间,一条数据1KB,每个磁盘块16条数据,三层B树能存储16 * 16 * 16=4096条数据,
一个磁盘块代表一次IO,很明显数据量多的情况下,IO次数也会多,会影响查询性能,于是在B树的基础上衍生出了B+树。
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2~4层。mysql的InnoDB存储引擎在设计时 是将根节点常驻内存的,也就是说查找某一键值的行记录时 最多只需要1 - 3次磁盘I/O操作 。
2.2.3 为什么要用B+Tree而不用BTree?
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
- 从上一节中的B-Tree结构图中可以看到
每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的:- 如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,
- 当存储的数据量很大时同样会导致B-Tree的
深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。
- 在B+Tree中,
所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
2.2.4 非聚集索引查询数据的过程?
- 数据库中的B+Tree索引可以分为聚集索引(clustered index)和辅助索引(secondary index)。上面的B+Tree示例图在数据库中的实现即为聚集索引,聚集索引的B+Tree中的叶子节点存放的是整张表的行记录数据。
- 辅助索引与聚集索引的区别在于辅助索引的叶子节点并不包含行记录的全部数据,而是存储相应行数据的聚集索引键,即主键。当通过辅助索引来查询数据时,InnoDB存储引擎会遍历辅助索引找到主键,然后再通过主键在聚集索引中找到完整的行记录数据。
- 非聚集索引也是B+Tree
2.3 红黑树、AVL树 TODO
参考 敖丙CSDN:https://blog.csdn.net/qq_35190492/article/details/109503539
红黑树也是对树结构的一种高度综合运用,涉及到多叉树,树平衡调整,节点旋转等等。
红黑树为什么要固定黑节点?
3 其他常见算法
3.1 LRU & LFU 重要 重要
参考:https://blog.csdn.net/qq_36389060/article/details/123893425
3.2 二分法
时间复杂度:O(logn)
/**
* 704. 二分查找 TODO 存在多种写法
* 二分查找条件:数组有序 + 数组无重复元素
*/
public int search(int[] nums, int target) {
int left = 0;
int right = nums.length - 1;
while (left <= right) {
// 防止数值过大相加超过边界
int mid = left + (right - left) / 2;
if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] == target) {
return mid;
}
}
return -1;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
项目问题总结
1 在线教育
1.1 微信登录流程
1.2 单点登录
参考:https://blog.csdn.net/qq_36389060/article/details/124097552
解决问题
- Cookie跨域的问题:多个域名共享Cookie,在写到客户端的时候设置Cookie的domain;
- Session不共享问题:把Session数据放在Redis中(使用Redis模拟Session)。
我们把Session数据放在Redis中(使用Redis模拟Session)实现Session共享,并通过设置domain解决cookie跨域问题 。并且将 将登录功能单独抽取出来做成一个子系统,这里我们称为SSO系统:
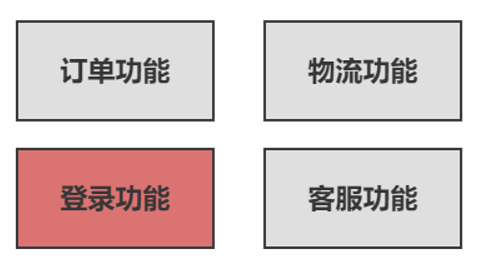
SSO系统(登录系统)中的用户登录逻辑如下:
- 根据 用户名 和 密码 去数据库进行查询;
- 首先分局用户名查询,如果未查询到则说明用户不存在;
- 如果用户存在,则进行密码核对,如果密码正确则登录成功。
- 判断登录成功之后,生成一个Token,然后将这个token存入redis,并设置过期时间(这里Token其实就是一个UUID)。
// 登录功能(SSO单独的服务)
@Override
public TaotaoResult login(String username, String password) throws Exception {
