
- 1word-embedding_def forward(self,inp): out = self.fc(inp) return o
- 2如何申请与使用携程API接口_携程api开放平台
- 3手写RPC-令牌桶限流算法实现,以及常见限流算法
- 4单例模式以及线程安全问题_单例模式线程不安全
- 5基于java和百度AI人脸动漫头像生成系统设计与实现_人物头像卡通系统设计与实现
- 6【数据库】 mysql数据库管理工具 Navicat平替工具 免费开源数据库管理工具_navacat平替
- 7营销广告电商行业如何实现降本提效?看这篇就够了!_降低电商营销成本
- 8我开源的H5商城2.0版本发布,强烈推荐_开源的h5移动端商场项目
- 9Langflow系列教程之 09 快速搭建AI 文档质量检查,从本地内存加载的文档构建问答聊天机器人(教程含源码)_langflow 本地运行源码
- 10基于java swing和mysql实现的学生选课成绩信息管理系统(源码+数据库+ER图文档+运行指导视频)_javaswing+数据库学生管理系统
在 Amazon Bedrock 中微调 Claude 3 Haiku 模型,以提高其准确性和质量
赞
踩

在 Amazon Bedrock 平台上,像 Anthropic Claude 这样的前沿大型语言模型 (LLM) 经过海量数据训练,具备了理解和生成类人文本的能力。通过在专有数据集上进行微调,Anthropic Claude 3 Haiku 能够针对特定领域或任务提供卓越的性能,这种微调过程代表了一种深度定制,使用您独特的数据来优化模型表现,是其区别于其他模型的关键优势。
Amazon Bedrock 是一项全面托管的服务,它提供了多种高性能基础模型 (FM) 的选择,并整合了构建生成式 AI 应用程序所需的广泛功能。这一服务简化了开发流程,同时确保了安全性、隐私保护和负责任的生成式 AI 实践。利用 Amazon Bedrock 自定义模型,您可以安全地使用自己的数据来定制 FM,实现个性化的模型优化。Anthropic 公司声称,Claude 3 Haiku 在智能模型领域中,以其快速和成本效益高的特点,成为市场上的佼佼者。目前,您可以在亚马逊云科技美国西部(俄勒冈州)区域使用 Amazon Bedrock 对 Anthropic Claude 3 Haiku 进行微调,这是目前唯一提供此类全托管微调服务的平台。
本文将详细介绍在 Amazon Bedrock 中微调 Anthropic Claude 3 Haiku 的流程。首先,我们将概述微调的基本概念,然后深入探讨微调模型的关键步骤,包括权限设置、数据准备、启动微调任务以及对微调后的模型进行评估和部署。
解决方案概览
微调是自然语言处理(NLP)领域的一项技术,它允许将预训练的语言模型进行定制,以适应特定的任务需求。在微调的过程中,预训练的 Anthropic Claude 3 Haiku 模型会根据特定任务调整其权重,从而提升在该任务上的表现。这一过程涉及到超参数的调整,如学习率和批大小,以确保微调达到最佳效果。
在 Amazon Bedrock 上进行 Anthropic Claude 3 Haiku 的微调,为企业带来了显著的优势。微调不仅能够提升模型在特定任务上的性能,还能让模型处理更为定制化的使用案例,甚至达到或超过更强大模型(如 Anthropic Claude 3 Sonnet 或 Anthropic Claude 3 Opus)的任务特定性能指标。这使得企业能够在降低成本和响应时间的同时,获得更优的性能表现。本质上,微调 Anthropic Claude 3 Haiku 为您提供了一种灵活的工具来定制 Anthropic Claude,使您能够高效地定制模型,从而满足特定的性能和响应时间要求。
使用您自己的数据,您可以在多种不同的应用场景中,充分利用微调 Anthropic Claude 3 Haiku 模型的优势。以下是一些特别适合微调 Anthropic Claude 3 Haiku 模型的用例:
分类 - 例如,当您拥有 10,000 个标记样例,并希望 Anthropic Claude 在此任务上表现出色。
结构化输出 - 例如,当您需要 Anthropic Claude 的响应始终符合给定结构。
