
- 15年时间,从外包测试到自研,最后到阿里,这5年的经历只有自己能知道...._测试培训完去自研
- 2SpringBoot日志关系--及排除模块中的日志框架_jasypt-spring-boot-starter 排除日志模块
- 3使用Python实现深度学习模型:模型监控与性能优化
- 44年外包上岸,我只能说这类公司能不去就不去
- 5GrassRouter多链路聚合路由应用场景拓扑详解_多链路聚合路由器
- 6机器学习算法: 岭回归算法_岭回归c++算法实例
- 7H5--公众号页面如何唤起小程序_jweixin-1.6.0.js
- 8C++入门基础篇(下)
- 92024年前端最新最新的Vue面试题大全含源码级回答,吊打面试官系列,前端初级面试题_2024前端vue面试题
- 10Linux —— 进程间通信
腾讯论文入选 AI 国际顶会,详细解读 NLP 研究成果
赞
踩


近日,自然语言处理(NLP)领域顶级会议ACL-IJCNLP 2021公布了论文接收情况。腾讯有50余篇论文被接收,又一次刷新了论文录取数量纪录,领跑国内业界AI研究第一梯队。
本文将对腾讯 AI Lab 主导的两篇论文进行详细解读。
ACL2021杰出论文:
基于单语翻译记忆的神经网络机器翻译技术


论文地址:https://arxiv.org/pdf/2105.11269.pdf
从2017年开始,包括微软、Facebook、腾讯在内的多支研究团队均致力于尝试利用检索式对话系统的结果引导生成式模型,以生成更加相关且更为丰富的对话回复。无独有偶,在机器翻译领域,来自CMU、NYU、腾讯的多个团队也一直在推进利用翻译记忆 (Translation Memory) 提升翻译效果的研究工作。无论是对话还是翻译领域,之前他们的工作均集中在利用输入端相似度的检索方式从平行语料中检索数据,并以某种方式输入到深度生成网络来提升生成/翻译效果( 如下图所示)。
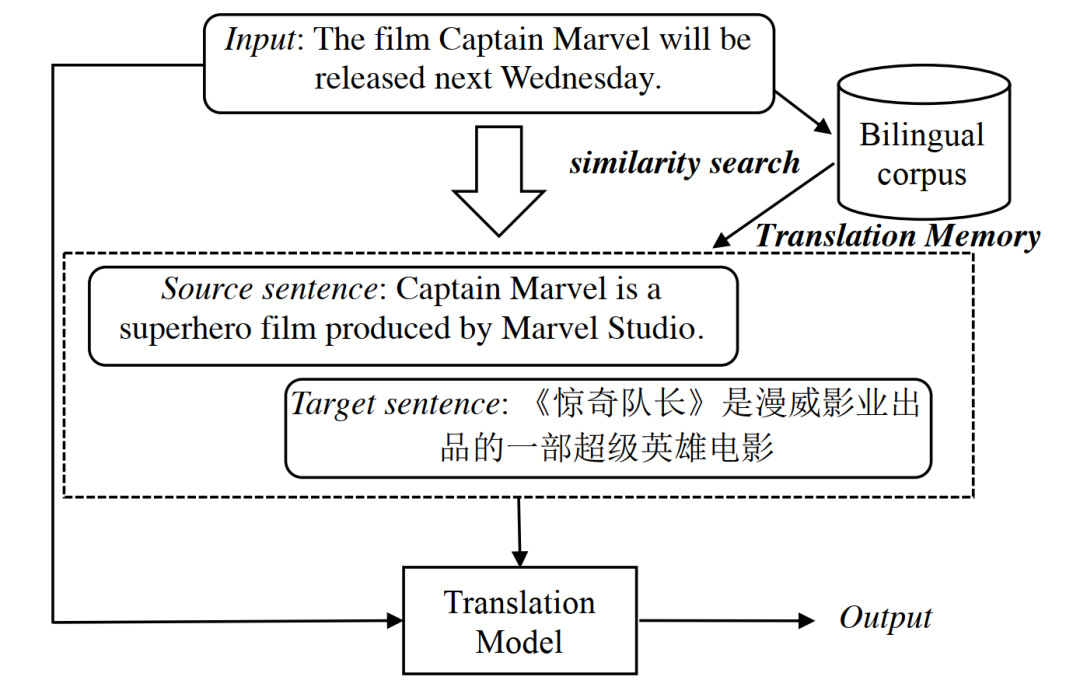
不同于上述工作,在本论文中,作者提出了一种全新的基于单语翻译记忆的翻译框架——训练过程中利用一个双塔结构(dual-encoder framework)的检索模型将源端句子和目标端句子在向量空间对齐,而推理过程中与源端句子在向量空间中距离最近的k条目标端句子,则会被选中作为翻译记忆。需要注意的是,该模型的检索范围并不限定在训练集的句子中,而可以来自任意的单语语料。随后,为了将检索模型与下游翻译模型统一为一个可以端到端训练的整体,检索模型输出的相似度分值将引导翻译模型的注意力(attention)集中到更为有用的检索结果上。基于这样的方式,检索模型可以通过如下逻辑被优化:对最终翻译过程有帮助(能提升参考译文似然度)的检索结果应该被奖励,而那些无用的检索结果则应被惩罚。
实验结果表明,本论文提出的模型即使不使用额外单语数据,翻译效果都要超出目前最好的,而在低资源场景下,一旦模型获得了更多额外的单语语料,模型的翻译效果会大幅度提升。最后,该模型只需对翻译记忆进行热切换就可以实现领域自适应,而不需要对模型进行任何微调。
一、模型设计

