
- 1Python算法题集_从前序与中序遍历序列构造二叉树_python 前序遍历
- 2【iOS免越狱】利用IOS自动化WebDriverAgent实现自动直播间自动输入_webdriveragent 滑动
- 3最小生成树超详细介绍_什么是最小生成树
- 4第十三届通信、电路与系统国际会议(ICCCAS 2024)即将召开!_icccas2024
- 5算法学习过程——欧拉(费马小定理、欧拉函数、欧拉定理、欧拉降幂、欧拉筛法)_1_欧拉算法
- 6基于Sim2Real的鸟瞰图语义分割方法
- 7MobaXterm-Chinese中文版本安装及简单使用_mobaxterm汉化
- 8用群辉NAS打造影视墙(Jellyfin篇)_nas jellyfin
- 9verilog中signed的使用_verilog 中signed类型
- 10使用JAR命令打包JAR文件使用Maven打包使用Gradle打包打包Spring Boot应用
Transformers实战02-BERT预训练模型微调_bert模型微调
赞
踩
简介
BERT(Bidirectional Encoder Representations from Transformers)是一种基于 Transformer 模型的预训练语言表示方法,由Google研究团队于2018年提出。BERT 通过在大规模文本语料上进行无监督的预训练,学习了通用的语言表示,并且在各种自然语言处理任务中取得了显著的性能提升。
BERT仅使用了Transformer架构的Encoder部分。BERT自2018年由谷歌发布后,在多种NLP任务中(例如QA、文本生成、情感分析等等)都实现了更好的结果。
“Word2vec与GloVe都有一个特点,就是它们是上下文无关(context-free)的词嵌入。所以它们没有解决:一个单词在不同上下文中代表不同的含义的问题。例如,对于单词bank,它在不同的上下文中,有银行、河畔这种差别非常大的含义。BERT的出现,解决了这个问题。
BERT 的主要特点包括:
-
双向性:BERT 使用双向 Transformer 模型来处理输入序列,从而能够同时考虑上下文的信息,而不仅仅是单向的上下文信息。这种双向性使得 BERT 能够更好地理解句子中的语义和语境。
-
预训练-微调框架:BERT 使用了预训练-微调的方法。首先,在大规模文本语料上进行无监督的预训练,通过 Masked Language Model(MLM)和 Next Sentence Prediction(NSP)任务学习语言表示;然后,在特定的下游任务上微调模型参数,使其适应于特定的任务,如文本分类、命名实体识别等。
-
Transformer 模型:BERT 基于 Transformer 模型结构,其中包括多层的编码器,每个编码器由自注意力机制和前馈神经网络组成。这种结构能够有效地捕获输入序列中的长距离依赖关系,有助于提高模型在各种自然语言处理任务中的性能。
-
多层表示:BERT 提供了多层的语言表示,使得用户可以根据具体任务选择不同层的表示进行应用。较底层的表示通常更加接近原始输入,而较高层的表示则更加抽象,包含了更多的语义信息。
-
开放源代码:BERT 的源代码和预训练模型已经在 GitHub 上开放,使得研究人员和开发者可以基于 BERT 进行进一步的研究和应用开发。
BERT 通过预训练大规模文本语料上的通用语言表示,以及在各种下游任务上的微调,有效地提高了自然语言处理任务的性能,并且成为了当前领域内最具影响力的预训练模型之一。
transformer提供了不同领域中常见的机器学习模型类型:
-
VISION MODELS(视觉模型):用于处理和分析图像数据的模型,如卷积神经网络(CNN)中的ResNet、VGG,Vision Transformer (ViT)等。
-
AUDIO MODELS(音频模型):用于处理和分析音频数据的模型,如声学模型、语音识别模型等。
-
VIDEO MODELS(视频模型):用于处理和分析视频数据的模型,如视频分类、目标检测、行为识别等。
-
MULTIMODAL MODELS(多模态模型):结合多种数据类型(如文本、图像、音频等)进行分析和预测的模型,如OpenAI的CLIP。
-
REINFORCEMENT LEARNING MODELS(强化学习模型):用于解决强化学习问题的模型,如Deep Q-Networks(DQN)、Actor-Critic等。
-
TIME SERIES MODELS(时间序列模型):用于分析和预测时间序列数据的模型,如循环神经网络(RNN)、长短期记忆网络(LSTM)等。
-
GRAPH MODELS(图模型):用于处理和分析图数据的模型,如图神经网络(GNN)、图卷积网络(GCN)等。
BERT的基本原理
BERT基于的是Transformer模型,并且仅使用Transformer模型的Encoder部分。在Transformer模型中,Encoder的输入是一串序列,输出的是对序列中每个字符的表示。同样,在BERT中,输入的是一串序列,输出的是也是对应序列中每个单词的编码。
以“He got bit by Python”为例,BERT的输入输出如下图所示:
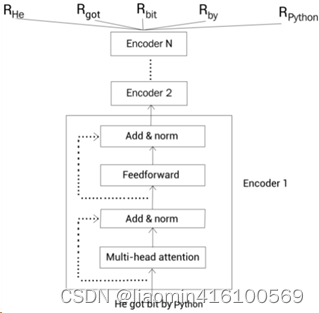
其中输入为序列“He got bit by Python”,输出的是对每个单词的编码
R
w
o
r
d
R_{word}
Rword。这样在经过了BERT处理后,即得到了对每个单词包含的上下文表示
R
w
o
r
d
R_{word}
Rword。
分词
from transformers import AutoModel, BertTokenizer model_name="bert-base-chinese" #bert-base-uncased model=AutoModel.from_pretrained(model_name) tokenizer=BertTokenizer.from_pretrained(model_name) print(type(model),type(tokenizer)) sequence = ["我出生在湖南A阳,我得家在深圳.","我得儿子是廖X谦"] #输出中包含两个键 input_ids 和 attention_mask,其中 input_ids 对应分词之后的 tokens 映射到的数字编号列表,而 attention_mask 则是用来标记哪些 tokens #是被填充的(这里“1”表示是原文,“0”表示是填充字符)。 print(tokenizer(sequence, padding=True, truncation=True, return_tensors="pt",pair=True)) #将输入切分为词语、子词或者符号(例如标点符号),统称为 tokens; print(tokenizer.tokenize(sequence[0]),len(tokenizer.tokenize(sequence[0]))) #我们通过 convert_tokens_to_ids() 将切分出的 tokens 转换为对应的 token IDs: print(tokenizer.convert_tokens_to_ids(tokenizer.tokenize(sequence[0]))) #可以通过 encode() 函数将这两个步骤合并,并且 encode() 会自动添加模型需要的特殊 token,例如 BERT 分词器会分别在序列的首尾添加[CLS] 和 [SEP] print(tokenizer.encode(sequence[0])) #解码还原文字,可以看到encode前后加了[CLS] 和 [SEP] print(tokenizer.decode(tokenizer.encode(sequence[1])))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
输出
<class 'transformers.models.bert.modeling_bert.BertModel'> <class 'transformers.models.bert.tokenization_bert.BertTokenizer'>
{'input_ids': tensor([[ 101, 2769, 1139, 4495, 1762, 3959, 1298, 2277, 7345, 117, 2769, 2533,
