
- 1FastMVSNet自定义测试数据集网络实现流程(二)_mvsnet训练自己的数据集
- 2Kafka学习---分区与副本原理解析_kafka分区和副本理解
- 3银行木马卷土重来、开发者破坏开源库影响数千应用程序|1月10日全球网络安全热点
- 4Redis-stack 初体验_redis stack
- 5[Bug0014] Hexo+Github 搭建博客报错 :remote: Support for password authentication was removed on August 13, ...
- 6Android网络基础1——网络分层_android 开发七层模型
- 7数据全生命周期保护基本要求_数据生命周期安全防护,2024年最新2024年展望网络安全原生开发的现状_数据安全 一般数据 全生命周期保护措施
- 8使用Docker Compose一键部署前后端分离项目(图文保姆级教程)_docker-compose部署前后端项目
- 9【利器篇】前端40+精选VSCode插件,总有几个你未拥有!_vscode 前端开发必备插件
- 10【2024浙江省蓝桥杯C++B组省赛】题解A-D(含题面)_有一个数组,包含 1 到 n 这 n 个整数,初始为一个从小到大的有序排列:{1, 2, 3
【JavaScript RegExp】正则表达式_js 使用 regexp 字符串匹配正则(1)_js 正则匹配括号
赞
踩
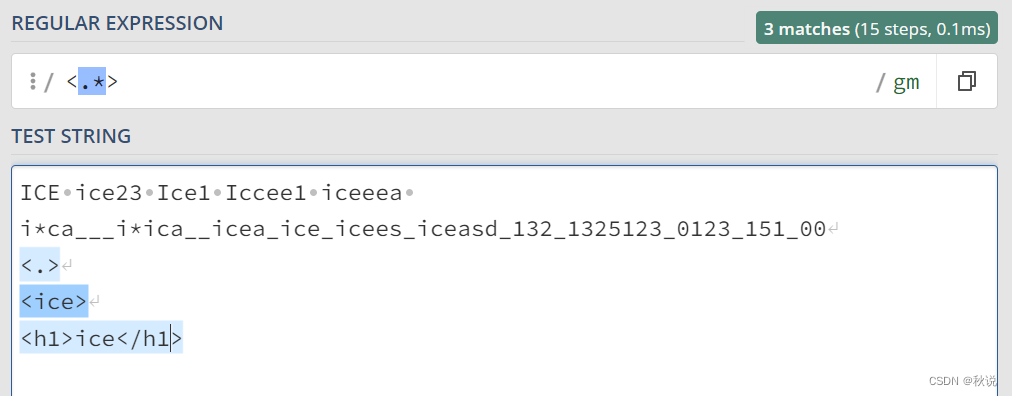
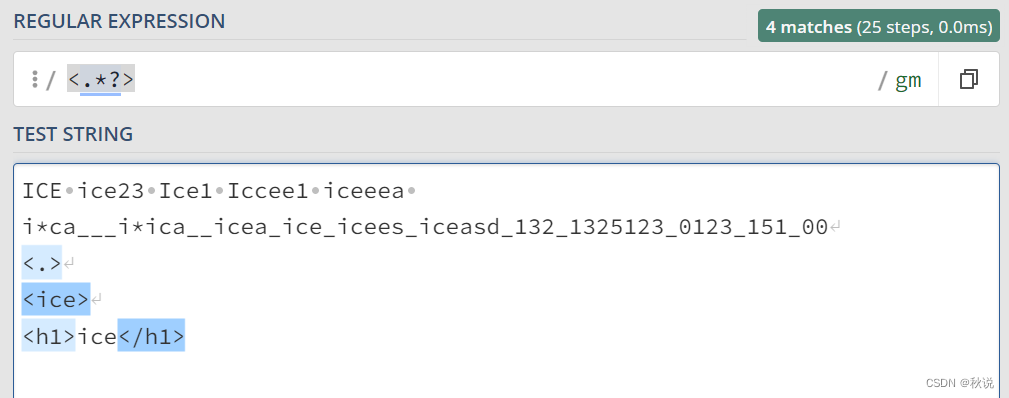
<.*?> 用于匹配最短的、非贪婪的以 < 开始、> 结束的字符串片段,通常用于匹配 HTML 或 XML 标签中的内容。
元字符
除了特殊字符外,正则表达式中还可以使用一些元字符、字符类、量词和定位符等来构建模式。(某些字符既可以是特色字符,也可以是其它字符等)
元字符是具有特殊含义的字符,它们用于构建正则表达式的基本模式。一些常见的元字符包括:.、^、$、\、|、[]、{}、() 等。
[]:字符类,用于匹配字符集合中的任意一个字符。例如,[abc] 匹配 a、b 或 c 中的任意一个。
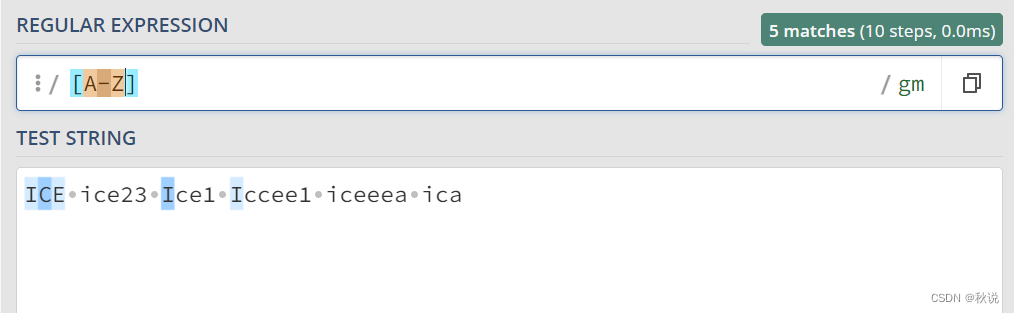