行业知识 - 例如,当您需要教会 Anthropic Claude 如何回答有关您公司或行业的问题。
工具和 API - 例如,当您需要教会 Anthropic Claude 如何真正擅长使用您的 API。
在接下来的部分中,我们将通过使用 Amazon Bedrock 控制台和 Amazon Bedrock API,介绍在 Amazon Bedrock 中微调和部署 Anthropic Claude 3 Haiku 的步骤。

Amazon Bedrock API
扫码了解更多
必备条件
要使用此功能,请确保满足以下要求:
一个可正常使用的亚马逊云科技账户。
在 Amazon Bedrock 中启用了 Anthropic Claude 3 Haiku。您可以在 Amazon Bedrock 控制台的模型访问页面上确认它是否启用。
访问 Amazon Bedrock 中 Anthropic Claude 3 Haiku 微调的预览版。要申请访问权限,请联系您的亚马逊云科技账户团队或通过 Amazon Management Console 提交支持工单。创建支持工单时,选择服务为 Bedrock,类别为 Models。
所需的训练数据集(以及可选的验证数据集)已经准备好并且存储在 Amazon Simple Storage Service (Amazon S3)中。
在使用 Amazon Bedrock 创建模型定制作业时,您需要设置一个具有特定权限的 Amazon Identity and Access Management (IAM) 角色(更多详细信息,请扫码参阅创建模型定制服务角色):
信任关系,允许 Amazon Bedrock 服务承担并使用该角色。
访问 Amazon S3 中训练和验证数据的权限。
将输出数据写入 Amazon S3 的权限。
如果您使用 Amazon Key Management Service (Amazon KMS) 密钥加密了资源,则可选择授予解密权限。

Amazon Management Console
扫码了解更多

创建模型定制服务角色
扫码了解更多
左右滑动查看更多
以下代码是信任关系,允许 Amazon Bedrock 承担 IAM 角色:
- {
- "Version": "2012-10-17",
- "Statement": [
- {
- "Effect": "Allow",
- "Principal": {
- "Service": "bedrock.amazonaws.com"
- },
- "Action": "sts:AssumeRole",
- "Condition": {
- "StringEquals": {
- "aws:SourceAccount": "account-id"
- },
- "ArnEquals": {
- "aws:SourceArn": "arn:aws:bedrock:us-west-2:account-id:model-customization-job/*"
- }
- }
- }
- ]
- }

左右滑动查看完整示意
准备数据
要微调 Anthropic Claude 3 Haiku 模型,训练数据必须采用 JSON Lines (JSONL) 格式,其中每一行表示一个单独的训练记录。具体来说,训练数据格式与 MessageAPI 保持一致:
- {"system": string, "messages": [{"role": "user", "content": string}, {"role": "assistant", "content": string}]}
- {"system": string, "messages": [{"role": "user", "content": string}, {"role": "assistant", "content": string}]}
- {"system": string, "messages": [{"role": "user", "content": string}, {"role": "assistant", "content": string}]}
左右滑动查看完整示意