2157, 1762, 3918, 1766, 119, 102],
[ 101, 2769, 2533, 1036, 2094, 3221, 2445, 3813, 6472, 102, 0, 0,
0, 0, 0, 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
['我', '出', '生', '在', '湖', '南', 'A', '阳', ',', '我', '得', '家', '在', '深', '圳', '.'] 16
[2769, 1139, 4495, 1762, 3959, 1298, 2277, 7345, 117, 2769, 2533, 2157, 1762, 3918, 1766, 119]
[101, 2769, 1139, 4495, 1762, 3959, 1298, 2277, 7345, 117, 2769, 2533, 2157, 1762, 3918, 1766, 119, 102]
[CLS] 我 得 儿 子 是 廖 X 谦 [SEP]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
模型输出
#这里演示最终输出隐藏状态得输出 from transformers import AutoModel,AutoTokenizer model_name="bert-base-chinese" #bert-base-uncased model=AutoModel.from_pretrained(model_name) tokenizer=BertTokenizer.from_pretrained(model_name) raw_inputs = [ "I've been waiting for a HuggingFace course my whole life.", "I hate this so much!", ] inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt") outputs = model(**inputs) print("词个数",len(tokenizer.encode(raw_inputs[0]))) """ 在BERT模型中,last_hidden_state 的形状是 [batch_size, sequence_length, hidden_size],其中: batch_size 表示批量大小,即输入的样本数量。在你的例子中,batch_size 是 2,表示你有两个句子。 sequence_length 表示序列长度,即输入文本中词元的数量。在你的例子中,sequence_length 是 19,表示每个句子包含 19 个词元,我爱中国,我就是一个词元,爱也是一个词元。 hidden_size 表示隐藏状态的维度,通常是模型的隐藏层的大小。在BERT-base模型中,hidden_size 是 768,表示每个词元的隐藏状态是一个包含 768 个值的向量。 """ print(outputs.last_hidden_state.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
输出:torch.Size([2, 19, 768])
BERT预训练的方法
BERT的预训练语料库使用的是Toronto BookCorpus和Wikipedia数据集。在准备训练数据时,首先从语料库中采样2条句子,例如Sentence-A与Sentence-B。这里需要注意的是:2条句子的单词之和不能超过512个。对于采集的这些句子,50%为两个句子是相邻句子,另50%为两个句子毫无关系。
假设采集了以下2条句子:
Beijing is a beautiful city
I love Beijing
- 1
- 2
对这2条句子先做分词:
Tokens = [ [CLS], Beijing, is, a, beautiful, city, [SEP], I, love, Beijing, [SEP] ]
- 1
然后,以15%的概率遮挡单词,并遵循80%-10%-10%的规则。假设遮挡的单词为city,则:
Tokens = [ [CLS], Beijing, is, a, beautiful, [MASK], [SEP], I, love, Beijing, [SEP] ]
接下来将Tokens送入到BERT中,并训练BERT预测被遮挡的单词,同时也要预测这2条句子是否为相邻(句子2是句子1的下一条句子)。也就是说,BERT是同时训练Masked Language Modeling和NSP任务。
BERT的训练参数是:1000000个step,每个batch包含256条序列(256 * 512个单词 = 128000单词/batch)。使用的是Adam,learning rate为1e-4、β1 = 0.9、β2 = 0.999。L2正则权重的衰减参数为0.01。对于learning rete,前10000个steps使用了rate warmup,之后开始线性衰减learning rate(简单地说,就是前期训练使用一个较大的learning rate,后期开始线性减少)。对所有layer使用0.1概率的dropout。使用的激活函数为gelu,而非relu。
验证使用两条句子。
checkpoint = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"拼多多得货物真是差劲.",
"我喜欢天猫,天猫货物都很好",
]
raw_inputs1 = [
"拼多多买了一件掉色衣服.",
"我在天猫买的衣服颜色还行",
]
#允许传入两个数组,相同索引会自动通过[SEP]拼接。
inputs = tokenizer(raw_inputs,raw_inputs1, padding=True, truncation=True, return_tensors="pt")
print(tokenizer.decode(inputs.input_ids[0]))
print(tokenizer.decode(inputs.input_ids[1]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出
[CLS] 拼 多 多 得 货 物 真 是 差 劲. [SEP] 拼 多 多 买 了 一 件 掉 色 衣 服. [SEP] [PAD] [PAD]
[CLS] 我 喜 欢 天 猫 , 天 猫 货 物 都 很 好 [SEP] 我 在 天 猫 买 的 衣 服 颜 色 还 行 [SEP]
- 1
- 2
预测的整个过程
#演示预测的整个过程。 import torch from transformers import AutoModelForSequenceClassification #情感分析任务 checkpoint = "bert-base-chinese" tokenizer = AutoTokenizer.from_pretrained(checkpoint) model = AutoModelForSequenceClassification.from_pretrained(checkpoint) print(type(model)) raw_inputs = [ "拼多多得货物真是差劲.", "我喜欢天猫,天猫货物都很好", ] inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt") outputs = model(**inputs) #将分词的词反编码出来 print(tokenizer.decode(inputs.input_ids[0]),tokenizer.decode(inputs.input_ids[1])) #"Logits" 是指模型在分类问题中输出的未经过 softmax 或 sigmoid 函数处理的原始预测值。 print("分类输出形状:",outputs.logits.shape) print("分类输出:",outputs.logits) #经过softmax就是预测的结果了 predictions = torch.nn.functional.softmax(outputs.logits, dim=-1) #预测的每一行是一个句子,第一列表示积极的概率,第二列表示不积极的概率 print("预测结果:",predictions) #有两种分类0表示积极,1表示不积极 print("label和索引:",print(model.config.id2label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
