
- 1Unity3D 游戏数据本地化存储与管理详解
- 2生成对抗网络(GAN)_对抗网络 共享特征
- 3python+jieba+wordcloud实现超酷的词云_jieba分词后如何使用jupyter输出
- 4go + uniapp 通过 微信 code 获取 appid 等信息 无废话_uniapp获取微信code
- 5go语言有没有简单的流程引擎_go 流程引擎
- 6Mysql---C#在cmd中使用mysqldump导出sql文件
- 7论文阅读【时间序列分析1】Reconstructing Nonlinear Dynamical Systems from Multi-Modal Time Series_多模态时间序列
- 8yolov5调试common.py出现importerror: cannot import name ‘tryexcept‘ from ‘utils‘_cannot import name 'tryexcept' from 'utils
- 9Android:漫画APP开发笔记之ListView中图片按屏幕宽度缩放_android listview可缩放
- 10基于 Nginx Ingress + 云效 AppStack 实现灰度发布
YOLOv5-6.1从训练到部署(一):环境安装、示例检测、推理文件的导出与可视化_yolov5 6.1
赞
踩
1 前言
本系列文章是演示如何使用Ultralytics公司的开源项目YOLOv5-6.1版本进行目标检测的文章,包括直接使用官方权重进行检测和部署,以及在自定义数据集上进行训练和部署,在学习本系列文章之前,需要知道Pytorch的基本使用和YOLOv5的原理,其他知识我们可以跟着文章来学。
2 项目基本环境
本项目对环境的要求如下:
Python 3.6.5
Pytorch 1.71