下面是一个用于在 Amazon Bedrock 中微调 Anthropic Claude 3 Haiku 的文本摘要使用案例的示例输入,采用 JSONL 格式,每条记录占一行文本:
- {
- "system": "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.",
- "messages": [
- {"role": "user", "content": "instruction:\n\nSummarize the news article provided below.\n\ninput:\nSupermarket customers in France can add airline tickets to their shopping lists thanks to a unique promotion by a budget airline. ... Based at the airport, new airline launched in 2007 and is a low-cost subsidiary of the airline."},
- {"role": "assistant", "content": "New airline has included voucher codes with the branded products ... to pay a booking fee and checked baggage fees ."}
- ]
- }
左右滑动查看完整示意
在调用经过微调的模型时,可以使用相同的 MessageAPI 格式,这种一致性设计非常便捷。在每一行中,“system” 消息是可选的信息,它提供了上下文和指令,例如指定特定的目标或角色,通常被称为系统提示。“user” 内容对应于用户的指令,而“assistant”内容是经过微调的模型应该提供的期望响应。在 Amazon Bedrock 中微调 Anthropic Claude 3 Haiku 支持单回合和多回合对话。如果您想使用多回合对话,每行的数据格式如下:
{"system": string, "messages": [{"role": "user", "content": string}, {"role": "assistant", "content": string}, {"role": "user", "content": string}, {"role": "assistant", "content": string}]}左右滑动查看完整示意
最后一行 “assistant” 角色代表了经过微调的模型的期望输出,而之前的历史对话为输入提示。对于单回合和多回合对话数据,每条记录的总长度(包括 system、user 和 assistant 的内容)不要超过 32,000 个 token。
除了训练数据外,您还可以准备验证和测试数据集。虽然这一步是可选的,但建议使用验证数据集,因为它允许您在训练期间监控模型的性能。这个数据集支持诸如提前停止等功能,有助于提高模型性能和收敛性。另外,测试数据集用于在训练完成后评估最终模型的性能。这两个额外的数据集格式与您的训练数据集类似,但在微调过程中具有不同的用途。
如果您已经在使用 Amazon Bedrock 来微调 Amazon Titan、 Meta Llama 或 Cohere 模型,那么训练数据应该遵循以下格式:
- {"prompt": "<prompt1>", "completion": "<expected generated text>"}
- {"prompt": "<prompt2>", "completion": "<expected generated text>"}
- {"prompt": "<prompt3>", "completion": "<expected generated text>"}
左右滑动查看完整示意
对于这种格式的数据,您可以使用以下 Python 代码将其转换为微调所需的格式:
- import json
-
-
- # Define the system string, leave it empty if not needed
- system_string = ""
-
-
- # Input file path