输出
[CLS] 拼 多 多 得 货 物 真 是 差 劲. [SEP] [PAD] [PAD] [CLS] 我 喜 欢 天 猫 , 天 猫 货 物 都 很 好 [SEP]
分类输出形状: torch.Size([2, 2])
分类输出: tensor([[0.4789, 1.0043],
[0.2907, 0.7432]], grad_fn=<AddmmBackward0>)
预测结果: tensor([[0.3716, 0.6284],
[0.3888, 0.6112]], grad_fn=<SoftmaxBackward0>)
{0: 'LABEL_0', 1: 'LABEL_1'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
BERT模型微调
加载数据集
我们以同义句判断任务为例(每次输入两个句子,判断它们是否为同义句),带大家构建我们的第一个 Transformers 模型。我们选择蚂蚁金融语义相似度数据集 AFQMC 作为语料,它提供了官方的数据划分,训练集(train.json) / 验证集(dev.json) / 测试集(test.json)分别包含 34334 / 4316 / 3861 个句子对,标签 0 表示非同义句,1 表示同义句:
{"sentence1": "还款还清了,为什么花呗账单显示还要还款", "sentence2": "花呗全额还清怎么显示没有还款", "label": "1"}
- 1
训练集用于训练模型,验证集用于每次epoch后训练集的正确率,测试集用于验证最后生成模型的准确率。
Dataset
Pytorch 通过 Dataset 类和 DataLoader 类处理数据集和加载样本。同样地,这里我们首先继承 Dataset 类构造自定义数据集,以组织样本和标签。AFQMC 样本以 json 格式存储,因此我们使用 json 库按行读取样本,并且以行号作为索引构建数据集。
class MyDataSet(Dataset): def __init__(self,filePath): self.data={} current_directory = os.getcwd() with open(current_directory+"/dataset/"+filePath,"rt", encoding="utf-8") as f: for idx,line in enumerate(f): self.data[idx]=json.loads(line.strip()) def __getitem__(self, item): return self.data[item] def __len__(self): return len(self.data) train_data=MyDataSet("train.json") dev_data=MyDataSet("dev.json") print(dev_data[1])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
输出:
{'id': 1, 'sentence1': '网商贷怎么转变成借呗', 'sentence2': '如何将网商贷切换为借呗'}
- 1
可以看到,我们编写的 AFQMC 类成功读取了数据集,每一个样本都以字典形式保存,分别以 sentence1、sentence2 和 label 为键存储句子对和标签。
如果数据集非常巨大,难以一次性加载到内存中,我们也可以继承 IterableDataset 类构建迭代型数据集:
class MyDataSetIter(IterableDataset):
def __init__(self,filePath):
self.filePath=filePath
def __iter__(self):
current_directory = os.getcwd()
with open(current_directory+"/dataset/"+self.filePath,"rt", encoding="utf-8") as f:
for _,line in enumerate(f):
data=json.loads(line.strip())
yield data
print(next(iter(MyDataSetIter("dev.json"))))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出:
{'sentence1': '双十一花呗提额在哪', 'sentence2': '里可以提花呗额度', 'label': '0'}
- 1
DataLoader
接下来就需要通过 DataLoader 库按批 (batch) 加载数据,并且将样本转换成模型可以接受的输入格式。对于 NLP 任务,这个环节就是将每个 batch 中的文本按照预训练模型的格式进行编码(包括 Padding、截断等操作)。
我们通过手工编写 DataLoader 的批处理函数 collate_fn 来实现。首先加载分词器,然后对每个 batch 中的所有句子对进行编码,同时把标签转换为张量格式:
#DataLoader处理数据为seq1 [SEP] seq2 from transformers import AutoTokenizer import torch from torch.utils.data import DataLoader checkpoint = "bert-base-chinese" tokenizer = AutoTokenizer.from_pretrained(checkpoint) def collote_fn(batch_samples): batch_sentence_1, batch_sentence_2 = [], [] batch_label = [] for sample in batch_samples: batch_sentence_1.append(sample['sentence1']) batch_sentence_2.append(sample['sentence2']) batch_label.append(int(sample['label'])) X = tokenizer( batch_sentence_1, batch_sentence_2, padding=True, truncation=True, return_tensors="pt" ) y = torch.tensor(batch_label) return X, y train_loader=DataLoader(train_data,batch_size=4,shuffle=False,collate_fn=collote_fn) X,y=next(iter(train_loader)) print("label的维度",y.shape) print("s1,s2合并的维度",X.input_ids.shape) for idx,d in enumerate(X.input_ids): print("第一批次4个元素中的第{}个:{},label={}".format(idx,tokenizer.decode(X.input_ids[idx]),y[idx]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
输出
label的维度 torch.Size([4])
s1,s2合并的维度 torch.Size([4, 30])
第一批次4个元素中的第0个:[CLS] 蚂 蚁 借 呗 等 额 还 款 可 以 换 成 先 息 后 本 吗 [SEP] 借 呗 有 先 息 到 期 还 本 吗 [SEP],label=0