本论文提出的方法将整个翻译过程分为检索和生成两步。如图一所示,该方法中翻译记忆库是一堆目标语言句子的集合
 。在翻译过程中,对于输入
。在翻译过程中,对于输入
 ,检索模型(Retrieval Model)根据相关度函数
,检索模型(Retrieval Model)根据相关度函数![]()
 从翻译记忆库中找到
从翻译记忆库中找到 个可能对翻译有帮助的句子
个可能对翻译有帮助的句子![]()
 ,其中
,其中![]()
 。然后翻译模型根据条件概率
。然后翻译模型根据条件概率![]()
 生成翻译结果。在训练过程中,最大化参考译文的似然度能够同时优化检索模型和翻译模型的参数。(本部分省略了部分细节,有关模型的更多详情与数学描述请参阅原论文)
生成翻译结果。在训练过程中,最大化参考译文的似然度能够同时优化检索模型和翻译模型的参数。(本部分省略了部分细节,有关模型的更多详情与数学描述请参阅原论文)
检索模型
本论文采取了双塔框架模型进行检索,该框架的优点在于能将搜索问题转化为最大内积搜索(Maximum Inner Product Search)。源端句子和目标端句子的相似度可以通过对应的向量表示的点积得到:

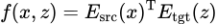
其中
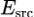 和
和
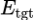 分别是源端句子编码器和目标端句子编码器,用两个独立的Transformer实现。在推理时,翻译记忆库中所有句子的向量表示可以用目标端句子编码器提前计算得到,并用FAISS搭建索引。
分别是源端句子编码器和目标端句子编码器,用两个独立的Transformer实现。在推理时,翻译记忆库中所有句子的向量表示可以用目标端句子编码器提前计算得到,并用FAISS搭建索引。
翻译模型
在翻译过程中,本论文为标准翻译框架(包括一个源端编码器和一个解码器)添加了一个额外的记忆编码器来输入翻译记忆。为了使检索模型和翻译模型能够一同被最终的翻译目标所优化,我们将检索模型得到的相关性分数加入到注意力中的计算中
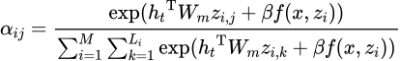 (2)
(2)
其中 是第
是第 条翻译记忆中第
条翻译记忆中第 个片段的的注意力分数, 而