- input_file = "Orig-FT-Data.jsonl"
-
-
- # Output file path
- output_file = "Haiku-FT-Data.jsonl"
-
-
- with open(input_file, "r") as f_in, open(output_file, "w") as f_out:
- for line in f_in:
- data = json.loads(line)
- prompt = data["prompt"]
- completion = data["completion"]
-
-
- new_data = {}
- if system_string:
- new_data["system"] = system_string
- new_data["messages"] = [
- {"role": "user", "content": prompt},
- {"role": "assistant", "content": completion}
- ]
-
-
- f_out.write(json.dumps(new_data) + "\n")
-
-
- print("Conversion completed!")
左右滑动查看完整示意
为了优化微调性能,训练数据的质量比数据集的大小更重要。我们建议从一个小但高质量的训练数据集开始( 50-100 行数据是一个合理的起点),对模型进行微调并评估其性能。根据评估结果,您可以迭代和优化训练数据。通常,随着高质量训练数据的增加,您可以期望从微调后的模型中获得更好的性能。然而,时刻保持数据质量是至关重要的,因为一个庞大但质量较低的数据集可能无法带来期望的微调模型性能提升。
目前,用于微调 Anthropic Claude 3 Haiku 的训练数据和验证数据记录数量要求与 Amazon Bedrock 微调其他模型的限制一致。具体来说,训练数据不应超过 10,000 条记录,验证数据不应超过 1,000 条记录。这些限制可以提供高效的资源利用,同时允许在合理的数据规模内进行模型优化和评估。
微调模型
在 Amazon Bedrock 中微调 Anthropic Claude 3 Haiku,允许您配置各种超参数,这些超参数可以显著影响微调过程和所产生模型的性能。下表总结了支持的超参数。
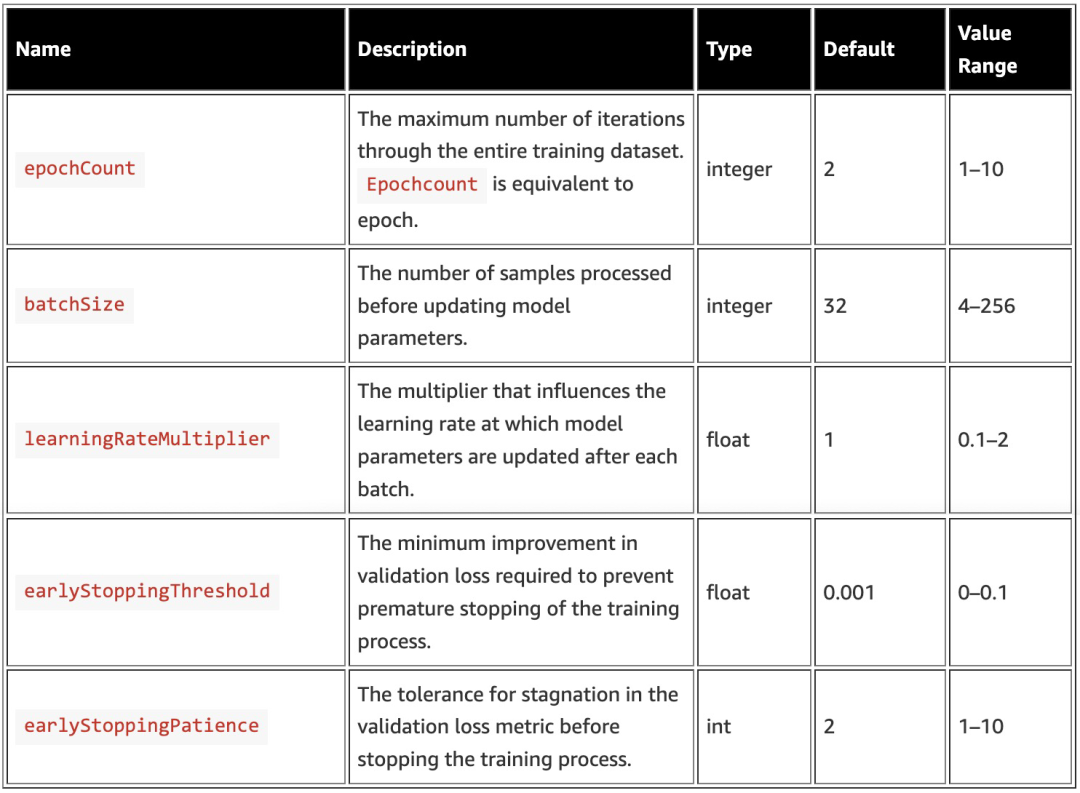
learningRateMultiplier 参数是一个调整基础学习率的因子,基础学习率由模型自身设置。它通过将模型的基础学习率与该乘数相乘,从而决定了训练过程中实际应用的学习率。通常,当训练数据集的大小增加时,您应该增加 batchSize 的值,并且可能需要执行超参数优化(HPO),以找到最佳设置。“早停止”是一种防止过拟合的技术,当验证损失停止改善时,它会停止训练过程。验证损失在每个 epoch 结束时计算。如果在 earlyStoppingPatience 个连续 epoch 内,验证损失没有足够下降(由 earlyStoppingThreshold 决定),训练过程将被停止。
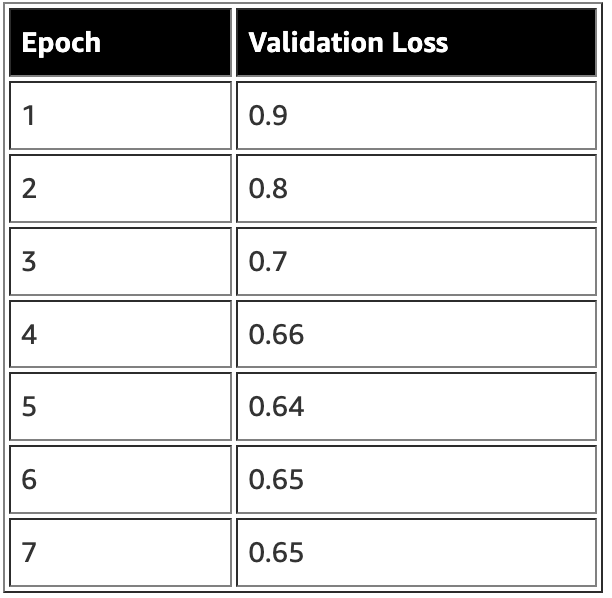
例如,下表显示了一个训练过程中每个 epoch 的示例验证损失值。
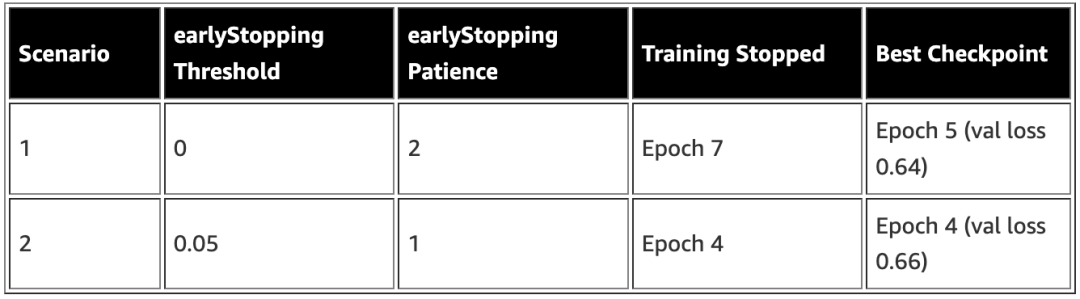
下表根据不同的 earlyStoppingThreshold 和 earlyStoppingPatience 配置,说明了在训练过程中早停止的行为。
选择合适的超参数值对于实现最优的微调性能至关重要。您可能需要尝试不同的设置,或使用诸如 HPO 之类的技术,来为您特定的使用场景和数据集找到最佳配置。
在 Amazon Bedrock 控制台上
运行微调作业
确保您已获得在 Amazon Bedrock 中微调 Anthropic Claude 3 Haiku 的预览版访问权限,如必备条件中所提到的。获得访问权限后,完成以下步骤:
1、在 Amazon Bedrock 控制台上,选择导航窗格中的 Foundation models。
2、选择 Custom models。