第一批次4个元素中的第1个:[CLS] 蚂 蚁 花 呗 说 我 违 约 一 次 [SEP] 蚂 蚁 花 呗 违 约 行 为 是 什 么 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD],label=0
第一批次4个元素中的第2个:[CLS] 帮 我 看 一 下 本 月 花 呗 账 单 有 没 有 结 清 [SEP] 下 月 花 呗 账 单 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD],label=0
第一批次4个元素中的第3个:[CLS] 蚂 蚁 借 呗 多 长 时 间 综 合 评 估 一 次 [SEP] 借 呗 得 评 估 多 久 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD],label=0
- 1
- 2
- 3
- 4
- 5
- 6
可以看到,DataLoader 按照我们设置的 batch size 每次对 4 个样本进行编码,并且通过设置 padding=True 和 truncation=True 来自动对每个 batch 中的样本进行补全和截断。这里我们选择 BERT 模型作为 checkpoint,所以每个样本都被处理成了“了“[CLS] sen1 [SEP] sen2 [SEP]”的形式。
这种只在一个 batch 内进行补全的操作被称为动态补全 (Dynamic padding),Hugging Face 也提供了
DataCollatorWithPadding类来进行,如果感兴趣可以自行了解。
训练模型
构建模型
常见的写法是继承 Transformers 库中的预训练模型来创建自己的模型。例如这里我们可以继承 BERT 模型(BertPreTrainedModel 类)来创建一个与上面模型结构完全相同的分类器:
#构建模型 from transformers import BertPreTrainedModel,BertModel,AutoConfig from torch import nn class BertForPartwiseCLs(BertPreTrainedModel): """ 定义模型继承自BertPreTrainedModel """ def __init__(self,config): """ 传入config,原始镜像的config """ super().__init__(config) #定义BertModel self.model=BertModel(config, add_pooling_layer=False) #丢弃10% self.dropout=nn.Dropout(config.hidden_dropout_prob) #全连接为2分类 self.classifier=nn.Linear(768,2) #初始化权重参数 self.post_init() def forward(self,input): #执行模型产生一个(批次,词元,隐藏神经元)的输出 bert_output=self.model(**input) #输出的数据有多个词元,取第一个[CLS]词元,因为每个词元通过注意力机制都包含了和其他词的语义信息,所以只需要一个即可 #这里句子的维度编程了[批次,1,768] vector_data=bert_output.last_hidden_state[:,0,:] vector_data=self.dropout(vector_data) logits=self.classifier(vector_data) return logits checkpoint = "bert-base-chinese" config=AutoConfig.from_pretrained(checkpoint) model=BertForPartwiseCLs.from_pretrained(checkpoint,config=config) print(model) X,y=next(iter(train_loader)) print(model(X).shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
输出
D:\python\evn311\Lib\site-packages\huggingface_hub\file_download.py:1132: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`. warnings.warn( Some weights of BertForPartwiseCLs were not initialized from the model checkpoint at bert-base-chinese and are newly initialized: ['bert.classifier.bias', 'bert.classifier.weight', 'bert.model.embeddings.LayerNorm.bias', 'bert.model.embeddings.LayerNorm.weight', 'bert.model.embeddings.position_embeddings.weight', 'bert.model.embeddings.token_type_embeddings.weight', 'bert.model.embeddings.word_embeddings.weight', 'bert.model.encoder.layer.0.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.0.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.0.attention.output.dense.bias', 'bert.model.encoder.layer.0.attention.output.dense.weight', 'bert.model.encoder.layer.0.attention.self.key.bias', 'bert.model.encoder.layer.0.attention.self.key.weight', 'bert.model.encoder.layer.0.attention.self.query.bias', 'bert.model.encoder.layer.0.attention.self.query.weight', 'bert.model.encoder.layer.0.attention.self.value.bias', 'bert.model.encoder.layer.0.attention.self.value.weight', 'bert.model.encoder.layer.0.intermediate.dense.bias', 'bert.model.encoder.layer.0.intermediate.dense.weight', 'bert.model.encoder.layer.0.output.LayerNorm.bias', 'bert.model.encoder.layer.0.output.LayerNorm.weight', 'bert.model.encoder.layer.0.output.dense.bias', 'bert.model.encoder.layer.0.output.dense.weight', 'bert.model.encoder.layer.1.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.1.