
- 1后端必备 Git 分支开发:规范指南
- 2自我介绍怎么说面试不会凉?
- 3微信二次开发-微信视频号开发-微信api开发-VideosApi_微信视频号 视频上传api
- 4c++ web 框架 ---ricky.chu_网页版c++框架
- 5“5G+AI”到底有啥用?这篇漫画告诉你答案…
- 6远程管理 Linux:putty软件(mac版windows版)_putty for mac
- 7安装pyspark过程,超级easy_pyspark 安装
- 8【保姆级教程】Windows 远程登陆 Linux 服务器的两种方式:SSH + VS Code,开发必备_windows远程登录linux
- 9VASA-1:实时音频驱动的数字人说话面部视频生成技术_vasa-1 数字人
- 10gitlab拉取项目不用输用户名密码_idea gitlab clone输入token而不是用户名密码
一键生成透明底图像!教你用AI绘画开源 SD 插件实现素材自由!_layerdiffusion
赞
踩

大家好,这里是和你们一起探索 AI 的程序员晓晓~
AI 绘画自出现以来一直都在不断发展完善,实现了很多我们在实际应用中迫切需要的功能,比如生成正确的手指、指定的姿势、准确的文本内容等。上周,又一个重磅新功能在开源的 SD 生态内实现了——直接通过文本直接生成透明底图像和图层!这将为 AI 绘画和设计领域带来了新的可能性,使图像形式更多样,也能给设计师带来更多便利。
今天我们就一起来了解实现这一新功能的技术 LayerDiffusion,以及如何在 SD WebUI Forge 和 ComfyUI 中利用 LayerDiffusion 生成透明底图片。
一、LayerDiffusion 简介