// 1.根据用户名查询用户信息
TbUserExample example = new TbUserExample();
Criteria criteria = example.createCriteria();
criteria.andUsernameEqualTo(username);
List<TbUser> list = userMapper.selectByExample(example);
if (null == list || list.isEmpty()) {
return TaotaoResult.build(400, "用户不存在");
}
// 2.根据查询到的用户进行核对密码
TbUser user = list.get(0);
if (!DigestUtils.md5DigestAsHex(password.getBytes()).equals(user.getPassword())) {
return TaotaoResult.build(400, "密码错误");
}
// 3.密码核对成功则登录成功
// 4.生成一个用户token,并存入redis
String token = UUID.randomUUID().toString();
jedisCluster.set(USER_TOKEN_KEY + ":" + token, JsonUtils.objectToJson(user));
// 5.设置用户token的过期时间
jedisCluster.expire(USER_TOKEN_KEY + ":" + token, SESSION_EXPIRE_TIME);
return TaotaoResult.ok(token);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
用户登录其他子系统时,其它子系统会请求 SSO(登录系统)中的登录方法进行登录流程(就是上面的逻辑),将返回的token写到Cookie中,下次访问时HTTP请求会自动把Cookie带上。
public TaotaoResult login(String username, String password,
HttpServletRequest request, HttpServletResponse response) {
//请求参数
Map<String, String> param = new HashMap<>();
param.put("username", username);
param.put("password", password);
//登录处理
String stringResult = HttpClientUtil.doPost(REGISTER_USER_URL + USER_LOGIN_URL, param);
TaotaoResult result = TaotaoResult.format(stringResult);
//登录出错
if (result.getStatus() != 200) {
return result;
}
//登录成功后把取token信息,并写入cookie
String token = (String) result.getData();
//写入cookie
CookieUtils.setCookie(request, response, "TT_TOKEN", token);
//返回成功
return result;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
之后用户每次发起HTTP请求时,都会自动将Cookie都会带上,后端可以通过拦截器得到token,进而判断该用户是否已经登录。
单点登录(SSO)流程总结
- SSO系统生成一个token,并将用户信息存到Redis中,并设置过期时间;
- 其他系统请求SSO系统进行登录,得到SSO返回的token,写到Cookie中;
- 每次请求时,Cookie都会带上,拦截器得到token,判断是否已经登录 。
到这里,其实我们会发现其实就两个变化:
- 将登陆功能抽取为一个系统(SSO),其他系统请求SSO进行登录;
本来将用户信息存到Session,现在将用户信息存到Redis。
到这里,我们已经可以实现单点登录了。
1.3 后台权限管理的实现流程
数据库中的表
至少需要五张表才能完成权限管理:权限表、角色表、用户表、权限角色表、角色用户表。
实现流程
- 步骤一:根据用户名密码查询用户权限列表
- 步骤二:认证成功后
- 1)根据用户名生成token
- 2)将用户名和权限列表放入redis
- 3)返回生成的token到前端
- 步骤三:前端将后端传回的token放入cookie
- 步骤四:前端从cookie中获取token放入header中,后端springsecurity从token中获取用户名,从redis中获取到权限列表