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.1.attention.output.dense.bias', 'bert.model.encoder.layer.1.attention.output.dense.weight', 'bert.model.encoder.layer.1.attention.self.key.bias', 'bert.model.encoder.layer.1.attention.self.key.weight', 'bert.model.encoder.layer.1.attention.self.query.bias', 'bert.model.encoder.layer.1.attention.self.query.weight', 'bert.model.encoder.layer.1.attention.self.value.bias', 'bert.model.encoder.layer.1.attention.self.value.weight', 'bert.model.encoder.layer.1.intermediate.dense.bias', 'bert.model.encoder.layer.1.intermediate.dense.weight', 'bert.model.encoder.layer.1.output.LayerNorm.bias', 'bert.model.encoder.layer.1.output.LayerNorm.weight', 'bert.model.encoder.layer.1.output.dense.bias', 'bert.model.encoder.layer.1.output.dense.weight', 'bert.model.encoder.layer.10.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.10.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.10.attention.output.dense.bias', 'bert.model.encoder.layer.10.attention.output.dense.weight', 'bert.model.encoder.layer.10.attention.self.key.bias', 'bert.model.encoder.layer.10.attention.self.key.weight', 'bert.model.encoder.layer.10.attention.self.query.bias', 'bert.model.encoder.layer.10.attention.self.query.weight', 'bert.model.encoder.layer.10.attention.self.value.bias', 'bert.model.encoder.layer.10.attention.self.value.weight', 'bert.model.encoder.layer.10.intermediate.dense.bias', 'bert.model.encoder.layer.10.intermediate.dense.weight', 'bert.model.encoder.layer.10.output.LayerNorm.bias', 'bert.model.encoder.layer.10.output.LayerNorm.weight', 'bert.model.encoder.layer.10.output.dense.bias', 'bert.model.encoder.layer.10.output.dense.weight', 'bert.model.encoder.layer.11.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.11.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.11.attention.output.dense.bias', 'bert.model.encoder.layer.11.attention.output.dense.weight', 'bert.model.encoder.layer.11.attention.self.key.bias', 'bert.model.encoder.layer.11.attention.self.key.weight', 'bert.model.encoder.layer.11.attention.self.query.bias', 'bert.model.encoder.layer.11.attention.self.query.weight', 'bert.model.encoder.layer.11.attention.self.value.bias', 'bert.model.encoder.layer.11.attention.self.value.weight', 'bert.model.encoder.layer.11.intermediate.dense.bias', 'bert.model.encoder.layer.11.intermediate.dense.weight', 'bert.model.encoder.layer.11.output.LayerNorm.bias', 'bert.model.encoder.layer.11.output.LayerNorm.weight', 'bert.model.encoder.layer.11.output.dense.bias', 'bert.model.encoder.layer.11.output.dense.weight', 'bert.model.encoder.layer.2.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.2.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.2.attention.output.dense.bias', 'bert.model.encoder.layer.2.attention.output.dense.weight', 'bert.model.encoder.layer.2.attention.self.key.bias', 'bert.model.encoder.layer.2.attention.self.key.weight', 'bert.model.encoder.layer.2.attention.self.query.bias', 'bert.model.encoder.layer.2.attention.self.query.weight', 'bert.model.encoder.layer.2.attention.self.value.bias', 'bert.model.encoder.layer.2.attention.self.value.weight', 'bert.model.encoder.layer.2.intermediate.dense.bias', 'bert.model.encoder.layer.2.intermediate.dense.weight', 'bert.model.encoder.layer.2.output.LayerNorm.bias', 'bert.model.encoder.layer.2.output.LayerNorm.weight', 'bert.model.encoder.layer.2.output.dense.bias', 'bert.model.encoder.layer.2.output.dense.weight', 'bert.model.encoder.layer.3.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.3.