[A-Z]代表匹配所有大写字母,[a-z] 代表匹配所有小写字母。
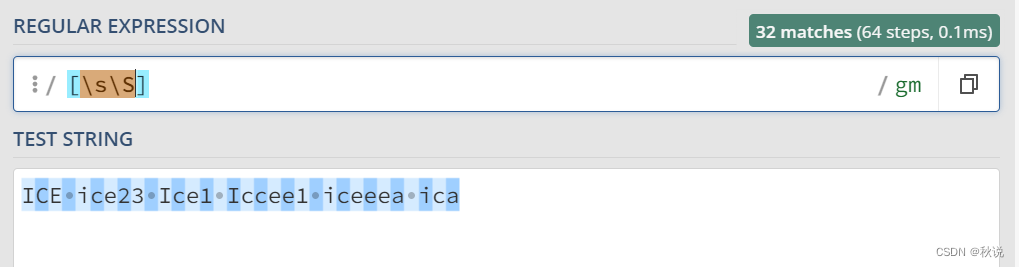
[\s\S] 代表匹配所有,\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。
{}:量词,用于指定匹配模式的重复次数。例如,a{2,4} 匹配连续出现 2 到 4 次的字符 a。
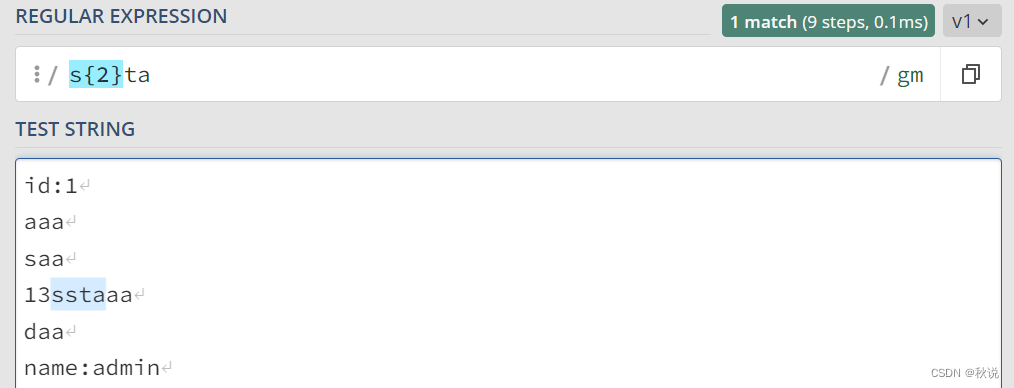
如果想设置 00~99 的两位数(至少1位,至多2位),可以写为如下形式:
[0-9]{1,2}
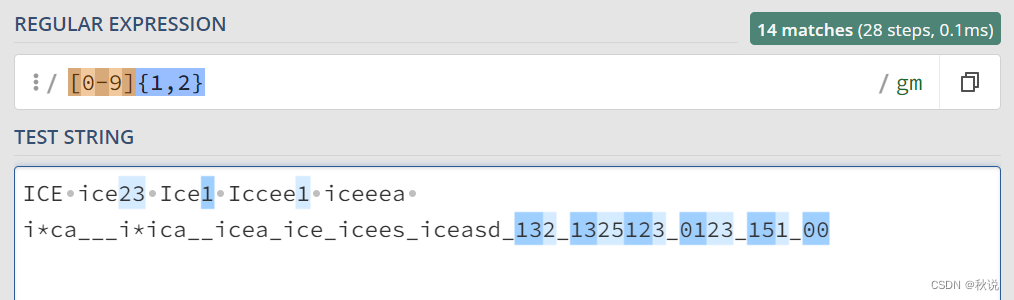
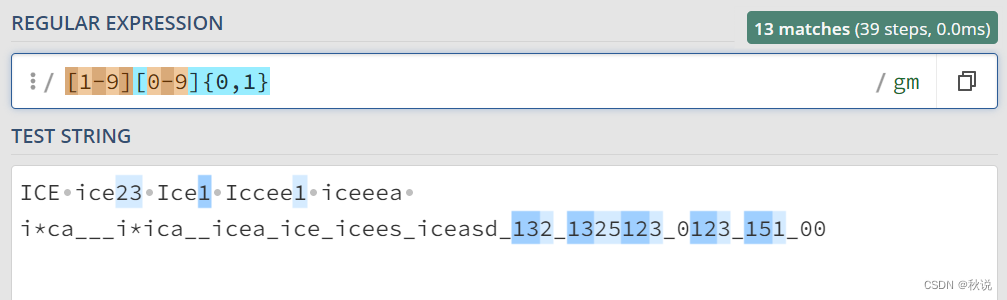
匹配 1~99 的正整数:
[1-9][0-9]{0,1}或[1-9][0-9]?
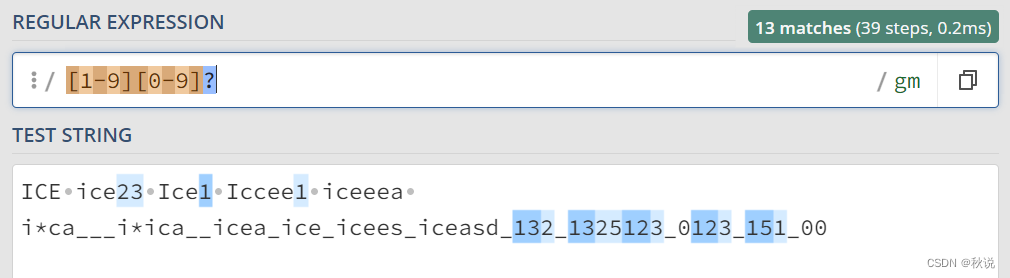
\b:单词边界,匹配单词的边界位置。
\B:非单词边界,匹配不是单词边界的位置。
\w 代表匹配字母、数字、下划线。等价于 [A-Za-z0-9_]
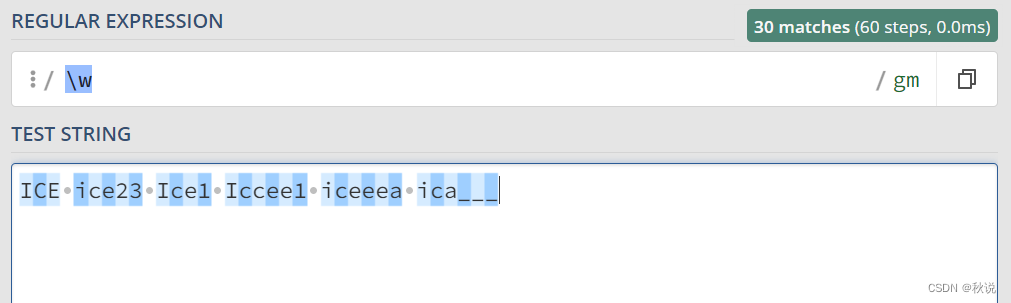
<\w>用于匹配含有一个字母、数字、下划线的标签<>
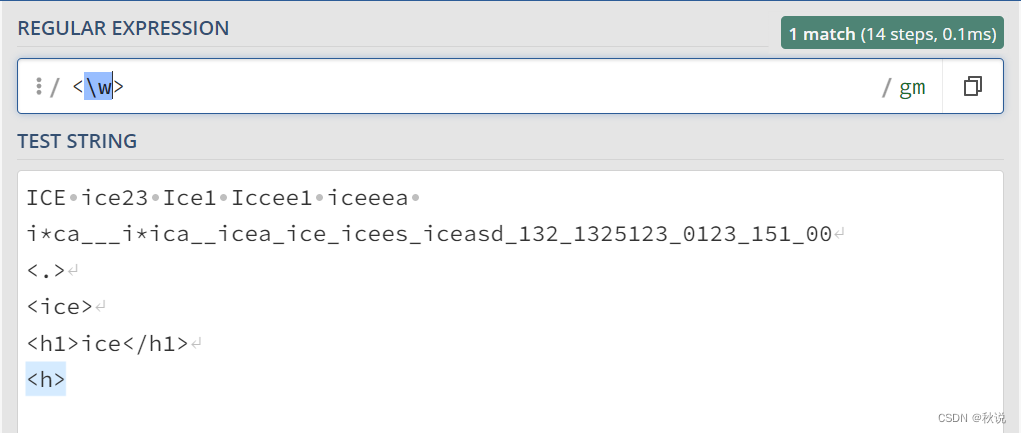
<\w+>用于匹配至少含有一个字母、数字、下划线的<>
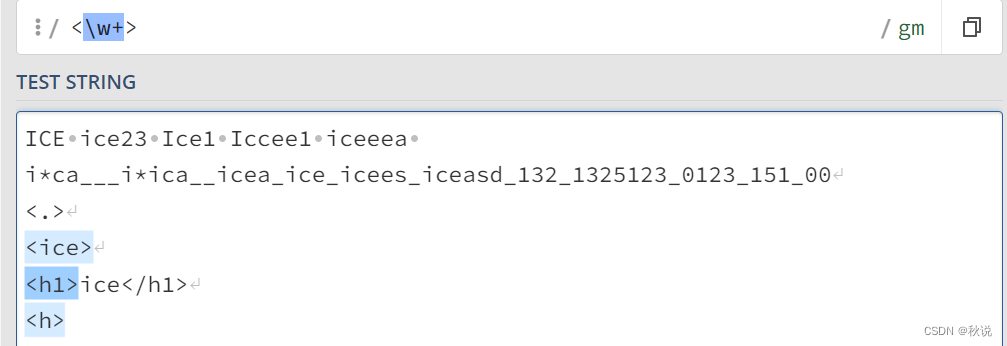
注意:这里没匹配到</h1>的原因是因为/w不能匹配斜杠
注意: 在字符集 [ ] 中,^ 具有特殊的含义,它用于表示取反操作,即匹配不在字符集内的字符。
例如,[^abc] 匹配任何一个不是 a、b 或 c 的字符
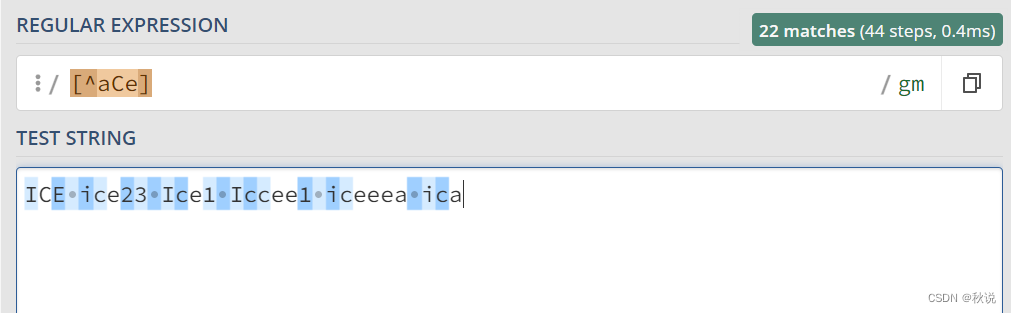
字符表格汇总
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置。 |
| * | 匹配前面的子表达式零次或多次。 |
| + | 匹配前面的子表达式一次或多次。 |
