
- 1Android——最强大的RecyclerView框架
- 2Flink集成kafka消费数据和推送消息_flink 推送
- 3lstm 文本纠错_PyCorrector文本纠错工具实践和代码详解
- 4【面试题】手写Promise_面试题手写一个promise代码
- 5J204B接口简介
- 6数据结构:顺序表的实现
- 7KVM IO虚拟化_virtualio和virtual bus
- 8用Python的flask、tornado和fastapi探索SSE推送服务_flask sse
- 92024年运维最新dbeaver安装和使用教程_dbeaver使用教程,2024年最新透彻解析
- 10el-select的错误提示不生效、el-select验证失灵、el-select的blur规则失灵_elementplus el-select v-model placeholder 不生效
druiddatasource配置_数据库连接池配置(案例及排查指南)
赞
踩
引言
想必本文的读者对数据库都不会陌生,由于数据库良好的特性和服务的稳定性,使得我们的工作几乎离不开,而数据库连接池因为连接复用的优势也被广泛的使用,但凡事不可能只有好处而没有代价,使用连接池一个最直接的代价就是需要配置一堆的参数。其实很多时候这个复杂度也不存在,只要找个工程把配置拷贝一份,改一下用户名密码也就能工作了,因为之前的配置都正常工作了一段时间基本也没问题了,这个逻辑本身没毛病,但有个前提至少知道配了什么,不然问题来了都不知道如何应对。本文以 druid 1.1.5 (https://github.com/alibaba/druid) 连接池为例来阐述几个参数的重要性及如果避免踩坑,虽然下面提到的都是druid的配置项,但多数连接池(不限于数据库)其实也都有类似的配置,基本用法和场景均可借鉴。
连接池配置
maxWait
参数表示从连接池获取连接的超时等待时间,单位毫秒,需要注意这个参数只管理获取连接的超时。获取连接等待的直接原因是池子里没有可用连接,具体包括:连接池未初始化,连接长久未使用已被释放,连接使用中需要新建连接,或连接池已耗尽需等待连接用完后归还。这里有一个很关键的点是 maxWait 未配置或者配置为 0 时,表示不设等待超时时间(可能与一些人认为 -1 表示无限等待的预期不符合,虽然在 druid 中 maxWait 配置成 -1 的含义也相同)。对实现细节感兴趣的读者可以从 com.alibaba.druid.pool.DruidDataSource#getConnection 方法入手,查看参数的使用逻辑。
推荐配置: 内网(网络状况好) 800;网络状况不是特别好的情况下推荐大于等于 1200,因为tcp 建连重试一般是 1 秒。
如果不配置maxWait,后果会怎么样呢?可能有些应用就这么干的,而且也没发生过异常,不过最终墨菲定律还是会显灵的,下面来看几个真实的案例:
案例一
// 参数配置maxWait=0, maxActive=5, …正常流量下业务没有发现任何问题,但突发大流量涌入时,造成连接池耗尽,所有新增的DB请求处于等待获取连接的状态中。由于 maxWait=0 表示无限等待,在请求速度大于处理速度的情况下等待队列会越排越长,最终业务上的表现就是业务接口大量超时,流量越大造成实际吞吐量反而越低。
案例二
maxWait=0, removeAbandoned=true, removeAbandonedTimeout=180, …现象:业务代码正常运行了很长时间没有出现过消息积压情况,在一次全链路压测后产生大量的压测数据,造成了MQ消息的堆积。即使重启服务,也只能保持几十秒的正常运行,随后又进入消费停滞的状态。使用 jstack 发现是卡在获取数据库连接中,再过3分钟左右后出现错误:abandon connection, owner thread: xxx 。最后业务通过配置 maxWait=3000(3秒超时),业务MQ消息正常消费。