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.3.attention.output.dense.bias', 'bert.model.encoder.layer.3.attention.output.dense.weight', 'bert.model.encoder.layer.3.attention.self.key.bias', 'bert.model.encoder.layer.3.attention.self.key.weight', 'bert.model.encoder.layer.3.attention.self.query.bias', 'bert.model.encoder.layer.3.attention.self.query.weight', 'bert.model.encoder.layer.3.attention.self.value.bias', 'bert.model.encoder.layer.3.attention.self.value.weight', 'bert.model.encoder.layer.3.intermediate.dense.bias', 'bert.model.encoder.layer.3.intermediate.dense.weight', 'bert.model.encoder.layer.3.output.LayerNorm.bias', 'bert.model.encoder.layer.3.output.LayerNorm.weight', 'bert.model.encoder.layer.3.output.dense.bias', 'bert.model.encoder.layer.3.output.dense.weight', 'bert.model.encoder.layer.4.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.4.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.4.attention.output.dense.bias', 'bert.model.encoder.layer.4.attention.output.dense.weight', 'bert.model.encoder.layer.4.attention.self.key.bias', 'bert.model.encoder.layer.4.attention.self.key.weight', 'bert.model.encoder.layer.4.attention.self.query.bias', 'bert.model.encoder.layer.4.attention.self.query.weight', 'bert.model.encoder.layer.4.attention.self.value.bias', 'bert.model.encoder.layer.4.attention.self.value.weight', 'bert.model.encoder.layer.4.intermediate.dense.bias', 'bert.model.encoder.layer.4.intermediate.dense.weight', 'bert.model.encoder.layer.4.output.LayerNorm.bias', 'bert.model.encoder.layer.4.output.LayerNorm.weight', 'bert.model.encoder.layer.4.output.dense.bias', 'bert.model.encoder.layer.4.output.dense.weight', 'bert.model.encoder.layer.5.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.5.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.5.attention.output.dense.bias', 'bert.model.encoder.layer.5.attention.output.dense.weight', 'bert.model.encoder.layer.5.attention.self.key.bias', 'bert.model.encoder.layer.5.attention.self.key.weight', 'bert.model.encoder.layer.5.attention.self.query.bias', 'bert.model.encoder.layer.5.attention.self.query.weight', 'bert.model.encoder.layer.5.attention.self.value.bias', 'bert.model.encoder.layer.5.attention.self.value.weight', 'bert.model.encoder.layer.5.intermediate.dense.bias', 'bert.model.encoder.layer.5.intermediate.dense.weight', 'bert.model.encoder.layer.5.output.LayerNorm.bias', 'bert.model.encoder.layer.5.output.LayerNorm.weight', 'bert.model.encoder.layer.5.output.dense.bias', 'bert.model.encoder.layer.5.output.dense.weight', 'bert.model.encoder.layer.6.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.6.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.6.attention.output.dense.bias', 'bert.model.encoder.layer.6.attention.output.dense.weight', 'bert.model.encoder.layer.6.attention.self.key.bias', 'bert.model.encoder.layer.6.attention.self.key.weight', 'bert.model.encoder.layer.6.attention.self.query.bias', 'bert.model.encoder.layer.6.attention.self.query.weight', 'bert.model.encoder.layer.6.attention.self.value.bias', 'bert.model.encoder.layer.6.attention.self.value.weight', 'bert.model.encoder.layer.6.intermediate.dense.bias', 'bert.model.encoder.layer.6.intermediate.dense.weight', 'bert.model.encoder.layer.6.output.LayerNorm.bias', 'bert.model.encoder.layer.6.output.LayerNorm.weight', 'bert.model.encoder.layer.6.output.dense.bias', 'bert.model.encoder.layer.6.output.dense.weight', 'bert.model.encoder.layer.7.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.7.