OpenCV-Python 4.5.5
OpenVINO 2022 Python
onnxruntime-gpu 1.10.0
- 1
- 2
- 3
- 4
- 5
建议在Anaconda上新建一个虚拟的Python开发环境,命名为yolov5
上述环境中的Python包安装指令为:
pip install opencv-python==4.5.5.64
pip install opencv-contrib-python==4.5.5.64
pip install openvino-dev==2022.3.1
pip install onnxruntime-gpu==1.10.0
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
- 1
- 2
- 3
- 4
- 5
如果安装时,存在版本不兼容,可以修改小版本号,例如可以将2022.3.1改成2022.2.0。
这里pytorch的下载比较麻烦,如果下载比较慢,可以在pytorch whl文件列表中下载对应的whl文件(包括torch、torchvision、torchaudio等),而whl文件可以通过迅雷下载,速度比从官网下载快很多。
例如,本机的系统为Windows,cuda版本是12.0,安装的Python虚拟环境为3.6.5,要下载的 torch 版本为1.7.0,那么需要需要下载的whl文件如下所示:

torchvision和torchaudio的whl文件下载方式类似,但需要注意和torch的版本匹配,匹配关系看这条命令:conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
3 在GitHub中下载代码
YOLOv5有很多版本,不同的公司和个人都会将自己开发的YOLOv5项目放到GitHub上,我们这边选择ultralytics的,这是原装正版,随着这些年的迭代升级,其代码的可读性和对工程化的支持度,都已经达到了极高程度,因此这个版本比较适合我们学习。
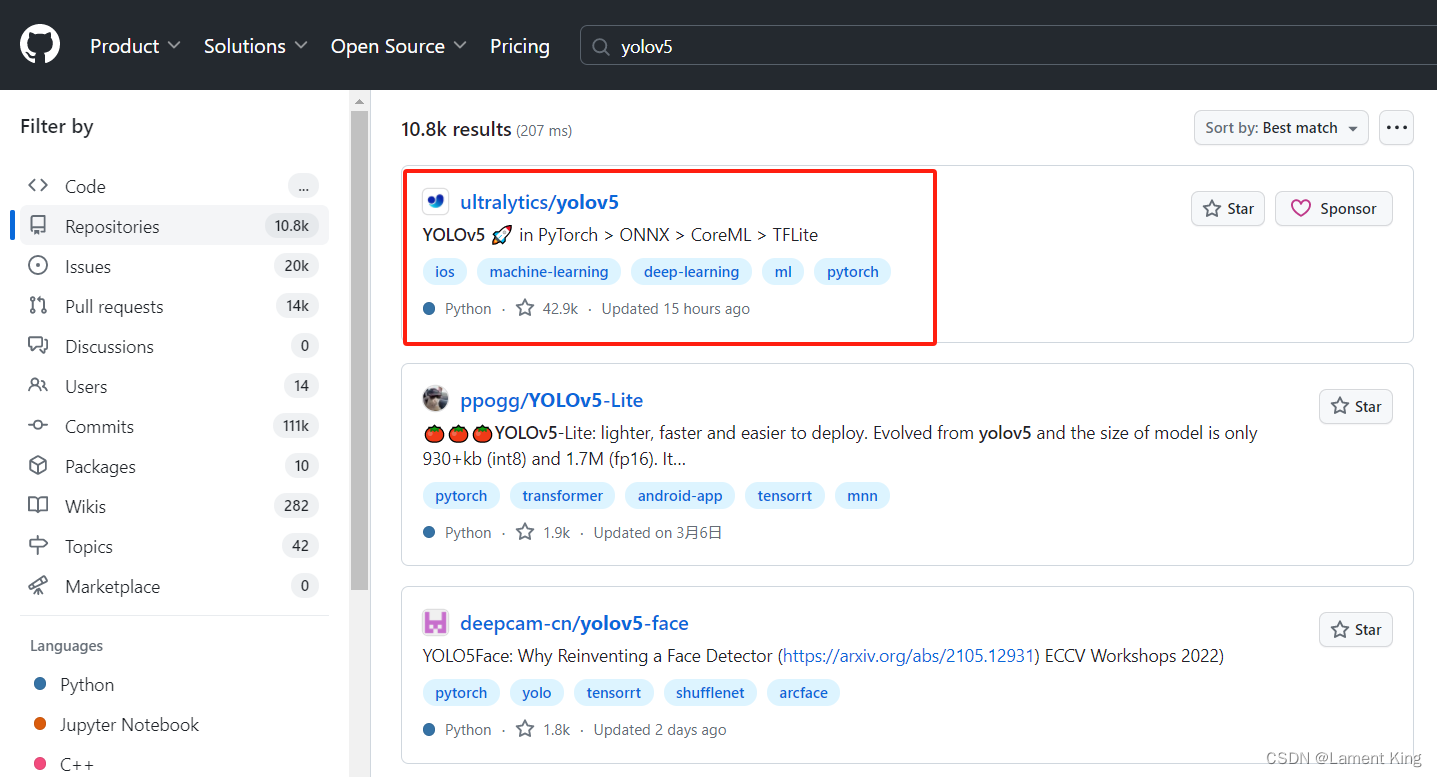
点击去之后,不要急着对其使用git clone,因为新合并的代码很可能错在bug,我们要选择发行版,这个比较稳定。
点击分支旁边的tags,里面可以看到不同的发行版:

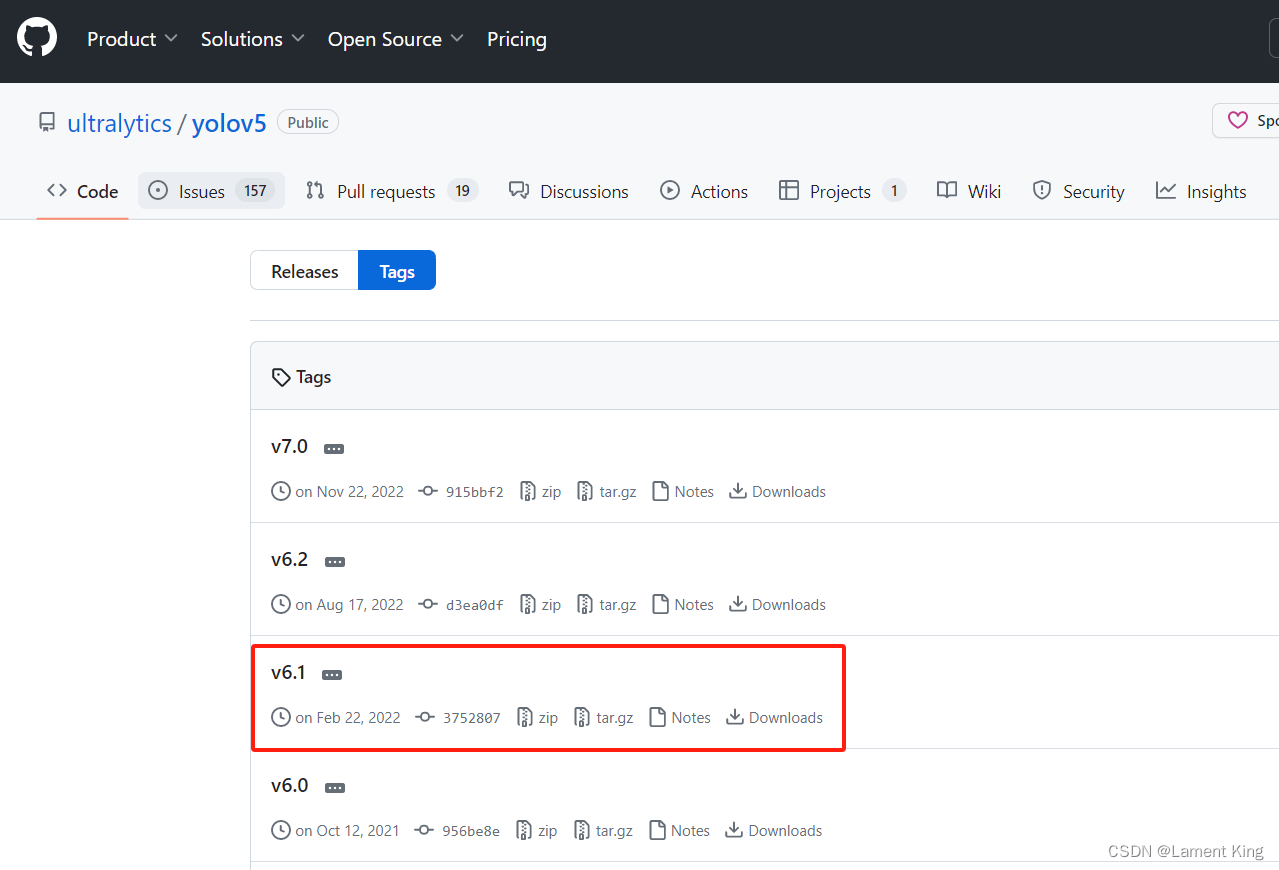
我们选择v6.1,其实选择v6.2也可以,因为差距不大,但不能选择v7.0,因为从7之后,YOLOv5增加了图像分割的功能,这会对我们的教学带来额外的工作量,特别是对于还未来得及学习图像分割的学生。
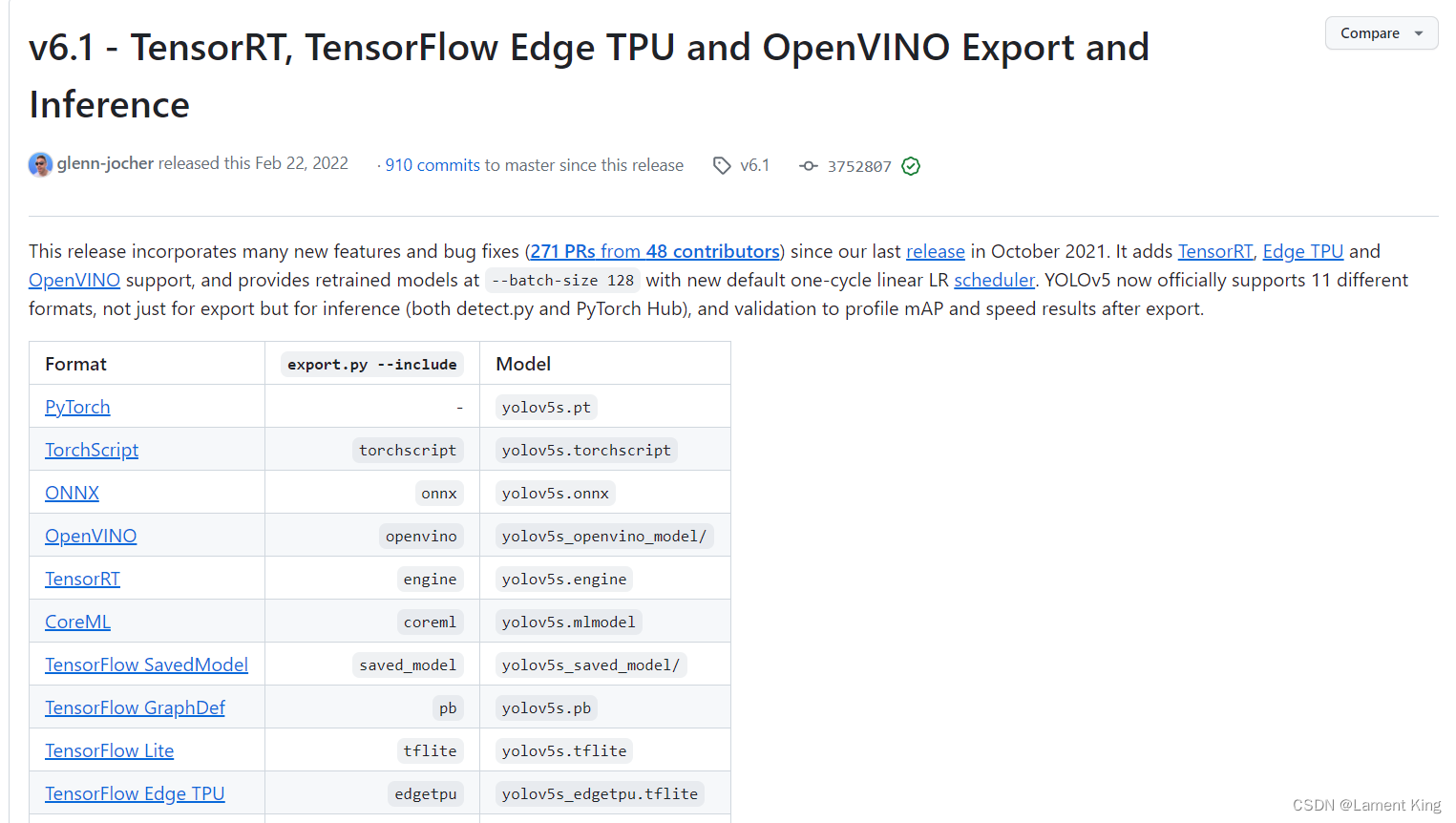
点进去可以看到v6.1的介绍,这里包含相对于之前版本的更新(Important Updates)、在公开数据集上的表现(New Results)、资产(Assets,包含权重文件及源代码)以及其他一些信息,各位有兴趣可以自己看。我们滑到最下面,找到Assets,然后点击Source Code下载源码。
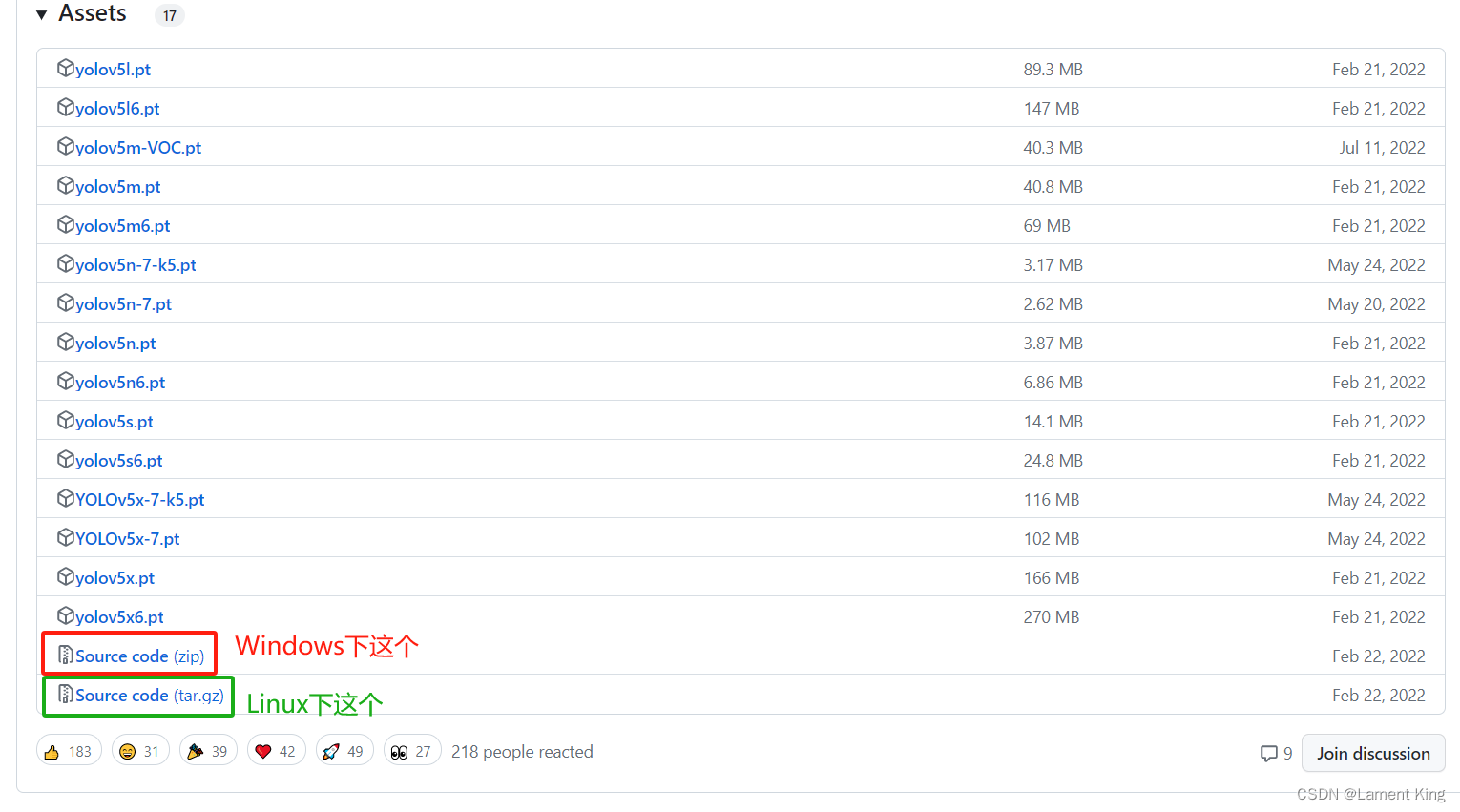
下载之后解压缩,我们的源码下载完毕。
4 项目环境补充与推理测试
(1)安装requirements.txt
前面安装的Pytorch、OpenCV等只是基本环境,程序运行过程中还需要很多其他程序库,例如numpy、Pillow等
这里我们在项目下打开命令行终端,然后激活环境,随后执行下面命令:
pip install -r requirements.txt
- 1
这里面requirements.txt的内容如下:
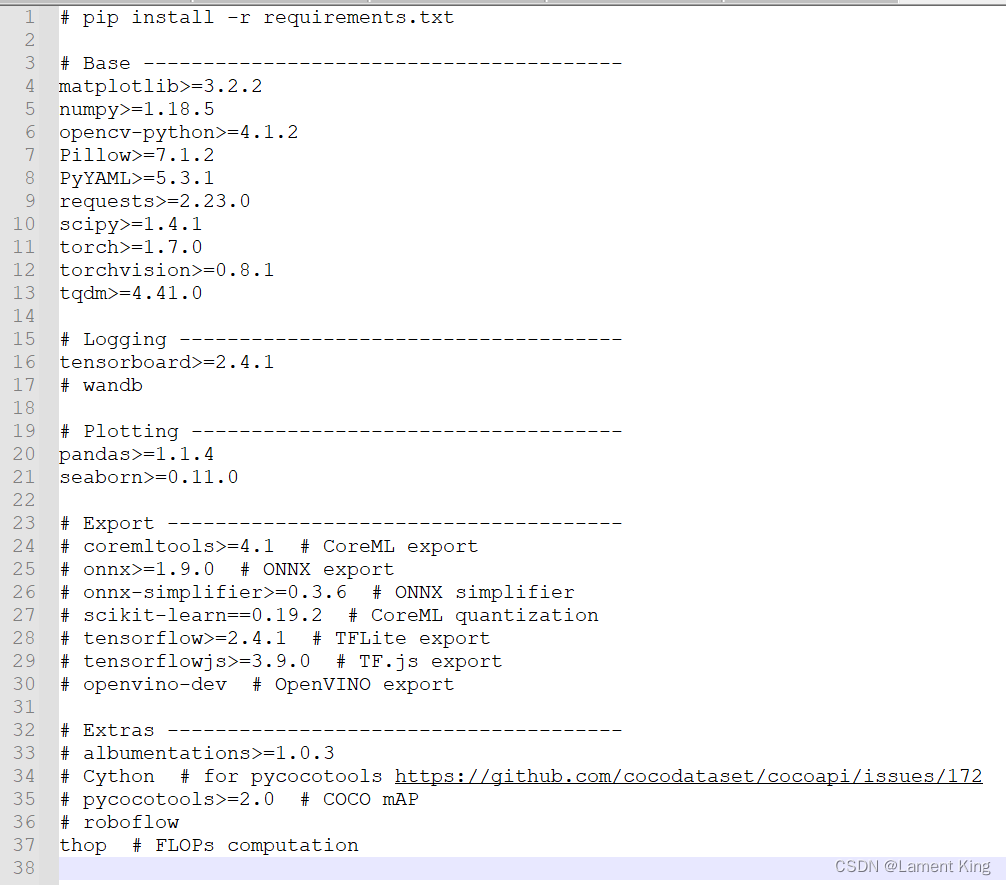