LayerDiffusion 是由 @ lllyasviel (没错就是那个开发出 Controlnet、Fooocus 和 SD WebUI Forge 的大神)最新推出的一种透明图像生成技术,它的核心所在是“潜在透明度”,即将 Alpha 通道整合到预训练模型的潜在结构中,使模型能够生成带有透明度的图。
官方给出的演示案例效果非常好,不仅可以生成一般物体,而且对于玻璃、发光这种透明/半透明的对象,以及头发丝这种精细的内容,生成的效果依旧完美。本文章封面图的卷发女生就是我直接用 LayerDiffusion 生成的,极大提升了出图效率,而且真正做到了“毫无抠图痕迹”,再也不用担心有白边了。

除了直接生成透明底图像,LayerDiffusion 还支持生成分层图像。包括根据一个透明底图像生成完美融合的背景,并将该背景提取为完整独立的图层;以及根据背景图像+提示词生成前景主体,并将该主体提取为透明底图层。

目前 SD WebUI Forge 和 ComfyUI 已经支持 LayerDiffusion 的透明底功能,并且在未来还将支持通过图像生成透明底图像,下面为大家介绍如何在这 2 款工具中实现对应的功能。
二、在 SD WebUI Forge 中使用 LayerDiffusion
由于是同一个作者开发的,所以 SD WebUI Forge 最先实现了对 LayerDiffusion 的支持,界面操作非常方便,生成速度也很快。具体操作如下:
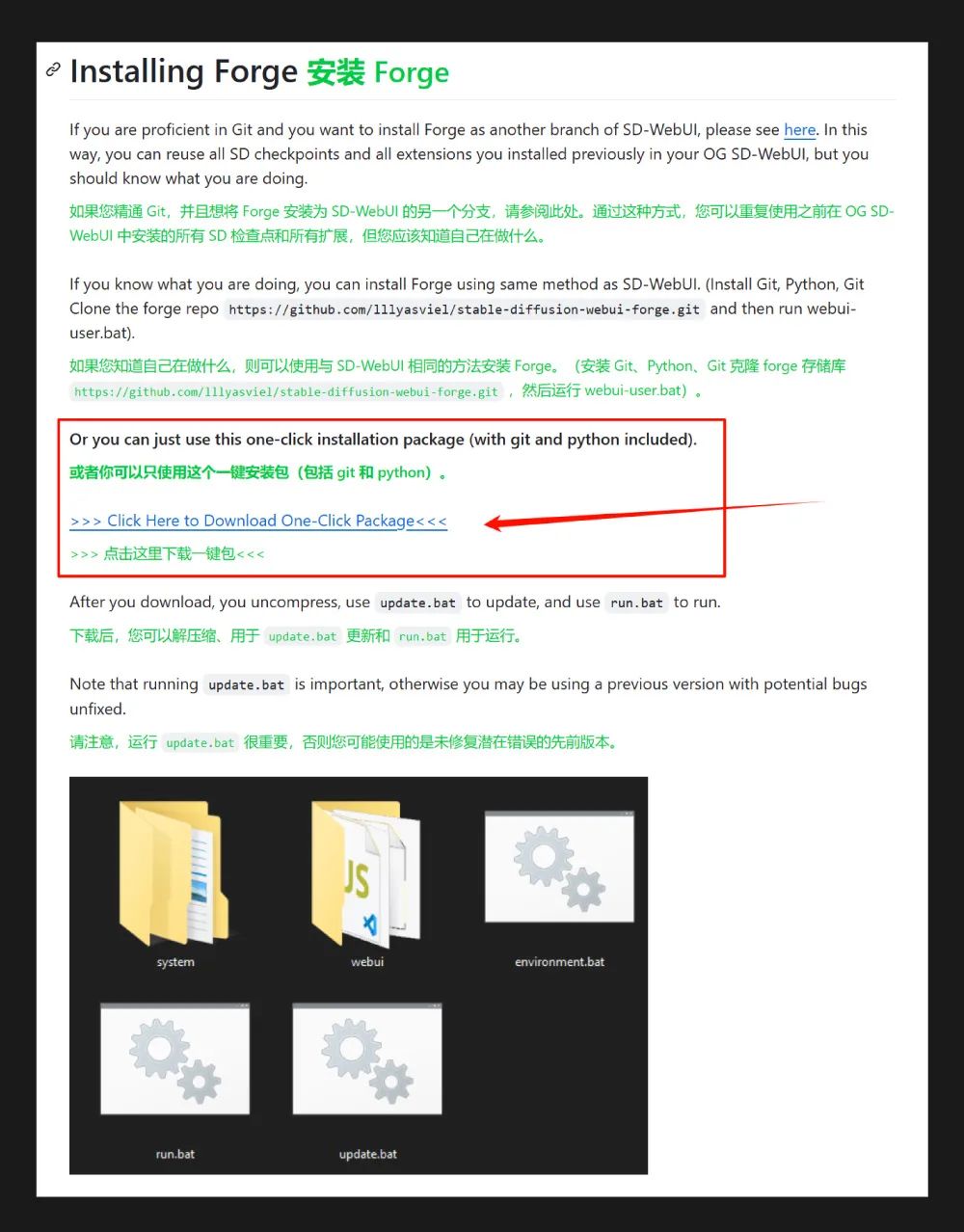
① 安装 SD WebUI Forge
SD WebUI Forge 一键安装包:请看文末扫描获取本地安装包哦~
