
- 1无人机之电池保养
- 2深度学习在医疗健康领域的应用:疾病预测_深度学习与疾病
- 3AI绘画Stable diffusion的SDXL模型超详细讲解,针不错!(含实操教程)_total amount of video memory allocated by the torc
- 4ubuntu18.04下深度学习环境的配置过程(pytorch、cuda、cudnn)_ubuntu18.04下安装深度学习的库函数
- 5关于利用IBERT核对GTX收发器板级测试的原理与过程详解_gtx ibert
- 6lodash源码分析之Number_lodash hex转num
- 72023全国安全生产合格证危险化学品经营单位安全管理人员真题练习_依据《危险化学品安全管理条例》的规定,依法设立的危险化学品生产企业在其厂区范
- 8动态跨数据库库同步数据_dbsyncer-plugin-demo
- 9显色指数测试软件,显色性
- 10MySQL-存储过程(PROCEDURE)_4.5过程调用…………………………45
Java-Redis基本使用大全_java redis
赞
踩
概念
redis是一款高性能的NOSQL系列的非关系型数据库
NoSQL(NoSQL = Not Only SQL),意即“不仅仅是SQL”,是一项全新的数据库理念,泛指非关系型的数据库。
NOSQL和关系型数据库比较
优点:
- 成本: nosql数据库相比关系型数据库价格便宜。
- 查询速度: nosql数据库将数据存储于缓存之中,速度快
- 存储数据的格式: nosql的存储格式是key,value形式、文档形式、图片形式等等
- 扩展性: 关系型数据库有类似join这样的多表查询机制,导致扩展很艰难
缺点:
1)维护的工具和资料有限
2)不提供对sql的支持
3)不提供关系型数据库对事务的处理
非关系型数据库的优势:
1)性能NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
2)可扩展性同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
关系型数据库的优势:
1)复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
2)事务支持使得对于安全性能很高的数据访问要求得以实现。对于这两类数据库,对方的优势就是自己的弱势,反之亦然。
总结:
关系型数据库与NoSQL数据库并非对立而是互补的关系,即通常情况下使用关系型数据库,在某些访问比较频繁的数据我们可以存储在 redis中来提高查询的速度,让NoSQL数据库对关系型数据库的不足进行弥补。
一般会将数据存储在关系型数据库中,在noSql数据库中备份存储关系型数据库的数据来提高QPS
主流的NOSQL产品:
键值(Key-Value)存储数据库
相关产品: Redis ,MongoDB
典型应用: 内容缓存,主要用于处理大量数据的高访问负载。
数据模型: 一系列键值对
优势: 快速查询
劣势: 存储的数据缺少结构化
还有以下产品:
列存储数据库,文档型数据库,图形(Graph)数据库 …
什么是Redis
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s ,且Redis通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如下:
key,value格式的数据,其中key都是字符串 value 有5种格式
-
字符串类型String
-
哈希类型 Hash ( map格式)
-
列表类型 List (ArrayList格式)
-
集合类型Set 不允许重复元素 (HashSet格式)
-
有序集合类型 Sortedset 不允许重复元素,且元素有顺序 (本质上就是HashSet但是在这个基础上提供了手动排序(分数))
Redis 主要用途不是存数据而是做缓存实际的数据都是保存在数据库里 , 数据库(本地磁盘)和 Redis(内存)哪一个访问数据快不用想肯定是内存 ,内存好点的话可以 快 物理磁盘几十倍的速度甚至上百倍的读写速度,既然这样我们可以将第一次从数据库查询出来的数据保存在 Redis中进判断如果redis中有数据那么就从Redis中获取如果没有那么从数据库中获取然后保存到Redis中
比如
@Override
public String show() {
JedisPool pool= JedisUtil.getPool();
Jedis jedis=pool.getResource();
if (jedis.get("show")!=null){
return jedis.get("show");
}else{
List<javaBean> list= service_inter.show();
String json= JSON.toJSONString( list);
jedis.set("show",json);
return json;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这代码的意思就是 如果在redis中show有值那么就将此key中存储的值返回
如果没有在从数据库查询出来 然后 重新存入show中并将值返回
redis的应用场景
缓存(数据查询、短连接、新闻内容、商品内容等等)
• 聊天室的在线好友列表
• 任务队列。(秒杀、抢购、12306等等)
• 应用排行榜
• 网站访问统计
• 数据过期处理(可以精确到毫秒
• 分布式集群架构中的session分离
Redis下载安装地址
https://github.com/tporadowski/redis/releases

链接:https://pan.baidu.com/s/1kFtQNnC1FUrlsmL2J9xddQ