个片段的的注意力分数, 而 是上文提到的相关性得分。简单来说,更有益于提升翻译质量的记忆片段应该收到更多的注意力,进而得到更大的相关性得分,直接优化翻译目标就可以优化检索模型。
是上文提到的相关性得分。简单来说,更有益于提升翻译质量的记忆片段应该收到更多的注意力,进而得到更大的相关性得分,直接优化翻译目标就可以优化检索模型。
跨语言对齐预训练任务
本论文提出的模型存在冷启动问题,因此作者提出了两种跨语言对齐预训练任务为检索模型热身。作者称这两个预训练任务在实践中缺一不可。
二、实验
本论文共进行了三种不同设置的实验:1)传统设置:所有模型都只能用训练集作为翻译记忆库,2)低资源设置:双语训练对数量较少,但模型可以使用额外的单语数据作为翻译记忆,3)利用单语数据实现翻译模型的非参数领域自适应。请注意已有的方法仅能直接适用于第一种设置,而2) 3)两种设置只能依赖本论文提出的模型才成为可能。
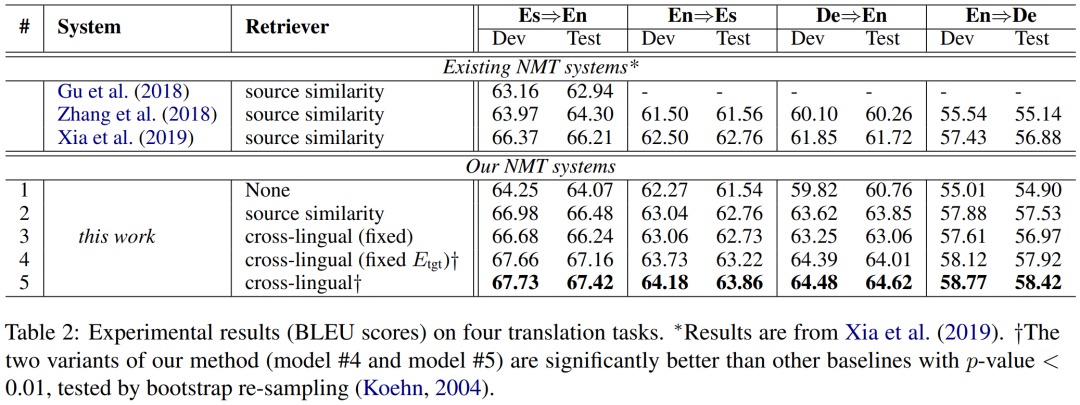
实验一:传统设置
本实验使用了翻译记忆的经典数据集JRC-Acquis,并挑选了西英,英西,德英,英德四个翻译方向进行实验。实验中,作者复现了三种经典的基线模型的实验结果,并实现了一系列模型的变种来验证模型不同模块对翻译性能的影响。上表中的Model 1-5分别表示:
1. 没有使用翻译记忆的基本翻译模型 Transformer base。
2. 使用双语翻译记忆的基本翻译模型。
3. 本论文提出的模型,但不进行端到端优化,训练时仅更新翻译模型不更新检索模型。
4 & 5:本论文提出的模型,区别在于异步更新策略 (因字数限制,该部分介绍被省略,详情请参阅原论文)
从实验结果可以看出,在所有任务上,本论文提出的完整模型均取得了最好效果,相对于不使用翻译记忆的基线模型(Model #1)平均提升了3.26 BLEU值。其中端到端训练是关键所在,Model #4 & 5,相对于没有进行端到端训练的Model 3都有超过1 BLEU值的性能提升。最令人惊奇的是,仅仅只使用单语翻译记忆的Model #4 和 #Model 5在性能上居然超过了使用双语翻译记忆的Model 2以及三种复现的基线模型。这可以归因于是端到端训练使跨语言检索模型能更好的适应下游的翻译任务。
实验二:低资源设置
如前文所说,本论文提出的模型最大优势在于能够将单语数据作为翻译记忆。为了证明单语翻译记忆的有效性,作者进行了低资源场景实验,实验中模型只能获得部分双语数据以及额外的单语数据作为翻译记忆。