先下载 WebUI Forge 官方一键安装包(请看文末领取哦),解压后安装到本地;然后进入根目录,点击 update.bat 更新程序 (必须点击),再点击 run.bat 启动 WebUI 界面。初次启动会下载很多配置文件,包括一个 1.99G 的 realisticVisionV51_v51VAE.safetensor 模型,所以时间会比较比较久,记得耐心等待,完成后会在浏览器中自动打开 UI 界面。
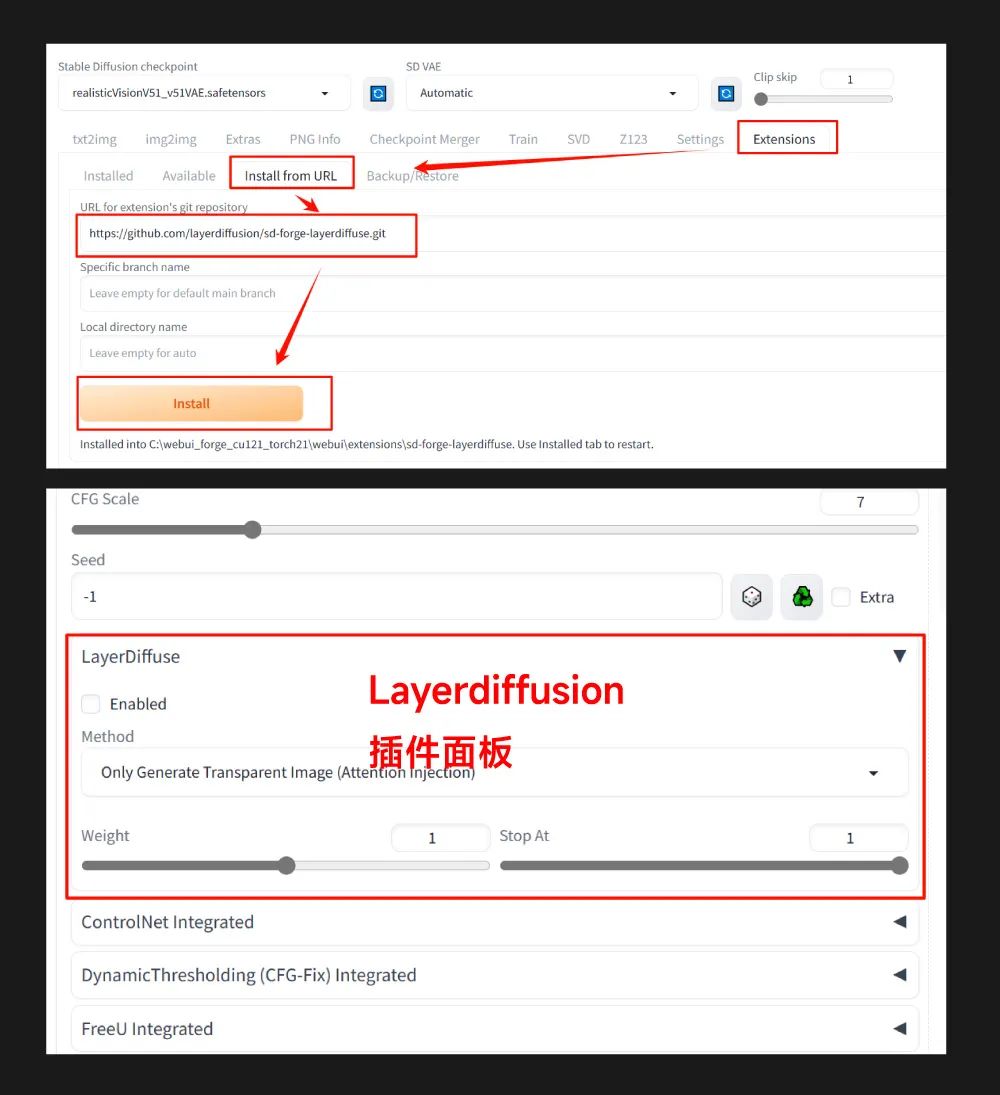
② 安装 LayerDiffusion 插件
Layerdiffusion 插件
Git 网址: https://github.com/layerdiffusion/sd-forge-layerdiffuse.git
如无法通过链接下载请看文末领取本地安装包
安装方法与 SD WebUI 一样,即进入 Extensions 版块,选择从 git 网站安装,然后重启 WebUI。或者进入 WebUI Forge 根目录,在 webui\extensions 文件夹中通过 git clone 命令安装。安装成功后,就能在界面上看到 LayerDiffusion 的插件面板了
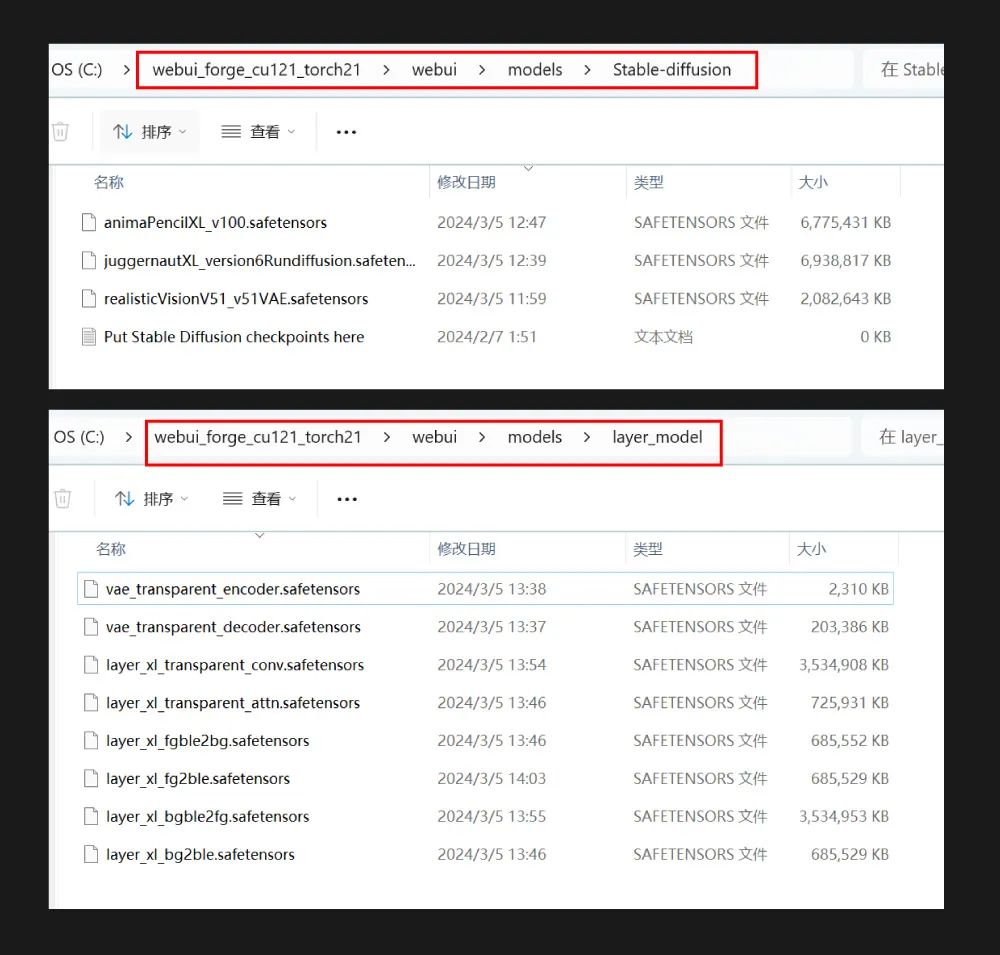
③ 安装模型
LayerDiffusion 插件目前仅支持 SDXL 模型,官方推荐了 Juggernaut XL V6 和 anima_pencil-XL 1.0.0 这两款模型进行操作(请看文末领取模型安装包),下载后安装到根目录的 webui\models\Stable-diffusion 文件夹中。此外还需要下载 8 个 LayerDiffusion 处理模型,安装到根目录的 webui\models\layer_model 文件夹中。