提取码:1234
文件内容介绍:
redis.windows.conf:配置文件
redis-cli.exe: redis的客户端
redis-server.exe:redis服务器端
appendonly.aof 缓存文件(当持久化后的数据就会存储在这里)(如果没有数据这个文件是不存在的)
使用顺序 先打开服务端 然后不要关闭 在打开客户端 在客服端使用命令操作就行了
一般情况都是在代码里使用 这一步只是测是否能用
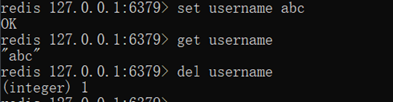
字符串类型String 操作方法
string格式
-
存储: set key value
列: set username abc
-
获取: get key
列: get username
-
删除: del key
列: del username
哈希类型 hash 操作方法
map格式
- 存储:hset key field value
key 主要就是区分不同map, 相当于java对象的意思.不要弄成java中的key了
而域(field)就是map中的 key value就是值了
hset hash_day1 password 123
- 获取:
hget hash_day1 username 获取指定的field
hgetall hash_day1 获取所有的key 和value
- 删除:
hdel hash_day1 username //删除指定的field

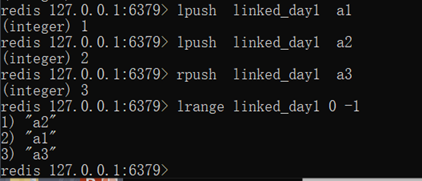
列表类型 list 操作方法
只支持linkedlist格式 前后
- 添加:
1. lpush key value: 从开头插入
lpush linked_day1 a1
2. rpush key value:从最后插入
rpush linked_day1 a3
- 获取:
lrange key start end :范围获取
lrange linked_day1 0 -1 (从开始到最后)
- 删除:
lpop key: 删除列表最左边的元素,并将元素返回
lpop linked_day1
rpop key: 删除列表最右边的元素,并将元素返回
rpop linked_day1

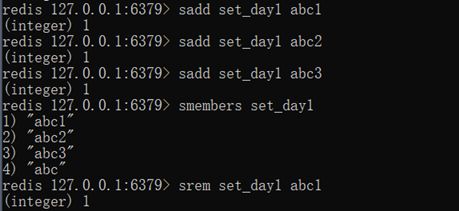
集合类型 set 操作方
不允许重复元素
-
存储: sadd key value
sadd set_day1 a
-
获取:
smembers set_day1 (全部value)
-
删除: srem key value
srem set_day1t abc1
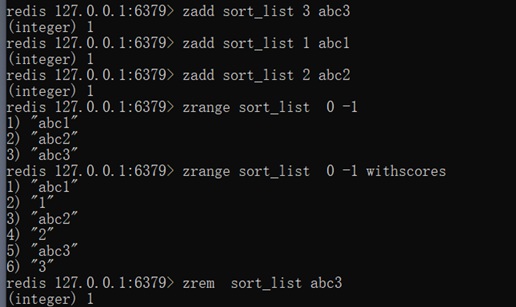
有序集合类型 sortedset 操作方法
不允许重复元素,且元素有顺序.每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序
- 存储:zadd key score value
zadd sort_list 3 abc3
zadd sort_list 1 abc1
zadd sort_list 2 abc2
-
获取:zrange key start end [withscores]
zrange mysort 0 -1 (只显示 value)
zrange mysort 0 -1 withscores (分数也显示)
-
删除:zrem key value
zrem mysort lisi
通用命令
-
keys * : 查询数据库中所有的键 (相当于数据库中所有的表)
-
type key : 获取数据库中键对应的类型 (相当于表的类型)
-
del key: 删除指定数据库的key 和此key下所有value (相当于删除表)

- flushall 清空Redis服务全部数据
Redis持久化
redis是一个内存数据库,当redis服务器重启,或者电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘的文件中。这就就不会丢失数据了
一般情况下 都不要设置 默认就行了 因为redis 主要是用于数据缓存 的 实际的数据都是存在 数据库中的
保存的内容都保存在appendonly.aof这个文件中 (一开始是没有此文件的 当持久化后会自动生成 )
使用持久化那么 启动服务器的时候必须指定配置文件 否则 无效
语法 redis-server.exe redis.windows.conf
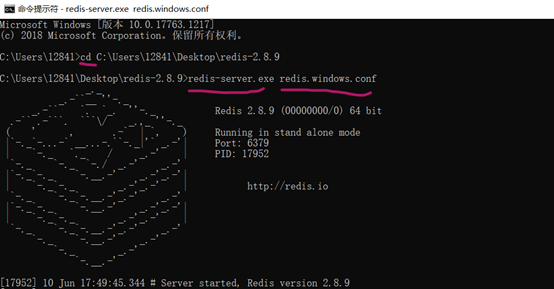
-
RDB:默认方式,不需要进行配置,默认就使用这种机制
在一定的间隔时间中,检测key的变化情况,然后持久化数据打开 redis.windwos.conf 配置文件 然后ctrl+f 快捷搜索 save 900 1

save 900 1 代表的意思 就是 900秒后至少有一个键被改变 就会持久化
在900内 添加了一个键 那么900后就会持久化
save 300 10 代表的意思 就是 300秒后至少有10个键被改变 就会持久化
以此类推 ,可以自定义规则 比如 save 10 5 10秒内5个键被改变了那么10秒后就会持久化
-
AOF:日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据
打开redis.windwos.conf文件ctrl+f快捷键搜索appendonly
默认为no 将此值设置为yes 就开启了AOF 然后往下找 就能看见
appendfsync always 每一次操作都进行持久化
appendfsync everysec 规则意思就是每隔一秒进行一次持久化 (默认)
appendfsync no 不进行持久化