这里有个#Export,是导出需要安装的程序库,这个我们稍后会讲。
(2)检测示例
下面我们测试一下程序,看看环境是否已经准备好。
当前目录下,有一个名为tutorial.ipynb的文件,用jupyter notebook打开,

并切换到刚刚安装的环境,如果在jupyter notebook中找不到,那么可以用python -m ipykernel install --user --name yolov5先把环境添加到jupyter notebook中。
然后滑倒下面Inference,这里可以看到推理时的命令行参数:

项目文件中有现成的图像例子:
好,我们就以zidane.jpg为例,演示一下如何检测。在命令行终端输入:
python detect.py --source data/images/zidane.jpg
- 1

首先是下载字体文件(Arial.ttf),当检测到目标框之后,要在左上角标类型标签,这里就是标签的字体。
随后是命令行参数,因为我们的命令只有待测图片,还有其他参数省略了,这里显示其他的参数;再下面是YOLO的版本与torch的版本;接着是下载模型文件,这里直接访问github太慢了,我们把网址(https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt)复制下来,然后通过迅雷下载,再移动到当前目录下:
我们关闭终端,重新打开终端运行刚刚的命令
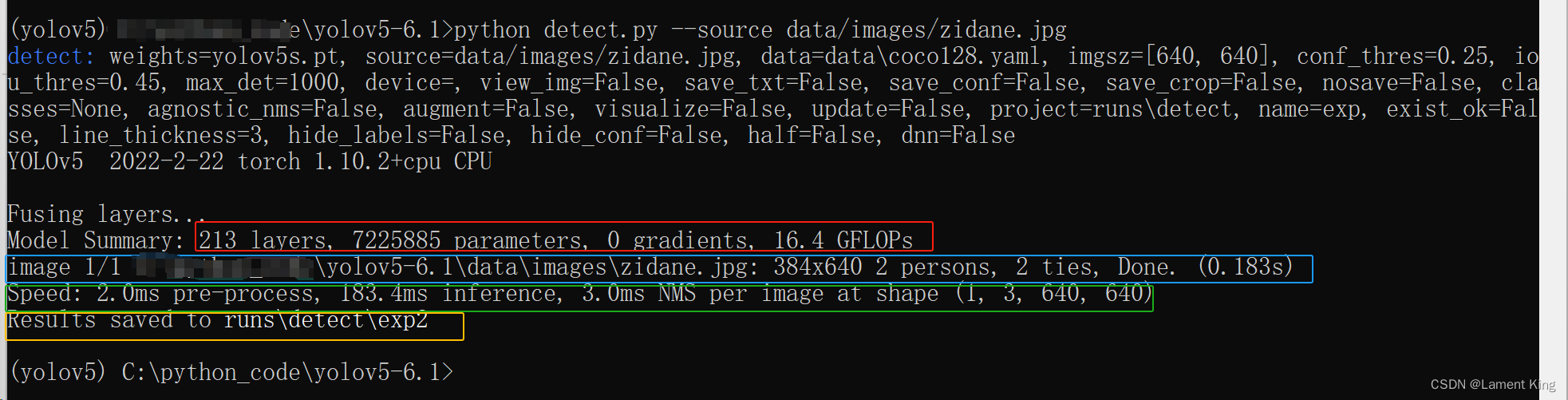
可以看到,fusing layers…下面,红色边框里的是模型概述,蓝色边框里的是检测的图像地址及其检测结果,绿色是推理速度,黄色是推理结果的保存位置。我们根据上述保存位置,找到图像:
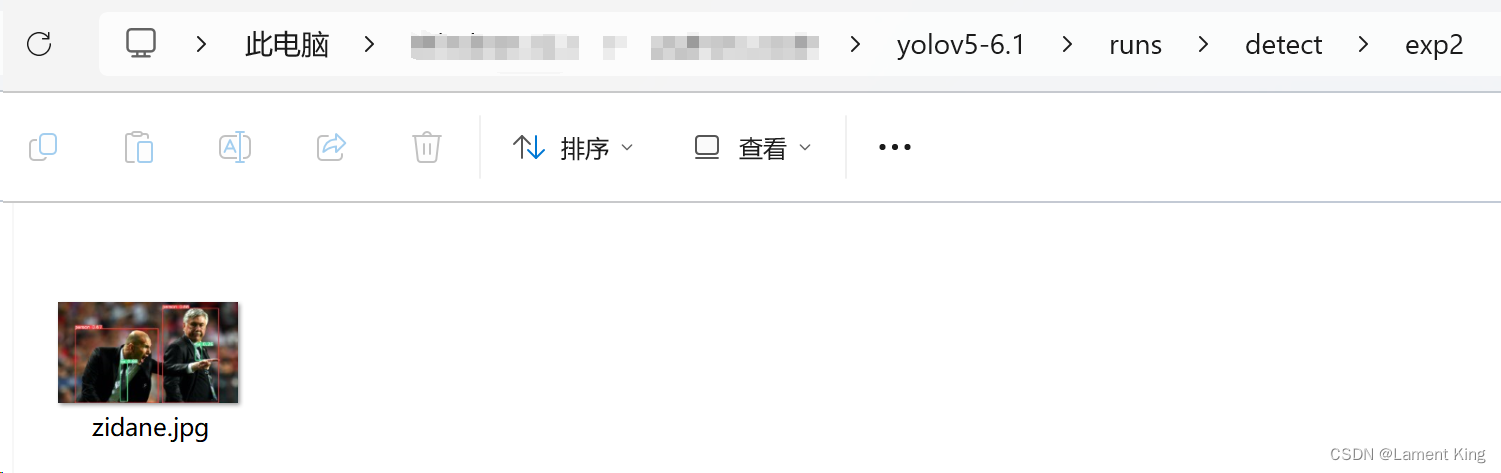