WebUI Forge 的 LayerDiffusion 插件目前支持生成透明底图像、根据背景图像生成前景图像和根据透明底前景生成背景图像。下面分别介绍一下它们的操作方法:
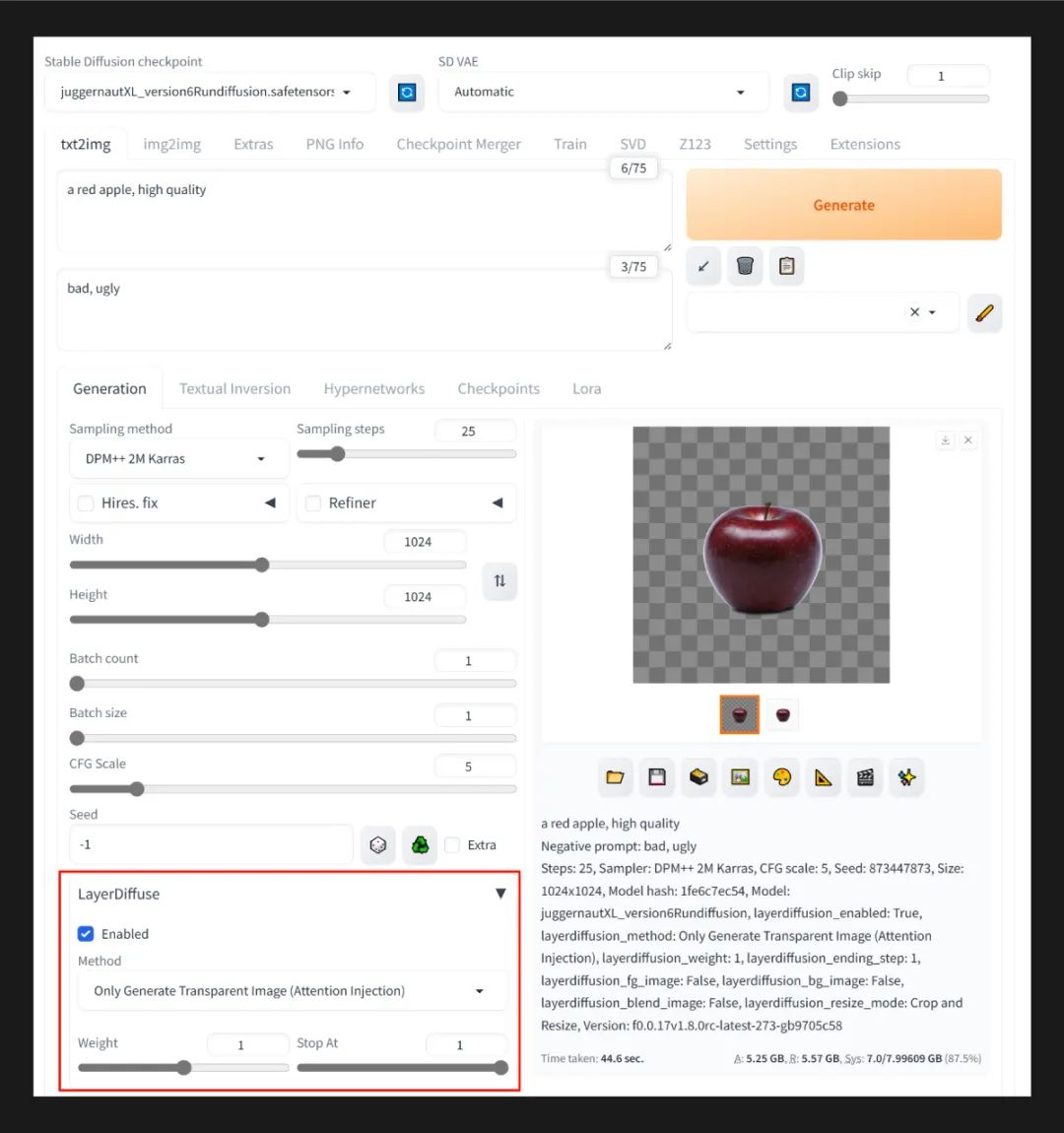
① 直接生成透明底图像
首先启用 LayerDiffusion 插件,Method 选择 Only Generate Transparent Image (Attention Injection)。然后选择大模型、设置生成参数 (下方有参考数值) 。LayerDiffusion 会一次性生成 2 张图像,第一张是带棋盘背景的预览图,第二张则是透明背景的 PNG 图片,下载后可以直接做为素材使用。
-
大模型:juggernautXL_version6Rundiffusion;VAE:automatic
-
正向提示词:a red apple, high quality;
-
反向提示词:bad, ugly;
-
生成参数:Steps: 25, Sampler: DPM++ 2M SDE Karras, CFG scale: 5, Size: 1024x1024,
-
layerdiffusion 插件:layerdiffusion_method: Only Generate Transparent Image (Attention Injection), layerdiffusion_weight: 1, layerdiffusion_ending_step: 1
② 根据背景图像生成透明底前景
首先在启用 LayerDiffusion 插件,并选择 From background to Blending 模式并上传一张背景图像,然后选择大模型、设置生成参数(下方有参考数值)。
-
