
- 1IT的季节——2004年11月无忧指数IT篇
- 2ADB常用命令整理(全网最全)_adb命令大全详解
- 3100ask七天物联网训练营学习笔记 - 裸机程序框架设计
- 4【自学记录7】【Pytorch2.0深度学习从零开始学 王晓华】第七章 实战ResNet_pytorch2.0深度学习从零开始学 随书源码
- 5数据治理与人工智能:合作与挑战
- 6python中关于Opencv中关于矩形的函数总结
- 7上位机图像处理和嵌入式模块部署(h750 mcu和usb虚拟串口)
- 8论文阅读:Memory Networks_deep memory connected network
- 9自然语言处理中的文本生成技术的未来趋势_nlp文本生成
- 10uView,uinput设置为disabled禁用后点击事件click失效的问题及解决_uview中disabled
基于聚类算法完成航空客户价值分析任务_基于聚类算法完成航空公司客户价值分析
赞
踩
1、背景与挖掘目标
1.1 案例背景
- 著名的“二八”定律

- 二八定律:20%的客户,为企业带来约80%的利益。
- 在企业与客户关系管理中,对客户分类,区分不同价值的客户。针对不同价值的客户提供个性化服务方案,采取不同的营销策略,将有限营销资源集中与高价值客户,实现企业利润最大化目标。
- 在竞争激烈的航空市场离,很多航空公司都推出了优惠的营销方式来吸引更多的客户。在此种环境下,如何将公司有限的资源充分利用,提升企业竞争力,为企业带来更多的经济效应。
1.2 传统方法存在的缺陷
广泛应用与分析客户价值的模型是RFM模型,它是通过三个指标(最近消费时间间隔(Recency)、消费频率(Frequency)、消费金额(Monetary))来进行客户细分,识别出高价值的客户。如果对航空公司客户价值进行分析,该模型存在一定的缺陷:
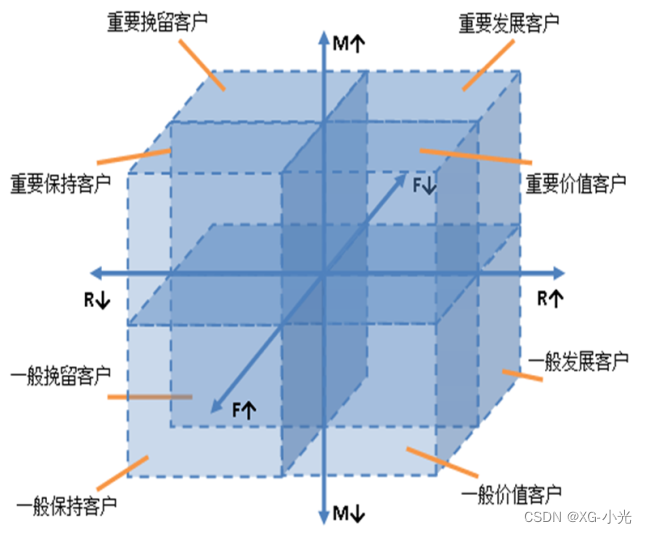
在模型中,消费金额表示在一段时间内,客业产品金额的总和。因航空票价受到运输距离、舱位等级等多种因素影响,同样消费金额的不同旅客对航空公司的价值是不同的。因此这个指标并不适合用于航空公司的客户价值分析。
传统模型分析是利用属性分箱方法进行分析如图,但是此方法细分的客户群太多,需要一一识别客户特征和行为,提高了针对性营销的成本。
1.3 任务描述
信息时代的来临使得企业营销焦点从产品中心转变成客户中心。具体地,对不同的客户进行分类管理,**给予不同类型的客户制定优化的个性化服务方案,采取不同的营销策略。**将有限的营销资源集中于高价值的客户,实现企业利润最大化。因此,如何对客户进行合理的分类成为了管理中亟需解决的关键问题之一。航空公司能够获取到客户的多种信息与行为数据,我们需要根据这些数据来实现以下目标:
- 借助航空公司数据,对客户进行分类;
- 对不同类别的客户进行特征分析,比较不同类别客户的价值;
- 对不同价值的客户类别进行个性化服务,制定相应的营销策略。
1.4 数据集字段含义
航空公司包含的客户信息包含了有44种属性,具体的每种属性对应的含义如下图所示。
| 客户基本信息 | MEMBER_NO | 会员卡号 |
|---|---|---|
| FFP_DATE | 入会时间 | |
| GENDER | 性别 | |
| FFP_TIER | 会员卡级别 | |
| WORK_CITY | 工作地城市 | |
| WORK_PROVINCE | 工作地所在省份 | |
| WORK_COUNTRY | 工作地所在国家 | |
| AGE | 年龄 | |
| 乘客信息 | FIRST_FLIGHT_DATE | 第一次飞行时间 |
| LOAD_TIME | 观测窗口的结束时间 | |
| FLIGHT_COUNT | 飞行次数 | |
| SUM_YR_1 | 第一年总票价 | |
| SUM_YR_2 | 第二年总票价 | |
| SEG_KM_SUM | 观测窗口总飞行公里数 | |
| WEIGHTED_SEG_KM | 观测窗口总加权飞行公里数(Σ舱位折扣×航段距离) | |