打开如下:

能输出这张图,表示已经成功检测,我们的环境转好了。
也可以将图片换成电脑摄像头或者视频,假如我们要使用0号摄像头(如果只有一个摄像头,则默认为0号),则可以这样:
python detect.py --source 0
- 1
如果想结束视频检测,则只需要按两下Q键即可。
5 推理文件的导出与使用
(1)推理文件的导出
YOLOv5 6.1相比于前面的版本,便于导出推理框架,这里我们以导出onnx和OpenVINO的IR文件为例。
在GitHub的YOLOv5 6.1页面,有一个教你怎么导出推理文件的命令
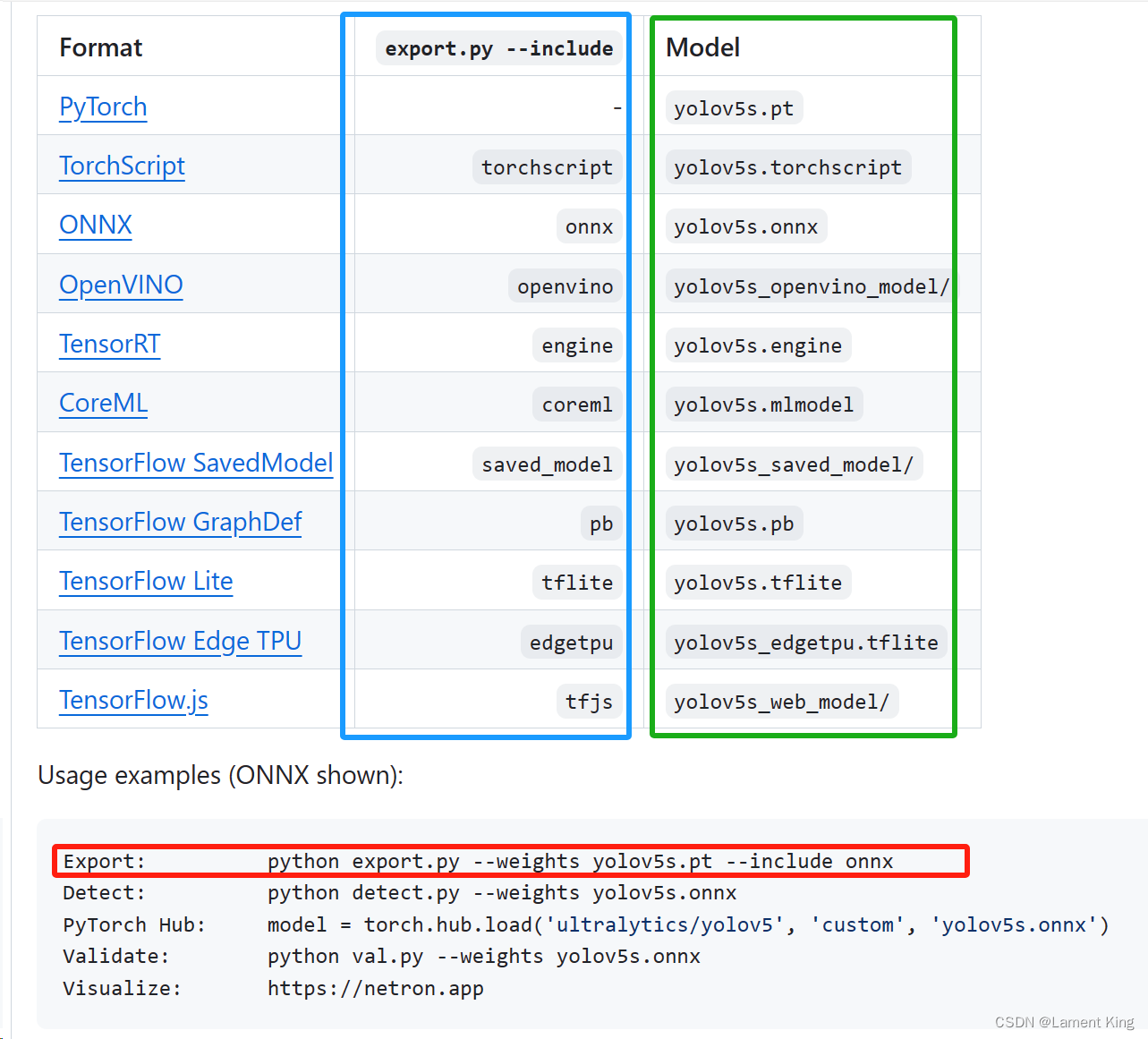
在tutorial.ipynb文件中,也还有一个cell教你如何导出onnx文件
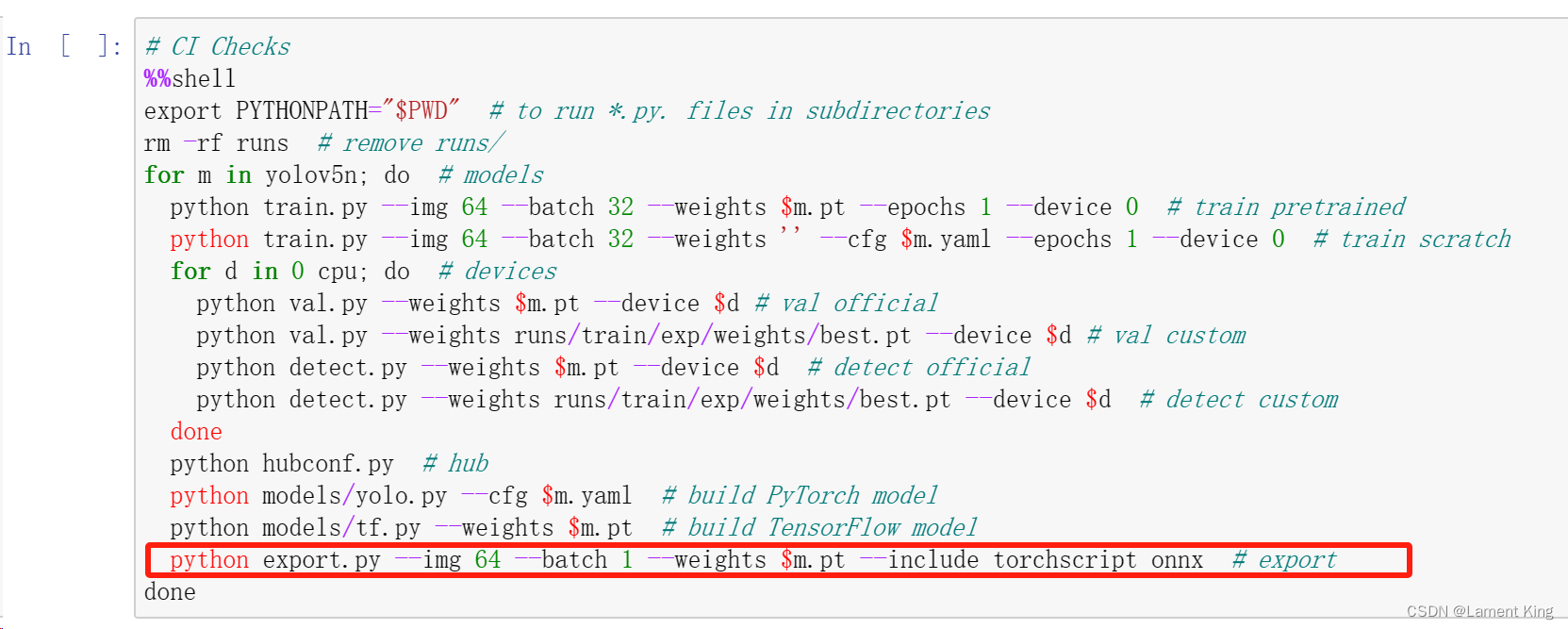
这里我们同时导出onnx文件和OpenVINO的中间文件(Intermediate Representation,简称IR),在命令行终端输入:
python export.py --weights yolov5s.pt --include onnx openvino
- 1
结果:
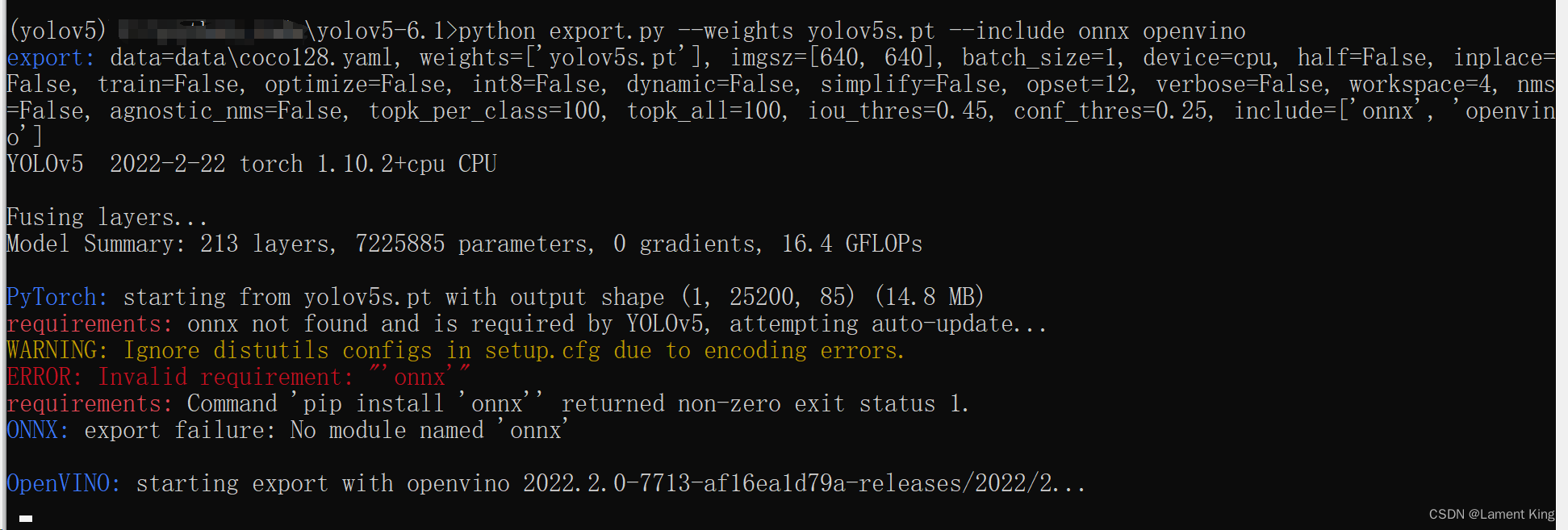
这里发生了错误,还记得requirements.txt中的#Export吗,这里注明了推理框架需要安装的包
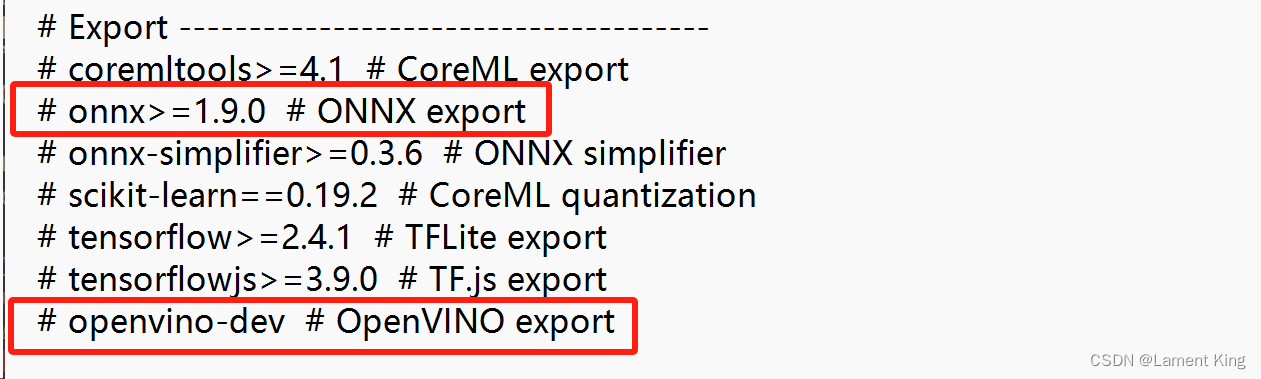
假如我们想获得onnx文件,就需要onnx>=1.9.0,而openvino-dev我们之间装了,所以之类不需要继续安装,命令行输入:
pip install onnx
- 1
随后再次输入:
python export.py --weights yolov5s.pt --include onnx openvino
- 1
结果
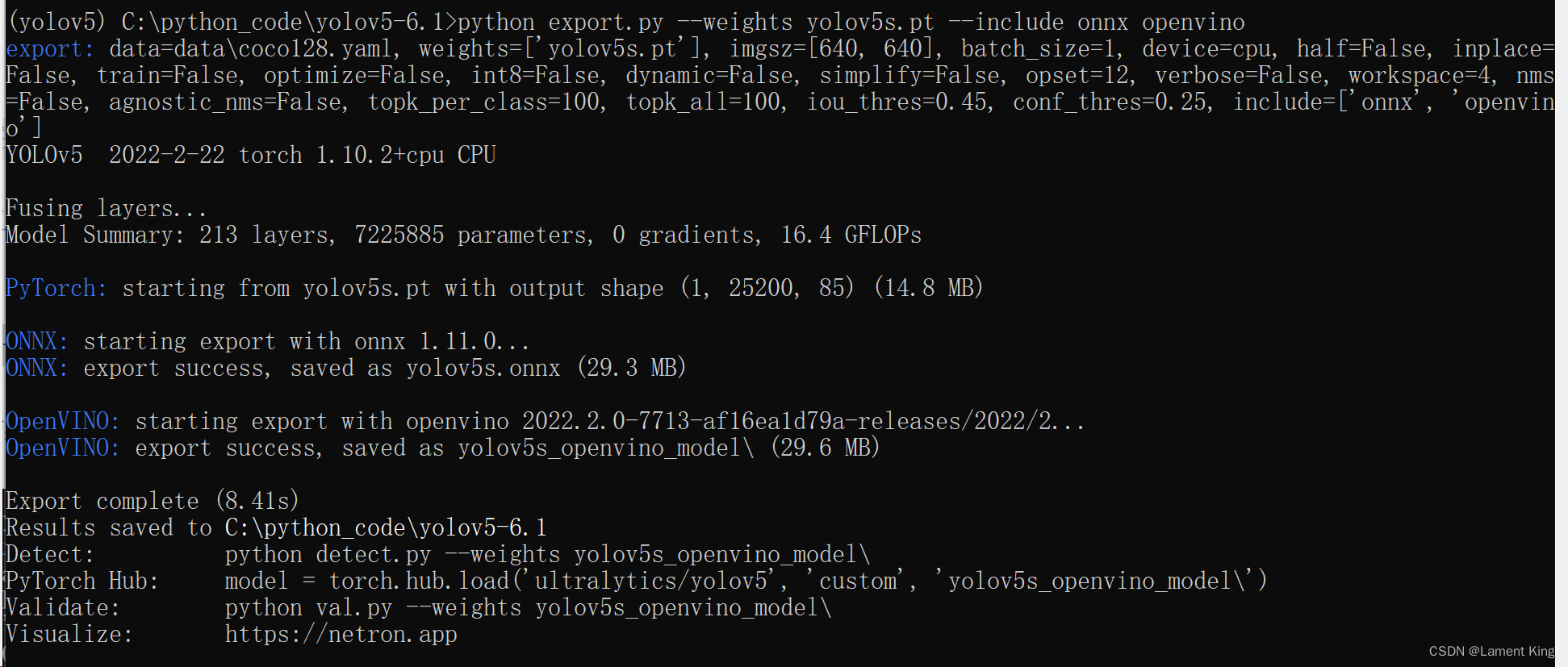
没有报错,说明导出成功。
在当前目录下可以到对应的onnx文件及IR文件:
(2)推理文件的使用
现在我们可以用推理文件进行推理了,我们先用onnx文件来试一下,使用该文件默认调用的推理框架是onnxruntime,命令行终端输入:
python detect.py --weights yolov5s.onnx --source data/images/zidane.jpg
- 1
输出如下:
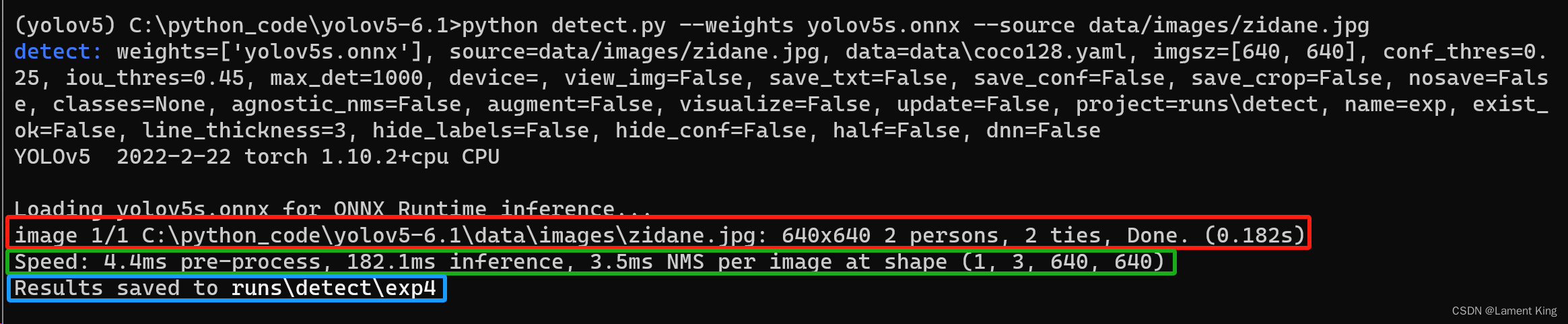
红色方框的内容是推理结果,结果显示,640×640的图片中有两个人和两个领带被检测出来,用时182毫秒;绿色方框的内容是推理的每个步骤用时,这里显示预处理用了4.4毫秒,(神经网络)推理花了182.1毫秒,NMS花了3.5毫秒;蓝色方框内是推理结果的保存位置,我们这里就不打开看了。
我们再试一下使用OpenVINO的IR文件试一下,命令行输入
python detect.py --weights yolov5s_openvino_model --source data/images/zidane.jpg
- 1
输出如下:
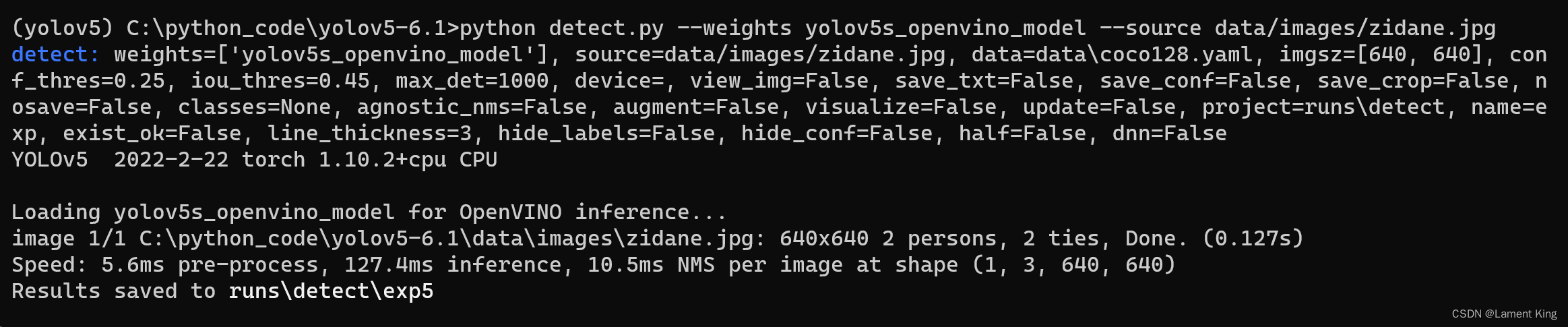
可以看到,在当前环境下,OpenVINO的推理速度明显高于onnxruntime。
(3)查看模型结构
这里我们使用netron打开yolov5s.onnx,刚刚我们导出推理文件时,终端输出显示我们可以通过在浏览器中输入https://netron.app进入网页版netron,进而打开模型文件(不推荐这种方式)。