根据情况进行开启 使用 appendfsync always模式的话会占用一些性能 但是保证了数据的安全了不会丢失
注意事项 Redis默认就会开启持久化策略 但是如果不去管缓存文件的大小写等 迟早内存会gg了
设置缓存文件清理策略
如果内存到达了指定的上限,还要往redis里面添加更多的缓存内容,需要设置清理内容的策略:
默认为0,没有指定最大缓存,如果有新的数据添加,超过最大内存,则会使redis崩溃,
大概在520~600行左右 # maxmemory <bytes> 下面配置
maxmemory 314572800 相当于 300mb
设置maxmemory之后,就需要配合 缓存数据回收策略。 当 maxmemory满了就会触发进行清理
下面为redis官网上的几种清理策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰 (常用)
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
maxmemory-policy allkeys-lru

使用命令方式设置配置
如果你不想在配置文件里配置我们可以通过命令配置
登录客户端
redis-cli -h 81.70.77.136
如果有账户密码的话
redis-cli -h ip地址 -p 6379 -a 密码
- 1
- 2
- 3
- 4
语法: config set key value
config set maxmemory 100MB
config set maxmemory-policy allkeys-lru
config set maxmemory-samples 3
- 1
- 2
- 3
查询
config get maxmemory
config get maxmemory-policy
config get maxmemory-samples
- 1
- 2
- 3
使用java连接Redis
如果使用maven :
<!-- Redis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.9.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意: 在用java操作Redis前必须开启Redis服务器 否则 会出现连接失败
通过 Jedis jedis = new Jedis(“localhost”,6379); 或者 Jedis jedis = new Jedis();
默认就是 Localhost 6379 来连接服务器 以下是5种value格式操作方法
字符串String
@Test
public void show1(){
// Jedis jedis = new Jedis("localhost",6379);
Jedis jedis = new Jedis(); //默认就是 Localhost 6379
/// 2. 操作
String ok= jedis.set("username","zhangsan");
if (!ok.equals("OK")){
System.out.println("添加成功");
}
String username = jedis.get("username");
//删除 可以传入多个参数 或者 字符串数组 删除多个 删除成功返回 1
Long de= jedis.del("username"); //del 参数是泛型
// 3. 关闭连接
jedis.close();
System.out.println(username);
System.out.println("删除结果:"+de);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
哈希 map
双列存储 无序也就是查询的时候和插入的顺序可能不一致 键唯一 值不唯一
@Test
public void show2(){
//打开连接
Jedis jedis = new Jedis(); //默认就是 Localhost 6379
Long add= jedis.hset("Mymap","user","hu");
Long add1=jedis.hset("Mymap","pass","123");
System.out.println(add+"_"+add1);
//获取指定 map 里的key的值
String user=jedis.hget("Mymap","user");
String pass=jedis.hget("Mymap","pass");
//获取指定 map 里的多个key的值
List<String> hmget = jedis.hmget("Mymap", "user", "pass");
System.out.println(hmget);
//查询map中指定的key是否存在
Boolean hexists = jedis.hexists("Mymap", "user");
System.out.println(hexists);
//第二个参数, 可以删除多个,传入字符串数组,或者多个参数 删除成功返回 1
Long de=jedis.hdel("Mymap","user","pass");
//关闭连接
jedis.close();
System.out.println(user);
System.out.println(pass);
System.out.println("删除结果:"+de);
//打印所有 哈希 map 里的值
Map<String, String> map=jedis.hgetAll("Mymap");
Set<String> set=map.keySet();
for (String key:set){