原因分析:业务依赖两个数据源,这里表示为 datasource1 与 datasource2,其中在部分代码段中同时开启了两个库的事务。如图1 所示,线程1 获取了 datasource1 中的最后一个连接 connection[n],等待获取 datasource2 的连接,此时线程2也正在执行类似的操作,造成了死锁等待。大家对这种互锁一定很熟悉,只是这次是发生在DB上。为什么一段时间后程序报 abandon connection 的错误,这是因为配置了 {removeAbandoned:true, removeAbandonedTimeout:180} 这两个参数,这个配置的含义是如果一个连接持有 180 秒还没有归还,就被认为是异常连接(对于OLTP的业务查询通常都是毫秒级的),需要关闭掉这条连接。之所以正常情况下没有发生问题是因为连接池水位比较低,资源充足没有造成相互等待的情况。
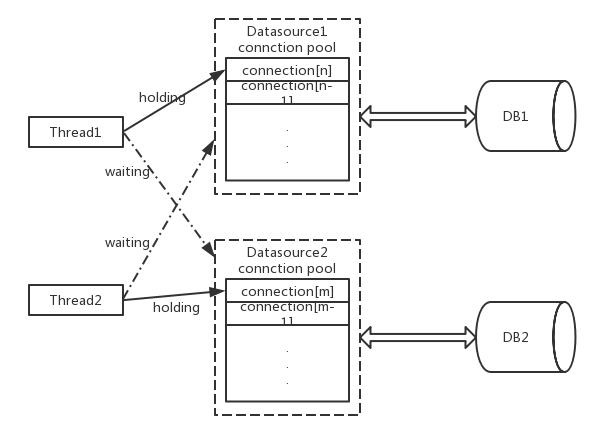
图1. 双DB连接池死锁问题
connectionProperties
参数是以键值对表示的字符串,其中可以配置 connectTimeout 和 socketTimeout,它们的单位都是毫秒,这两个参数在应对网络异常方面非常重要。connectTimeout 配置建立 TCP 连接的超时时间,socketTimeout 配置发送请求后等待响应的超时时间。这两个参数也可以通过在 jdbc url 中添加 connectTimeout=xxx&socketTimeout=xxx 的方式配置,试过在 connectinoProperties 中和 jdbc url两个地方都配置,发现优先使用 connectionProperties 中的配置。如果不设置这两项超时时间,服务会有非常高的风险。现实案例是在网络异常后发现应用无法连接到DB,但是重启后却能正常的访问DB。因为在网络异常下socket 没有办法检测到网络错误,这时连接其实已经变为“死连接”,如果没有设置 socket 网络超时,连接就会一直等待DB返回结果,造成新的请求都无法获取到连接。
推荐配置:socketTimeout=3000;connectTimeout=1200
keepAlive
参数表示是否对空闲连接保活,布尔类型。可能不少人认为 druid 连接池默认会维持DB连接的心跳,对池子中的连接进行保活,特别配置了 minIdle 这个参数后觉得,有了 minIdle 最少应该会保持这么多空闲连接。其实,keepAlive 这个参数是在 druid 1.0.28 后新增的,并且默认值是 false,即不进行连接保活。
那么需要保活连接,是不是将 keepAlive 配置成 true 就完事了呢?虽然 true 的确是开启了保活机制,但是应该保活多少个,心跳检查的规则是什么,这些都需要正确配置,否则还是可能事与愿违。这里需要了解几个相关的参数:minIdle 最小连接池数量,连接保活的数量,空闲连接超时踢除过程会保留的连接数(前提是当前连接数大于等于 minIdle),其实 keepAlive 也仅维护已存在的连接,而不会去新建连接,即使连接数小于 minIdle;minEvictableIdleTimeMillis 单位毫秒,连接保持空闲而不被驱逐的最小时间,保活心跳只对存活时间超过这个值的连接进行;maxEvictableIdleTimeMillis 单位毫秒,连接保持空闲的最长时间,如果连接执行过任何操作后计时器就会被重置(包括心跳保活动作);timeBetweenEvictionRunsMillis 单位毫秒,Destroy 线程检测连接的间隔时间,会在检测过程中触发心跳。保活检查的详细流程可参见源码com.alibaba.druid.pool.DruidDataSource.DestroyTask,其中心跳检查会根据配置使用ping或validationQuery 配置的检查语句。