大模型:JuggernautXL_version6Rundiffusion;VAE:automatic;Clip Skip: 1
-
正向提示词:a man sitting, high quality;
-
反向提示词:bad, ugly;
-
生成参数:Steps: 25, Sampler: DPM++ 2M SDE Karras, CFG scale: 7, Size:768x1024,
-
layerdiffusion 插件:layerdiffusion_method: From background to Blending, layerdiffusion_weight: 1, layerdiffusion_ending_step: 1, layerdiffusion_resize_mode: Crop and Resize
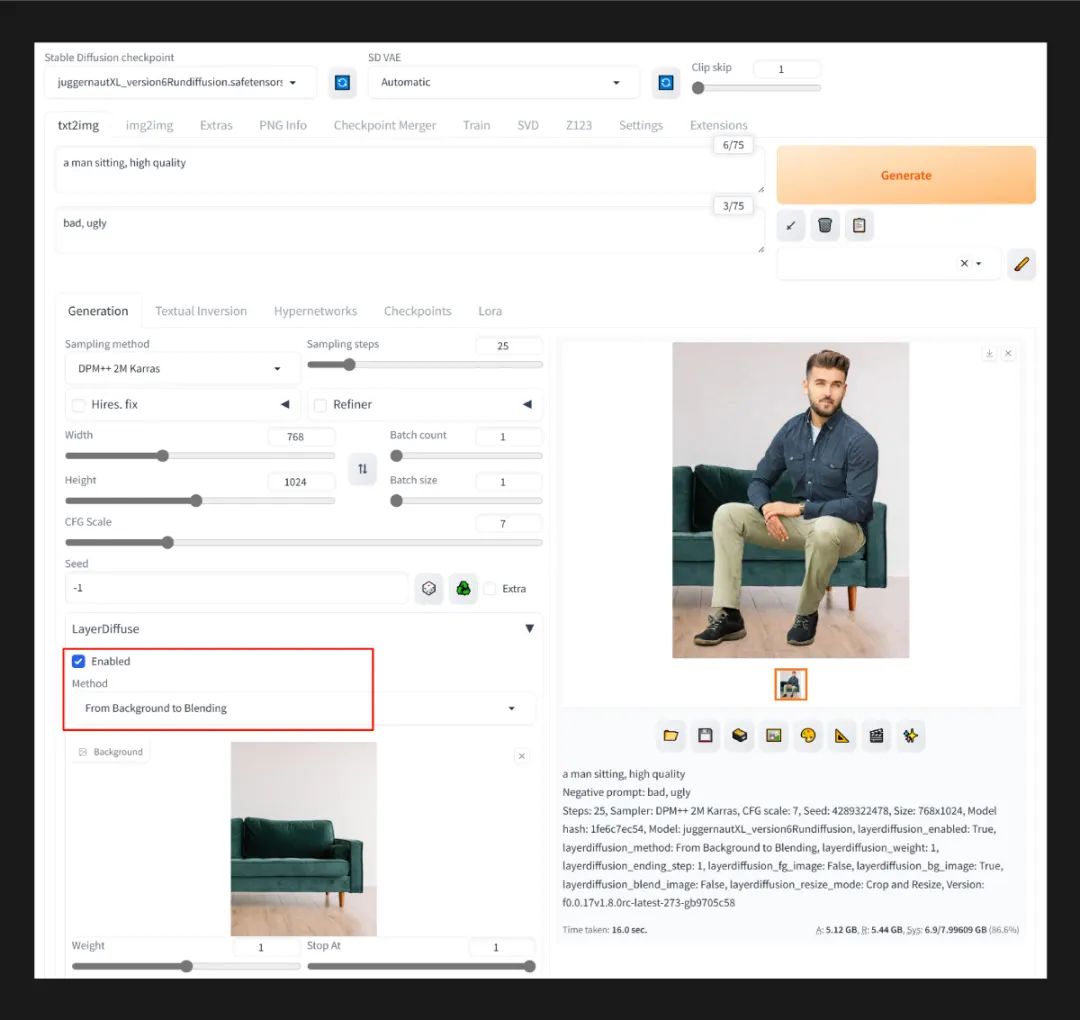
图像生成后,先更改 LayerDiffusion 的模式为 From Background and Blending to Foreground,然后将右侧的图像直接拖入空白的 blending 图像区,并将采样器更改为 Euler A 或 UniPC (否则会出现一些颜色误差,这一点作者正在研究改进);再次点击生成,就能得到前景人物的透明底图像。
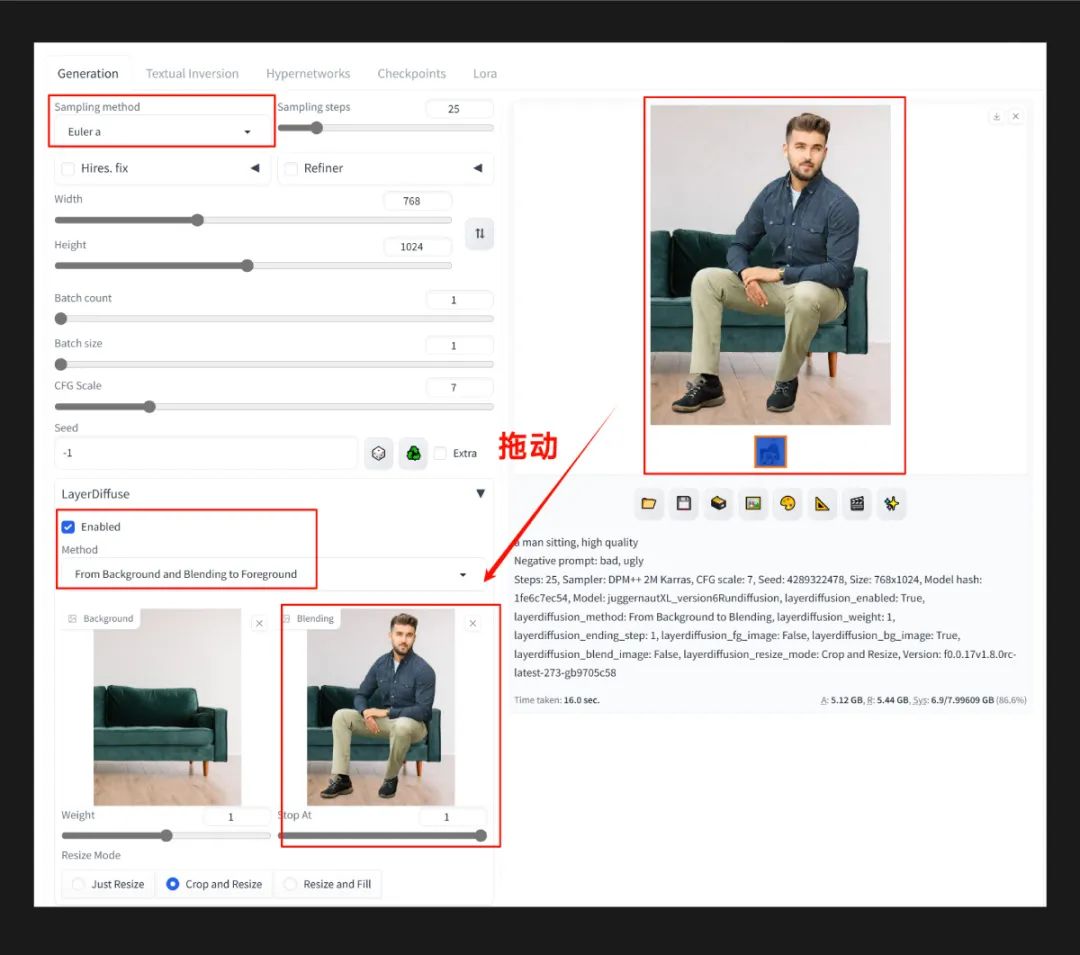
③ 根据前景生成背景
先使用 LayerDiffusion 生成一张透明底的物体,比如一个玻璃杯或者一只小猫,然后保存图像。将 LayerDiffusion 模式修改为 From Foreground to Blending,上传刚刚生成的透明底图像,然后加上提示词以及生成参数(下方有参考数值),点击生成。
-