System.out.println("键:"+key);
System.out.println("值:"+map.get(key));
}
}
还可以直接传进入map
Map map = new HashMap();
map.put("field1", "value");
map.put("field2", "value");
jedis.hmset("key1", map);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
列表List
单例集合 有序 数据可重复 常用于 记录消息… 内容
@Test
public void show3(){
//打开连接
Jedis jedis = new Jedis(); //默认就是 Localhost 6379
//插入单个值 返回插入的位置
Long add= jedis.lpush("day1","a"); //添加开头位置
Long add1= jedis.rpush("day1","b"); //从结尾处添加
Long add2= jedis.rpush("day1","c"); //从结尾处添加
System.out.println(add+"_"+add1+"_"+add2);
//插入多个值 返回总长度
Long rpush = jedis.rpush("day1", "d", "e", "f");
System.out.println("插入多个值"+rpush);
//获取List长度
Long day11 = jedis.llen("day1");
System.out.println("List长度"+day11); //3
//删除开头元素 删除成功将 删除的值返回 每次只能删除一个 如果想要删除多个可以用循环
String value_l=jedis.lpop("day1");
//删除结尾元素 删除成功将 删除的值返回 每次只能删除一个 如果想要删除多个可以用循环
String value_r=jedis.rpop("day1");
if (value_l!=null&&value_r!=null){
System.out.println("删除成功");
System.out.println("删除的值是:"+value_l+"___"+value_r);
}
1364110
// 获取指定区间的数据
// 其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推
// -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
List<String> list= jedis.lrange("day1",0,-1);
//查询
for (String li:list){
System.out.println(li);
}
// b a c
// 获取指定下标元素
String day1 = jedis.lindex("day1", 0);
System.out.println(day1); //b
//对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
//下标 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,
// 以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
//命令执行成功时,返回 ok 。
String day12 = jedis.ltrim("day1", 0, -1);
System.out.println(day12);
jedis.close();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
集合set
单列存储 注意 是无序的 但是值唯一 常用于记录关键信息 保证数据的唯一 同时也不需要顺序 比如: 人员名称
@Test
public void show5(){
//打开连接
Jedis jedis = new Jedis(); //默认就是 Localhost 6379
//添加1个或者多个值 添加成功 返回成功的数量 否则返回0
Long sadd = jedis.sadd("ser", "a", "b", "c", "e", "f");
System.out.println(sadd); //5
//获取集合中元素的数量
Long ser = jedis.scard("ser");
System.out.println(ser); //5
//查询 集合中是否包含 指定元素
Boolean hexists = jedis.sismember("ser", "a");
System.out.println(hexists); //true
//获取集合中所有成员
Set<String> ser1 = jedis.smembers("ser");
System.out.println(ser1); //[e, b, f, a, c]
//随机从集合中 抽取一个元素
String ser2 = jedis.srandmember("ser");
System.out.println(ser2); //c
//随机从集合中 抽取多个元素
List<String> ser3 = jedis.srandmember("ser", 2);
System.out.println(ser3); //[e, c]
//删除一个 或者多个 元素 返回删除的个数 删除失败返回0
Long srem = jedis.srem("ser", "a", "c");
System.out.println(srem);
jedis.close();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