3、在 Models 部分的 Customize model 菜单中,选择 Create Fine-tuning job。
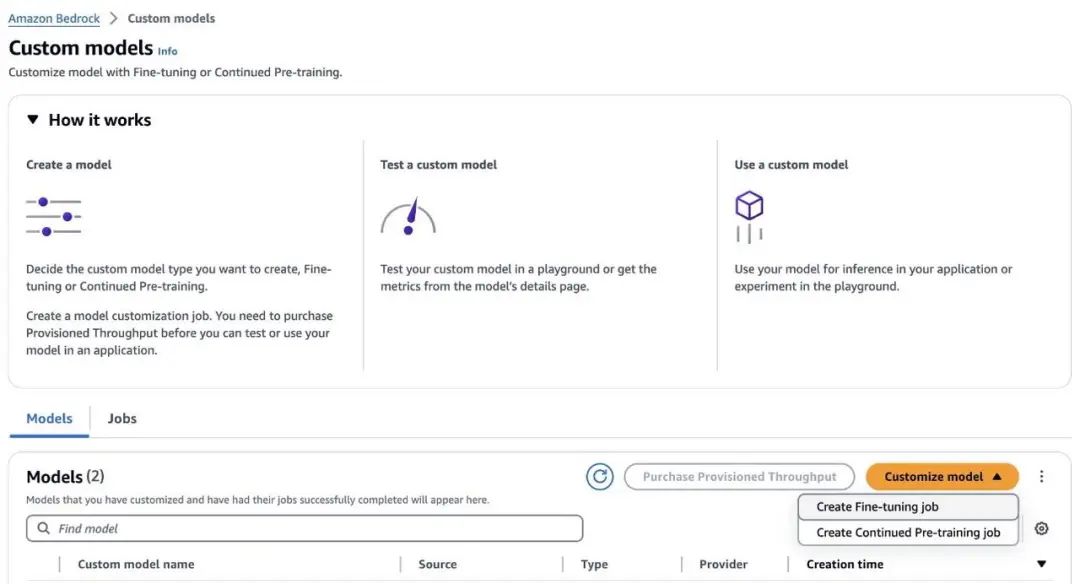
4、对于 Category (类别),选择 Anthropic。
5、对于 Models available for fine-tuning (可用于微调的模型),选择 Claude 3 Haiku。
6、选择 Apply (应用)。
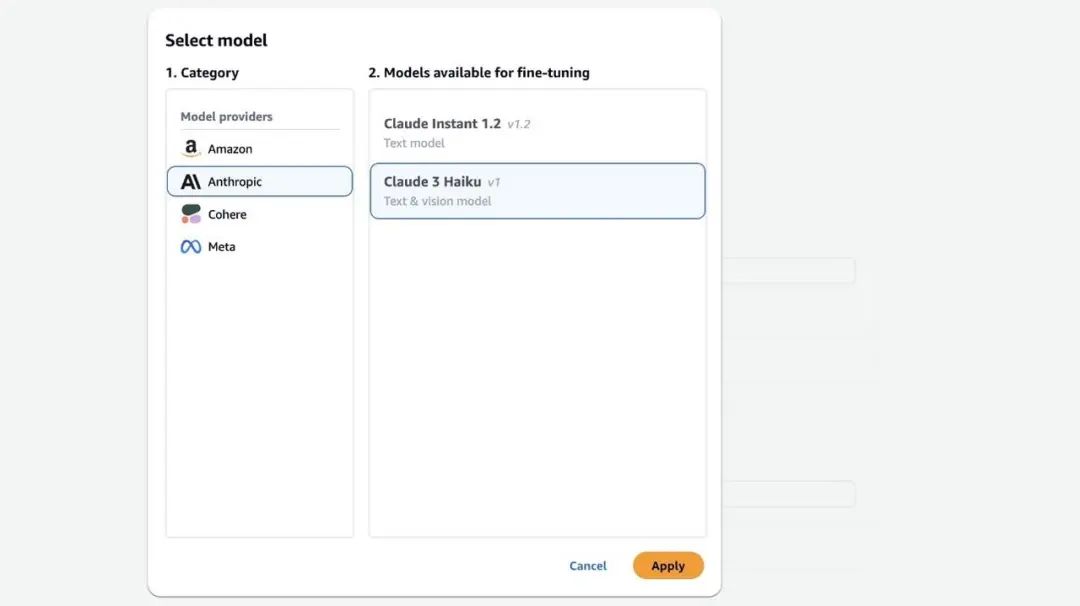
7、对于 Fine-tuned model name (微调后模型名称),输入一个模型名称。
8、选择 Model encryption (模型加密)以添加一个 KMS 密钥。
9、可选择展开 Tags (标签)部分,添加用于跟踪的标签。
10、对于 Job name (作业名称),输入一个训练作业名称。
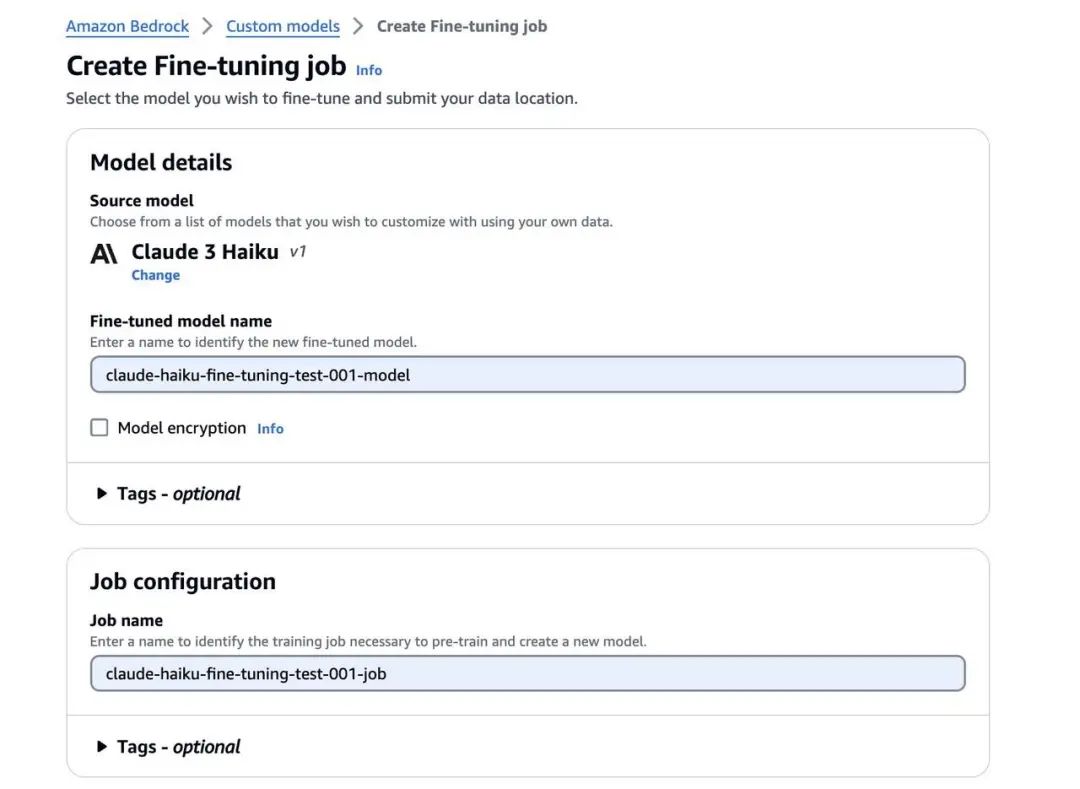
在开始微调作业之前,请按照先决条件中提到的,在与您的 Amazon Bedrock 服务位于同一区域(例如 us-west-2)内创建一个 S3 存储桶。在撰写本文时,Amazon Bedrock 中微调 Anthropic Claude 3 Haiku 的功能在美国西部(俄勒冈州)区域处于预览状态。在这个 S3 存储桶中,为您的训练数据、验证数据和微调制品设置单独的文件夹。将您的训练数据集和验证数据集分别上传到对应的文件夹中。
11、在 Input data (输入数据)下,指定您的训练数据集和验证数据集的 S3 位置。
这种设置可以为您的微调过程实施适当的数据访问和区域兼容性。
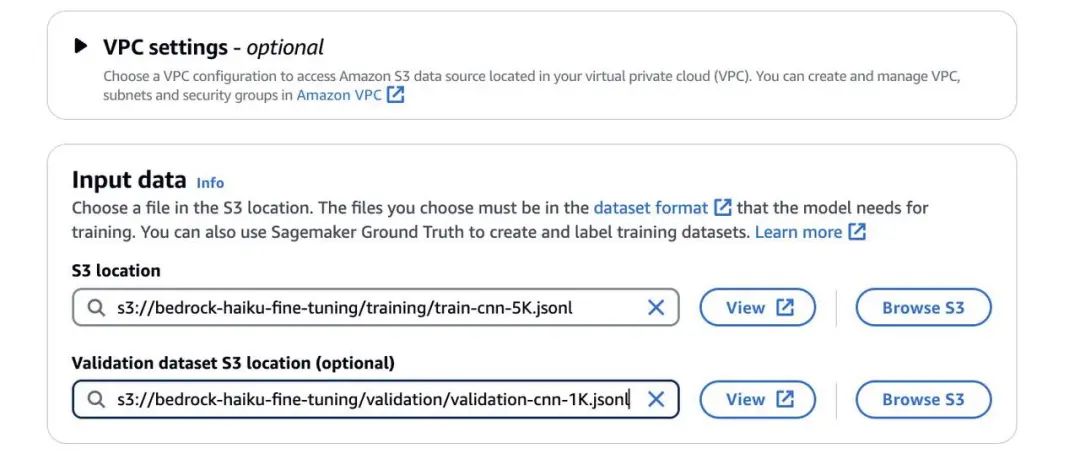
接下来,您需要为微调作业配置超参数。
12、设置 epochs 数量、batch 大小和学习率乘数。
13、如果您包含了验证数据集,可以启用早期停止功能。
此功能允许您设置一个早期停止阈值和容忍值。早期停止阈值有助于防止过拟合,当模型在验证集上的性能停止改善时,它会停止训练过程。
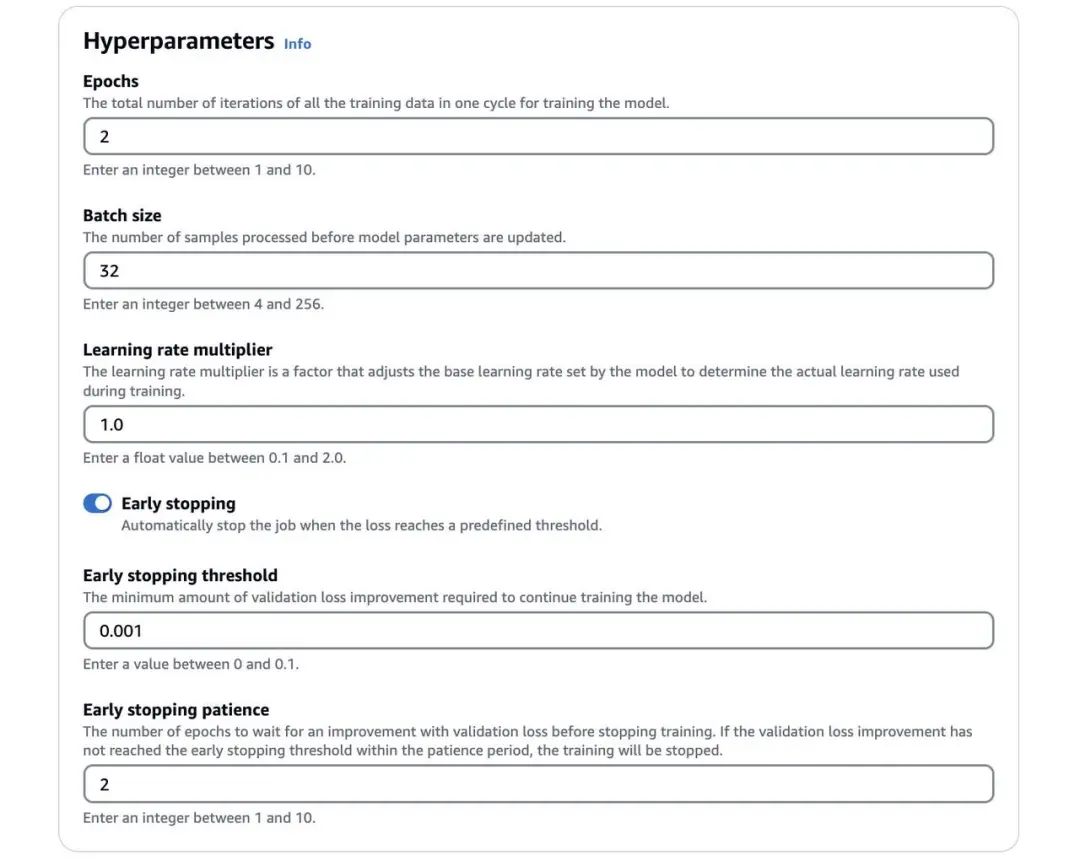
14、在 Output data (输出数据)下的 S3 location( S3 位置)中,输入将存储微调指标的存储桶的 S3 路径。
15、在 Service access(服务访问)下,选择一种授权 Amazon Bedrock 的方法。如果您有具有细粒度 IAM 策略的访问角色,可选择 Use an existing service role (使用现有服务角色),或选择 Create and use a new service role (创建并使用新的服务角色)。
16、在为微调 Anthropic Claude 3 Haiku 添加了所有必需配置后,选择 Create Fine-tuning job (创建微调作业)。
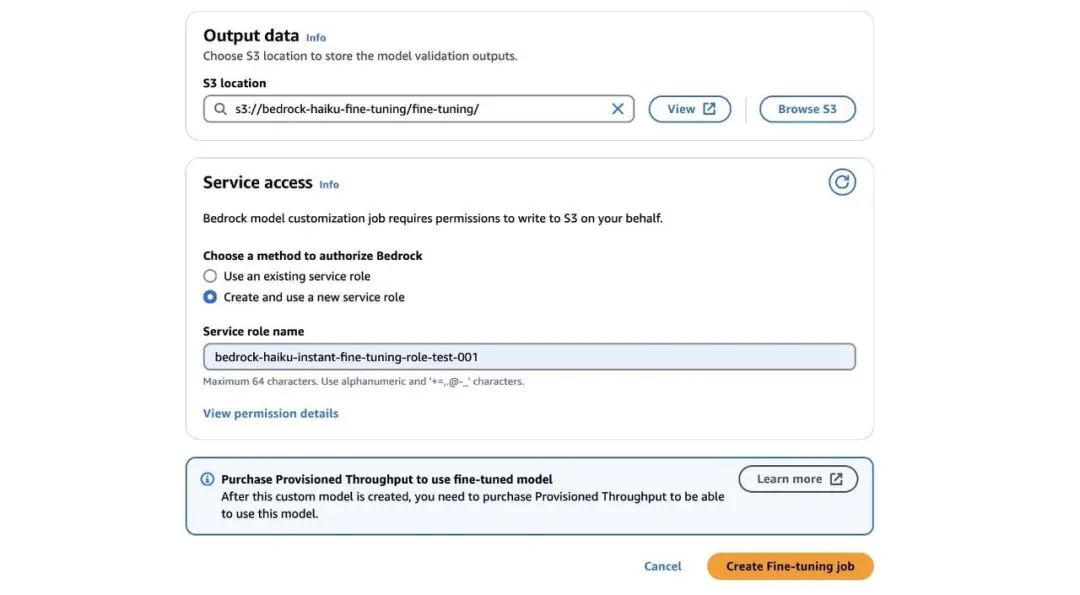
当微调作业开始时,您可以在 Jobs(作业)下查看训练作业的状态( Training (训练中)或 Complete (已完成))。
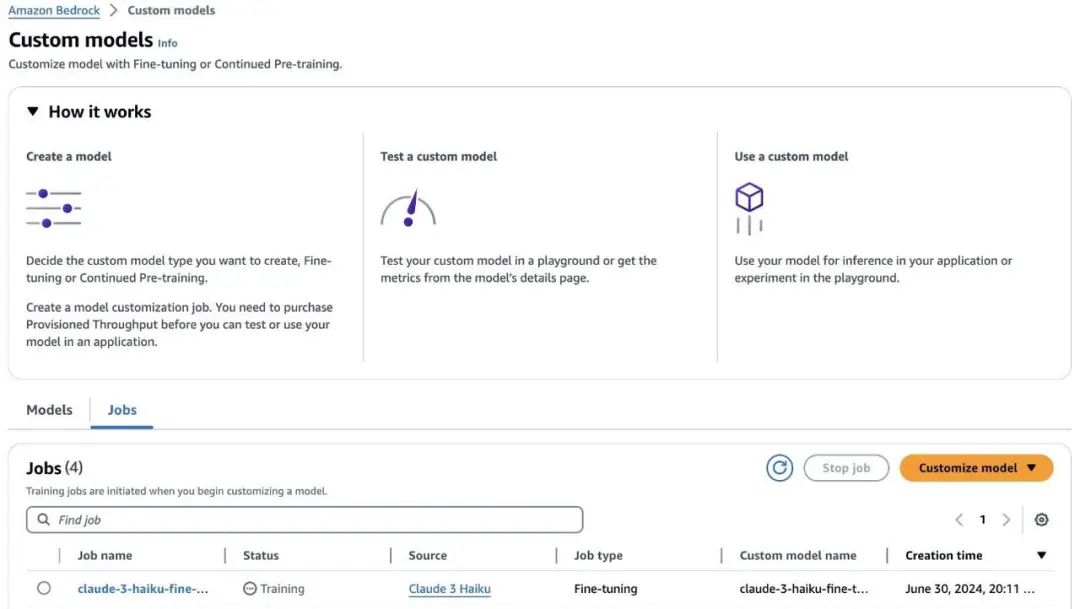
随着微调作业的进行,您可以找到有关训练作业的更多信息,包括作业创建时间、作业持续时间、输入数据以及用于微调作业的超参数。在 Output data (输出数据)下,您可以导航到 S3 存储桶中的微调文件夹,在那里您可以找到作为微调作业一部分计算出的训练和验证指标。
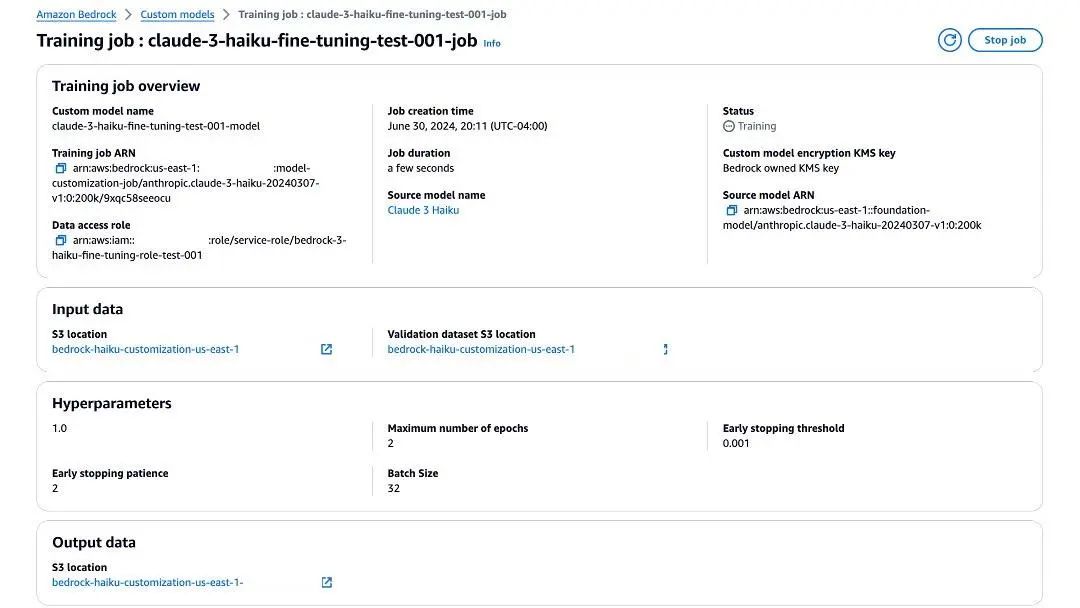
使用 Amazon Bedrock API 运行微调作业。
请确保按照先决条件中的说明申请访问 Amazon Bedrock 中微调 Anthropic Claude 3 Haiku 的预览版。
要使用 Amazon Bedrock API 启动 Anthropic Claude 3 Haiku 的微调作业,请完成以下步骤:
1、创建一个 Amazon Bedrock 客户端,并为 Anthropic Claude 3 Haiku 模型设置基础模型 ID:
- import boto3