推荐配置:如果网络状况不佳,程序启动慢或者经常出现突发流量,则推荐配置为true;
案例一
keepAlive=true, minIdle=5, timeBetweenEvictionRunsMillis=10000, minEvictableIdleTimeMillis=100000, maxEvictableIdleTimeMillis=100000, …请问上述配置连接能保活成功吗? 不能,由于 minEvictableIdleTimeMillis == maxEvictableIdleTimeMillis,所以连接在开始检测时就会被断定超过 maxEvictableIdleTimeMillis 需要丢弃。
案例二
keepAlive=true, minIdle=5, timeBetweenEvictionRunsMillis=10000, minEvictableIdleTimeMillis=95000, maxEvictableIdleTimeMillis=100000, …请问上述配置连接能保活成功吗? 具有随机性,由于maxEvictableIdleTimeMillis - minEvictableIdleTimeMillis < timeBetweenEvictionRunsMillis,所以有可能在这个窗口期并没有执行Destroy线程检测任务,无法保证心跳一定会被执行。
maxActive
最大连接池数量,允许的最大同时使用中的连接数。这里特地唠叨一下,配置 maxActive 千万不要好大喜多,虽然配置大了看起来业务流量飙升后还能处理更多的请求,但切换到DB视角会发现其实连接数的增多在很多场景下反而会减低吞吐量,一个非常典型的例子就秒杀,在更新热点数据时DB 需要加锁操作,这个时候再让更多的连接操作DB就有点像假日往高速上涌入的车辆,只会给DB添堵。
推荐配置:20,多数场景下 20 已完全够用,当然这个参数跟使用场景相关性很大,一般配置成正常连接数的3~5倍。
DB“慢查”排查记
上面讲了一些配置的坑,那么是否中规中矩的按照推荐配置就万事大吉了呢,现实中的世界往往没这么简单的事,下面分享一个“慢查”排查的一个案例,了解一下DB慢查的排查思路。
有应用反馈发现大量DB慢查,并且日志上还记录了详细的执行时间和SQL语句。接到问题后我们第一时间排查DB发现并没有异常,也没有慢查记录,并且日志中的大部分SQL都能匹配索引,测试执行都在毫秒级。于是开始排查网络是否正常,有没丢包、重传等现象,查询监控数据发现也很正常,然后进行抓包分析发现实际请求处理的速度非常正常,至此可以排除DB问题。
于是再深入分析,查询DB其实可分为两个阶段:1. 获取连接阶段; 2. 执行查询阶段;绝大部分情况下获取连接代价非常小,直接就能从连接池获取到,即使需要新建连接代价往往也不大,所以使用时非常容易忽略获取连接这个阶段。什么情况下获取连接会出问题呢?一种情况是建立连接慢,一种是连接池已经耗尽,再对照上面的案例进行排查,依次排除了这两种情况。至此问题还是一筹莫展,还好高手在场,想到用 strace 跟踪 SQL 请求前后干了什么,最后发现记录慢查日志开始和结束之间有写日志操作,这里的写日志是同步的并且在特定情况下正好触发了另个问题导致写日志非常慢,并且这个日志操作是封装在底层的,连业务开发都不清楚有这么个操作。至此真相水落石出,最终修复了写日志慢的问题后就不再出现类似的“慢查”了。
结语
有时一个“慢查”问题有时候可能并非像结果展示的那样确切,看似最可能出在DB上的问题,却是另外几个风马牛不相及的原因凑到一起造成的,所以有时还得留个心眼,全局地看问题,看似无路可走时去追查抽象的背后实现。经验加演练能有效地预防故障,限于篇幅本文只挑选几个最容易引发问题及容易误解的参数做一些经验性地介绍,上述很多案例都可以使用 iptables, tc 等工具来模拟断网和丢包来复现,希望有赞的经验能帮助到读者避免一些常见问题。