有序集合sortedset
单列存储 类似等同于 set 但是数据是有序的
(常用于分表分类存储 或者员工 的工资 )
@Test
public void show5(){
//打开连接
Jedis jedis = new Jedis(); //默认就是 Localhost 6379
// 向有序list 里添加值 一次只能添加一个 插入成功返回1 失败0
// 第二个参数是分数 意思是指定顺序 正是通过此数值来为集合中的成员进行从小到大的排序。如果数值相同那么就按照插入的顺序
//注意 值是唯一的 相同的值会被覆盖的
Long add= jedis.zadd("mysort",0,"aaaa");
Long add1 =jedis.zadd("mysort",0,"bbbb");
Long add2 =jedis.zadd("mysort",1,"cccc");
Long add3 =jedis.zadd("mysort",1,"dddd");
Long add4 =jedis.zadd("mysort",2,"eeee");
Long add5 =jedis.zadd("mysort",2,"ffff");
Long add6 =jedis.zadd("mysort",3,"gggg");
Long add7 =jedis.zadd("mysort",3,"hhhh");
System.out.println(add+"_"+add1+"_"+add2);
//获取集合长度
Long mysort = jedis.zcard("mysort");
System.out.println("数量"+mysort);
//第二个参数, 可以删除多个或单个值 删除成功返回 1 失败返回0
long de= jedis.zrem("mysort","aaaa","bbbb");
System.out.println("删除结果"+add);
//删除指定 分数 或者 分区区间 内全部值
// 1 ,1 代表删除 1分数内全部值
//1,3 代表删除 1 2 3 这些分数内全部值
// 0 , -1 代表 清空
Long mysort3 = jedis.zremrangeByScore("mysort", 1, 1);
System.out.println("删除结果"+mysort3);
//通过索引区间 获取值 0,0 代表第一个 0,2 代表获取前三个
//0 表示有序集第一个成员,以 1 表示有序集第二个成员,以此类推。
// -1 表示最后一个成员, -2 表示倒数第二个成员,以此类推。
Set<String> set= jedis.zrange("mysort",0,-1);
for (String in:set){
System.out.print(in+",");
}
//eeee,ffff,gggg,hhhh,
System.out.println();
//返回 指定分数内全部的值
Set<String> mysort1 = jedis.zrangeByScore("mysort", 3, 3);
System.out.println(mysort1); //[gggg, hhhh]
// 返回 区间分数 全部值
Set<String> mysort2 = jedis.zrangeByScore("mysort", 1, 3);
System.out.println(mysort2); // [eeee, ffff, gggg, hhhh]
jedis.close();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
注意 set sortedset 这些数据结构 还有 一些不常用的方法 我上面也没演示 我就稍微讲一下 以后用到了到百度上找
-
交集
交集就是2个集合 相同的地方 (返回新的集合) 比如:(1,2,3)和(1,4,5) 结果(1)
-
差集
差集就是2个集合不同的地方 (返回新的集合) 比如:(1,2,3)和(1,3,4) 结果( 2,4)
-
并集
就是将2个集合合并 相同的地方抵消 (返回新的集合) 比如(1,2,) 和(1,2,3,4) 结果(1,2,3,4)
除了以上还有一些零零散散的方法 这里就不说了 不重要 几乎用不上
Jedis连接池
//普通连接池
@Test
public void show6(){
JedisPoolConfig config=new JedisPoolConfig();
config.setMaxTotal(50);//最大连接数量
config.setMaxIdle(10);//最大空闲时间
JedisPool pool=new JedisPool(config,"localhost",6379);
Jedis jedis=pool.getResource();//从连接池获取连接
String ok= jedis.set("conut","123");
if (!ok.equals("OK")){
System.out.println("添加失败");
}
System.out.println( jedis.get("conut"));
}
//配置文件jedis.properties 连接池 在下面有写好的连接池类和配置文件
@Test
public void show7(){
Jedis jedis = JedisUtil.Jedis();
jedis.set("user","abc");
System.out.println(jedis.get("user"));
jedis.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
配置文件目录resource ,文件名称 jedis.properties
#你的主机ip