大模型:JuggernautXL_version6Rundiffusion;VAE:automatic;Clip Skip: 1
-
正向提示词:a dog sitting on the grass, in a spring park, high quality;
-
反向提示词:bad, ugly;
-
生成参数:Steps: 25, Sampler: DPM++ 2M SDE Karras, CFG scale: 7, Size:896*1152,
-
layerdiffusion 插件:layerdiffusion_method: From Foreground to Blending, layerdiffusion_weight: 1, layerdiffusion_ending_step: 1, layerdiffusion_resize_mode: Crop and Resize
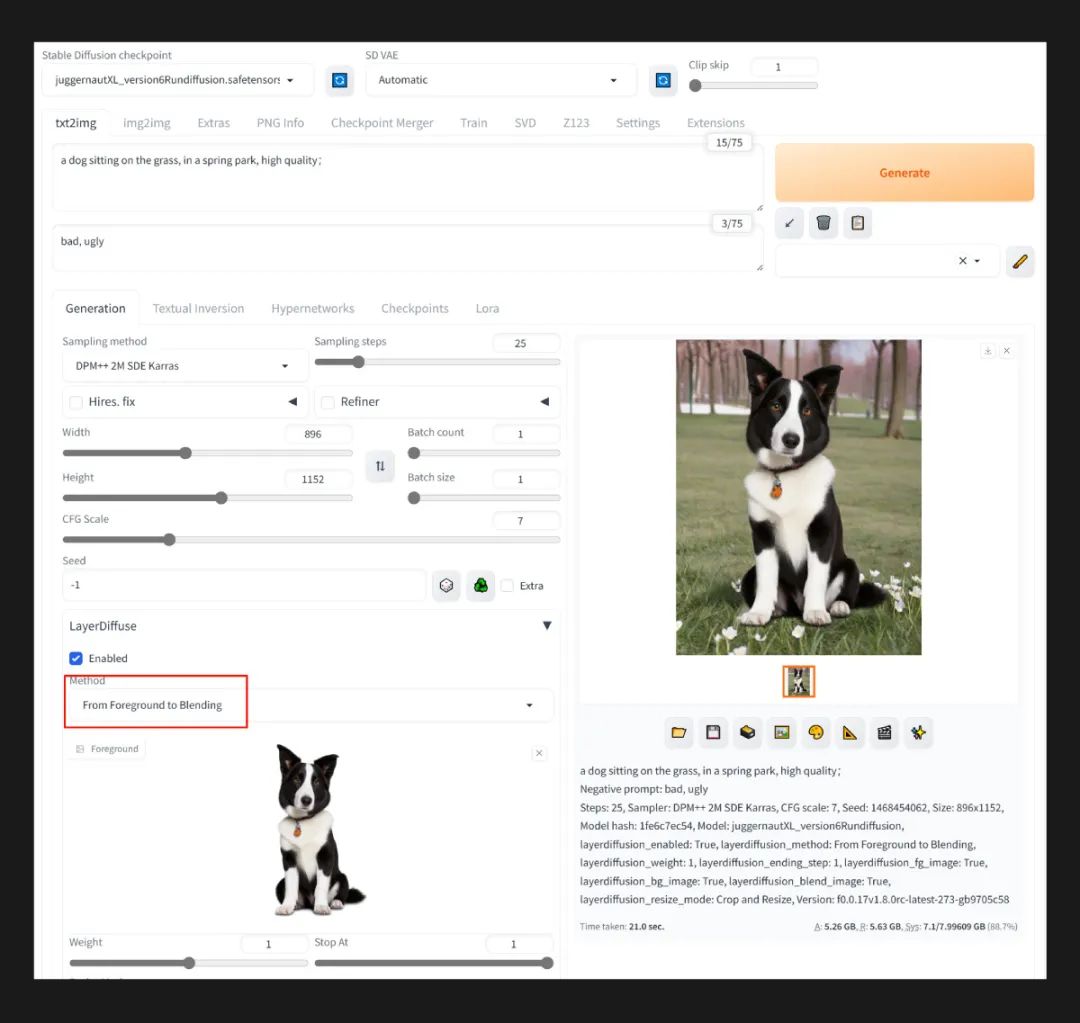
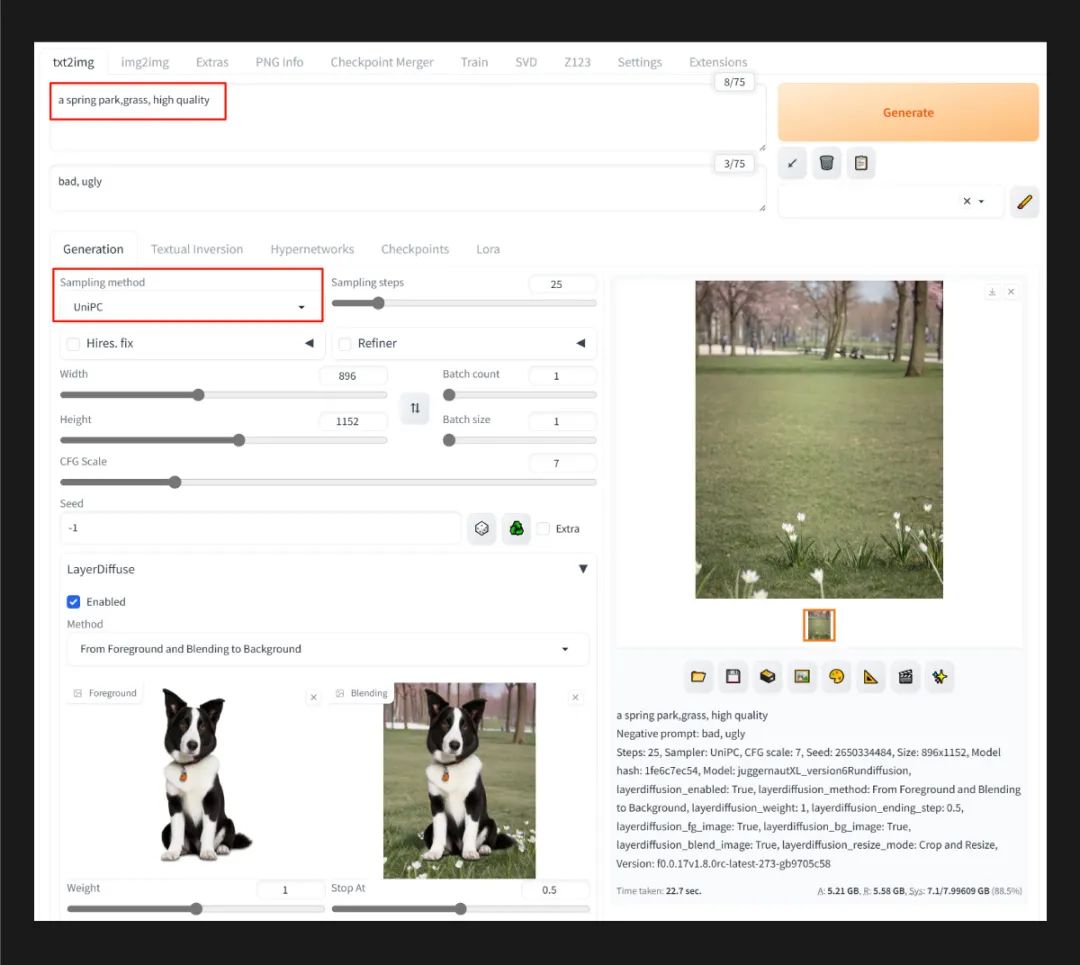
然后将 LayerDiffusion 模式修改为 From Foreground and Blending to Background,将生成的图像拖入 Blending 区域,然后将 stop_at 参数调整为 0.5、采样器更改为 Euler A 或者 UniPC,并将提示词修改为 “a spring park,grass, high quality”,点击生成,就能得到一张完整的背景图像了。
在 ComfyUI 中使用 LayerDiffusion
① 安装插件
ComfyUI-layerdiffuse 插件
git 网址: https://github.com/huchenlei/ComfyUI-layerdiffuse.git