| ? | 匹配前面的子表达式零次或一次。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘s{2}’ 不能匹配 “asa” 中的 ‘s’,但是能匹配 “assd” 中的两个 s。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,‘s{2,}’ 不能匹配 “Bsa” 中的 ‘s’,但能匹配 “assssd” 中的所有 s。‘s{1,}’ 等价于 ‘s+’。‘s{0,}’ 则等价于 ‘s*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,“s{1,3}” 将匹配 “assssssd” 中的前三个 s。‘s{0,1}’ 等价于 ‘s?’。逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “ssss”,‘s+?’ 将匹配单个 “s”,而 ‘s+’ 将匹配所有 ‘s’。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符。 |
| (pattern) | 匹配 pattern 并获取这一匹配。 |
| (?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。例如,“Windows(?=95 |
| (?!pattern) | 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。例如"Windows(?!95 |
| (?<=pattern) | 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,"`(?<=95 |
| (?<!pattern) | 反向否定预查,与正向否定预查类似,只是方向相反。例如"`(?<!95 |
| x | y |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 “plain” 中的’p’、‘l’、‘i’、‘n’。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,‘[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B | 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]'。 |
| \W | 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,‘\x41’ 匹配 “A”。‘\x041’ 则等价于 ‘\x04’ & “1”。正则表达式中可以使用 ASCII 编码。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,‘(.)\1’ 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
特殊结构
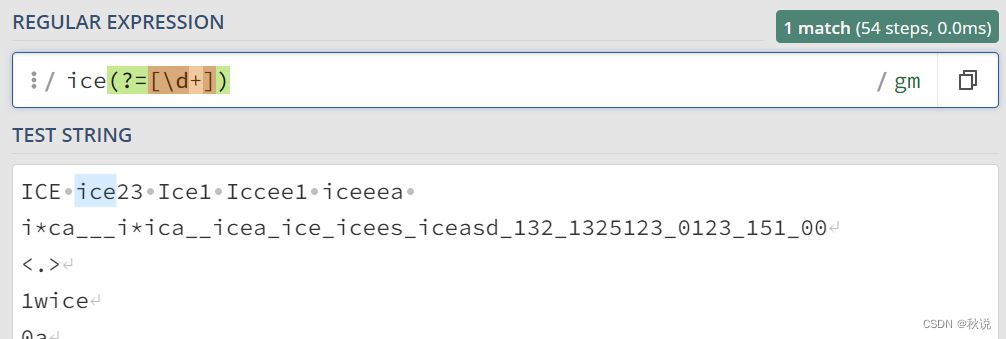
exp1(?=exp2):查找 exp2 前面的 exp1。
例如,ice(?=[\d+])匹配数字前面的ice字符串:
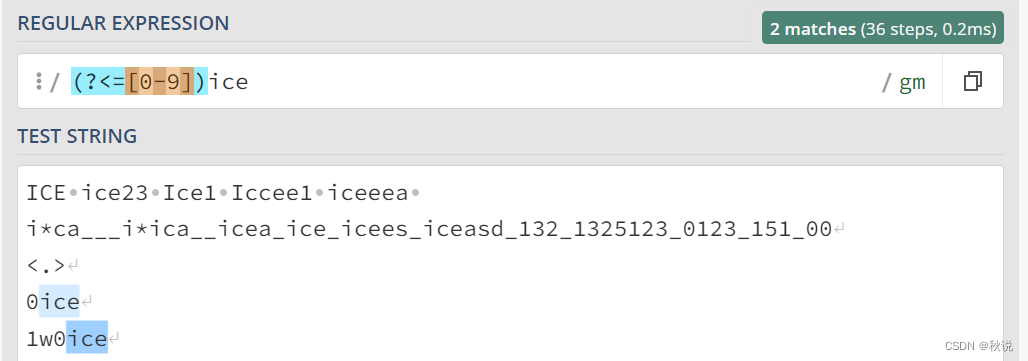
(?<=exp2)exp1:查找 exp2 后面的 exp1。
例如,(?<=[0-9])ice匹配数字后面的ice字符串:
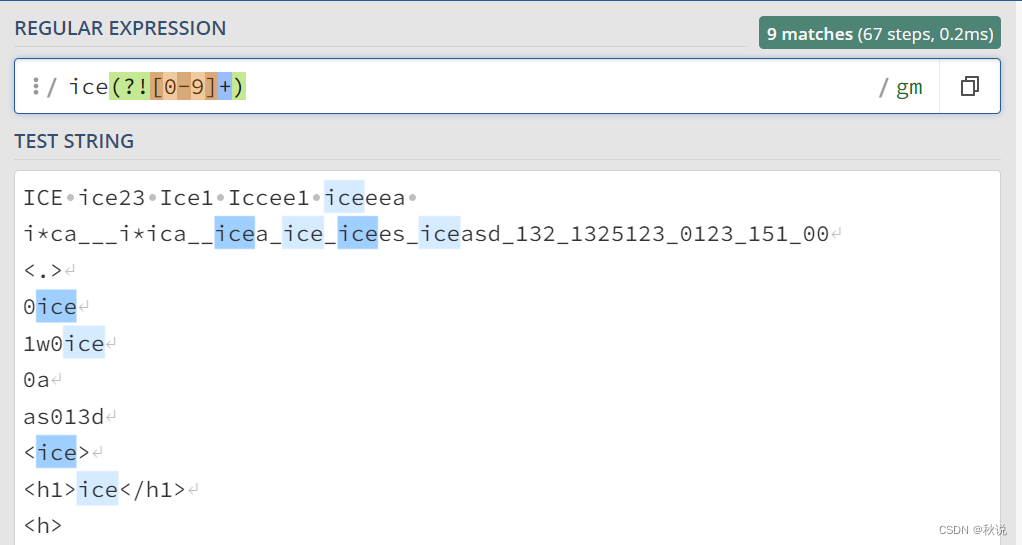
exp1(?!exp2):查找后面不是 exp2 的 exp1。
例如,ice(?![0-9]+)匹配ice字符串,但ice字符串的后面不是数字:
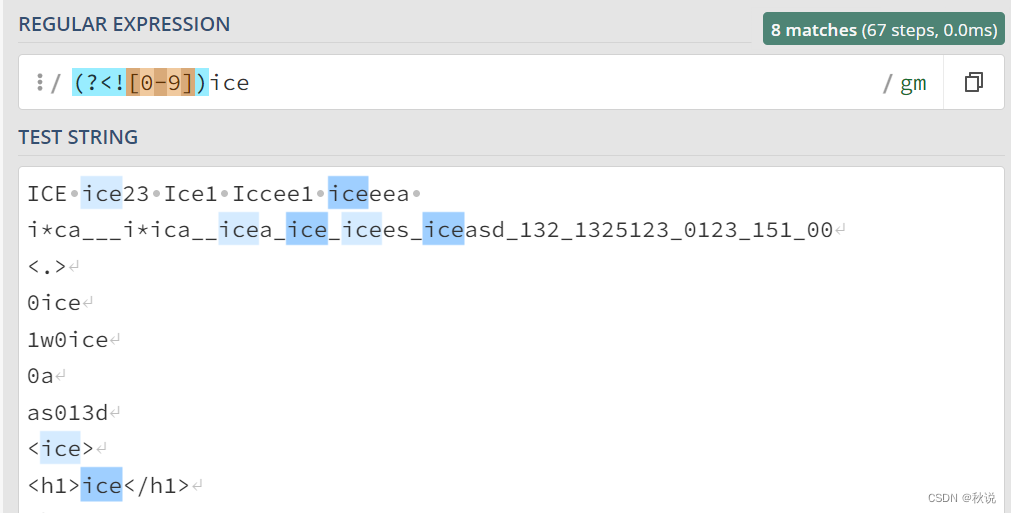
(?<!exp2)exp1:查找前面不是 exp2 的 exp1。
例如,(?<![0-9])ice匹配前面不是数字的ice字符串:
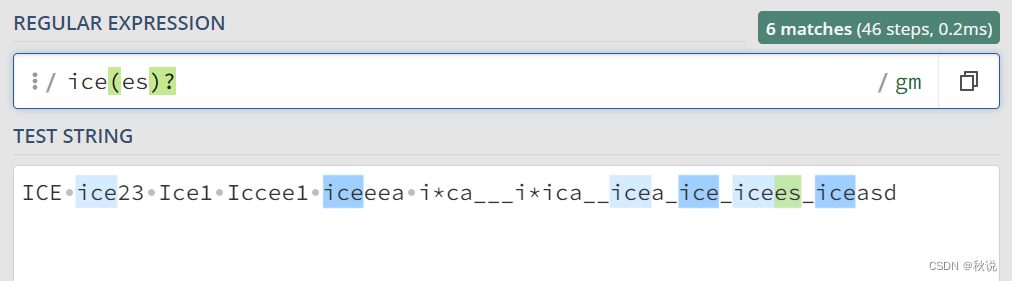
(exp)?:指示括号内的内容可选,即该内容可以出现零次或一次。
例如,ice(es)? 可以匹配 ice 、 iceasd 中的 ice 和icees中的 icees:
标记
标记也称为修饰符,用于指定额外的匹配策略。
| 修饰符 | 含义 | 描述 |
|---|---|---|