host=127.0.0.1
#Redis端口
port=6379
# 最大活动连接数 (多少个线程同时访问Redis的上限)
maxTotal=50
# 最大空闲数 (待机状态)
maxIdle=10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
获取连接工具类JedisUtil
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
public class JedisUtil {
private static JedisPool jedisPool=null;
private static Jedis jedis=null;
static {
InputStream inputStream= JedisUtil.class.getClassLoader().getResourceAsStream("jedis.properties");
Properties properties=new Properties();
try {
properties.load(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
JedisPoolConfig config=new JedisPoolConfig();
config.setMaxTotal(Integer.parseInt(properties.getProperty("maxTotal")));//最大连接数量
config.setMaxIdle(Integer.parseInt(properties.getProperty("maxIdle")));//最大空闲时间
// statc是共享的 连接不一样是 无法返回到连接池 所以防止多次new (多线程)
if (jedisPool==null){
jedisPool=new JedisPool(config,properties.getProperty("host"),Integer.parseInt(properties.getProperty("port")));
}
}
private static JedisPool getPool(){
return jedisPool;
}
//获取 连接
public static Jedis Jedis(){
JedisPool pool= JedisUtil.getPool();
jedis=pool.getResource();
return jedis ;
}
//关闭连接 其实就是将连接返回池中
public static void close(){
if (jedis!=null){
jedis.close();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
Jedis其他方法
查询所有的key
Set keys = jedis.keys(“*”);
for (String key:keys){
System.out.println(key);
}
JedisUtil.close();
清空所有的key
jedis.flushAll();
返回全部key的个数
jedis.dbSize();
设置key生存时间,当key过期时,它会被自动删除
jedis.expire(“key1”, 5);//5秒过期
在字符串格式中 可以同时设置key和value 和过期时间
jedis.setex(“key”, 5, “haha”);
移除指定的key的生存时间(设置这个key永不过期)
jedis.persist(“key1”);
检查给定key是否存在
jedis.exists(“key1”);
将key改名为key2,当key和key2相同或者key1不存在时,返回一个错误
jedis.rename(“key1”, “key2”);
返回指定key所储存的值的类型
类型: none(key不存在), string(字符串),list(列表),set(集合),zset(有序集),hash(哈希表)
jedis.type(“key1”);
返回一个集合的全部成员,该集合是所有给定集合的交集
意思是多个set集合中 有哪些值是相同的 然后返回出来
比如 在命令里
redis 127.0.0.1:6379> SADD myset “hello”
redis 127.0.0.1:6379> SADD myset “foo”
redis 127.0.0.1:6379> SADD myset “bar”
redis 127.0.0.1:6379> SADD myset2 “hello”
redis 127.0.0.1:6379> SADD myset2 “world”
redis 127.0.0.1:6379> SINTER myset myset2
结果 hello
java中的代码:
jedis.sinter(“key1”,“key2”)
返回一个集合的全部成员,该集合是所有给定集合的并集
意思是 将几个set集合合并 多个值相同只返回一个 不同的全部返回
比如 在命令里
redis> SADD key1 “a”
redis> SADD key1 “b”
redis> SADD key1 “c”
redis> SADD key2 “c”
redis> SADD key2 “d”
redis> SADD key2 “e”
redis> SUNION key1 key2
结果 acbed
java中的代码:
jedis.sunion(“key1”,“key2”)
返回一个集合的全部成员,该集合是所有给定集合的差集
也就是多个set集合中相同的值去掉 将剩下的返回
比如
key1 = {a,b,c,d}
key2 = {c}
key3 = {a,c,e}