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.7.attention.output.dense.bias', 'bert.model.encoder.layer.7.attention.output.dense.weight', 'bert.model.encoder.layer.7.attention.self.key.bias', 'bert.model.encoder.layer.7.attention.self.key.weight', 'bert.model.encoder.layer.7.attention.self.query.bias', 'bert.model.encoder.layer.7.attention.self.query.weight', 'bert.model.encoder.layer.7.attention.self.value.bias', 'bert.model.encoder.layer.7.attention.self.value.weight', 'bert.model.encoder.layer.7.intermediate.dense.bias', 'bert.model.encoder.layer.7.intermediate.dense.weight', 'bert.model.encoder.layer.7.output.LayerNorm.bias', 'bert.model.encoder.layer.7.output.LayerNorm.weight', 'bert.model.encoder.layer.7.output.dense.bias', 'bert.model.encoder.layer.7.output.dense.weight', 'bert.model.encoder.layer.8.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.8.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.8.attention.output.dense.bias', 'bert.model.encoder.layer.8.attention.output.dense.weight', 'bert.model.encoder.layer.8.attention.self.key.bias', 'bert.model.encoder.layer.8.attention.self.key.weight', 'bert.model.encoder.layer.8.attention.self.query.bias', 'bert.model.encoder.layer.8.attention.self.query.weight', 'bert.model.encoder.layer.8.attention.self.value.bias', 'bert.model.encoder.layer.8.attention.self.value.weight', 'bert.model.encoder.layer.8.intermediate.dense.bias', 'bert.model.encoder.layer.8.intermediate.dense.weight', 'bert.model.encoder.layer.8.output.LayerNorm.bias', 'bert.model.encoder.layer.8.output.LayerNorm.weight', 'bert.model.encoder.layer.8.output.dense.bias', 'bert.model.encoder.layer.8.output.dense.weight', 'bert.model.encoder.layer.9.attention.output.LayerNorm.bias', 'bert.model.encoder.layer.9.attention.output.LayerNorm.weight', 'bert.model.encoder.layer.9.attention.output.dense.bias', 'bert.model.encoder.layer.9.attention.output.dense.weight', 'bert.model.encoder.layer.9.attention.self.key.bias', 'bert.model.encoder.layer.9.attention.self.key.weight', 'bert.model.encoder.layer.9.attention.self.query.bias', 'bert.model.encoder.layer.9.attention.self.query.weight', 'bert.model.encoder.layer.9.attention.self.value.bias', 'bert.model.encoder.layer.9.attention.self.value.weight', 'bert.model.encoder.layer.9.intermediate.dense.bias', 'bert.model.encoder.layer.9.intermediate.dense.weight', 'bert.model.encoder.layer.9.output.LayerNorm.bias', 'bert.model.encoder.layer.9.output.LayerNorm.weight', 'bert.model.encoder.layer.9.output.dense.bias', 'bert.model.encoder.layer.9.output.dense.weight'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference. BertForPartwiseCLs( (model): BertModel( (embeddings): BertEmbeddings( (word_embeddings): Embedding(21128, 768, padding_idx=0) (position_embeddings): Embedding(512, 768) (token_type_embeddings): Embedding(2, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) (encoder): BertEncoder( (layer): ModuleList( (0-11): 12 x BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) (intermediate_act_fn): GELUActivation() ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) ) ) ) (dropout): Dropout(p=0.1, inplace=False) (classifier): Linear(in_features=768, out_features=2, bias=True) ) torch.Size([4, 2])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
可以看到模型输出了一个 4×2 的张量,符合我们的预期(每个样本输出 2 维的 logits 值分别表示两个类别的预测分数,batch 内共 4 个样本)。
tqdm使用
tqdm是一个Python库,用于在终端中显示进度条。它广泛应用于各种数据处理任务中,如循环、迭代器、pandas数据帧等。以下是对tqdm的简要介绍:
- 简单易用: tqdm提供了简单直观的API,可以快速集成到代码中,只需要几行代码即可实现进度条显示。
- 丰富的功能: tqdm不仅可以显示进度条,还可以显示预估的剩余时间、完成百分比、已处理的数据量等信息。
- 自动检测环境: tqdm可以自动检测运行环境,在支持ANSI转义码的终端中使用动态进度条,在不支持的环境中使用静态进度条。
- 支持各种迭代器: tqdm支持各种Python内置迭代器,如list、range、enumerate等,也支持自定义迭代器。
- 可定制性强: tqdm提供了丰富的参数供用户自定义进度条的样式和行为,如颜色、宽度、刷新间隔等。
代码