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。 |
| g | global - 全局匹配 | 查找所有的匹配项。 |
| m | multi line - 多行匹配 | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。 |
| s | 特殊字符圆点 . 中包含换行符 \n | 默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
标记不写在正则表达式里,标记位于表达式之外,格式如下:
/pattern/i
/pattern/g
/pattern/m
/pattern/s
- 1
- 2
- 3
- 4
- 5
g修饰符实例:
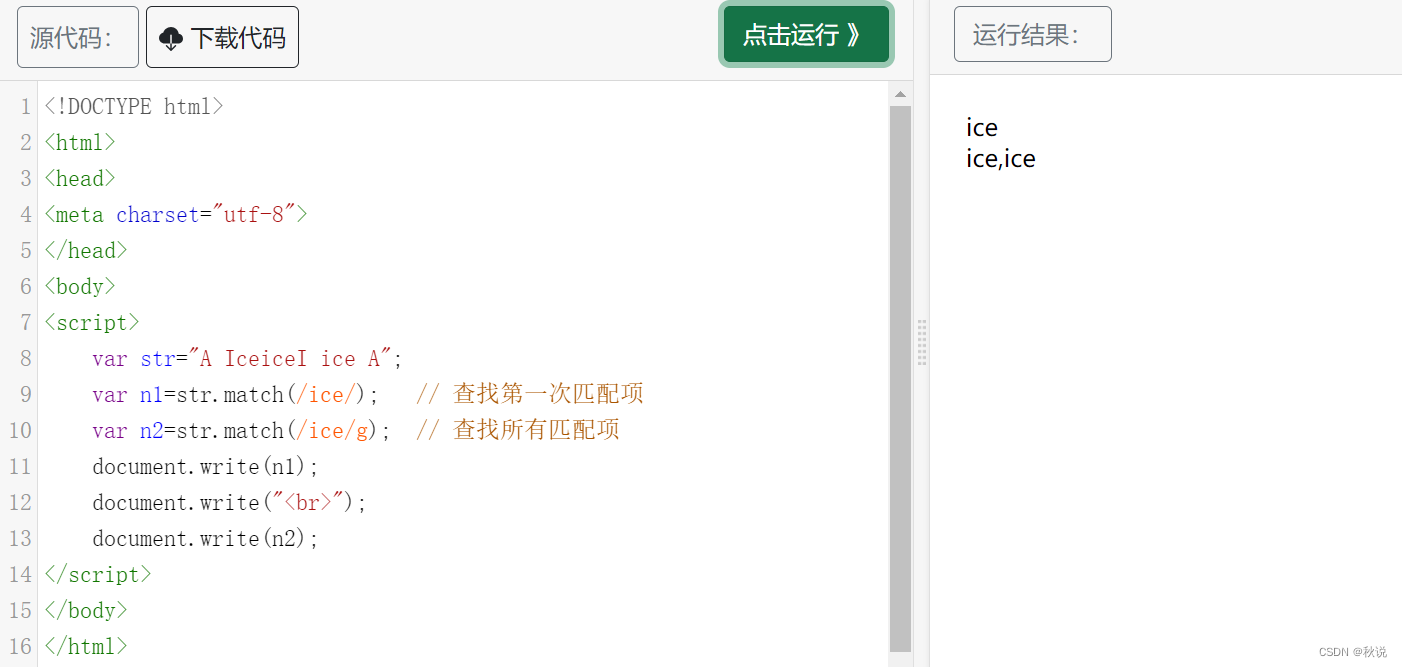
i 修饰符为不区分大小写匹配,实例(不区分大小写+全局匹配):
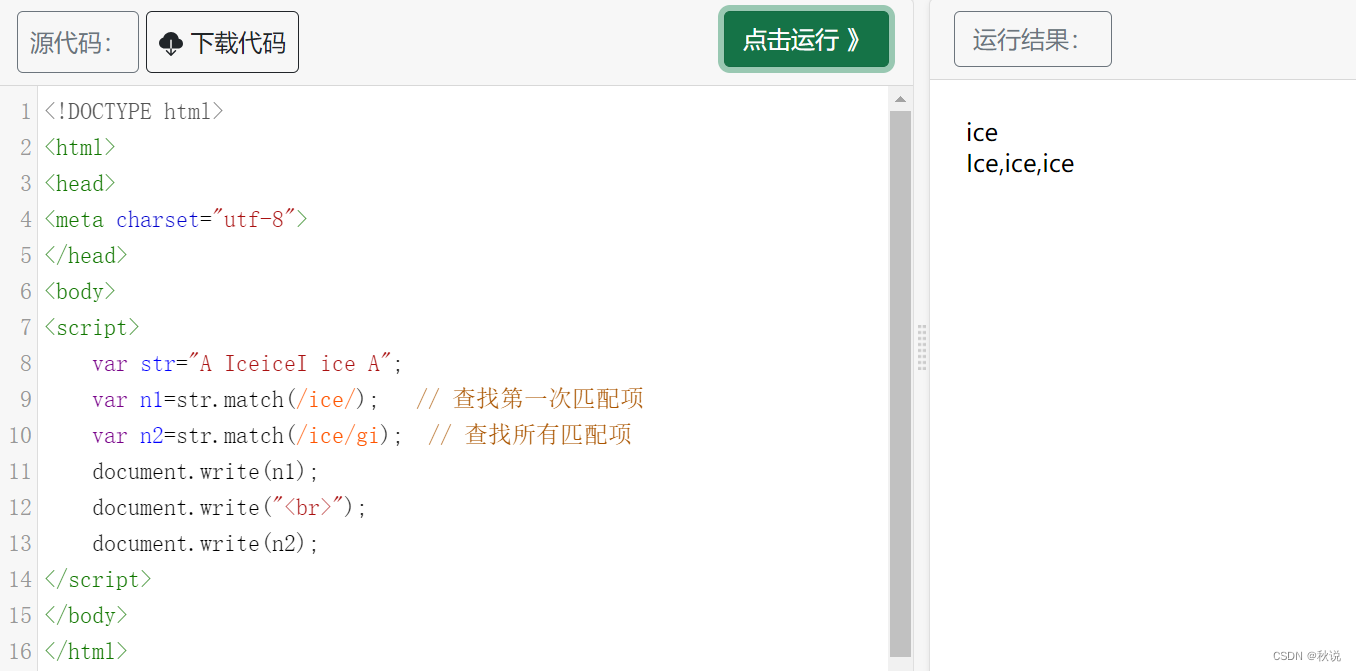
在 g 后添加 m 可以实现对每一行的匹配。
优先级
正则表达式从左到右进行计算,并遵循优先级顺序
| 运算符(由高到低) | 描述 |
|---|---|
| \ | \ 是用于转义其他特殊字符的转义符号;它具有最高的优先级;\d 匹配数字,\. 匹配点号。 |
(), (?:), (?=), [] | 圆括号和方括号。圆括号 () 用于创建子表达式,具有高于其他运算符的优先级。(abc)+ 匹配 “abc” 一次或多次。 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
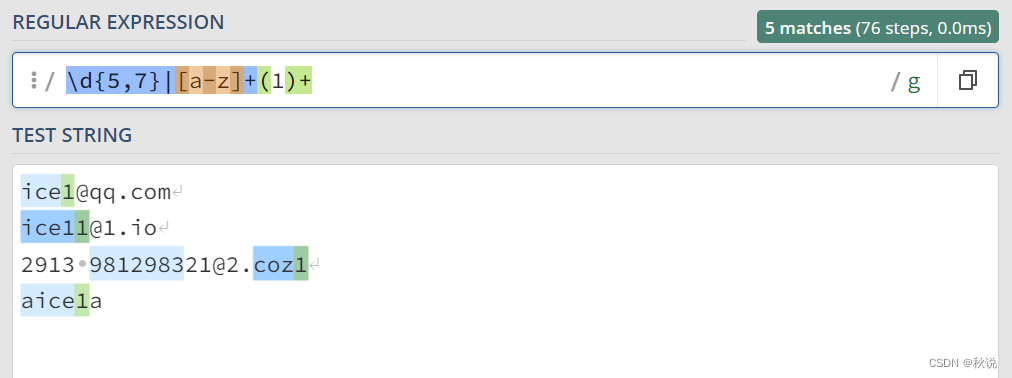
例如,\d{5,7}|[a-z]+(1)+
用于匹配5~7个数字 或 匹配任意个小写字母及其后面的至少1个数字:
实例
匹配常见的 HTTP 或 HTTPS URL
(\w+):\/\/([^\/:]+)(:\d*)?([^# ]*)
- 1
- 2
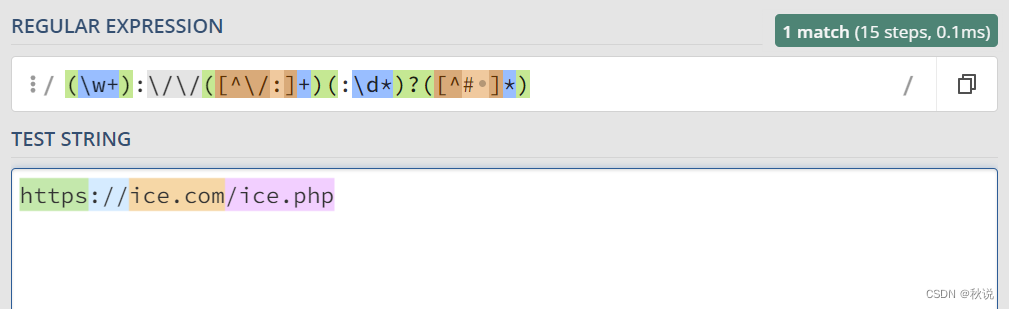
匹配路径
\/([^\/]+)\/([^\/]+)(\/[^\/]+)?
