
- 1JDK8新特性 - Lambda表达式_jdk8有lamda表达式吗
- 2阿里云服务器搭建hadoop集群后无法访问9870,8088web端口解决方案_阿里云服务器登不上hadoop的8970
- 3gitlab 克隆远程仓库 分支方法_gitlab克隆分支
- 4Docker高级篇之Docker-compose容器编排
- 5探秘AI测试助手:Test-Agent,智能化测试的新纪元
- 6使用window自带的ssh连接linux服务器_window用ssh连接linux
- 7万字总结!5大AI应用场景+17个细分方向+40多个案例精选_ai常见办公场景
- 8顺序输出片内RAM的数据_2分钟时ram的输出数据
- 9深入理解与解决Git中的“fatal: refusing to merge unrelated hi_git refusing to merge
- 10二、Neo4j的使用(知识图谱构建射雕人物关系)_neo4j的使用(知识图谱构建射雕)
IEEE SLT 2022论文丨如何利用x-vectors提升语音鉴伪系统性能?
赞
踩
分享一篇IEEE SLT 2022收录的声纹识别方向的论文,《HOW TO BOOST ANTI-SPOOFING WITH X-VECTORS》由AuroraLab(极光实验室)发表。
来源丨AuroraLab
AuroraLab源自清华大学电子工程系与新疆大学信息科学与工程学院,以说话人识别和标记、音频事件检测、知识图谱构建与应用为研究重点,围绕感知智能与认知智能的理论、技术与系统等开展研究。

论文题目:HOW TO BOOST ANTI-SPOOFING WITH X-VECTORS
作者列表:马欣悦,张姗姗,黄申,高骥,胡颖,何亮
论文原文:https://ieeexplore.ieee.org/document/10022504
论文下载:文末点击“阅读原文”下载论文
研究背景
随着语音合成、语音转换技术的进步,人工生成的语音几近以假乱真,给用于身份验证的自动声纹验证(Automatic Speaker Verification,ASV)系统的安全性带来了极大的威胁,因而对语音鉴伪技术的研究刻不容缓。
本文方案
从日常生活经验来看,如果我们熟悉目标说话人,往往会利用记忆中关于他的发声特征来判断某段音频的真或假。但说话人标签不能被直接用于指导鉴伪模型的训练,因为在真实应用场景中很难直接获得真假音频的说话人标签。由此,我们使用预先训练好的 TDNN[1]提取 x-vector,作为辅助鉴伪系统的说话人信息,提出了利用说话人信息增强鉴伪模型真假辨别能力的三套方案。上述方案部署到LightCNN[2]、SeNet34/50[3] 上以验证有效性。
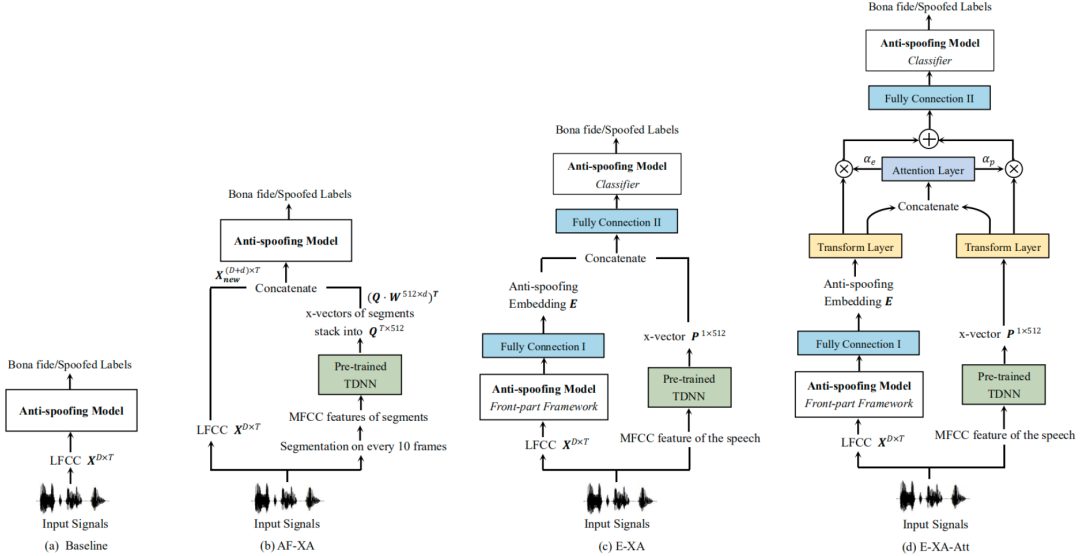