如无法通过链接下载请看文末领取本地插件安装包哦
首先将 ComfyUI 更新到最新版本。然后安装 layerdiffuse 插件,可以用过 manager 安装,也可以进入根目录的 custom_nodes 文件夹中,通过 git clone 命令安装;安装成功后,进入 ComfyUI-layerdiffuse 根目录,打开终端命令,运行 pip install -r requirements.txt 命令,安装 python 依赖项。
② 安装模型
LayerDiffusion 处理模型: https://huggingface.co/LayerDiffusion/layerdiffusion-v1/tree/main (网盘有资源包)
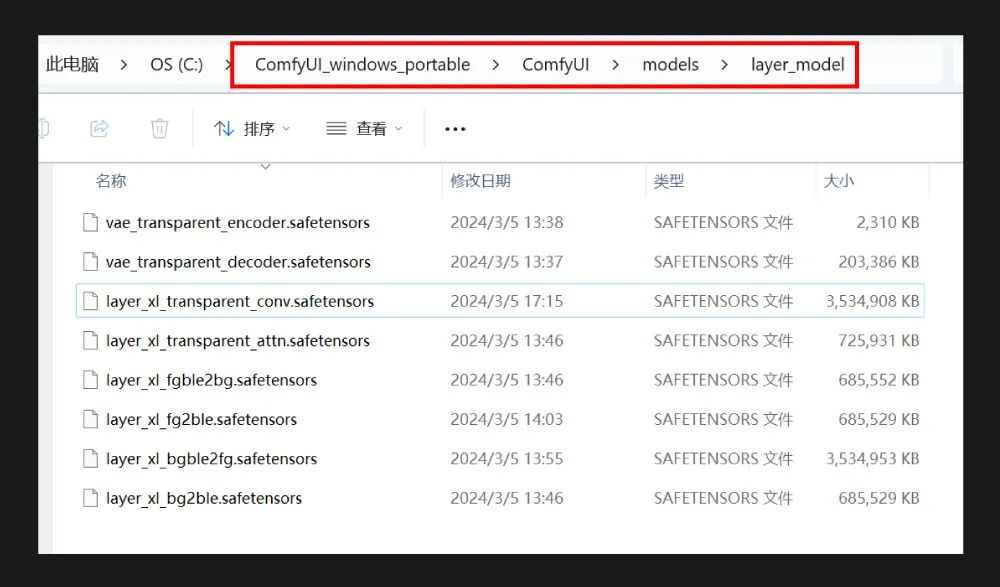
ComfyUI-layerdiffuse 插件目前仅支持 SDXL 模型,选择大模型时需要注意;此外还需要下载 LayerDiffusion 处理模型,安装到根目录的 models\layer_model 文件夹中。
③ 加载工作流
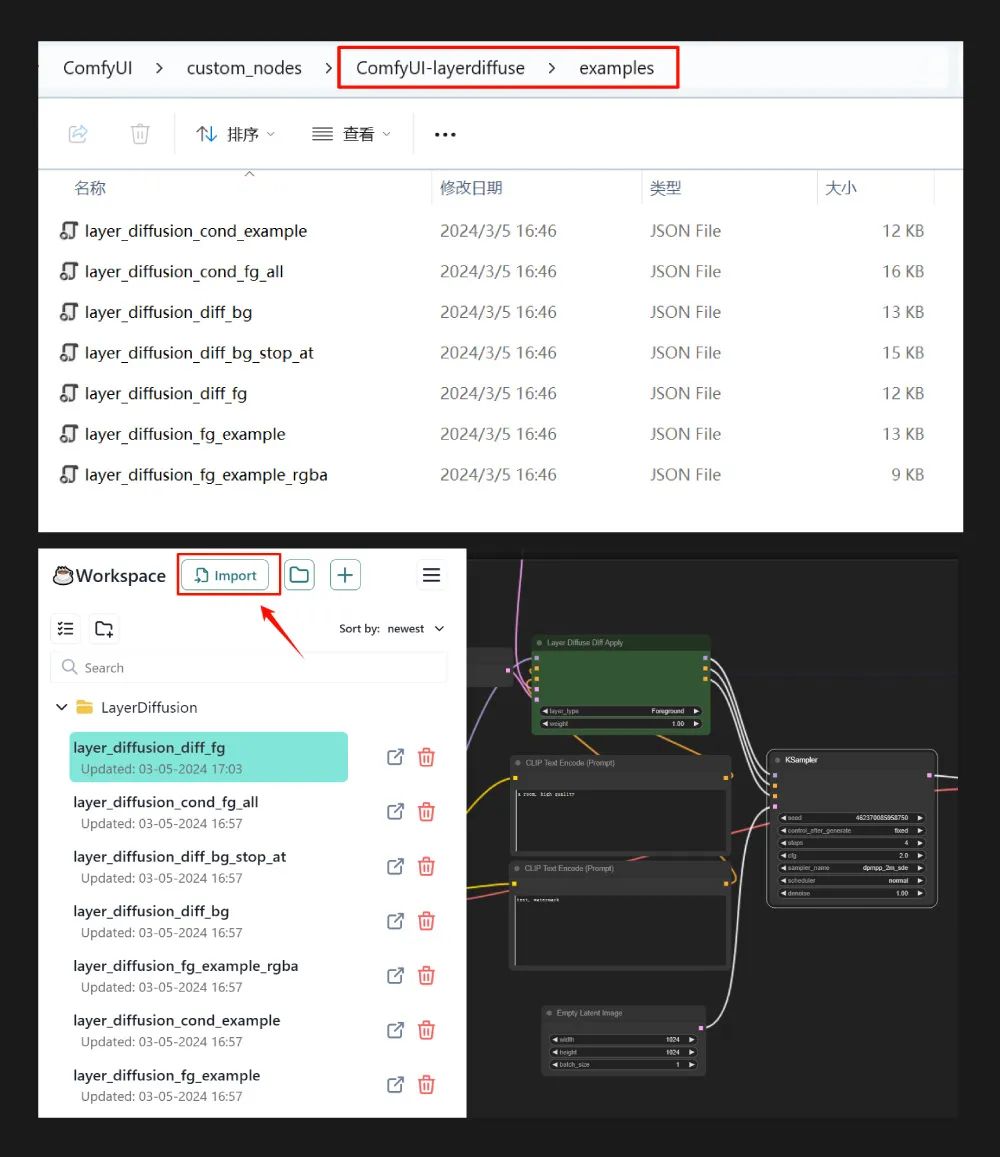
插件官方提供了 7 种工作流,全部存放在 custom_nodes\ComfyUI-layerdiffuse\examples 文件夹中,可以实现生成透明底图像、通过背景图像生成透明底前景、通过透明底前景生成完整背景等操作;我也进一步整理了这些文件,打包资源在文末网盘内。启动 ComfyUI 界面后,可以用 workspace 插件一次性将整个工作流文件夹导入 ComfyUI 中。
④ 直接生成透明底图像