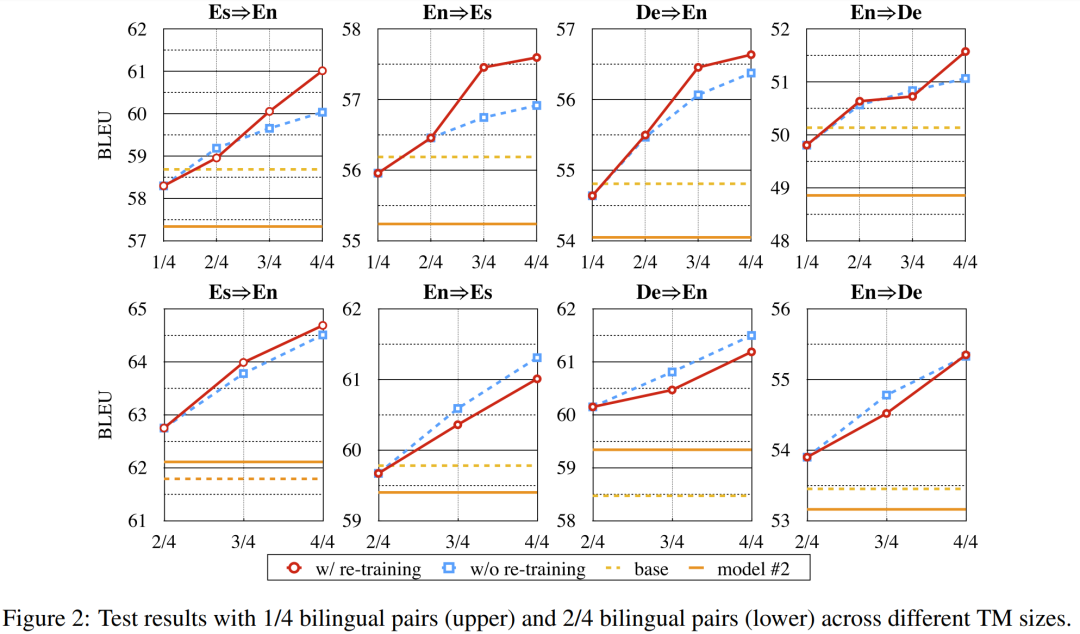
本场景下仍然有两种不同的训练选择:1)切换翻译记忆时不重新训练翻译模型;以及 2)切换翻译记忆时重新训练翻译模型。在上图中,蓝色虚线代表选择1,而红色实线代表选择2。可以看到,翻译质量随着翻译记忆库规模的增大而显著提升。另一个有趣的现象是,即使使用选择1) 的方式训练,模型的性能也不会受到很大影响。
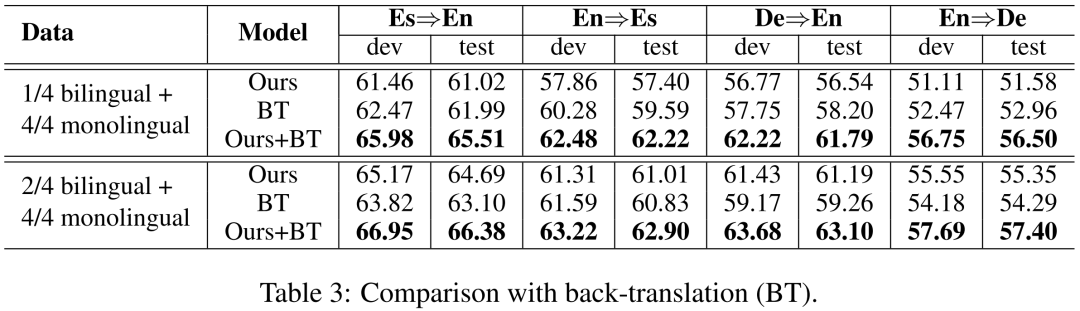
与Back-translation方法的对比:本论文也与back-translation (BT) 方法进行了对比。如上表所示,本论文提出的方法与BT方法各有所长,但令人惊喜的是,结果表明两种方法是互补的,他们的结合使翻译性能取得了进一步的巨大提升。
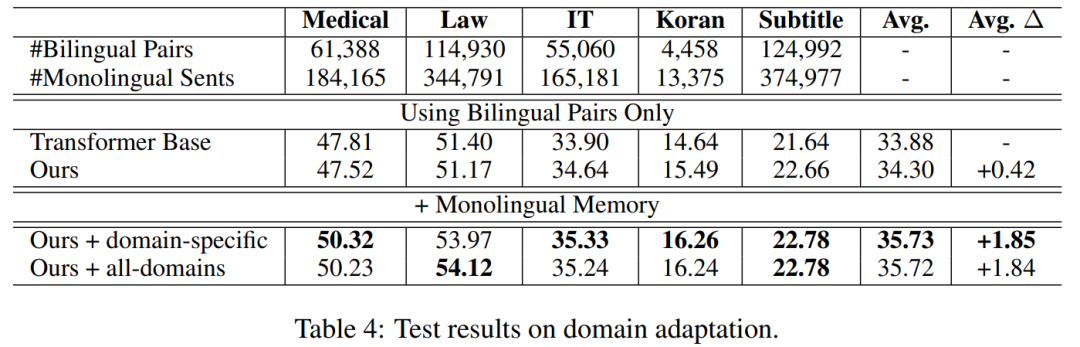
实验三:非参数领域自适应
本论文提出的模型的另一个独特优点是可以通过切换翻译记忆,不改变或增加参数即可以适用于特定领域。在最后一个实验中,作者通过切换翻译记忆,实现了翻译领域的自适应。上表中的实验结果表明,只使用双语翻译记忆时,基于翻译记忆的模型和不使用翻译记忆的模型效果各有千秋,但一旦增加了额外的单语翻译记忆,本论文提出的模型在五个领域上的平均BLEU值提升了1.87。
三、总结
本论文首次提出了利用单语翻译记忆提升翻译模型,并发现跨语言的检索模型可以通过端到端的方式进行优化。本论文提出的方法在低资源场景下取得了巨大的性能提升,并且可以实现一个模型适用于所有领域。
作者指出了两个未来可能的提升方向:1)为了保证公平,本研究中所用到的编码器均从随机参数开始训练,使用预训练语言模型将进一步提升翻译性能;2)增大翻译记忆的多样性有可能显著提升翻译性能,但本论文中的模型结构并未考虑这一点。
NAACL最佳论文:
视频辅助无监督语法归纳