图1 (a)基线, (b)AF-XA, (c)E-XA, (d)E-XA-att的模型结构图
方案一:声学特征阶段x-vectors辅助(Acoustic Feature level X-vectors Assistance,AF-XA)
声学特征阶段x-vectors辅助 (AF-XA) 方法将分段后的 x-vector 与声学特征帧对帧拼接作为防伪网络的输入,如图 1(b) 所示。声学特征向量X为T帧的d维LFCC倒谱系数。x-vectors的特征矩阵Q,它是由音频每10帧提取的x-vector且重复10次拼接而成。此外,我们在网络中加入一个变换矩阵W来降低提取的x-vector的维数,实验发现降至256维性能最佳,考虑模型参数量成本降至48维最好。
方案二:嵌入阶段x-vectors辅助(Embedding level X-vectors Assistance,E-XA)
嵌入阶段x-vectors辅助(E-XA)是利用x-vector适应到语音鉴伪模型的嵌入网络层中,如图1(c)所示。LightCNN 的防伪嵌入为 FC I 层的输出,SeNet34/50 的嵌入为平均池化层的输出。将x-vector与防伪嵌入连接后,增加 FC II层对组合嵌入降维,然后连接到后端分类器。LightCNN 和 SeNet34/50采用 E-XA 方法的网络配置详见表1。
方案三:引入注意力机制的嵌入阶段x-vectors辅助(E-XA with Attention Mechanism,E-XA-Att)
在 E-XA 的基础上,为了使神经网络更好地融合说话人信息和防伪信息,对两部分嵌入赋予注意力权值,权值通过网络训练学习到。防伪嵌入 E 和说话人嵌入 P 先由图1(d) 中名为“Transformer Layer” 的全连接层投影到公共嵌入空间,然后两个新嵌入分别归一化。归一化步骤对于提高系统性能至关重要,使得 Softmax 操作后的权重分配更有意义。将它们连接在一起后,输入到 “Attention Layer” 中计算注意力权重。两个嵌入乘上相应权重再相加输入到后端分类器。LightCNN 和 SeNet34/50 采用E-XA-Att 方法的网络配置详见表1。
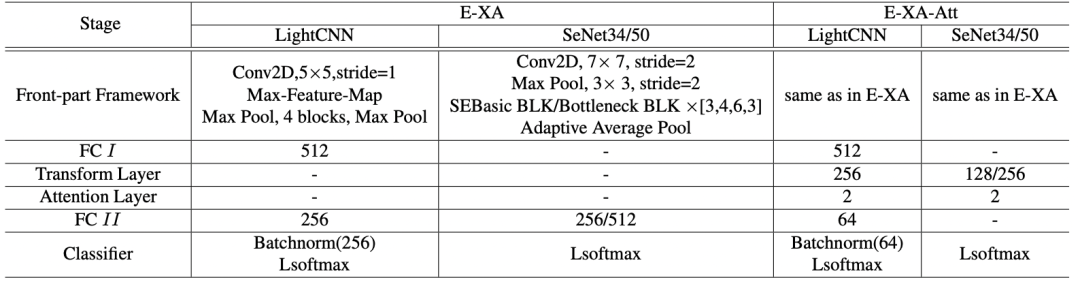
表1 使用 E-XA 相关方法的 LightCNN 和 SeNet34/50 网络配置。表中阶段 2-5 的数字指的是全连接层的节点数。“-”表明没有这一层。
实验结果分析
实验使用ASVspoof 2019 LA数据集[4]对上述模型方案展开训练和测试,表2列出了本文提出系统的输入特征、鉴伪模型、说话人信息辅助方案、参数量以及在ASVspoof 2019 LA开发和测试数据集上的性能,同时与现有的一些优秀鉴伪系统进行对比。其中串联决策成本函数 (Tandem Decision Cost Function,t-DCF)[5]为评估组合系统性能的主要指标,EER评估鉴伪系统性能。