layer_diffusion_fg_example_rgba 和 layer_diffusion_fg_example 两个工作流都可以生成透明底图像,且第二个工作流可以额外生成一个 Alpha 通道蒙版。


⑤ 生成前景&生成背景
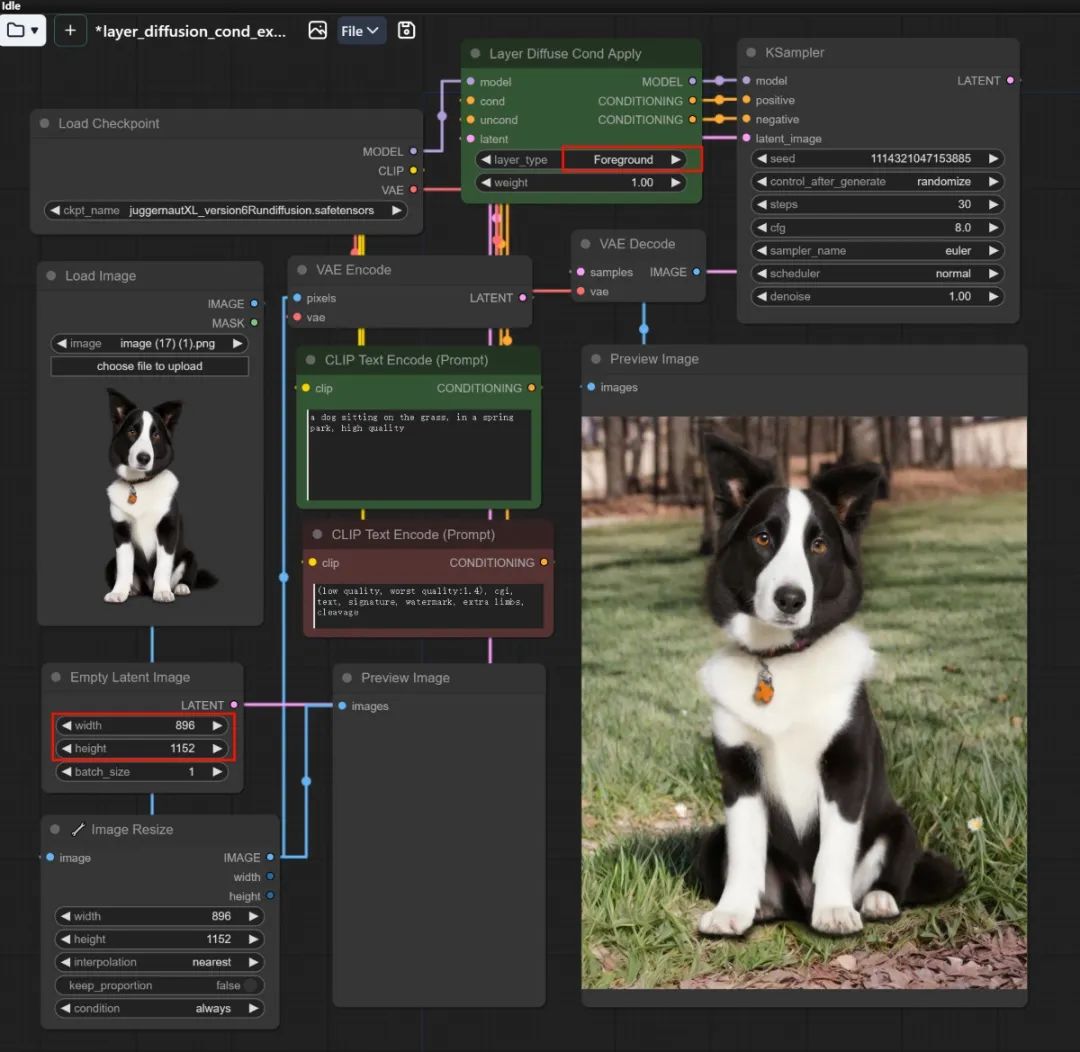
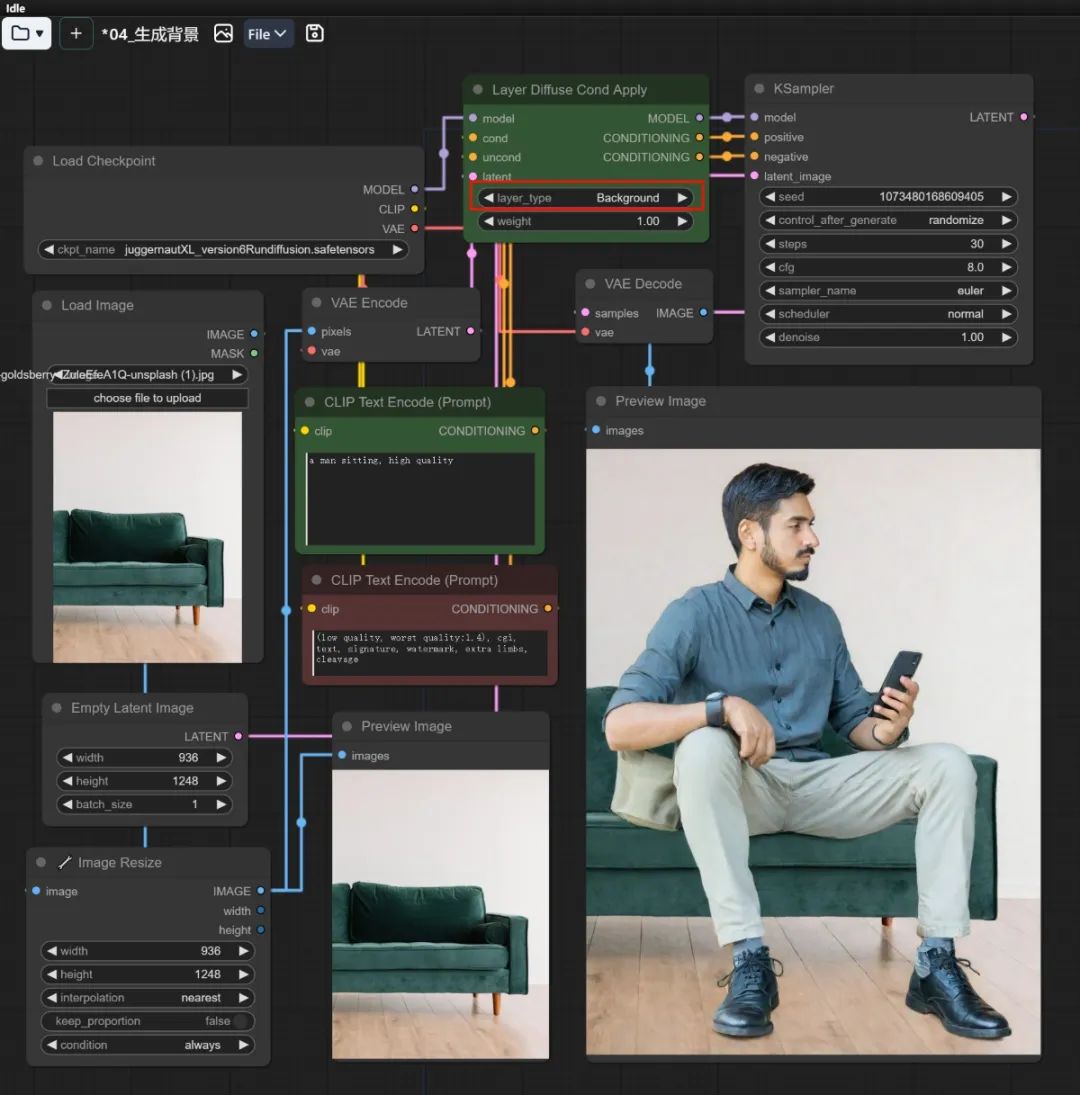
layer_diffusion_cond_example 工作流可以同时实现 “根据透明底前景生成背景” 和 “根据背景透明底前景” ,使用时注意在 Layer Diffuse Cond Apply 节点中对应地将 layer_type 调节成 foreground 或者 background。
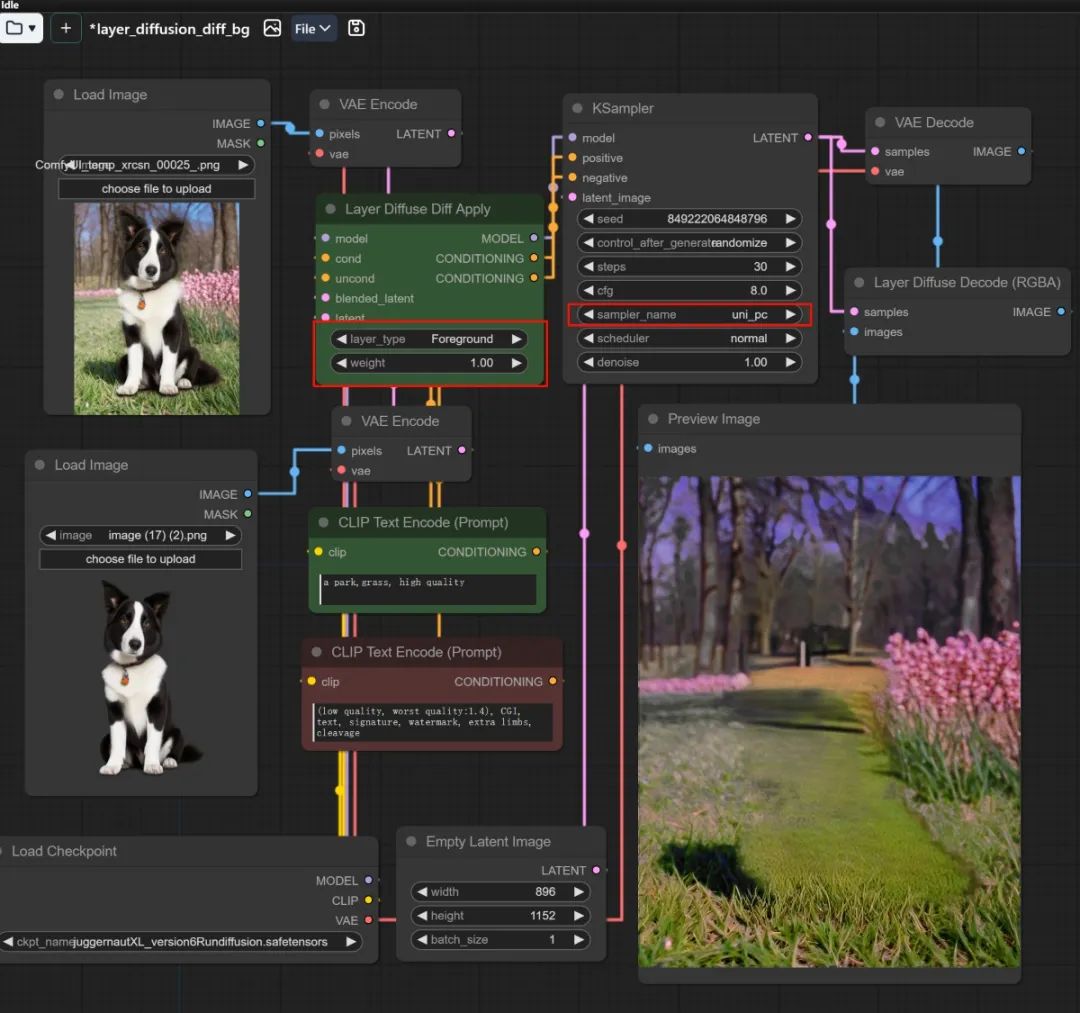
⑥ 提取完整背景
在根据一个透明底图像生成背景后,可以通过 layer_diffusion_diff_bg 工作流提取一个完整的背景图层。主体在提示词中完整描述背景内容,采样器需要选择 Euler A 或者 Uni_pc。
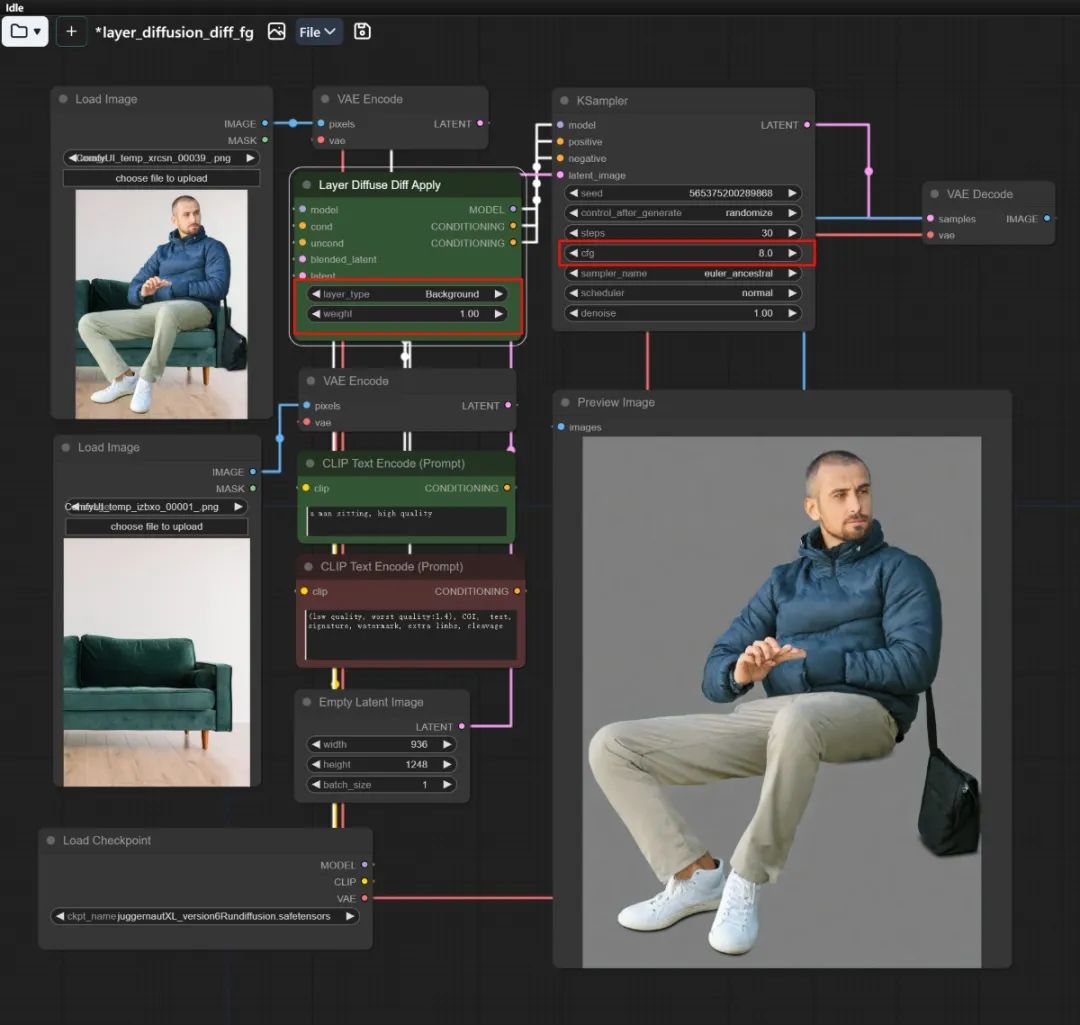
⑦ 提取前景图层
在一个背景图中生成一个新的主体后,可以再通过 layer_diffusion_diff_fg 工作流将主体提取为透明底图层。注意修改提示词,采样器依旧选择 Euler A 或者 Uni_pc。
以上就是本期为大家介绍的 AI 绘画插件 layerdiffusion,安装后可以在 SD WebUI Forge 和 ComfyUI 中通过文本生成透明底图像及分层图像。文内提到的模型及工作流文件都可扫描下方获取哦~
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除