论文地址:https://arxiv.org/abs/2104.04369v2
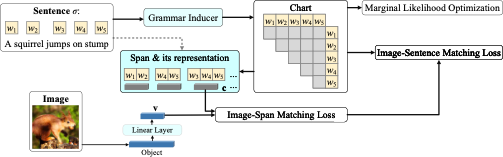
长久以来,句法分析一直都是NLP研究的热点话题之一。很多现有的方法都是在有语法标注的数据集上学习。但是这种有监督的学习存在两个弱点:1. 标注这样的数据集需要大量的语言专家,费时费力。2. 只有几个常见语种有标注好的数据集,许多小语种甚至没有足够的语言专家来标数据。因此,近些年来有越来越多的研究试图从海量未标注的文本中来进行无监督的句法学习。以C-PCFG[1]为例(见下图),给定一个句子,句法抽取器(Grammar Inducer)预测出一个句法图(Chart),并对句子的边缘似然函数进行优化。

除了以上的商业价值以外,无监督句法分析还有着重要的科学价值,长期以来认知科学(cognitive science)界一直争论着人类能习得语言的原因:是人脑中天生就存在某种机制,还是单纯靠统计学习(statistical learning)的方式,而无监督句法分析正是用来验证统计学习理论的重要手段之一。
过去的无监督句法分析的方法都是以纯文本为输入,而视觉中含有很多文本所不具备的知识,因此最近有一些方法[2,3]试图通过图片信息来辅助无监督句法分析。以VC-PCFG [3] 为例(见下图),它在C-PCFG的基础上额外增加了一个图片和句子之间的损失函数,通过图片特征对文本特征进行正则化,可进一步提高句法抽取器的性能。
但是这种方法的提升是有局限的。从VC-PCFG论文的实验部分可以看到,相较于C-PCFG,VC-PCFG主要提升的是NP的性能,而在其他常见的短语类型上的提升并不明显,如VP,PP,SBAR, ADJP和ADVP。这一现象也存在在另一篇文章VG-NSL [2] 中。一个可能的解释是这两篇文章用到的图片特征提取器是在物体分类上训练的,这种特征对于物体有比较准确的描述从而提升了NP。但对于涉及到物体的动作和变化的短语类型,如VP,因为图片是静态的,这种物体分类的特征并不不能提供这样的变化信息。但如果我们将静态图片换成动态视频,很有可能对涉及到动词的短语类型也会有所提升。
本文提出了Multi-Modal Compound PCFGs (MMC-PCFG)用于视频辅助的无监督句法分析 ,框架如下。与VC-PCFG [3]不同的是,本模型以视频作为输入,并融合了视频多种模态的信息,是VC-PCFG [3] 在视频上的泛化。
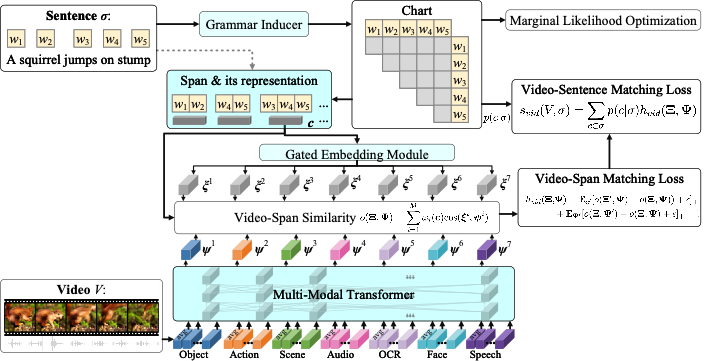
一、模型设计
对于每个视频我们首先在时间上等间隔抽取包括物体,动作,场景,声音,字符,人脸,语音在内的共M种特征。本文借鉴多模态transformer[4]来计算视频和文本片段之间的相似度。具体来说,我们首先把输入特征的连接在一起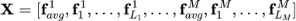
 , 这里
, 这里
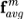 是
是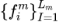
 的平均。此外我们还使用特征类型编码
的平均。此外我们还使用特征类型编码
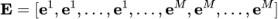 和位置编码
和位置编码
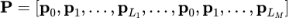 来区分不同视频特征的种类和时间顺序。然后将这三者的加和作为transformer的输入,并使用与各平均特征对应位置的输出作为视频特征的输出,记作
来区分不同视频特征的种类和时间顺序。然后将这三者的加和作为transformer的输入,并使用与各平均特征对应位置的输出作为视频特征的输出,记作
 。
。
接下来我们计算视频 和某个句子
和某个句子 中某个片段
中某个片段 之间的相似度。这里用
之间的相似度。这里用 表示该片段的特征。我们利用gated embedding module将
表示该片段的特征。我们利用gated embedding module将
 映射到
映射到
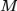 个不同的编码,记作
个不同的编码,记作
 。然后视频和文中片段的相似度可以通过加权求和这
。然后视频和文中片段的相似度可以通过加权求和这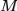
 对视频和文中片段的cosine值得到,即
对视频和文中片段的cosine值得到,即
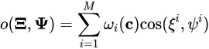 。这里的权重
。这里的权重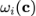
 是将
是将
 输入到一个线性层通过softmax得到。
输入到一个线性层通过softmax得到。
我们用hinge loss来计算视频V和某文本片段c的损失函数,即
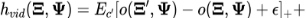