| LAST_FLIGHT_DATE | 末次飞行日期 | |
| AVG_FLIGHT_COUNT | 观测窗口季度平均飞行次数 | |
| BEGIN_TO_FIRST | 观测窗口第一次乘机时间至MAX(观测窗口时段,入会时间)时长 | |
| LAST_TO_END | 最后一次乘机时间至观测窗口末端时长 | |
| AVG_INTERVAL | 平均乘机时间间隔 | |
| MAX_INTERVAL | 观测窗口内最大时间间隔 | |
| avg_discount | 平均折扣率 | |
| P1Y_Flight_Count | 第一年乘机次数 | |
| L1Y_Flight_Count | 第二年乘机次数 | |
| Ration_L1Y_Flight_Count | 第二年的乘机次数比率 | |
| Ration_P1Y_Flight_Count | 第一年乘机的次数比率 | |
| 积分信息 | EXCHANGE_COUNT | 积分兑换次数 |
| AVG_BP_SUM | 观测窗口季度平均基本积分累计 | |
| BP_SUM | 观测窗口总基本积分 | |
| EP_SUM_YR_1 | 第一年精英资格积分 | |
| EP_SUM_YR_2 | 第二年精英资格积分 | |
| ADD_POINTS_SUM_YR_1 | 观测窗口中第一年其他积分 | |
| ADD_POINTS_SUM_YR_2 | 观测窗口中第二年其他积分 | |
| P1Y_BP_SUM | 第一年里程积分 | |
| L1Y_BP_SUM | 第二年里程积分 | |
| EP_SUM | 观测窗口总精英积分 | |
| ADD_Point_SUM | 观测窗口中其他积分 | |
| Eli_Add_Point_SUM | 非乘机积分总和 | |
| L1Y_ELi_Add_Points | 第二年非乘机积分总和 | |
| Points_Sum | 总累计积分 | |
| L1Y_Points_Sum | 第二年观测窗口总累计积分 | |
| Ration_P1Y_BPS | 第一年里程积分占最近两年积分比例 | |
| Ration_L1Y_BPS | 第二年里程积分占最近两年积分比例 | |
| Point_NotFlight | 非乘机的积分变动次数 |
- 观测窗口:以过去某个时间点为结束时间,某一时间长度作为宽度,得到历史时间范围内的一个时间段;
- 客户信息属性说明:针对航空客户的信息,对每个属性进行相应说明;
- 乘客信息:包含会员档案信息和其乘坐航班记录等。
2、分析方法与过程
2.1 初步分析
提出适用于航空公司的LRFMC模型
- 因消费金额指标在航空公司中不适用,故选择客户在一定时间内累积的飞行里程M和客户乘坐舱位折扣系数的平均值C两个指标代替消费金额。此外,考虑航空公司会员加入时间在一定程度上能够影响客户价值,所以在模型中增加客户关系长度L,作为区分客户的另一指标,因此构建出LRFMC模型。
- 采用聚类的方法对客户进行细分,并分析每个客户群的特征,识别其客户价值。
2.2 总体流程
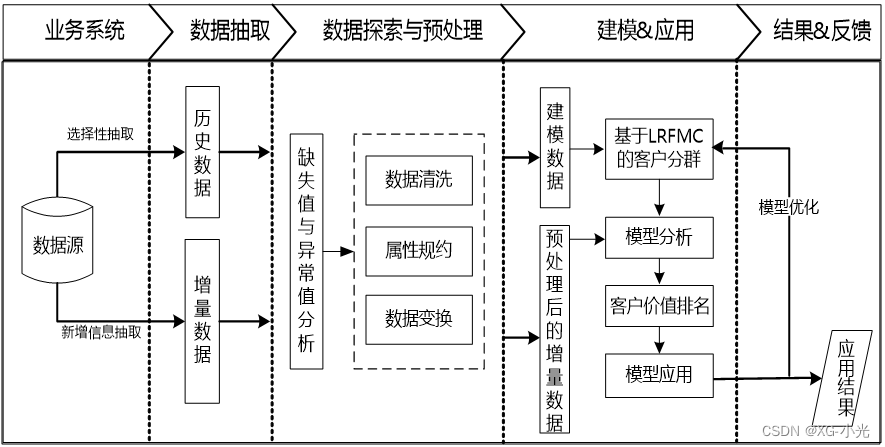
2.3 具体过程
2.3.1 数据探索
以2014-03-31为结束时间,选取宽度为两年的时间段作为分析观测窗口,抽取观测窗口内有乘机记录的所有客户的详细数据形成历史数据。对于后续新增的客户详细信息,利用其数据中最大的某个时间点作为结束时间,采用上述同样的方法进行抽取,形成增量数据。
导入需要的模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import datetime
import sklearn.preprocessing
import sklearn.cluster
- 1
- 2
- 3
- 4
- 5
- 6
读取CSV格式数据,每一行代表一个客户,每一列代表一个属性字段