- 步骤五:最后由springsecurity给用户赋予权限,可以进行相应的操作
1.4 接口间权限管理(思考如何实现)TODO
参考:https://blog.csdn.net/qq_49721447/article/details/122620425
1.5 跨域问题
参考一:https://blog.csdn.net/zzti_erlie/article/details/107001096
参考二:https://blog.csdn.net/qq_38128179/article/details/84956552
1.5.1 为什么要解决跨域问题
现在绝大多数公司的项目都是前后端分离的,前后端分离后势必会遇到跨域问题。
我们debug会发现,reponse为undefined,提示消息为Network Error。
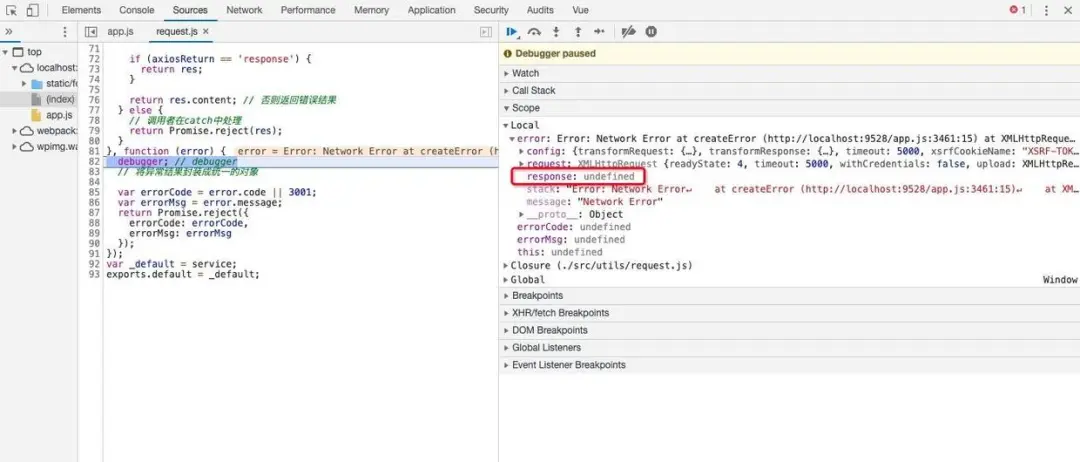
所以当你和前端联调的时候一直请求失败,报网络错误,一般情况下是后端没有做跨域配置。
注意此时并不是后端没有收到请求,而是收到请求了,也返回结果了,但是浏览器将结果拦截了,并且报错。
1.5.2 什么是跨域
同源策略
出于浏览器的同源策略限制。同源策略(Sameoriginpolicy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。
同源策略会阻止一个域的javascript脚本和另外一个域的内容进行交互。所谓同源(即指在同一个域)就是两个页面具有相同的协议(protocol),主机(host)和端口号(port)。
为什么要有同源策略呢?
举个例子,以银行转账为例,看看你的钱是怎么没的:
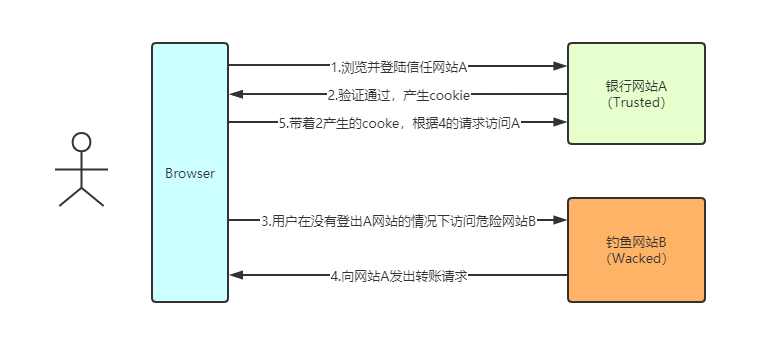
这就是著名的CSRF攻击(跨站请求伪造,当然还有很多其他方式),还有如果第5步不对请求的来源进行校验,那么你的钱已经被转走了。
html页面中的如下三个标签是允许跨域加载资源的
<img src=XXX>
<link href=XXX>
<script src=XXX>
- 1
- 2
- 3
什么是跨域
当一个请求url的协议、域名、端口三者之间任意一个与当前页面url不同即为跨域。

1.5.3 解决跨域的方法
虽然同源策略保证了安全,但一些合理的用途也会受到影响。例如:前端项目在a域名下发送一个Ajax请求到b域名,由于同源策略我们的Ajax请求会报错,导致不能正常请求接口。
解决跨域的方式有很多种,简单介绍2个。
1.5.3.1 JSONP
JSONP主要是利用
1.5.3.2 CROS
浏览器将CORS请求分成两类:简单请求(simple request)和非简单请求(预检请求)(not-so-simple request)。
非简单请求
在正式的跨域请求前,发送一个OPTIONS请求去询问服务器是否接受接下来的跨域请求,携带如下header:
Origin: 发起请求原来的域
Access-Control-Request-Method: 将要发起的跨域请求方式(GET/POST/…)
Access-Control-Request-Headers: 将要发起的跨域请求中包含的请求头字段
- 1
- 2
- 3
服务器在返回中增加如下header来表明是否允许这个跨域请求。浏览器收到后进行检查如果不符合要求则不会发起后续请求
Access-Control-Allow-Origin: 允许哪些域来访问(*表示允许所有域的请求)
Access-Control-Allow-Methods: 允许哪些请求方式
Access-Control-Allow-Headers: 允许哪些请求头字段
Access-Control-Allow-Credentials: 是否允许携带Cookie
- 1
- 2
- 3
- 4
简单请求
只要同时满足以下两大条件,就属于简单请求:
(1) 请求方法是以下三种方法之一:
HEAD
GET
POST
(2)HTTP请求头信息不超出以下几种字段:
Accept
Accept-Language
Content-Language
Last-Event-ID
Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
简单请求会在请求中加入Origin头,直接发起请求,不会先询问了,后端返回相应的header即可。在响应中检查Access-Control-Allow-Origin,不符合要求就报错。
1.5.4 项目中怎么解决跨域问题的(针对Spring)
理解了跨域的本质,再看各种配置其实就是根据请求往reponse中增加header。
1.5.4.1 方式一: 利用Filter
配置如下Filter,CrossDomainFilter是对javax.servlet.Filter的封装,本质上是一个Filter。