- 1
- 2
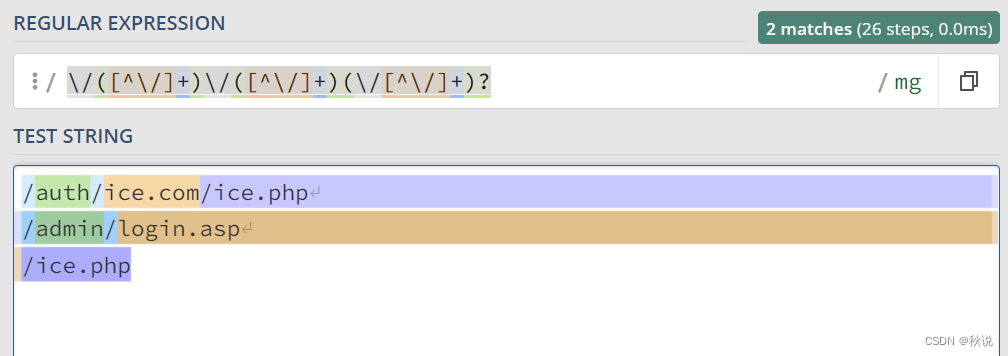
匹配URL的各个部分
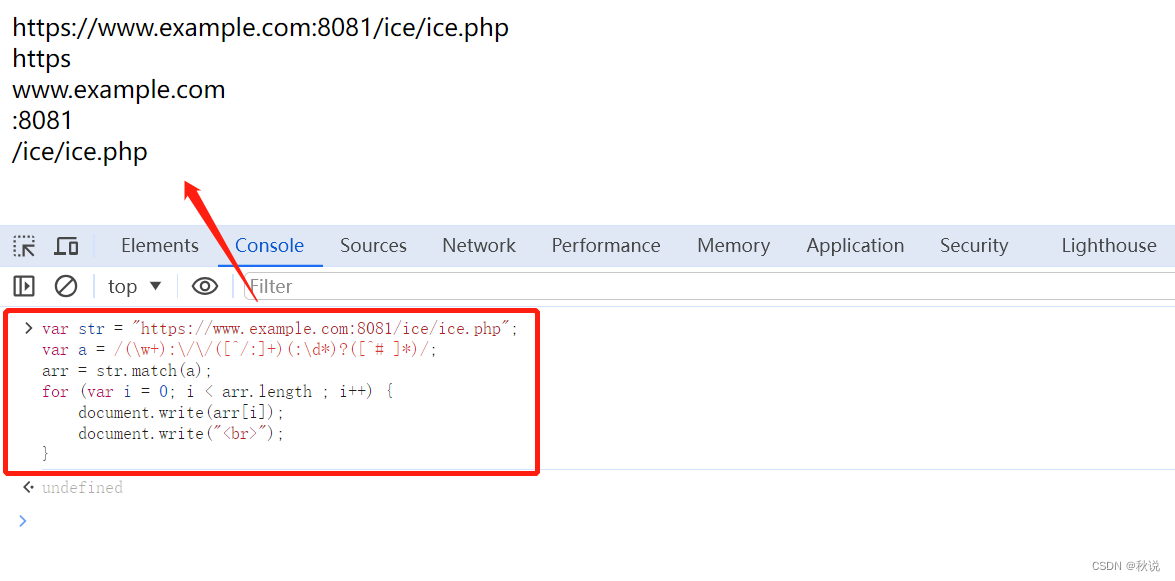
(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)
- 1
- 2
第一个括号子表达式(\w+)捕获 Web 地址的协议部分。该子表达式匹配在冒号和两个正斜杠前面的任何单词。
第二个括号子表达式([^/:]+)捕获地址的域地址部分。子表达式匹配非 : 和 / 之后的一个或多个字符。
第三个括号子表达式(:\d*)捕获端口号(如果已指定)。该子表达式匹配冒号后面的零个或多个数字。只能重复一次该子表达式,因为有?的存在
第四个括号子表达式([^# ]*)捕获 Web 地址指定的路径和 / 或页信息。该子表达式能匹配不包括 # 或空格字符的任何字符序列。
var str = "https://www.example.com:8081/ice/ice.php";
var a = /(\w+):\/\/([^/:]+)(:\d\*)?([^# ]\*)/;
arr = str.match(a);
for (var i = 0; i < arr.length ; i++) {
document.write(arr[i]);
document.write("<br>");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
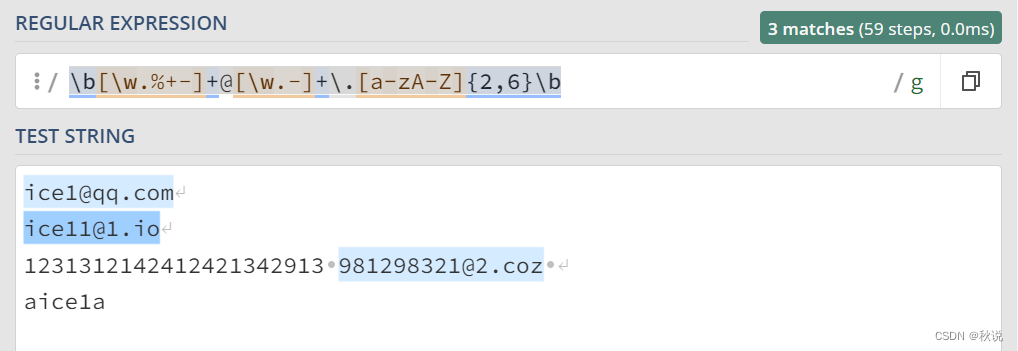
全局搜索邮箱正则表达式
/\b[\w.%+-]+@[\w.-]+\.[a-zA-Z]{2,6}\b/g
- 1
- 2
1、 \b: 匹配单词边界,确保电子邮件地址与其他字符分隔。
2、[\w.%+-]+: 匹配电子邮件地址的本地部分,包括字母、数字、下划线、百分号、点、加号和减号。+ 表示至少要有一个或多个这些字符。
3、@: 匹配电子邮件地址中的 “@” 符号。
4、[\w.-]+: 匹配邮件服务器名称,包括字母、数字、下划线、点和减号。这个部分的域名中可以包含一个以上的点,但不能以点结尾。
5、\.: 匹配电子邮件地址中的点号。
6、[a-zA-Z]{2,6}: 匹配顶级域名,这部分通常是由2到6个字母组成的字符串。注意,这部分是限制为大小写字母的,因此它只能匹配常见的顶级域名。
7、\b: 再次匹配单词边界,确保电子邮件地址与其他字符分隔。
8、最后的 /g 标志表示全局匹配。
日期匹配正则表达式