根据末次飞行日期,从航空公司系统内抽取2012-04-01至2014-03-31内所有乘客的详细数据,总共62988条记录。
#读取CSV格式数据,每一行代表一个客户,每一列代表一个属性字段
air_data_path = 'C:/Users/zhzg/Downloads/基于聚类算法完成航空客户价值分析任务-数据集/datasets/air_data.csv'
air_data = pd.read_csv(air_data_path)
print(air_data.shape)
- 1
- 2
- 3
- 4
预览前5条数据
#预览前5条数据
air_data.head(5)
- 1
- 2

#展示每列数据的类型
air_data.dtypes
#object类型代表文本,int64类型代表整数,float64类型代表浮点数,bool类型代表布尔值
- 1
- 2
- 3
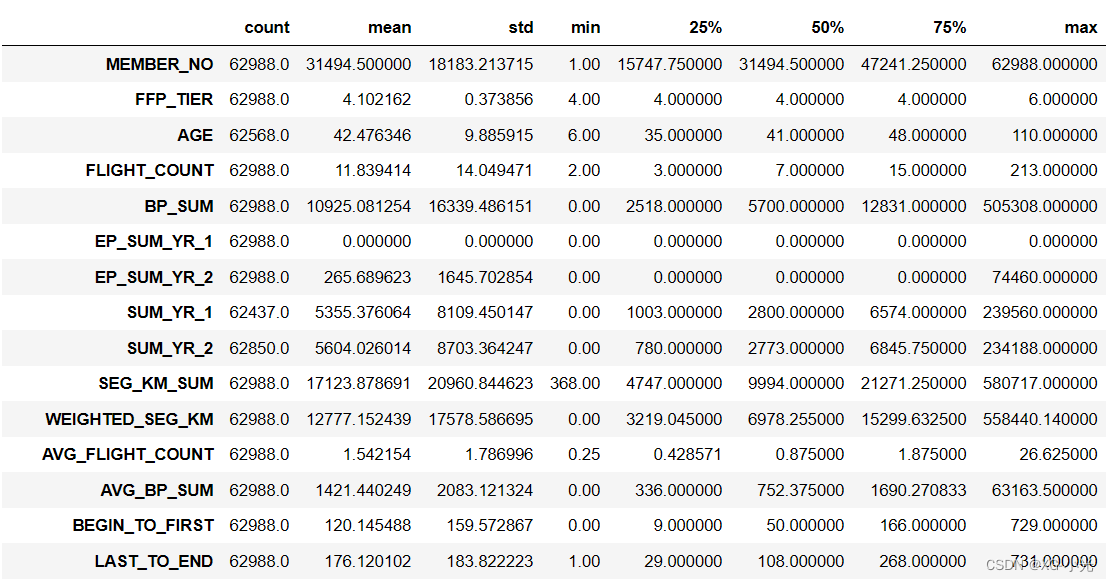
使用 pandas 中 DataFrame 的 describe() 函数表述数据的基本统计信息,对于数值型数据,输出结果指标包括count, mean,std,min,max以及第25百分位,中位数(第50百分位)和第75百分位。
原始数据中存在票价为空值,票价为空值的数据可能是客户不存在乘机记录造成。
票价最小值为0、折扣率最小值为0、总飞行公里数大于0的数据。其可能是客户乘坐0折机票或者积分兑换造成。
air_data.describe().T
- 1
2.3.2 数据预处理
数据清洗:从业务以及建模的相关需要方面考虑,筛选出需要的数据
- 丢弃票价为空的数据。
- 丢弃票价为0、平均折扣率不为0、总飞行公里数大于0的数据。
# 去除票价为空的记录
exp1 = airline_data["SUM_YR_1"].notnull()
exp2 = airline_data["SUM_YR_2"].notnull()
exp = exp1 & exp2
airline_notnull = airline_data.loc[exp]
print('删除缺失记录后数据的形状为:',airline_notnull.shape)
- 1
- 2
- 3
- 4
- 5
- 6
#只保留票价非零的,或者平均折扣率不为0且总飞行公里数大于0的记录。
index1 = airline_notnull['SUM_YR_1'] != 0
index2 = airline_notnull['SUM_YR_2'] != 0
index3 = (airline_notnull['SEG_KM_SUM']> 0) & \
(airline_notnull['avg_discount'] != 0)
airline = airline_notnull[(index1 | index2) & index3]
print('删除异常记录后数据的形状为:',airline.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.3.3 特征工程
变体 - LRFMC模型
在客户价值分析模型RFM模型的基础上上,加上了L客户关系时长以及C客户所享受的平均折扣率这两个特征用于客户分群与价值分析,得到航空行业的LRFMC模型:
Length of Relationship: 客户关系时长,反映可能的活跃时长。
Recency: 最近消费时间间隔,反映当前的活跃状态。
Frequency: 客户消费频率,反映客户的忠诚度。
Mileage: 客户总飞行里程,反映客户对乘机的依赖性。
Coefficient of Discount: 客户所享受的平均折扣率,侧面反映客户价值高低。
LRFMC 对应到数据集的字段
L = LOAD_TIME - FFP_DATE 会员入会时间距观测窗口结束的月数 = 观测窗口的结束时间 - 入会时间[单位:月]
R = LAST_TO_END 客户最近一次乘坐公司飞机距观测窗口结束的月数 = 最后一次乘机时间至观察窗口末端时长[单位:月]