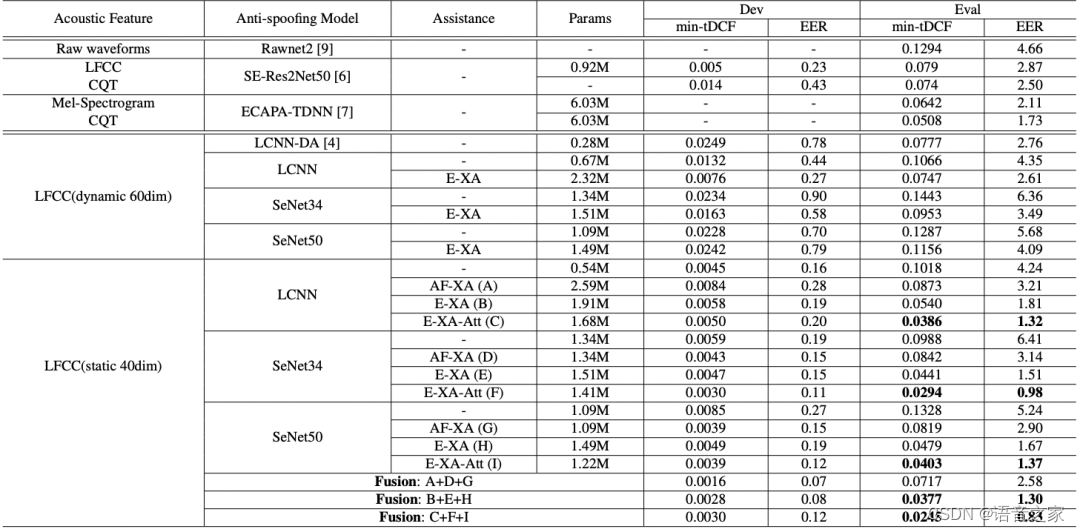
表2 x-vectors辅助的各种语音鉴伪系统在 ASVspoof 2019 LA 数据集上的 EER(%)
引入 AF-XA 后, LightCNN,SeNet34 和 SeNet50 使 EER 分别降低 24%、51%和44%。E-XA 方案更有效,三套鉴伪模型分别获得 57%、76%和68%的相对改善。在 E-XA 的方案基础上进一步挖掘说话人信息辅助的潜力,提出为说话人嵌入和鉴伪嵌入的连接增加注意力机制,让网络自行学习鉴伪任务对两者的需求程度。实验表明,E-XA 引入注意力机制后,系统的 EER 又进一步降低了 30% 左右,而对于 E-XA-Att 方案对两个嵌入分别归一化的操作对系统性能至关重要。
x-vectors有效辅助语音鉴伪系统的原因分析
从上述实验结果可知,说话人信息x-vectors强有力地辅助了语音鉴伪系统的性能提升。为了进一步分析原因,在 ASVspoof 2019 LA 训练集和测试集中各随机选择三位说话人,对他们的真假音频提取相应的说话人嵌入,并将这些说话人嵌入的分布利用 t-SNE 方法绘图观察。图2为训练集中 LA_0079、LA_0086、LA_0093 三位说话人各自真假音频提取的 x-vectors 分布,图 3为测试集中 LA_0001、LA_0026、LA_0038 三位说话人三位说话人各自真假音频提取的 x-vectors 分布。两图中不同颜色的叉号表示假音频不同的造假方式,绿色圆点代表真音频。
由两图可以发现,同一说话人真假音频提取的说话人嵌入在图中分布有较大区分度,不同生成方式的假音频说话人嵌入也有明显不同。说话人嵌入能将大部分假音频与真音频区分开,为语音鉴伪系统提供了具有强辨别力的信息,因而可以有效提升语音鉴伪系统性能。
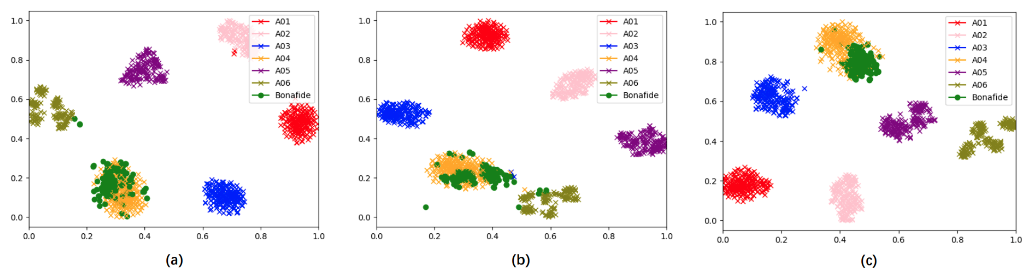
图2 ASVspoof 2019 LA 训练集中 (a)LA_0079 (b)LA_0086 (c)LA_0093 三位说话人真假音频说话人嵌入分布
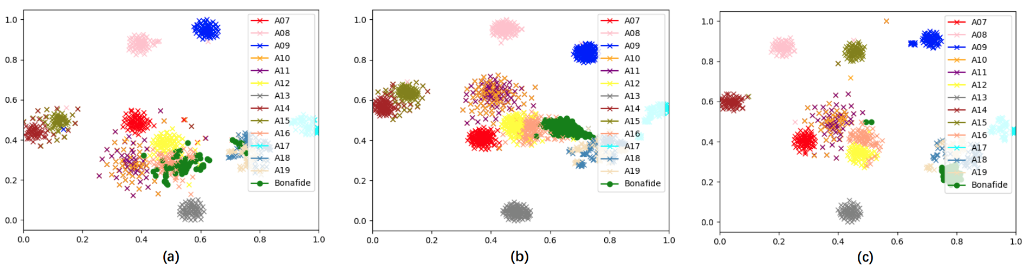
图3 ASVspoof 2019 LA 测试集中 (a)LA_0001 (b)LA_0026 (c)LA_0038 三位说话人真假音频说话人嵌入分布
小结