但这样做是通过上传模型文件来查看模型结构,某些公司安全机制比较严,不允许上传本地文件,这种情况下必须在本地安装netron。
在命令行终端输入:
pip install netron
- 1
然后在命令行终端输入netron(必须在安装了netron的虚拟环境中)
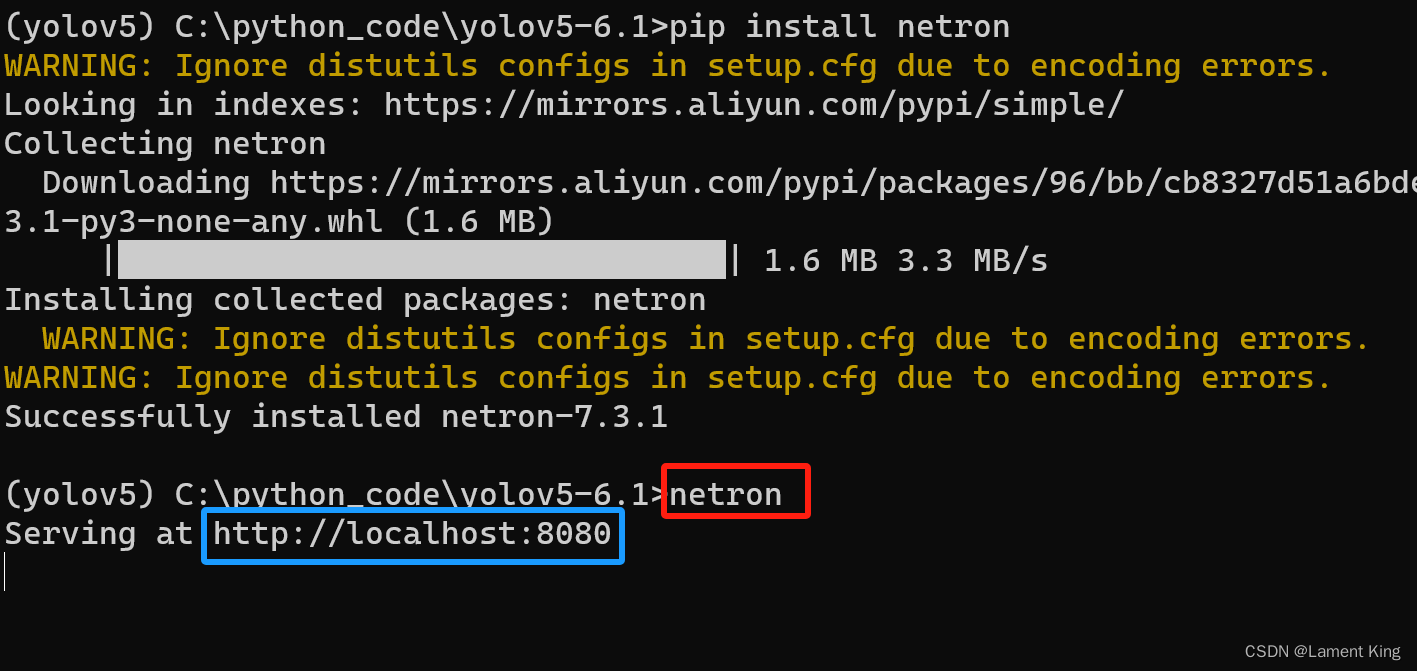
在浏览器中输入http://localhost:8080即可进入netron,或者在终端按住ctrl然后点击蓝色方框中的链接(win11可以,win10我没有试)

点击Open Model...,然后在提示窗中找到对应的yolov5s.onnx文件
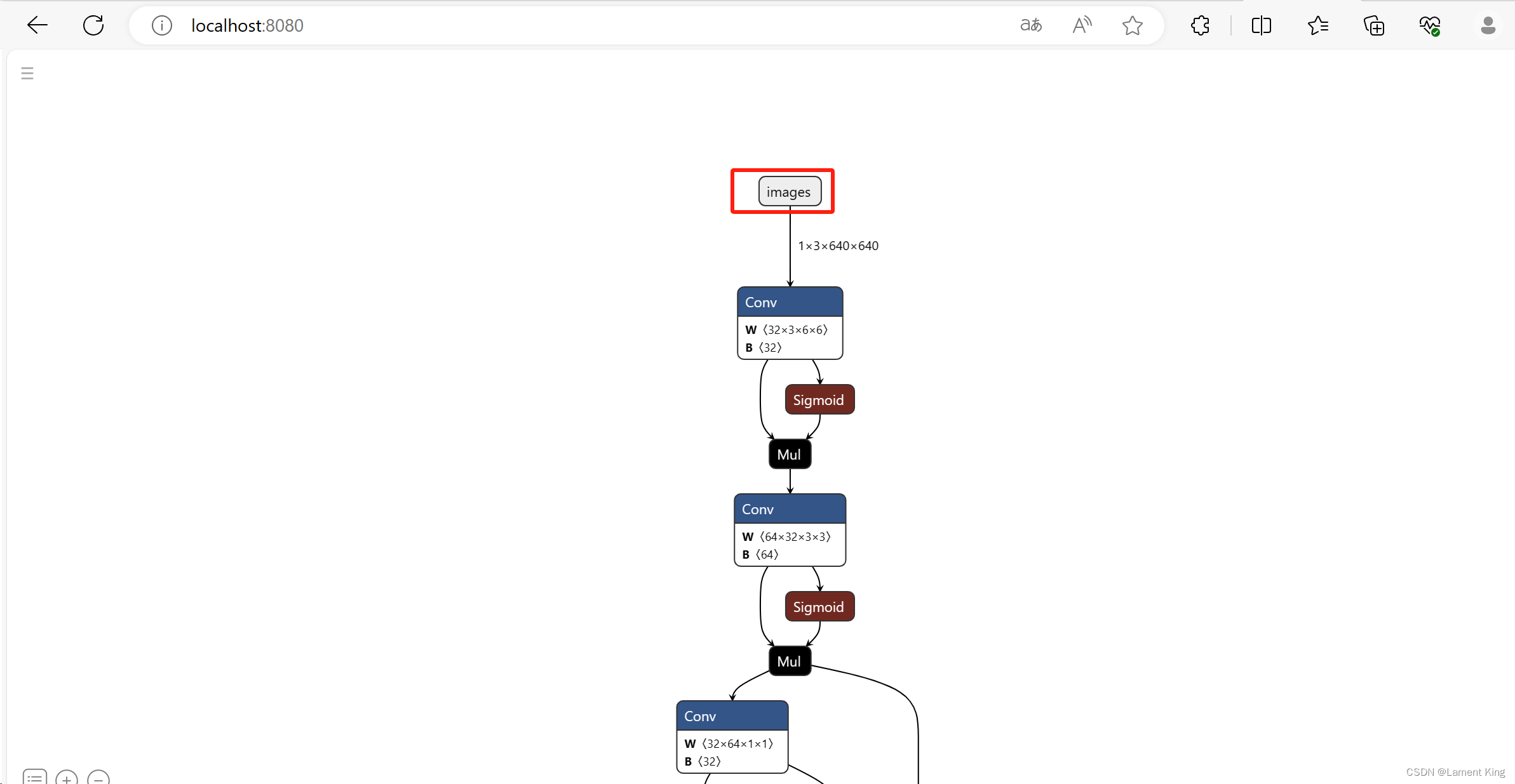
随后就能看到下面这样的结果
我们点击最上方的images,然后在右边可以看到关于模型的整体输入输出:
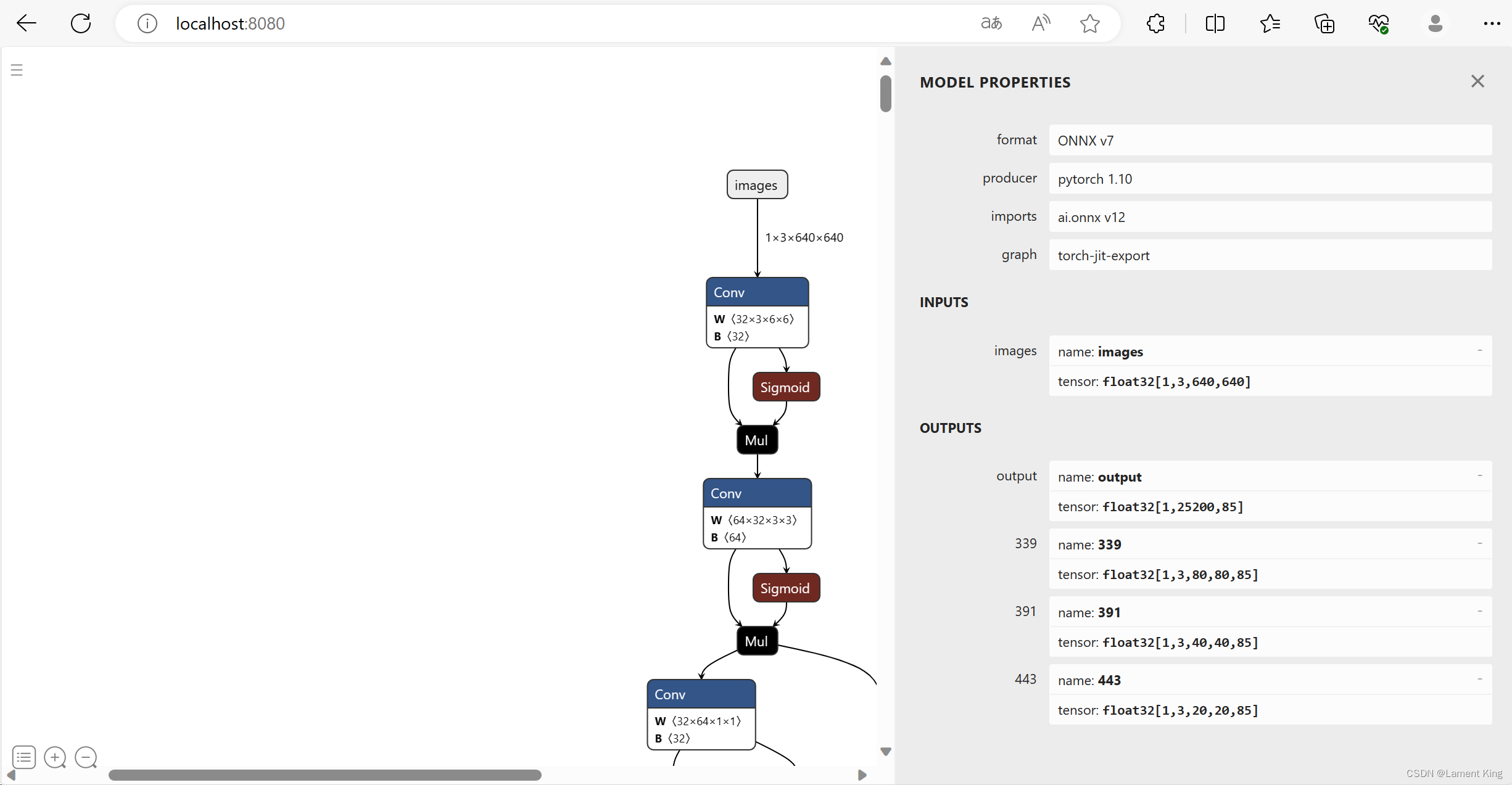
从INPUTS下面可以看到,当前模型的输入张量为float32[1, 3, 640, 640],其中float32是类型,[1, 3, 640, 640]是形状(shape),输出有四部分,名字分别为:output, 339, 391, 443,张量分别为:float32[1,25200,85], float32[1,3,80,80,85], float32[1,3,40,40,85], float32[1,3,20,20,85]。这里面339, 391, 443是三个检测头的输出,output是将这三个层合并,同时做了一些其他后处理工作(比如anchor box的中心点坐标解析与高宽缩放),所以我们只需要解析这个就行,其他三个不需要管他(早期版本是只有三个检测头的输出,从YOLOv5-6.x开始增加了一个output,只需要解析output)。之所以仍然保留三个检测头的输出,个人猜测是为了向下兼容,使得早期那些直接解析三个检测头的程序仍然可以运行)。