F = FLIGHT_COUNT 客户在观测窗口内乘坐公司飞机的次数 = 观测窗口的飞行次数[单位:次]
M = SEG_KM_SUM 客户在观测时间内在公司累计的飞行里程 = 观测窗口总飞行公里数[单位:公里]
C = avg_discount 客户在观测时间内乘坐舱位所对应的折扣系数的平均值 = 平均折扣率[单位:无]
方法一:
# 构建L特征 L = LOAD_TIME - FFP_DATE
load_time = datetime.datetime.strptime('2014/03/31', '%Y/%m/%d')
ffp_dates = [datetime.datetime.strptime(ffp_date, '%Y/%m/%d') for ffp_date in air_data['FFP_DATE']]
length_of_relationship = [(load_time - ffp_date).days for ffp_date in ffp_dates]
air_data['LEN_REL'] = length_of_relationship
# 移除不需要的列,保留LRFMC模型需要的属性
features = ['LEN_REL','FLIGHT_COUNT','avg_discount','SEG_KM_SUM','LAST_TO_END']
data = air_data[features]
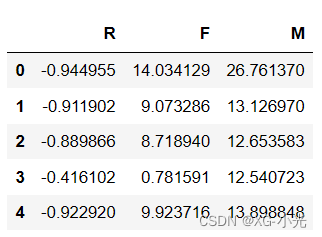
features = ['L','F','C','M','R']
data.columns = features
print(data.head(5))
data.describe().T
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
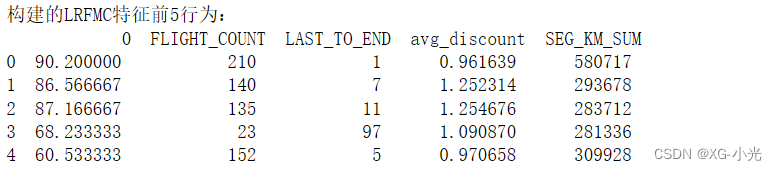
方法二:
airline_selection = airline[["FFP_DATE","LOAD_TIME", "FLIGHT_COUNT","LAST_TO_END", "avg_discount","SEG_KM_SUM"]] ## 构建L特征 L = pd.to_datetime(airline_selection["LOAD_TIME"]) - \ pd.to_datetime(airline_selection["FFP_DATE"]) L = L.astype("str").str.split().str[0] L = L.astype("int")/30 ## 合并特征 airline_features = pd.concat([L, airline_selection.iloc[:,2:]],axis = 1) print('构建的LRFMC特征前5行为:\n',airline_features.head(5)) ## 数据标准化 from sklearn.preprocessing import StandardScaler data = StandardScaler().fit_transform(airline_features)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
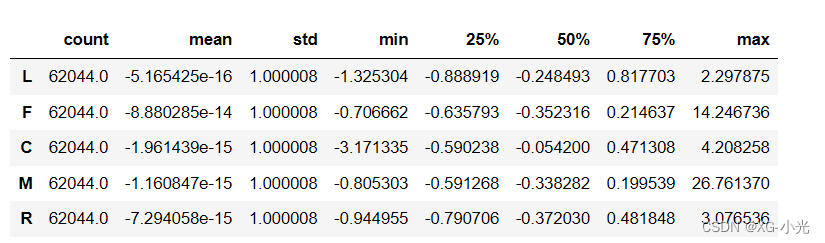
2.3.4 标准化
对特征进行标准化,使得各特征的均值为 0、方差为 1。下一个代码块等同于以下语句
# data = (data - data.mean(axis=0))/(data.std(axis=0))
ss = sklearn.preprocessing.StandardScaler(with_mean=True, with_std=True)#标准化
data = ss.fit_transform(data) #数据转换
data = pd.DataFrame(data, columns=features)