- bedrock = boto3.client(service_name="bedrock")
- base_model_id = "anthropic.claude-3-haiku-20240307-v1:0:200k"
左右滑动查看完整示意
2、生成一个唯一的作业名称和自定义模型名称,通常使用时间戳:
- from datetime import datetime
- ts = datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
- customization_job_name = f"model-finetune-job-{ts}"
- custom_model_name = f"finetuned-model-{ts}"
左右滑动查看完整示意
3、指定具有访问微调作业所需资源权限的 IAM 角色 ARN,如先决条件中所述:
customization_role = "arn:aws:iam::<YOUR_AWS_ACCOUNT_ID>:role/<YOUR_IAM_ROLE_NAME>"左右滑动查看完整示意
4、将定制类型设置为 FINE_TUNING,并定义如前一节所述的微调模型的超参数:
- customization_type = "FINE_TUNING"
- hyper_parameters = {
- "epochCount": "5",
- "batchSize": "32",
- "learningRateMultiplier": "0.05",
- "earlyStoppingThreshold": "0.001",
- "earlyStoppingPatience": "2"
- }
左右滑动查看完整示意
5、配置将存储微调后模型和输出数据的 S3 存储桶和前缀,并提供您的训练数据集和验证数据集(验证数据集为可选)的 S3 数据路径:
- s3_bucket_name = "<YOUR_S3_BUCKET_NAME>"
- s3_bucket_config = f"s3://{s3_bucket_name}/outputs/output-{custom_model_name}"
- s3_train_uri = "s3://<YOUR_S3_BUCKET_NAME>/<YOUR_TRAINING_DATA_PREFIX>"
- s3_validation_uri = "s3://<YOUR_S3_BUCKET_NAME>/<YOUR_VALIDATION_DATA_PREFIX>"
- training_data_config = {"s3Uri": s3_train_uri}
- validation_data_config = {
- "validators": [{
- "s3Uri": s3_validation_uri
- }]
- }
左右滑动查看完整示意
6、在设置好这些配置后,您可以使用 Amazon Bedrock 客户端的 create_model_customization_job 方法创建微调作业,传入所需的参数:
- training_job_response = bedrock.create_model_customization_job(
- customizationType=customization_type,
- jobName=customization_job_name,
- customModelName=custom_model_name,
- roleArn=customization_role,
- baseModelIdentifier=base_model_id,
- hyperParameters=hyper_parameters,
- trainingDataConfig=training_data_config,
- validationDataConfig=validation_data_config,
- outputDataConfig=output_data_config
- )
左右滑动查看完整示意
create_model_customization 方法将返回一个包含已创建的微调作业信息的响应。您可以通过 Amazon Bedrock API 或 Amazon Bedrock 控制台监控作业进度,并在作业完成时检索微调后的模型。