SDIFF key1 key2 key3
结果:{b,d}
java中的代码
jedis.sdiff(“key1”,“key2”);
windows 下启动redis服务闪退问题
第一步:在解压的redis文件夹下新建一个start.bat(window启动一般都是xx.bat
第二步:打开redis.windows.conf文件,限制内存
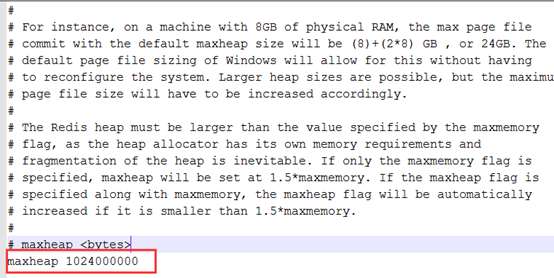
maxheap 1024000000
第三步:在新建的start.bat文件中加入下面一句话(因为启动redis需要用到这两个文件)
redis-server.exe redis.windows.conf
以上三个步骤完成之后,保存,双击start.bat即可启动,启动成功如下:

redis开启外网访问
当你的reids装在服务器上的时候 如果想让其他网络的人能访问到那么就需要开启 外网访问了 一般用于测试的时候
当项目上线的时候 换成本地 因为会导致数据丢失或者被盗
-
开放端口,默认6379 (或者关闭防火墙)
-
修改redis.conf配置文件
- bind 127.0.0.1 注释掉
- protected-mode no 关闭保护模式,这样外网可以访问到
重启redis启动
以上就是开启外网访问的流程 命令因为系统的不同 需要自己到网上找
远程外网访问:
redis-cli -h 192.168.81.146 -p 6379 -a 123456
- 1
Redis 服务器的各种信息和统计数值(优化)
在java中通过
jedis.info(); //(打印全部)
String str1="Memory"; //内存使用情况
String str2="clients"; //已连接客户端信息
String str3="server"; //Redis 服务器信息
String info = jedis.info(str1);
- 1
- 2
- 3
- 4
- 5
在本地通过客户端连接服务器通过
info (打印全部)
info clients (客户端的信息)
info server (服务端的信息)
info Memory (内存使用情况)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
clients
-
connected_clients:已连接客户端的数量(不包括通过从属服务器连接的客户端)
-
client_longest_output_list:当前连接的客户端当中,最长的输出列表
-
client_biggest_input_buf:当前连接的客户端当中,最大输入缓存
-
blocked_clients:正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
server
- redis_version : Redis 服务器版本
- redis_git_sha1 : Git SHA1
- redis_git_dirty : Git dirty flag
- os : Redis 服务器的宿主操作系统
- arch_bits : 架构(32 或 64 位)
- multiplexing_api : Redis 所使用的事件处理机制
- gcc_version : 编译 Redis 时所使用的 GCC 版本
- process_id : 服务器进程的 PID
- run_id : Redis 服务器的随机标识符(用于 Sentinel 和集群)
- tcp_port : TCP/IP 监听端口
- uptime_in_seconds : 自 Redis 服务器启动以来,经过的秒数
- uptime_in_days : 自 Redis 服务器启动以来,经过的天数
- lru_clock : 以分钟为单位进行自增的时钟,用于 LRU 管理
Memory(重点)
used_memory:由 Redis 分配器分配的内存总量,包含了redis进程内部的开销和数据占用的内存,以字节(byte)为单位
-
used_memory_human:已更直观的单位展示分配的内存总量。
-
used_memory_rss:向操作系统申请的内存大小。与 top 、 ps等命令的输出一致。
-
used_memory_rss_human:已更直观的单位展示向操作系统申请的内存大小。
-
used_memory_peak:redis的内存消耗峰值(以字节为单位)
-
used_memory_peak_human:以更直观的格式返回redis的内存消耗峰值
-
used_memory_peak_perc:使用内存达到峰值内存的百分比,
即(used_memory/ used_memory_peak) *100%
-
used_memory_overhead:Redis为了维护数据集的内部机制所需的内存开销,包括所有客户端输出缓冲区、查询缓冲区、AOF重写缓冲区和主从复制的backlog。
-
used_memory_startup:Redis服务器启动时消耗的内存
-
used_memory_dataset:数据占用的内存大小,即used_memory-sed_memory_overhead
-
used_memory_dataset_perc:数据占用的内存大小的百分比,
100%*(used_memory_dataset/(used_memory-used_memory_startup))
-
total_system_memory:整个系统内存
-
total_system_memory_human:以更直观的格式显示整个系统内存
-
used_memory_lua:Lua脚本存储占用的内存
-
used_memory_lua_human:以更直观的格式显示Lua脚本存储占用的内存
-
maxmemory:Redis实例的最大内存配置