本文提出了三种说话人信息x-vectors辅助语音鉴伪模型的有效方案,对语音鉴伪基线系统使用AF-XA可实现 EER 20-50%的相对性能提升,使用E-XA可实现50%以上的性能提升,使用E-XA-Att提升效果会更好。通过实验结果和t-SNE可视化绘图分析都证明了引入说话人信息x-vectors对语音鉴伪任务大有益处。最佳鉴伪系统为SeNet34使用E-XA-Att方案在ASVspoof 2019 LA测试集上EER=0.98%,min-tDCF=0.0294。所提出的方案不仅适用于论文中的LightCNN和SeNet基线系统,还可以作为通用方案拓展到其它鉴伪模型中。
参考资料
[1] David Snyder, Daniel Garcia-Romero, Daniel Povey, and Sanjeev Khudanpur, “Deep Neural Network Embeddings for Text-Independent Speaker Verification,” in Interspeech, 2017, pp. 999–1003.
[2] Xinyue Ma, Tianyu Liang, Shanshan Zhang, Shen Huang, and Liang He, “Improved LightCNN with Attention Modules for ASV Spoofing Detection,” in 2021 IEEE International Conference on Multimedia and Expo (ICME), 2021.↳
[3] Lai C I, Chen N, Villalba J, et al. "ASSERT: Anti-spoofing with squeeze-excitation and residual networks," in Interspeech, 2019, pp. 1013–1017.
[4] ASVspoof 2019: Automatic speaker verification spoofing and countermeasures challenge evaluation plan.[Online].Available: http://www.asvspoof.org/asvspoof2019/ asvspoof2019 evaluation plan.pdf.
[5] Kinnunen T , Delgado H , Evans N , et al. "Tandem Assessment of Spoofing Countermeasures and Automatic Speaker Verification: Fundamentals." IEEE/ACM Transactions on Audio, Speech, and Language Processing, 10.1109/TASLP.2020.3009494. 2020.