部署和评估微调后的模型
成功微调模型后,您可以评估在该过程中记录的微调指标。这些指标将存储在指定的 S3 存储桶中以供评估。对于训练数据,将以 step_number、 epoch_number 和 training_loss 等列记录逐步的训练指标。
如果您提供了验证数据集,其他验证指标将存储在单独的文件中,包括 step_number、 epoch_number 和相应的 validation_loss。
当您对微调指标感到满意时,可以购买 Provisioned Throughput (预配置吞吐量)来部署您的微调模型,这允许您在应用程序中利用微调模型的改进性能和专门功能。预配置吞吐量是指模型处理和返回输入输出的数量和速率。要使用微调模型,您必须购买预配置吞吐量,该吞吐量将按小时计费。预配置吞吐量的定价取决于以下因素:
微调模型所定制的基础模型。
为预配置吞吐量指定的模型单元(MU)数量。MU 是指定给定模型吞吐量能力的单位;每个 MU 定义了它在 1 分钟内可以处理的输入 token 数量和可以生成的输出 token 数量。
承诺期限,可以是无承诺期、1 个月或 6 个月。承诺期限越长,每小时费率折扣越大。
设置完预配置吞吐量后,您可以使用 MessageAPI 调用微调后的模型,类似于调用基础模型。这提供了无缝过渡,并保持与现有应用程序或工作流程的兼容性。
评估微调模型的性能至关重要,以确保它满足所需标准并在特定任务中表现出众。您可以进行各种评估,包括将微调模型与基础模型进行比较,或者将性能与更高级的模型(如 Anthropic Claude 3 Sonnet)进行评估。

预配置吞吐量
扫码了解更多
使用 Amazon Bedrock 控制台
部署微调后的模型
使用 Amazon Bedrock 控制台部署微调后的模型,请执行以下步骤:
1、在 Amazon Bedrock 控制台上,选择导航窗格中的 Custom models (自定义模型)。
2、选择微调后的模型,并选择 Purchase Provisioned Throughput (购买预配置吞吐量)。
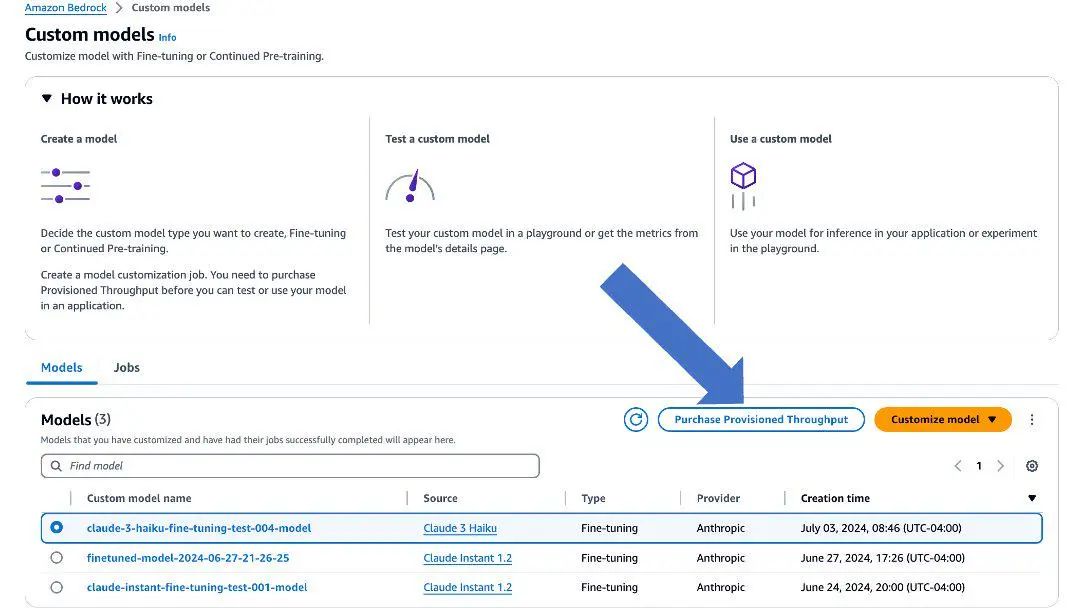
3、对于 Provisioned Throughput name (预配置吞吐量名称),输入一个名称。
4、选择您要部署的模型。
5、对于 Commitment term (承诺期限),选择您的承诺级别(在本文中,我们选择 No commitment (无承诺期))。
6、选择 Purchase Provisioned Throughput (购买预配置吞吐量)。
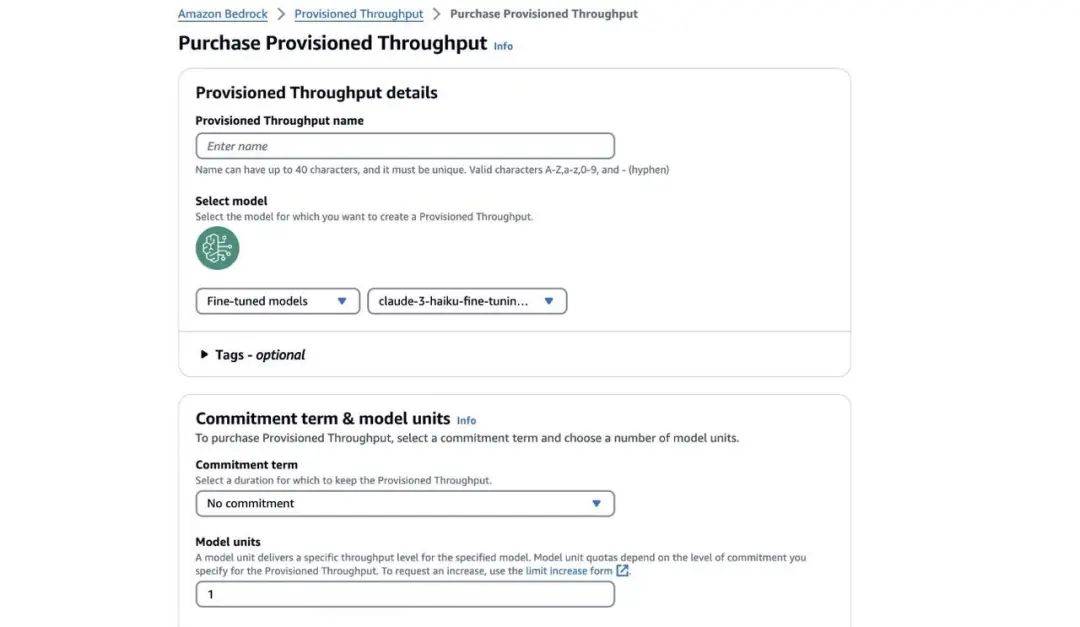
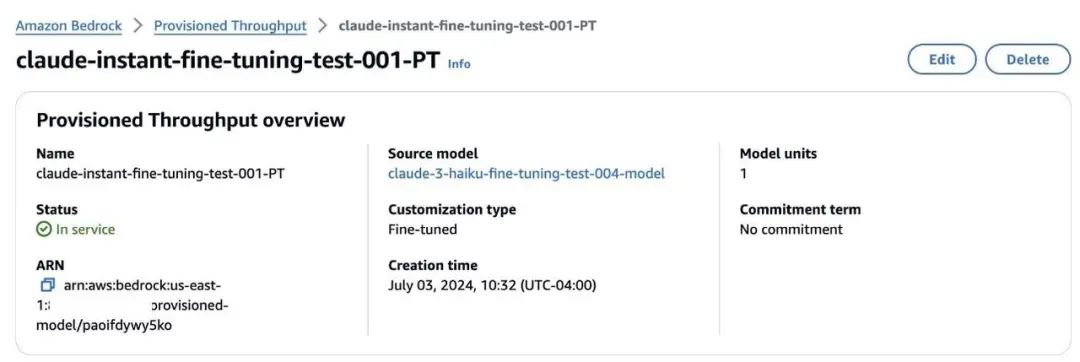
在使用预配置吞吐量部署完微调后的模型后,当您在 Amazon Bedrock 控制台上进入 Provisioned Throughput (预配置吞吐量)页面时,就可以看到该模型的状态显示为 In service(服务中)。
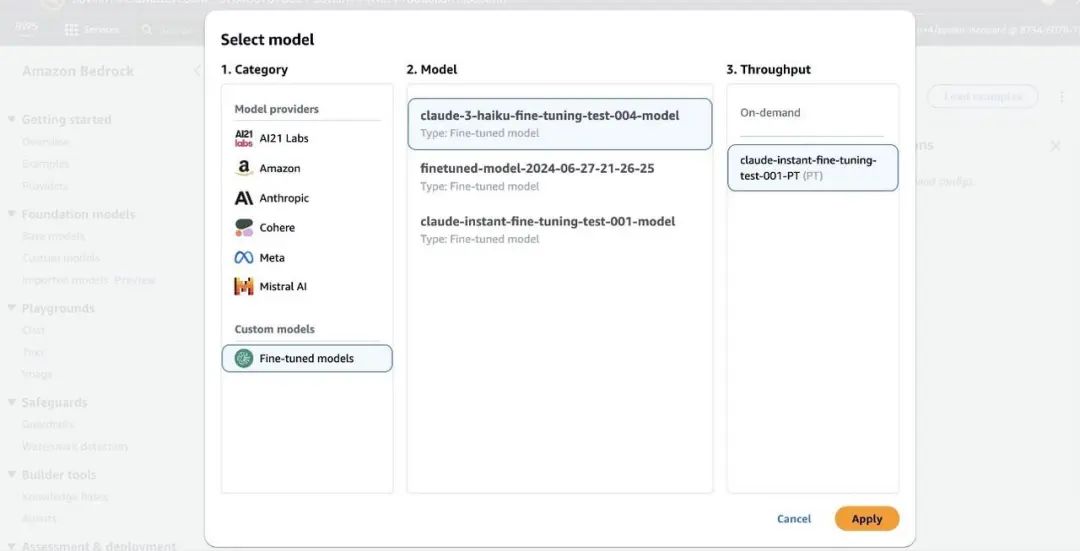
您可以将使用预配置吞吐量部署的微调后模型用于特定任务的使用场景。在 Amazon Bedrock playgrounds 中,您可以在 Custom models (自定义模型)下找到该微调后模型,并将其用于推理。
使用 Amazon Bedrock API
部署微调后的模型
使用 Amazon Bedrock API 部署微调后的模型,请完成以下步骤:
1、从作业输出中检索微调后模型的 ID,并使用所需的模型单元创建一个预配置吞吐量模型实例:
- import boto3
- bedrock = boto3.client(service_name='bedrock')
-
-
- custom_model_id = training_job_response["customModelId"]
- provisioned_model_id = bedrock.create_provisioned_model_throughput(
- modelUnits=1,