\d{4}-\d{2}-\d{2}
- 1
- 2
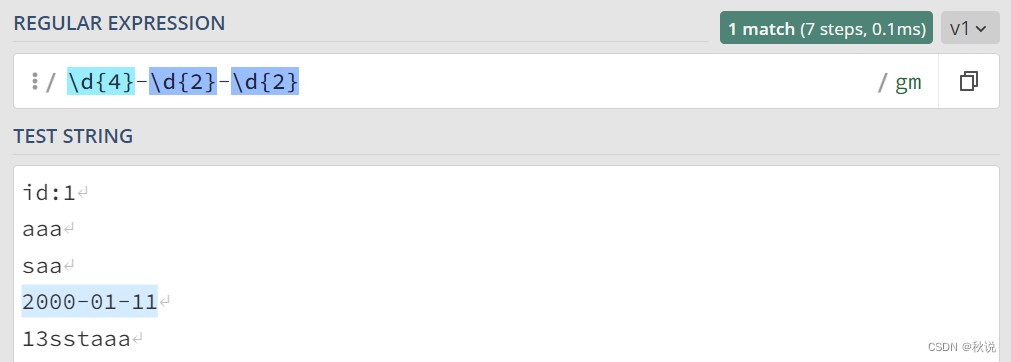
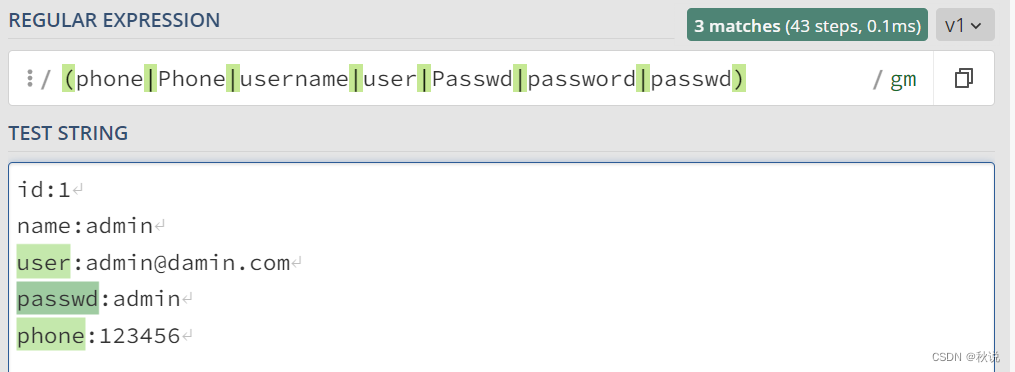
特殊字段匹配正则表达式
(phone|Phone|username|user|Passwd|password|passwd)
- 1
- 2
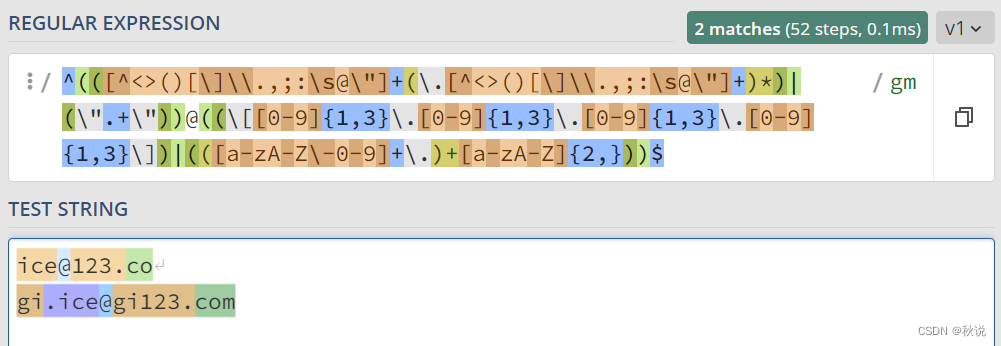
匹配邮箱正则表达式
常用于检测用户输入的邮箱是否为正确邮箱
^(([^<>()[\]\\.,;:\s@\"]+(\.[^<>()[\]\\.,;:\s@\"]+)*)|(\".+\"))@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$
- 1
- 2
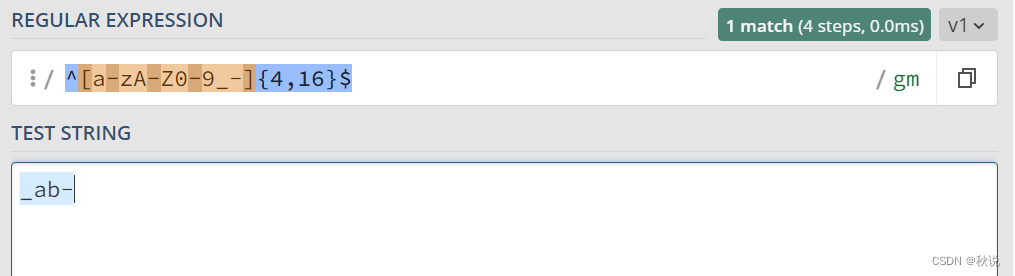
用户名正则表达式
包含字母,数字,下划线_,减号-
^[a-zA-Z0-9_-]{4,16}$
- 1
- 2
- 3
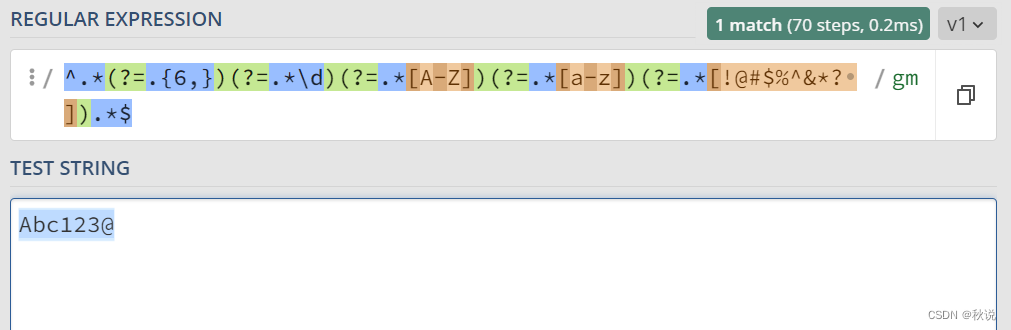
密码强度正则表达式
要求:最少6位,包括至少1个大写字母,1个小写字母,1个数字,1个特殊字符
^.*(?=.{6,})(?=.*\d)(?=.*[A-Z])(?=.*[a-z])(?=.*[!@#$%^&*? ]).*$
- 1
- 2
^: 匹配字符串的开始。
.*: 匹配零个或多个任意字符。
(?=.{6,}): 这是一个零宽度正向先行断言,用于确保密码至少包含6个字符。
(?=.*\d): 这是另一个零宽度正向先行断言,用于确保密码中至少包含一个数字。
(?=.*[A-Z]): 这是一个零宽度正向先行断言,用于确保密码中至少包含一个大写字母。
(?=.*[a-z]): 这是一个零宽度正向先行断言,用于确保密码中至少包含一个小写字母。
(?=.*[!@#$%^&*? ]): 这是一个零宽度正向先行断言,用于确保密码中至少包含一个特殊字符
.*: 匹配零个或多个任意字符。
$: 匹配字符串的结束。
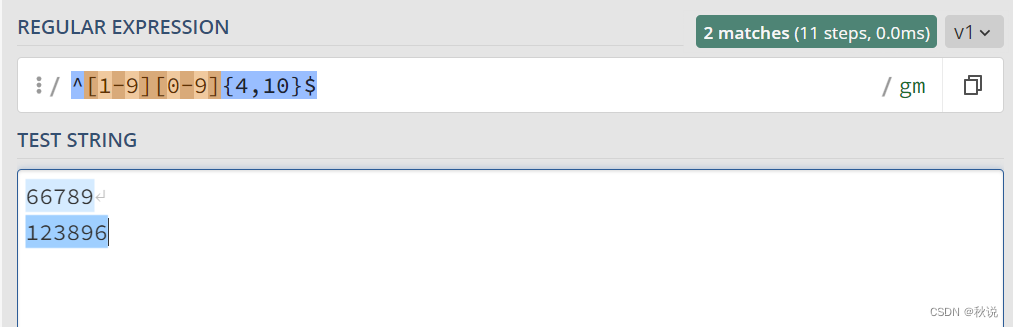
QQ号正则表达式
5至11位
^[1-9][0-9]{4,10}$
- 1
- 2
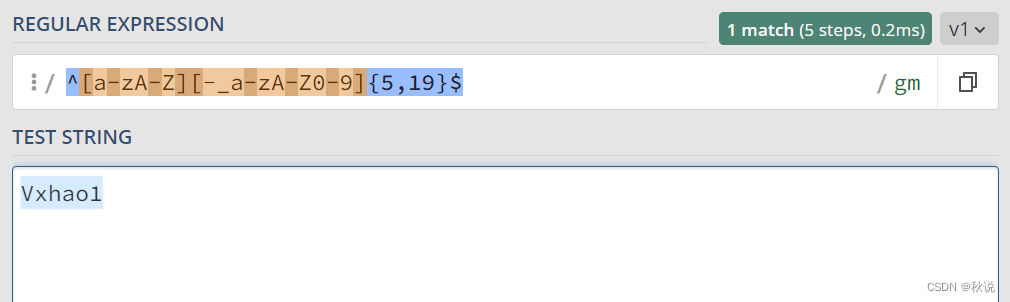
微信号正则表达式
6至20位,以字母开头,字母,数字,减号,下划线
^[a-zA-Z][-_a-zA-Z0-9]{5,19}$
- 1