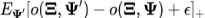 。这里
。这里
 和
和
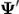 分别表示的是其他句子的某个片段和其他视频的特征。视频
分别表示的是其他句子的某个片段和其他视频的特征。视频
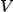 和句子
和句子
 也相应地定义为所有片段的加权求和
也相应地定义为所有片段的加权求和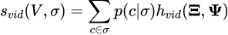
 ,这里的权重
,这里的权重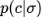
 通过句法图获得。
通过句法图获得。
训练时,我们同时优化句子的边缘概率函数和句子视频的匹配函数。测试时,只需要输入文本,通过CKY算法即可推导出句法树
二、实验
我们在三个数据集(DiDeMo, YouCook2, MSRVTT)上做了实验。因为这些数据集没有语法标注,我们用一个监督学习的方法[5]预测出来的结果当作reference tree。对于物体和动作特征,我们还用不同模型提取了多种不同的特征,包括物体(ResNeXt-101,SENet-154)和动作(I3D,R2P1D,S3DG)。每组实验都跑10个epoch并用不同的种子跑了4次。实验结果见表1。LBranch,RBranch和Random代表left branching tree, right branching tree 和random tree。因为VC-PCFG是为图片设计的,不能直接以视频作为输入。为了对比VC-PCFG,我们设计了一些简单的baseline。第一种baseline是将单个特征在时间轴上取平均,作为VC-PCFG输入 (ResNeXt, SENet …, Speech)。另一个baseline是将这些取平均的特征连接在一起然后作为VC-PCFG的输入 (Concat)。
首先我们比较C-F1和S-F1这两个综合评指标。Right Branching性能很强主要因为英语很大程度上是right branching的。VC-PCFG整体上要比比C-PCFG效果要好,说明利用视频信息是有帮助的。简单的将所有特征连在一起并不能让效果变的更好,有时甚至还不如单个特征(比如Concat 和 R2P1D)。其主要原因是没有考虑特征直接的关系。而我们提出的MMC-PCFG在所有三个数据集中性能都达到了最好的结果,说明我们的模型可以有效利用所有特征的信息。
接下来我们比较这些方法在NP,VP 和PP三种常见短语类型的召回率。对比在单个特征训练的VC-PCFG,使用物体特征(ResNeXt-101,SENet-154)在NP上的效果更好,而使用动作特征(I3D,R2P1D,S3DG)在VP和PP上效果更好。这验证了不同特征对不同的句法结构贡献不同。和VC-PCFG相比,MMC-PCFG在NP,VP和PP的召回率都是前两名且标准差较小,再次说明MMC-PCFG可以有效利用所有特征的信息,并给出较为一致的预测。

三、总结
受限于静态图片的表达能力,现有基于图片的无监督句法分析方法对于动词相关的短语提升有限。本文所提出的利用视频来辅助无监督句法分析可有效的解决这个问题。同时本文还提出了Multi-Modal Compound PCFG用来集成多种不同的特征。该模型的有效性在三个数据集上得到了验证。
从认知科学的角度看,考虑视觉信息、尤其是视频信息,更加接近人类所处的多模态环境,因此本文的结论推进了语言习得中统计学习理论的可能性,而如果这一理论最终得以验证,那么最终打造一个能实时捕捉多模态信息的机器人去习得人类语言将更有可能。
引用:
[1] Kim et al. Compound Probabilistic Context-Free Grammars for Grammar Induction. ACL 2019
[2] Shi et al. Visually Grounded Neural Syntax Acquisition. ACL 2019
[3] Zhao et al. Visually Grounded Compound PCFGs. EMNLP 2020
[4] Gabeur et al. Multi-modal Transformer for Video Retrieval. ECCV 2020
[5] Kitaev et al. Constituency Parsing with a Self-Attentive Encoder. ACL 2018


往
期
回
顾
技术
技术
新闻
转载

分享

点收藏

点点赞

点在看