- provisionedModelName='finetuned-haiku-model',
- modelId=custom_model_id
- )['provisionedModelArn']
左右滑动查看完整示意
2、当预配置吞吐量模型就绪后,您可以从 Amazon Bedrock 运行时客户端调用 invoke_model 函数,利用微调后的模型生成文本:
- import json
- bedrock_runtime = boto3.client(service_name='bedrock-runtime')
-
-
- body = json.dumps({
- "anthropic_version": "bedrock-2023-05-31",
- "max_tokens": 2048,
- "messages": [{"role": "user", "content": <YOUR_INPUT_PROMPT_STRING>}],
- "temperature": 0.1,
- "top_p": 0.9,
- "system": <YOUR_SYSTEM_PROMPT_STRING>
- })
-
-
- fine_tuned_response = bedrock_runtime.invoke_model(body=body, modelId=provisioned_model_id)
- fine_tuned_response_body = json.loads(fine_tuned_response.get('body').read())
- print("Fine tuned model response:", fine_tuned_response_body['content'][0]['text']+'\n')
左右滑动查看完整示意
通过遵循这些步骤,您可以通过 Amazon Bedrock API 部署和使用您微调后的 Anthropic Claude 3 Haiku 模型,生成符合您特定需求的定制 Anthropic Claude 3 Haiku 模型。
结论
在 Amazon Bedrock 上进行 Anthropic Claude 3 Haiku 的微调,为企业提供了一种灵活且高效的手段,以满足其特定的业务需求。通过结合 Amazon Bedrock 和 Anthropic Claude 3 Haiku 的速度与成本效益,企业能够实现对这种大型语言模型的深度定制,同时确保了强大的安全性。微调过程不仅提升了模型的准确性,还根据企业的独特需求定制了模型的输出,这种定制化的服务,显著提高了企业的工作效率和效果。
Amazon Bedrock 中微调 Anthropic Claude 3 Haiku 的功能目前在美国西部(俄勒冈州)区域处于预览阶段。若需申请访问预览版,请与您的亚马逊云科技账户团队联系或提交支持工单。
本篇作者

Yanyan Zhang
亚马逊云科技高级生成式 AI 数据科学家。作为生成式 AI 专家,她一直致力于尖端的人工智能与机器学习技术,帮助客户利用生成式 AI 实现预期目标。Yanyan 获得了德克萨斯 A&M 大学电气工程博士学位。工作之余,喜欢旅行、锻炼和探索新事物。

Sovik Kumar Nath
亚马逊云科技人工智能/机器学习和生成式 AI 高级解决方案架构师。他在金融、运营、营销、医疗保健、供应链管理和物联网等领域拥有设计端到端机器学习和业务分析解决方案的丰富经验。他拥有南佛罗里达大学和瑞士弗里堡大学的双硕士学位,以及印度理工学院卡拉格普尔分校的学士学位。

Carrie Wu
亚马逊云科技应用科学家。她的工作重点是微调大型语言模型以适应定制任务和负责任的人工智能。她毕业于斯坦福大学,获得管理科学与工程博士学位。

Fang Liu
亚马逊云科技主要机器学习工程师。他在利用尖端技术构建人工智能/机器学习产品方面拥有丰富的经验。他参与了 Amazon Transcribe 和 Amazon Bedrock 等知名项目。拥有清华大学计算机科学专业的硕士学位。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
点击阅读原文查看博客,获得更详细内容
听说,点完下面4个按钮
就不会碰到bug了!