#tqdm进度条使用 from tqdm.auto import tqdm import time # 创建一个迭代对象,比如一个列表 items = range(10) # 使用tqdm来迭代这个对象,并显示进度条 for item in tqdm(items, desc='Processing'): # 在这里执行你的任务 time.sleep(0.1) # 模拟一些长时间运行的任务 # range(10) 其实就是0-9 print([i for i in range(10)]) #创建一个tqdm对象,传入得必须是range对象,range(10) 其实就是0-9 print(range(10),len(range(10))) tdm=tqdm(range(10), desc='Processing') for item in range(10): time.sleep(1) # 模拟一些长时间运行的任务 #更新一次,其实就是进度条加上: 1/len(range(10)) tdm.update(1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
效果
训练模型
在训练模型时,我们将每一轮 Epoch 分为训练循环和验证/测试循环。在训练循环中计算损失、优化模型的参数,在验证/测试循环中评估模型的性能,与 Pytorch 类似,Transformers 库同样实现了很多的优化器,并且相比 Pytorch 固定学习率,Transformers 库的优化器会随着训练过程逐步减小学习率(通常会产生更好的效果)。例如我们前面使用过的 AdamW 优化器
完整的训练过程,可与使用colab来进行训练。
#训练模型和验证测试 #定义损失函数 from torch.nn import CrossEntropyLoss from transformers import get_scheduler #定义优化函数,from torch.optim import AdamW from transformers import AdamW from tqdm.auto import tqdm #定义epoch训练次数 epochs = 3 #默认学习率 learning_rate = 1e-5 # batchsize batch_size=4 #AdamW是Adam优化器的一种变体,它在Adam的基础上进行了一些改进,旨在解决Adam优化器可能引入的权重衰减问题。 optimizer=AdamW(model.parameters(),lr=1e-5) #定义交叉熵损失函数 loss_fn=CrossEntropyLoss() #重新初始化数据集 train_loader=DataLoader(train_data,batch_size=batch_size,shuffle=False,collate_fn=collote_fn) dev_loader=DataLoader(MyDataSet("dev.json"),batch_size=batch_size,shuffle=False,collate_fn=collote_fn) #总步数=epoch*批次数(总记录数train_data/一批次多少条数据batch_size) num_training_steps = epochs * len(train_loader) #默认情况下,优化器会线性衰减学习率,对于上面的例子,学习率会线性地从le-5 降到0 #。为了正确地定义学习率调度器,我们需要知道总的训练步数 (step),它等于训练轮数 (Epoch number) 乘以每一轮中的步数(也就是训练 dataloader 的大小) lr_scheduler = get_scheduler( "linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps, ) #初始化模型 device = 'cuda' if torch.cuda.is_available() else 'cpu' checkpoint = "bert-base-chinese" config=AutoConfig.from_pretrained(checkpoint) model=BertForPartwiseCLs.from_pretrained(checkpoint,config=config).to(device) #定义总损失 total_loss=0 #完成总batch complete_batch_count=0 #最好的正确率 best_acc = 0. current_directory = os.getcwd() for step in range(epochs): #进入训练模式 model.train() print(f"Epoch {step+1}/{epochs}\n-------------------------------") progress_bar=tqdm(range(len(train_loader))) for batch,(X,y) in enumerate(train_loader): X,y=X.to(device),y.to(device) #获取预测结果 pred=model(X) #计算损失函数 loss=loss_fn(pred,y) #清空梯度 optimizer.zero_grad() #前向传播 loss.backward(); #更新模型参数 optimizer.step(); #学习率线性下降,必须是更新模型参数之后,函数根据设定的规则来调整学习率。这个调整需要基于当前的模型状态,包括参数、损失函数值等,所以要放在optimizer.step()之后。 lr_scheduler.step() total_loss+=loss.item() complete_batch_count+=1 avg_loss=total_loss/complete_batch_count progress_bar.set_description("loss:{}".format(avg_loss)) progress_bar.update(1) #使用验证集验证模型正确性。 #进入预测模式,当前这一次epoch训练数据的正确率 model.eval() correct=0 #加载验证集的数据 for batch,(X,y) in enumerate(dev_loader): #获取预测结果 pred=model(X) #因为是[[0.9,0.1],[0.3,0.4]]所以取dim=1维度上最大值的索引,概率大的索引就是预测的类别,如果和label值y相等就加起来,算个数 correct += (pred.argmax(dim=1) == y).type(torch.float).sum().item() #正确/总数就是争取率 valid_acc=correct/len(dev_loader.dataset) print(f"{step+1} Accuracy: {(100*valid_acc):>0.1f}%\n") if valid_acc > best_acc: best_acc = valid_acc print('saving new weights...\n') torch.save(model.state_dict(), current_directory+f'/epoch_{step+1}_valid_acc_{(100*valid_acc):0.1f}_model_weights.bin') print("Done!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
模型预测
最后,我们加载验证集上最优的模型权重,汇报其在测试集上的性能。由于 AFQMC 公布的测试集上并没有标签,无法评估性能,这里我们暂且用验证集代替进行演示:
current_directory = os.getcwd()
model.load_state_dict(torch.load(current_directory+'/model_weights.bin'))
model.eval()
test_loader=DataLoader(test_data,batch_size=4,shuffle=False,collate_fn=collote_fn)
X,y=next(iter(test_loader))
X, y = X.to(device), y.to(device)
pred = model(X)
print(pred.argmax(1) == y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
文章部分文字引用:https://transformers.run/c2/2021-12-17-transformers-note-4/