可以看到我多返回了一个header,Access-Control-Max-Age,他表明了询问结果的有效期限,即在3600s之内浏览器可以不必再次询问。
@Component
@WebFilter(filterName = "crossDomain", urlPatterns = "/*")
public class CrossDomainFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
// 此处可以进行白名单检测
if(CorsUtils.isCorsRequest(request)) {
response.setHeader("Access-Control-Allow-Origin", request.getHeader("Origin"));
response.setHeader("Access-Control-Allow-Credentials", "true");
response.setHeader("Access-Control-Allow-Headers", request.getHeader("Access-Control-Request-Headers"));
response.setHeader("Access-Control-Allow-Methods", request.getHeader("Access-Control-Request-Method"));
response.setHeader("Access-Control-Max-Age", "3600");
}
// 是个OPTIONS请求,header已设好,不用执行后续逻辑,直接return
if(CorsUtils.isPreFlightRequest(request)) {
return;
}
filterChain.doFilter(request, response);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
看一下用到的工具类
public abstract class CorsUtils {
// 请求中有 origin 这个header则返会true
public static boolean isCorsRequest(HttpServletRequest request) {
return (request.getHeader(HttpHeaders.ORIGIN) != null);
}
public static boolean isPreFlightRequest(HttpServletRequest request) {
return (isCorsRequest(request) && HttpMethod.OPTIONS.matches(request.getMethod()) &&
request.getHeader(HttpHeaders.ACCESS_CONTROL_REQUEST_METHOD) != null);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.5.4.2 方式二: 利用CorsRegistry
@Configuration
public class GlobalCorsConfig {
@Bean
public WebMvcConfigurer corsConfigurer() {
return new WebMvcConfigurer() {
@Override
public void addCorsMappings(CorsRegistry registry) {
// 添加映射路径
registry.addMapping("/**")
// 允许的域
.allowedOrigins("*")
// 允许携带cookie
.allowCredentials(true)
// 允许的请求方式
.allowedMethods("GET","POST", "PUT", "DELETE")
// 允许的请求头
.allowedHeaders("*");
}
};
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
1.5.4.3 方式三: 利用@CrossOrigin注解
支持更细粒度的配置,可以用法方法上或者类上。
@RestController
@RequestMapping("resource")
@CrossOrigin({"http://127.0.0.1:8080"})
public class ResourceController {
}
- 1
- 2
- 3
- 4
- 5
1.6 RabbitMQ相关的应用
2 tiny-Spring
整体实现逻辑 & 循环依赖描述
参考:https://www.processon.com/view/link/62c7dab21e08534607e6810e


