
热门标签
热门文章
- 1FastMVSNet自定义测试数据集网络实现流程(二)_mvsnet训练自己的数据集
- 2Kafka学习---分区与副本原理解析_kafka分区和副本理解
- 3银行木马卷土重来、开发者破坏开源库影响数千应用程序|1月10日全球网络安全热点
- 4Redis-stack 初体验_redis stack
- 5[Bug0014] Hexo+Github 搭建博客报错 :remote: Support for password authentication was removed on August 13, ...
- 6Android网络基础1——网络分层_android 开发七层模型
- 7数据全生命周期保护基本要求_数据生命周期安全防护,2024年最新2024年展望网络安全原生开发的现状_数据安全 一般数据 全生命周期保护措施
- 8使用Docker Compose一键部署前后端分离项目(图文保姆级教程)_docker-compose部署前后端项目
- 9【利器篇】前端40+精选VSCode插件,总有几个你未拥有!_vscode 前端开发必备插件
- 10【2024浙江省蓝桥杯C++B组省赛】题解A-D(含题面)_有一个数组,包含 1 到 n 这 n 个整数,初始为一个从小到大的有序排列:{1, 2, 3
当前位置: article > 正文
llama3-8B模型8G显存量化部署_llama3 8b 显存
作者:小惠珠哦 | 2024-06-19 07:28:25
赞
踩
llama3 8b 显存
基于InternStudio平台,使用8G显存部署量化后的llama3-8b
Llama-3简单介绍
本次Llama-3的介绍与前两个版本差不多,大量的测试数据和格式化介绍。但Meta特意提到Llama-3使用了掩码和分组查询注意力这两项技术。
目前,大模型领域最流行的Transformer架构的核心功能是自我注意力机制,这是一种用于处理序列数据的技术,可对输入序列中的每个元素进行加权聚合,以捕获元素之间的重要关系。但在使用自我注意力机制时,为了确保模型不会跨越文档边界,通常会与掩码技术一起使用。在自我注意力中,掩码被应用于注意力权重矩阵,用于指示哪些位置的信息是有效的,哪些位置应该被忽略。通常当处理文档边界时,可以使用两种类型的掩码来确保自我注意力不会跨越边界:
- 填充掩码,当输入序列的长度不一致时,通常会对较短的序列进行填充,使其与最长序列的长度相等。填充掩码用于标记填充的位置,将填充的部分掩盖,使模型在自我注意力计算中忽略这些位置。
- 未来掩码,在序列生成任务中,为了避免模型在生成当前位置的输出时依赖后续位置的信息,可以使用未来掩码。
未来掩码将当前位置之后的位置都掩盖起来,使得自我注意力只能关注当前或之前的位置。
此外,在Transformer自注意力机制中,每个查询都会计算与所有键的相似度并进行加权聚合。
而在分组查询注意力中,将查询和键分组,并将注意力计算限制在每个查询与其对应组的键之间,从而减少了模型计算的复杂度。
由于减少了计算复杂度,分组查询注意力使得大模型更容易扩展到处理更长的序列或更大的批次大小。这对于处理大规模文本数据或需要高效计算的实时应用非常有益。
同时分组查询注意力允许在每个查询和其对应组的键之间进行关注的计算,从而控制了注意力的范围。这有助于模型更准确地捕捉查询和键之间的依赖关系,提高了表示能力。