data_db = data.copy()
# 描述标准化后的数据的元数据。
data.describe().T
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.3.5 构建模型
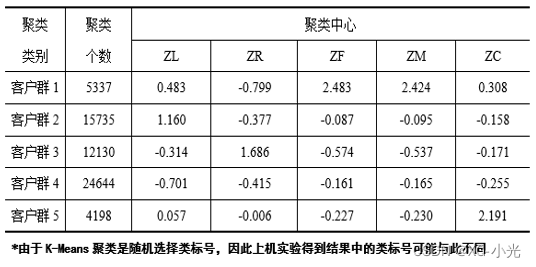
采用K-Means聚类算法对客户数据进行分群,将其聚成五类(需要结合业务的理解与分析来确定客户的类别数量)。我将客户群体细分为重要保持客户、重要发展客户、重要挽留客户、一般客户、低价值客户五类。
K-Means聚类算法:
- 选择初始化的 k 个样本作为初始聚类中心 a=a1,a2,…ak ;
- 针对数据集中每个样本 xi 计算它到 k 个聚类中心的距离并将其分到距离最小的聚类中心所对应的类中;
- 针对每个类别 aj ,重新计算它的聚类中心 aj=1|ci|∑x∈cix (即属于该类的所有样本的质心);
- 重复上面 2 3 两步操作,直到达到某个中止条件(迭代次数、最小误差变化等)。
LCRFM模型:
num_clusters = 5 #设置类别为5
km = sklearn.cluster.KMeans(n_clusters=num_clusters, n_jobs=4) #模型加载
km.fit(data) #模型训练
- 1
- 2
- 3
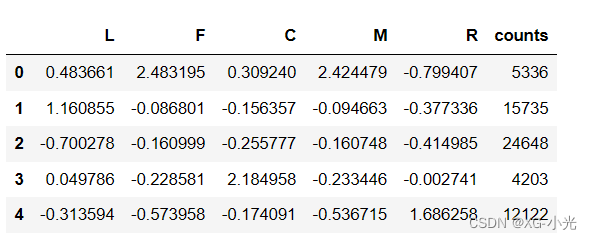
查看模型学习出来的5个群体的中心,以及5个群体所包含的样本个数。
r1 = pd.Series(km.labels_).value_counts()
r2 = pd.DataFrame(km.cluster_centers_)
r = pd.concat([r2, r1], axis=1)
r.columns = list(data.columns) + ['counts']
r
- 1
- 2
- 3
- 4
- 5
查看模型对每个样本预测的群体标签。
km.labels_
- 1
使用Calinski-Harabasz指数评价法对LCRFM模型进行评价。
## 模型评价 Calinski-Harabasz指数评价法 越大越好
from sklearn.metrics import calinski_harabasz_score
calinski_harabasz_score(data,km.labels_)
- 1
- 2
- 3
RFM模型
#尝试使用RFM模型
data_rfm = data[['R','F','M']]
data_rfm.head(5)
- 1
- 2
- 3
km.fit(data_rfm)#模型只对包含rfm数据集训练
- 1
查看模型对每个样本预测的群体标签。
km.labels_
- 1
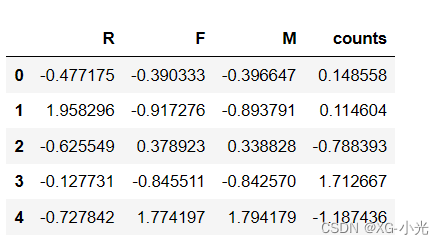
查看模型学习出来的3个群体的中心,以及3个群体所包含的样本个数。
r1 = pd.Series(km.labels_).value_counts()
r2 = pd.DataFrame(km.cluster_centers_)
rr = pd.concat([r2,r1],axis=1)
rr = pd.DataFrame(ss.fit_transform(rr))
rr.columns = list(data_rfm.columns)+['counts']
rr
- 1
- 2
- 3
- 4
- 5
- 6
使用Calinski-Harabasz指数评价法对RFM模型进行评价。
calinski_harabasz_score(data,km.labels_)
- 1
2.3.5 分析与决策
利用雷达图对LCRFM模型学习出的5个群体特征进行可视化分析。