- 2
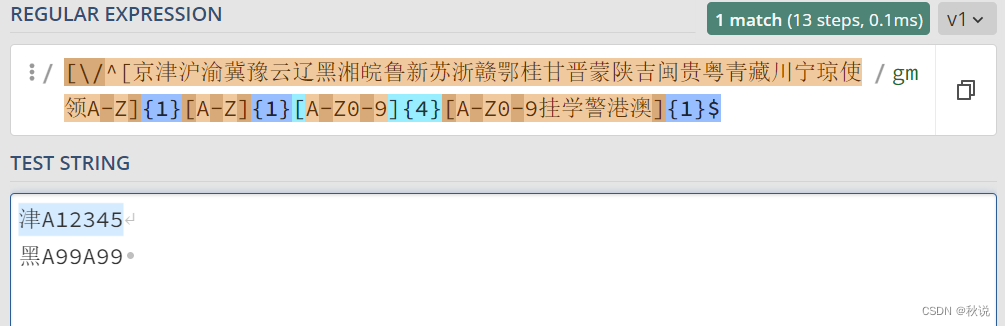
车牌号正则表达式
[\/^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$
- 1
- 2
匹配标签正则表达式
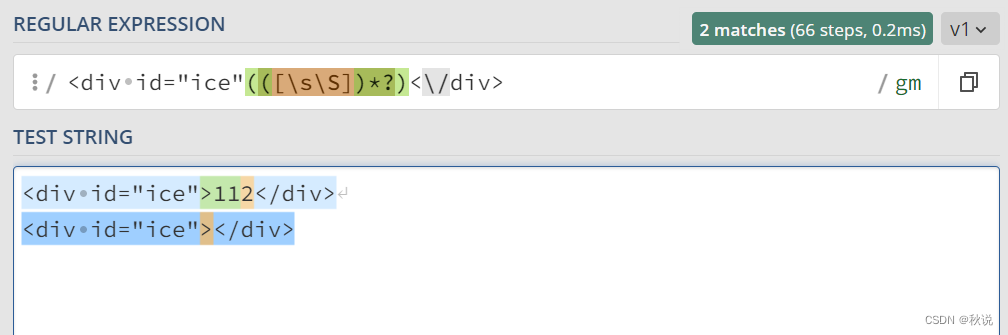
匹配 id=“ice” 的 div 标签:
<div id="ice"(([\s\S])*?)<\/div>
- 1
- 2
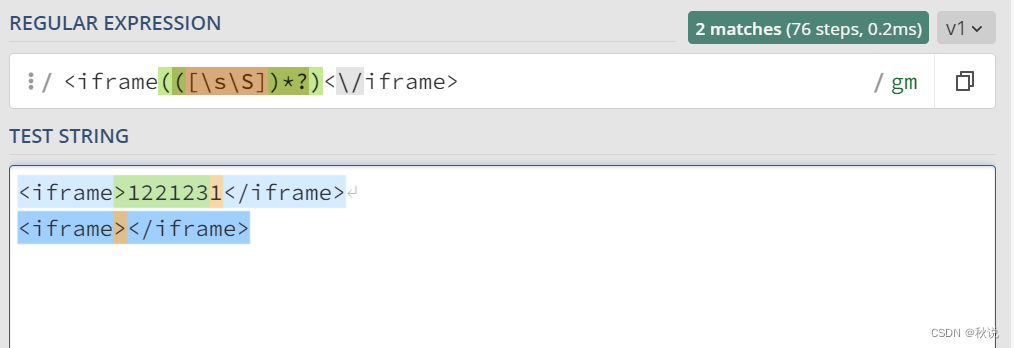
匹配 iframe 标签:
<iframe(([\s\S])*?)<\/iframe>
- 1
- 2
[\s\S]*?: 匹配任意空白字符或非空白字符,*? 表示非贪婪匹配,匹配尽量少的字符。
匹配浮点数正则表达式
^[-]?[0-9]+\.?[0-9]+$ // 匹配所有的浮点数
^\-{0,1}[0-9]+\.?[0-9]+$ //等价
- 1
- 2
- 3
^: 匹配字符串的开头。[-]?: 匹配可选的负号-,?表示负号可以出现 0 或 1 次。[0-9]+: 匹配一个或多个数字。\.?: 小数点.后的数字至少要出现一次。
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数网络安全工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点!真正的体系化!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
碰到天花板技术停滞不前!**
因此收集整理了一份《2024年网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
[外链图片转存中…(img-8na2crwA-1715564894474)]
[外链图片转存中…(img-s0S7HsZS-1715564894475)]
[外链图片转存中…(img-R9kqHBB2-1715564894475)]
[外链图片转存中…(img-7zw40qWH-1715564894475)]
[外链图片转存中…(img-Q8yzHnQg-1715564894475)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点!真正的体系化!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!