Meta表示,Llama-3 还使用了一个 128K的词汇表标记器,能更有效地编码语言,在处理语言时也更加灵活。训练数据方面,lama3在超过 15T tokens的公开数据集上进行了预训练。这个训练数据集是 Llama2的7倍,包含的代码数量也是 Llama 2 的4倍。为了实现多语言能力,Llama3的预训练数据集中有超过 5% 的高质量非英语数据,涵盖 30 多种语言。
量化部署
由于算力资源有限,使用InternStudio平台,8G显存部署量化后的llama3-8B。查看开发机的显存,如下图所示:
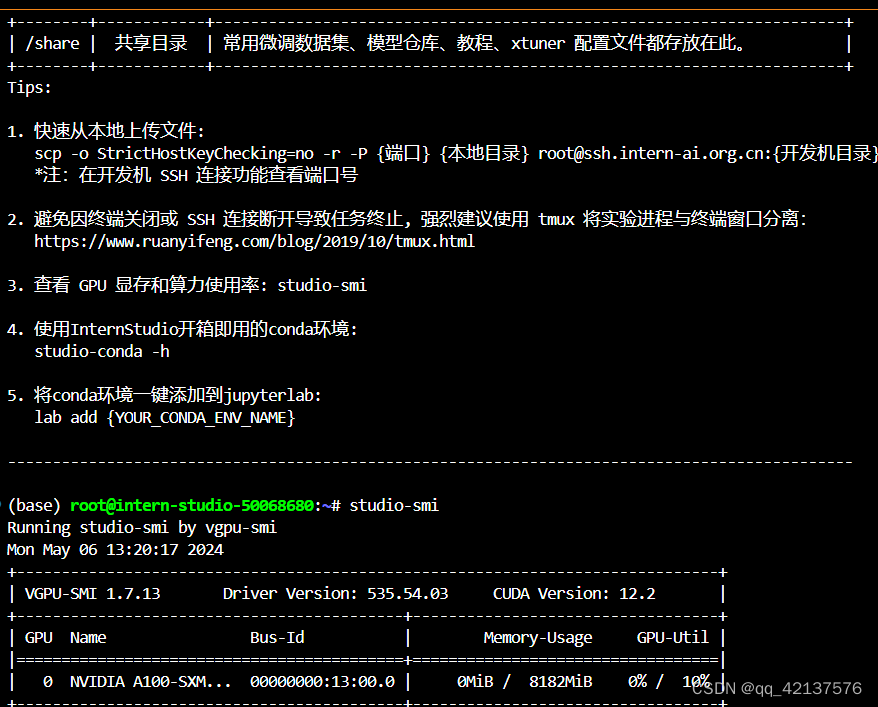
- 首先配置基本环境命令如下:
conda create -n llama3 python=3.10 #创建名字llama3的虚拟环境,python版本为3.10
conda activate llama3 #激活llama3环境
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia #下载pytorch
- 1
- 2
- 3
等待一会,即可安装成功。使用pip list,查看安装的结果,如下图所示:
- 其次下载模型
新建文件夹
mkdir -p ~/model #创建model文件夹
cd ~/model#切换model文件夹
- 1
- 2
使用软链接 InternStudio 中的模型命令如下
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct
- 1
使用上述软连接命令后,在model目录下即可出现模型的文件夹,如下图所示:

- Web Demo 部署
拉取Llama3-Tutorial代码。
cd ~
git clone https://github.com/SmartFlowAI/Llama3-Tutorial
- 1
- 2
安装 XTuner 时会自动安装其他依赖
cd ~
git clone -b v0.1.18 https://github.com/InternLM/XTuner
cd XTuner
pip install -e .
- 1
- 2
- 3
- 4
下图为代码下载完成的效果:

下图为安装好依赖的效果:

运行 web_demo.py
streamlit run ~/Llama3-Tutorial/tools/internstudio_web_demo.py \
~/model/Meta-Llama-3-8B-Instruct
- 1
- 2
运行上述代码,由于显存为8G,会出现显存不够的情况,如下图:

此时需要运行量化后的命令即可。
streamlit run ~/Llama3-Tutorial/tools/internstudio_quant_web_demo.py ~/model/Meta-Llama-3-8B-Instruct
- 1
效果如下:

本次实验参考Llama3-Tutorial这个教程,有兴趣者可以访问了解一下。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小惠珠哦/article/detail/735740
推荐阅读

相关标签