## 导入模块 import numpy as np import matplotlib.pyplot as plt from matplotlib.patches import Circle, RegularPolygon from matplotlib.path import Path from matplotlib.projections.polar import PolarAxes from matplotlib.projections import register_projection from matplotlib.spines import Spine from matplotlib.transforms import Affine2D def radar_factory(num_vars, frame='circle'): # 计算得到evenly-spaced axis angles theta = np.linspace(0, 2*np.pi, num_vars, endpoint=False) class RadarAxes(PolarAxes): name = 'radar' # 使用1条线段连接指定点 RESOLUTION = 1 def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) # 旋转绘图,使第一个轴位于顶部 self.set_theta_zero_location('N') def fill(self, *args, closed=True, **kwargs): """覆盖填充,以便默认情况下关闭该行""" return super().fill(closed=closed, *args, **kwargs) def plot(self, *args, **kwargs): """覆盖填充,以便默认情况下关闭该行""" lines = super().plot(*args, **kwargs) for line in lines: self._close_line(line) def _close_line(self, line): x, y = line.get_data() # FIXME: x[0], y[0] 处的标记加倍 if x[0] != x[-1]: x = np.concatenate((x, [x[0]])) y = np.concatenate((y, [y[0]])) line.set_data(x, y) def set_varlabels(self, labels): self.set_thetagrids(np.degrees(theta), labels) def _gen_axes_patch(self): # 轴必须以(0.5,0.5)为中心并且半径为0.5 # 在轴坐标中。 if frame == 'circle': return Circle((0.5, 0.5), 0.5) elif frame == 'polygon': return RegularPolygon((0.5, 0.5), num_vars, radius=.5, edgecolor="k") else: raise ValueError("unknown value for 'frame': %s" % frame) def _gen_axes_spines(self): if frame == 'circle': return super()._gen_axes_spines() elif frame == 'polygon': # spine_type 必须是'left'/'right'/'top'/'bottom'/'circle'. spine = Spine(axes=self, spine_type='circle', path=Path.unit_regular_polygon(num_vars)) # unit_regular_polygon 给出以1为中心的半径为1的多边形 #(0,0),但我们希望以(0.5, # 0.5)的坐标轴。 spine.set_transform(Affine2D().scale(.5).translate(.5, .5) + self.transAxes) return {'polar': spine} else: raise ValueError("unknown value for 'frame': %s" % frame) register_projection(RadarAxes) return theta
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
