
- 1100天玩转python——day53 接入第三方平台服务(API、SDK方式)_python调用sdk接口
- 2QP简介
- 3聊聊如何在内网下构建大模型微调环境
- 4git pull origin master(git merger)与git pull --rebase origin master(git --rebase)的区别_git pull origin master --rebase
- 5Redis DeskTop Manager 使用教程
- 6Ei国际学术会议投稿教程_ei会议投稿艾思科蓝
- 7关于Unity里面UGUI的Text字体无法显示以及尺寸无法改变的问题_unity text组件文本修改无效
- 8通过post修改别人服务器时间,如何更改电话服务器时间设置方法
- 9最近找到了一个免费的python教程,两周学会了python开发【内附学习视频】_1对1教python
- 102020年流动式起重机司机新版试题及流动式起重机司机作业考试题库_在起重作业中尽量使货物的重心在两根起吊绳的
随机森林算法梳理_随即森林数学公式树的深度
赞
踩
随机森林算法梳理
目录
1. 集成学习概念
集成学习是指通过构建并结合多个学习器来完成学习任务的策略,其一般结构:先产生一组“个体学习器”再通过某种策略将它们结合起来。集成学习通过将多个学习期进行结合,通常可获得比单一学习器显著优越的泛化性能。这对“弱学习器”尤为明显,(弱学习器是指泛化性能略优于随机猜测的学习器)因此集成学习很多理论研究都是针对弱学习器进行的,而基学习器有时也被称作弱学习器。值得注意的是集成学习所集成的各个学习器,应该是“好”而“不同”,即每个学习器都有较好的一方面,而且应是各有所长,满足集成学习的多样性,才能达到较好的泛化能力。
2. 个体学习器概念
个体学习器通常是由一个现有的学习算法从训练集数据产生,例如C4.5决策树算法、BP神经网络算法等,根据个体学习器种类的不同,集成又分为“同质”集成和“异质”集成两种,其中同质集成中的个体学习器成为“基学习器”,代表同种类型的学习器,异质集成中的个体学习器称为“组件学习器”,代表着不同算法组成的学习器。
3. boosting bagging
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即以"随机森林"为代表的Bagging生成方式,和以"Adavoost算法"和“GBDT算法”为代表的Boosting生成方式。
3.1.1Boosting 的思想
通过对样本进行不同的赋值,对学习错误的样本设置较大的权值,这样在后续的学习中集中处理难学的样本,最终得到一系列的预测结果,每个预测结果有一个权值,权值越大表示该预测效果越好。通过改变每次学习的样本分布来达到多样性的效果。
3.1.2Boosting的特点
学习器间存在强依赖关系,必须串行生成,集成方式为加权和,Boosting主要关注降低偏差
3.2.1Bagging的思想
主要通过对训练数据集进行随机有放回的采样,以组合成不同的数据集,利用弱学习器对不同的新数据集进行学习,得到一系列的预测结果,对这些预测结果做平均或者投票做出最终的预测。通过有放回的随机重采样来构建不同的训练集达到多样性的效果
3.2.2Bagging的特点
学习器间不存在强依赖关系,学习器可以并行训练生成,集成方式一般为投票的方式,Bagging主要关注降低方差
4. 结合策略(平均法,投票法,学习法)
4.1平均法
平均法主要针对数值型输出,即回归预测问题。
1.简单平均法

2.加权平均法

3.优缺点和适用场景
加权平均的权重一般是从训练数据中学习而得,现实任务中的训练样本通常不充分或存在噪声,这将使得学出的权重不完全可靠,尤其是对规模比较大的集成来说,要学习的权重比较多,较容易导致过拟合。因此,实验和应用均显示出,加权平均法未必一定优于简单平均法。适用场景:一般而言,在个体学习器性能相差较大时宜适用加权平均法,而在个体学习器性能相近时宜使用简单平均法。
4.2投票法
投票法主要用于分类任务的结合策略
1.绝对多数投票法
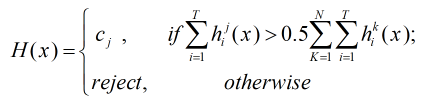
即若某标记的票数过半,则预测结果为该标记的值;否则拒绝预测
2.相对多数投票法

即预测为得票最多的标记,若同时有多个标记获得最高票,则从中随机选取一个。
3.加权投票法

4.3学习法
当训练数据很多时,一种更为强大的结合策略是使用“学习法”,即通过另一个学习器来进行结合。其中Stacking是学习法的典型代表。Stacking 先从初始数据集训练出初级学习器,然后“生成”一个新的数据集用于训练次级学习器。在这个新数据集中,初级学习器的输出被当做样例输入特征,而初始样本的标记仍被当做样例标记。
5. 随机森林思想
随机森林是Bagging的一个扩展变体,随机森林在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有d个属性)中选择一个最优属性;而在随机森林中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包括k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。参数k控制了随机性的引入程度,若k=d,则基决策树构建与传统决策树相同;若k=1,则随机选择一个属性用于划分,一般情况下推荐值k=log2 d
6. 随机森林的推广
Extra Tree
Totally Random Trees Embedding(TRTE)
Isolation Forest
7. 优缺点
优点
1.可以处理高维数据,不同进行特征选择(特征子集是随机选择)
2.模型的泛化能力较强
3.训练模型时速度快,成并行化方式,即树之间相互独立
4.模型可以处理不平衡数据,平衡误差
5.最终训练结果,可以对特种额排序,选择比较重要的特征
6.随机森林有袋外数据(OOB),因此不需要单独划分交叉验证集
7.对缺失值、异常值不敏感
8.模型训练结果准确度高
9.相对Bagging能够收敛于更小的泛化误差
缺点
1.当数据噪声比较大时,会产生过拟合现象
2.对有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响
8. sklearn参数2
class sklearn.ensemble.RandomForestClassifier(n_estimators=’warn’, criterion=’gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None)
n_estimators:随机森林树的数量
criterion:衡量生成的随机森林质量的参数
max_depth:随机森林树的最大深度
min_samples_split:树分裂的最小个数
min_samples_leaf :某一叶节点上样本的最小数量
min_weight_fraction_leaf:叶结点的最小加权分数
max_features:在生成最佳森林时最大特征数
max_leaf_nodes:最大叶结点
min_impurity_decrease:如果某一节点分裂后,随机森林减少的熵大于此值则增加该分支
bootstrap:在生成树随机森林时,是否采用bootstrap样本
oob_score:是否使用out-of-bag样本测试泛化性
n_jobs:是否使用多线程
random_state :随机种子
verbose:在优化和预测时控制模型详细程度
warm_start:是否重新生成随机森林
class_weight:每一等级的权重
9.应用场景
随机森林可以应用于回归和分类任务上,取决于随机森林的每颗树是分类树还是回归树
- 如果cart树是分类树,那么采用的计算原则就是gini指数。随机森林基于每棵树的分类结果,采用多数表决的手段进行分类。
- 如果是回归树,则cart树是回归树,采用的原则是最小均方差。即对于任意划分特征A,对应的任意划分点s两边划分成的数据集D1和D2,求出使D1和D2各自集合的均方差最小,同时D1和D2的均方差之和最小所对应的特征和特征值划分点。公式表示如下
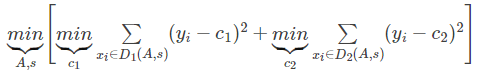
其中,c1为D1数据集的样本输出均值,c2为D2数据集的样本输出均值。
cart树的预测是根据叶子结点的均值,因此随机森林的预测是所有树的预测值的平均值。