-
maxmemory_human:以更直观的格式显示Redis实例的最大内存配置
-
maxmemory_policy:当达到maxmemory时的淘汰策略
-
mem_fragmentation_ratio:碎片率,used_memory_rss/ used_memory
-
mem_allocator:内存分配器
-
active_defrag_running:表示没有活动的defrag任务正在运行,
1表示有活动的defrag任务正在运行(defrag:表示内存碎片整理)
-
lazyfree_pending_objects:0表示不存在延迟释放的挂起对象
以上Memory参数主要看
used_memory_rss_human(当前使用了多少内存) < maxmemory_human (最大Redis内存)
其他的都不最重要
如果 项目上线了一段时间 used_memory_rss_human 离maxmemory_human 比例差距很大的话
那么将 maxmemory调小 比 used_memory_rss_human多三分之一就行
总结:
-
在优化方面 主要提升速度 还是需要你 专注设计 Redis 存储和查询
减少全部查询 减少删除大集合
-
Redis 存储 尽量都是 json格式的字符串 如果是对象那么使用 Json转换工具进行转换 这样方便以后的获取以及使用
-
在redis中没有修改 想要修改 就直接覆盖就行了
-
在Redis 提供了部分的删除 但是实际上只能满足部分需求 很多时候 删除其实也是覆盖
-
尽量能使用字符串结构就别使用集合结构 因为字符串配合json 无敌 处理的好的话比集合要快
注意的就是 每个key的数据量不要太大 如果数据量大的时候将数据进行分段 也就是将值拆分多个
存储到多个key里
-
避免操作大集合的命令:如果命令处理频率过低导致延迟时间增加,这可能是因为使用了高时间复杂度的命令操作导致 比如: 交集 并集…,这意味着每个命令从集合中获取数据的时间增大。 所以减少使用高时间复杂的命令,能显著的提高的Redis的性能
还有就是 map list set … 这些数据结构 尽量进行分段 就是不要把数据都存在 一个里
比如: 将1000条数据 分别存入 10个map里
每个集合数据量不要大于1000条
-
在java中是提供批量操作的管道命令 (用法和使用Jedis一样 通过pipe.xxx )
Jedis jedis= JedisPool.Jedis(); Pipeline pipe = jedis.pipelined(); //管道 批量处理- 1
- 2
管道命令把几个命令合并一起执行,从而减少因网络开销引起的延迟问题。因为10个命令单独发送到服务端会引起10次网络延迟开销,使用管道会一次性把执行结果返回,仅需要一次网络延迟开销。Redis本身支持管道命令,大多数客户端也支持,倘若当前实例延迟很明显,那么使用管道去降低延迟是非常有效的。
鉴于Pipepining发送命令的特性,Redis服务器是以队列来存储准备执行的命令,而队列是存放在有限的内存中的,所以不宜一次性发送过多的命令。如果需要大量的命令,可分批进行,效率不会相差太远滴,总好过内存溢出嘛~~
出现的错误
READONLY You can’t write against a read only slave.
因为连接的是从节点,从节点只有读的权限,没有写的权限
解决办法:
修改配置文件的slave-read-only为no,
config set slave-read-only no
- 1
java.io.IOException: 远程主机强迫关闭了一个现有的连接。
修改reids 配置文件 tcp-keepalive 60 就行了 (检测之前的连接-如果还存在那么就强制关闭)
在优化方面 主要提升速度 还是需要你 专注设计 Redis 存储和查询
减少全部查询 减少删除大集合
-
Redis 存储 尽量都是 json格式的字符串 如果是对象那么使用 Json转换工具进行转换 这样方便以后的获取以及使用
-
在redis中没有修改 想要修改 就直接覆盖就行了
-
在Redis 提供了部分的删除 但是实际上只能满足部分需求 很多时候 删除其实也是覆盖
-
尽量能使用字符串结构就别使用集合结构 因为字符串配合json 无敌 处理的好的话比集合要快
注意的就是 每个key的数据量不要太大 如果数据量大的时候将数据进行分段 也就是将值拆分多个
存储到多个key里
-
避免操作大集合的命令:如果命令处理频率过低导致延迟时间增加,这可能是因为使用了高时间复杂度的命令操作导致 比如: 交集 并集…,这意味着每个命令从集合中获取数据的时间增大。 所以减少使用高时间复杂的命令,能显著的提高的Redis的性能
还有就是 map list set … 这些数据结构 尽量进行分段 就是不要把数据都存在 一个里
比如: 将1000条数据 分别存入 10个map里
每个集合数据量不要大于1000条
-
在java中是提供批量操作的管道命令 (用法和使用Jedis一样 通过pipe.xxx )
Jedis jedis= JedisPool.Jedis(); Pipeline pipe = jedis.pipelined(); //管道 批量处理- 1
- 2
管道命令把几个命令合并一起执行,从而减少因网络开销引起的延迟问题。因为10个命令单独发送到服务端会引起10次网络延迟开销,使用管道会一次性把执行结果返回,仅需要一次网络延迟开销。Redis本身支持管道命令,大多数客户端也支持,倘若当前实例延迟很明显,那么使用管道去降低延迟是非常有效的。
鉴于Pipepining发送命令的特性,Redis服务器是以队列来存储准备执行的命令,而队列是存放在有限的内存中的,所以不宜一次性发送过多的命令。如果需要大量的命令,可分批进行,效率不会相差太远滴,总好过内存溢出嘛~~