可以在netron的页面中按照如下步骤,根据层(模块)的名字快速找到对应的结构:
四个输出结构如下所示:
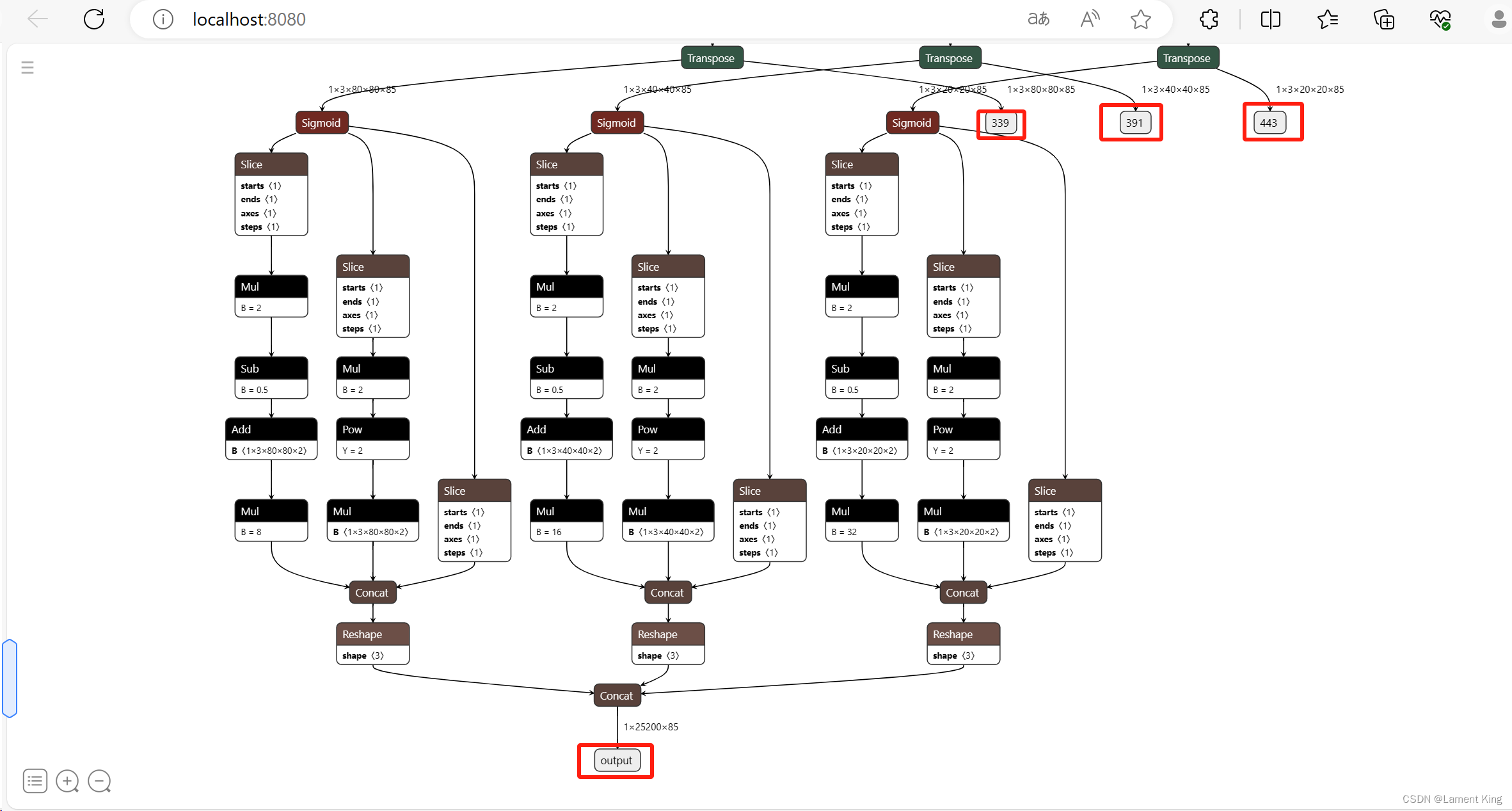
OK,关于可视化的部分我们暂时介绍到这里,更多关于netron的介绍可以去B站上看教程。
关于YOLOv5的结构与原理,这不是本门课的内容,本课程不是面向零基础的同学,这里只是简要介绍如何使用netron查看YOLOv5,若想对结构与原理有所了解,可以去知乎上看江大白的系列文章,建议从YOLOv3开始看,看到YOLOv5基本就懂了,如果想读源码,可以跟着这个视频来,这个10小时的视频讲的十分详细。
6 yolov5s6
我们回到GitHub页面,我们可以看到,有一个名为yolov5s6.pt的权重文件,这是由于YOLOv5-6.1在结构方面对之前的版本进行了改进。
我们将它下载下来,并导出为onnx文件,使用以下命令
python export.py --weights yolov5s6.pt --include onnx
- 1
然后使用netron查看模型的整体输入输出,可以发现OUTPUTS有四块:
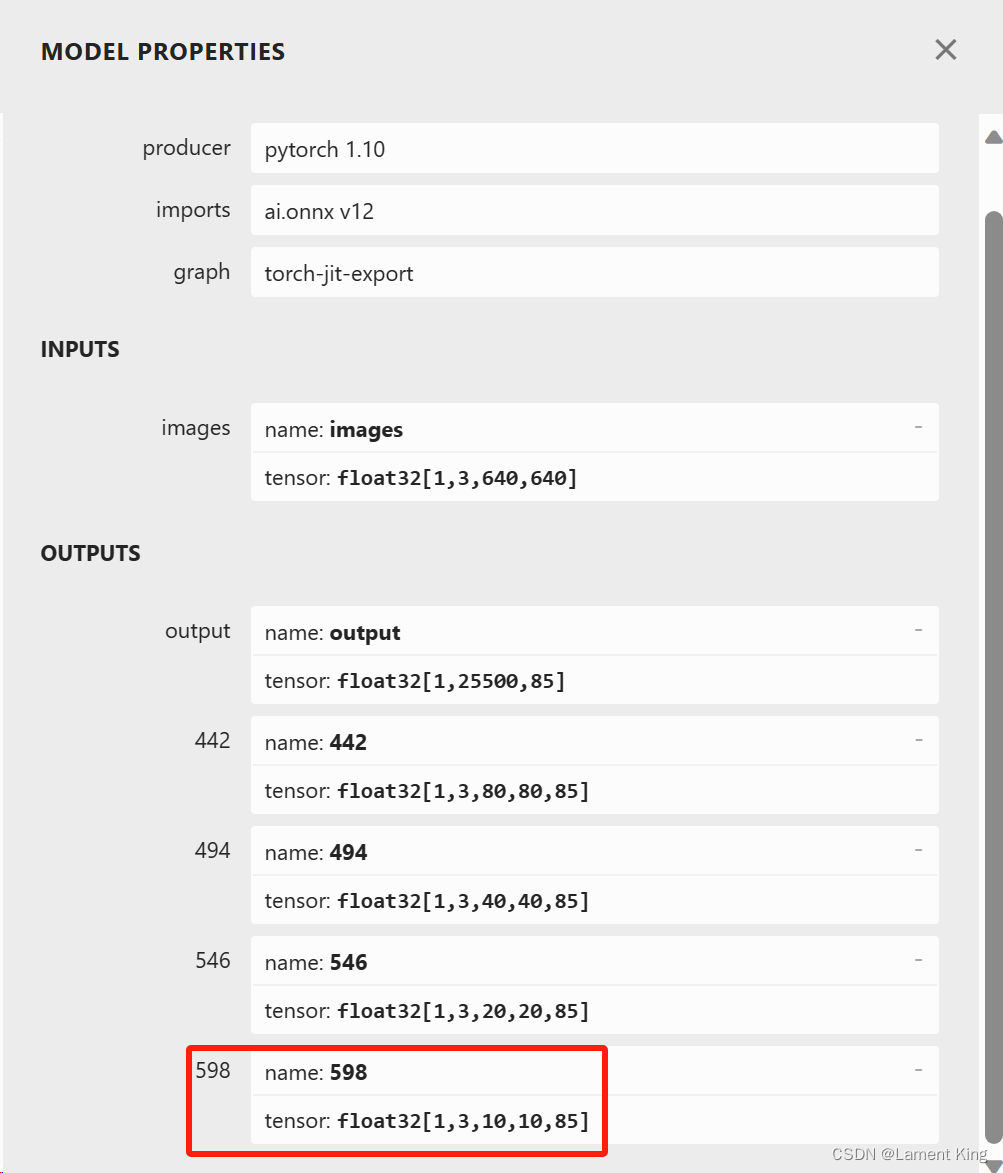
相比较yolov5s.onnx,这里多了一个形状为float32[1,3,10,10,85]的输出,如果有Neck结构改进经验,应该知道这是做了更强的特征融合,原本是将三个阶段的特征图进行融合,这里是四个,当然,最后仍然只需要解析output就行。
7 总结
好的,我们今天对Ultralytics的YOLOv5有了个初步的了解,已经学会了如何安装环境、检测图像、导出推理文件及推理文件的可视化,掌握这四项内容,那么今天的目的就达到了。