LCRFM模型作图
N = num_clusters theta = radar_factory(N, frame='polygon') data = r.to_numpy() fig, ax = plt.subplots(figsize=(5, 5), nrows=1, ncols=1, subplot_kw=dict(projection='radar')) fig.subplots_adjust(wspace=0.25, hspace=0.20, top=0.85, bottom=0.05) # 去掉最后一列 case_data = data[:, :-1] # 设置纵坐标不可见 ax.get_yaxis().set_visible(False) # 图片标题 title = "LCRFM Radar Chart for Different Means" ax.set_title(title, weight='bold', size='medium', position=(0.5, 1.1), horizontalalignment='center', verticalalignment='center') for d in case_data: # 画边 ax.plot(theta, d) # 填充颜色 ax.fill(theta, d, alpha=0.05) # 设置纵坐标名称 ax.set_varlabels(features) # 添加图例 labels = ["CustomerCluster_" + str(i) for i in range(1,6)] legend = ax.legend(labels, loc=(0.9, .75), labelspacing=0.1) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
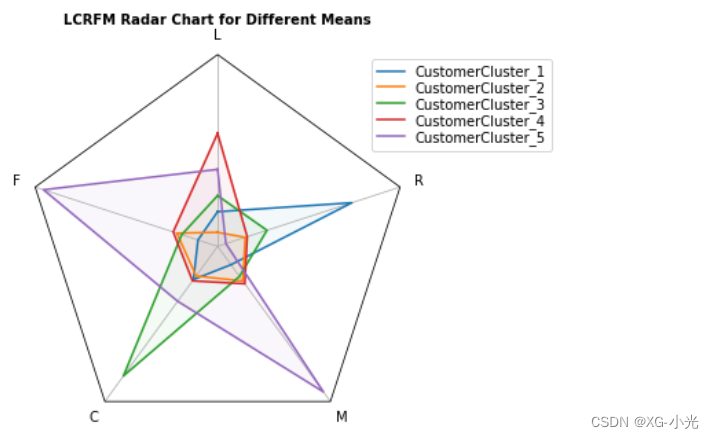
客户价值分析
对聚类结果进行特征分析,其中客户群1在F、M属性最大,在R属性最小;客户群2在L属性上最大;客户群3在R属性上最大,在F、M属性最小;客户群4在L、C属性上最小;客户群5在C属性上最大。
RFM模型作图
theta = radar_factory(3, frame='polygon') data = rr.to_numpy() fig, ax = plt.subplots(figsize=(5, 5), nrows=1, ncols=1, subplot_kw=dict(projection='radar')) fig.subplots_adjust(wspace=0.25, hspace=0.20, top=0.85, bottom=0.05) # 去掉最后一列 case_data = data[:, :-1] # 设置纵坐标不可见 ax.get_yaxis().set_visible(False) # 图片标题 title = "RFM Radar Chart for Different Means" ax.set_title(title, weight='bold', size='medium', position=(0.5, 1.1), horizontalalignment='center', verticalalignment='center') for d in case_data: # 画边 ax.plot(theta, d) # 填充颜色 ax.fill(theta, d, alpha=0.05) # 设置纵坐标名称 ax.set_varlabels(['R','F','M']) # 添加图例 labels = ["CustomerCluster_" + str(i) for i in range(1,6)] legend = ax.legend(labels, loc=(0.9, .75), labelspacing=0.1) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
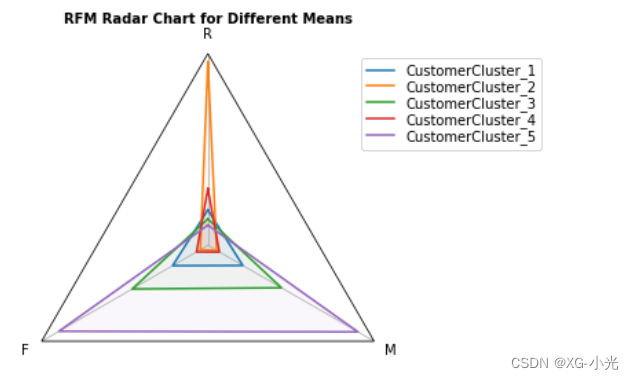
可以看出当使用RFM模型对用户进行划分时,我们可以考虑的参数(维度)较少,只有RFM三个维度,不能很好地对客户进行全面方面的分析。
DBSCAN模型对LCRFM特征进行计算
除了Kmeans聚类算法外,我们还可以使用DBSCAN等聚类算法进行建模。
from sklearn.cluster import DBSCAN
# db = DBSCAN(eps=10,min_samples=2).fit(data_db)
# Kagging debug
db = DBSCAN(eps=10,min_samples=2).fit(data_db.sample(10000))
DBSCAN_labels = db.labels_
DBSCAN_labels
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.3.6 根据LCRFM模型进行分析
根据业务定义五个等级的客户类别:重要保持客户、重要发展客户、重要挽留客户、一般客户、低价值客户。
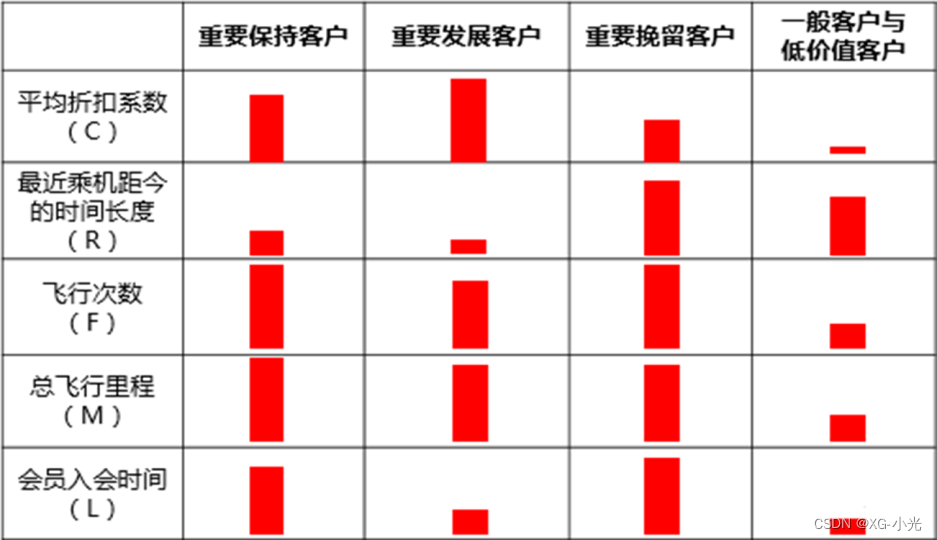
(1)重要保持客户
平均折扣系数较高(C↑),最近有乘机记录(R↓),飞行次数高(F↑),入会时间长(L↑)或总飞行里程高(M↑):
这类客户机票票价高,不在意机票折扣,乘机频率高,是公司最理想的客户类型。公司应优先将资源投放到他们身上,维持这类客户的忠诚度。
(2)重要发展客户
平均折扣系数高(C↑),最近有乘机记录(R↓),飞行次数较高(F↓)或总飞行里程较长(M↓):
这类客户机票票价高,不在意机票折扣,最近有乘机记录,但总里程相对重要保持客户偏低,具有非常大的发展潜力。公司应加强这类客户的满意度,使他们逐渐成为保持客户、忠诚客户。
(3)重要挽留客户
平均折扣系数较高(C↑),飞行次数高(F↑)或总飞行里程高(M↑),最近无乘机记录(R↑):
这类客户总里程高,飞行次数高,入会时间也长,但却较长时间没有乘机,判断客户可能处于流失状态。公司应加强与这类客户的互动,召回用户,使流失客户重新焕发价值。
(4)一般客户
平均折扣系数低(C↓),最近无乘机记录(R↑),飞行次数低(F↓)或总飞行里程低(M↓),入会时间短(L↓):
这类客户机票票价低,购买折扣机票,最近无乘机记录,客户可能是趁着机票折扣而选择购买,对品牌忠诚度较低。公司需要在资源支持的情况下强化对这类客户的联系。
(5)低价值客户
平均折扣系数低(C↓),最近有乘机记录(R↑),飞行次数高(F↓)或总飞行里程高(M↓),入会时间短(L↓):
这类客户与一般客户类似,机票票价低,经常够买折扣机票,最近无乘机记录,可能是趁着折扣而选择购买,对品牌无忠诚度。
3、决策
- 保持企业收入:维护好重要保持客户、重要发展客户的忠诚度,对这一类客户提供更加优质的乘机服务,对这一类客户赋予会员或会员升级,给予一定的会员福利提高客户与航空公司的粘性。
- 创造新的营收点:对重要挽留客户公司可以多跟客户进行联系,增强和公司和客户之间的互动,召回客户让挽留客户转回保持发展客户。
- 整体性布局:公司可以对热门航班不定期进行打折优惠,吸引更多的一般和低价值客户,同时提高航班的服务质量,将这两类客户进行转化;特惠机票同时也能给重要挽留客户带来吸引力,对重要保持和发展客户来说有优惠力度的机票也能让他们对航空公司更加满意。
学习——https://work.datafountain.cn/forum?id=67&type=2&source=1基于聚类算法完成航空客户价值分析任务

