
- 1HarmonyOS鸿蒙开发常用组件详细说明(图片、文本、按钮、弹窗、进度条、文本框)_鸿蒙组件
- 2pikachu—暴力破解_pikachu kali
- 3Cyber Weekly #13_口述全球大模型这半年:perplexity突然火爆和尚未爆发的ai应用生态
- 4git pull --rebase PK git pull
- 5解决Java应用程序中的SQLException:Access denied for user ‘root‘@‘localhost‘ 错误_caused by: java.sql.sqlexception: access denied fo
- 6【RK3568+RV1126】NPU算力集成_rk3568 npu
- 7在modelsim中添加altera库_modelsim-altera 位置
- 8厉害,刚刚官方宣布 IntelliJ IDEA 2020.2 EAP4发布了!
- 9C++ STL面试题_c++ stl 面试题
- 10关于个人与团队管理转身_在个人业务高手向团队管理转化的过程中,你认为的难点是什么,如何改进
Re12:读论文 Se3 Semantic Self-segmentation for Abstractive Summarization of Long Legal Documents in Low_selfsegmentation
赞
踩
论文名称:Semantic Self-segmentation for Abstractive Summarization of Long Legal Documents in Low-resource Regimes
AAAI官方预印版论文下载地址:https://www.aaai.org/AAAI22Papers/AAAI-3882.MoroG.pdf
官方软件demo:http://137.204.107.42:37338/
本文是2022年AAAI论文,关注法律文书生成式摘要。
本文关注的难点及对应的解决方案:
- 法律文书过长,标准Transformer复杂度随输入长度呈平方增长,小GPU放不下,直接truncate输入会导致信息缺失问题→将文本切分为多个较小的语义连续块(semantically coherent chunks),每次只在这些较短的块上做生成式摘要。
- 标注数据少→将文本切分为多个chunks,一起训练生成模型,作为数据增强操作。
将长文本输入分割为semantically coherent chunks(标准是余弦相似度大于chunk内平均值,我感觉这个实在是可以说是非常的简单粗暴了),摘要中每一个句子都与某一最相似的chunk匹配(标准是ROUGE-1-P)。(用来做切分的语言模型legal-bert先在一个度量学习任务上微调过)
使用同一个模型来生成摘要(也有做数据增强的意义在),这个生成模型是直接套用的之前的生成式模型。
最后合并所有chunks的摘要为最终结果。
1. 模型Re3
数据切分(先切分原文,然后将摘要与对应的原文chunk匹配,形成原文-摘要对)→摘要生成
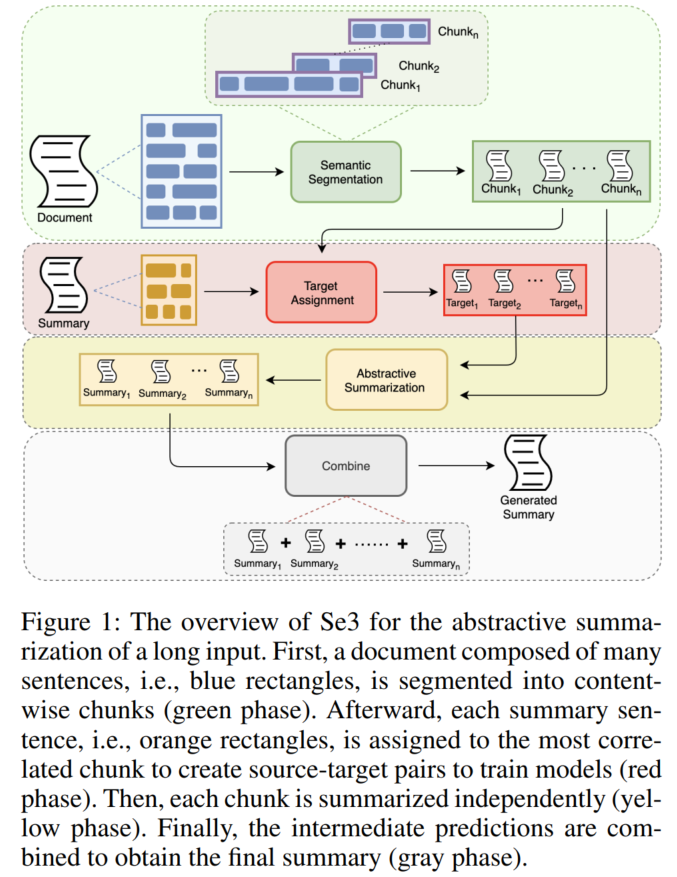
数据切分阶段:
- 切分原文(以句子为单位进行合并):
- 句子表征:使用在度量学习(metric learning)任务上微调过的Legal-Bert预训练模型实现句嵌入。
- 规定每个连续块token的最大长度和最小长度,当chunk加入新句子后的token数仍在二者范围内时,如果 新句子表征与当前chunk中每一句表征的余弦相似度的平均值 大于 新句子与下一chunk(这个chunk是look-ahead生成的,是后文直接组成chunk最小长度)中每一句表征的余弦相似度的平均值,则将新句子加入该chunk。
- 匹配摘要:将摘要中的每一句与其ROUGE-1-P值最高的chunk进行匹配。(Precision最高:该chunk中包含该句的内容最多)。
- 训练阶段丢弃没有匹配摘要的chunk。
摘要生成阶段:直接用已有的生成模型。论文中比较了BART(quadratic Transformer)和LED(linear Transformer,能输入更长的序列)的base模型的效果。
优化:
- look-ahead chunk的优势:不需要人工规定新句子能否加入chunk的余弦相似度平均值的阈值。
- 设置chunk的最小长度是为了充分利用GPU,最大长度是为了chunk能够完整地放进GPU。
2. 实验
2.1 实验设置
- 微调Legal-Bert预训练模型的度量学习任务:比较了使用triplet loss和contrastive loss的区别。
在Legal-Bert上训练了1个epoch,batch size为8,学习率为 2 × 1 0 − 5 2\times 10^{-5} 2×10−5 - BART和LED模型都使用了base版本,因为large版本太大了放不进GPU。
训练阶段:5个epoch,batch size为1,linear schedule( 5 × 1 0 − 5 5\times 10^{-5} 5×10−5)
推理阶段:beam size和length penalty都是2
2.2 主实验结果
baseline是PEGASUS(论文里没有写具体配置)和直接使用chunk最大token长度来进行truncation的BART、LED模型,此外比较了不同的chunk最大长度和最小长度的实验结果(显然长度越长效果越好。比较了一个GPU内存占比和结果的tradeoff):
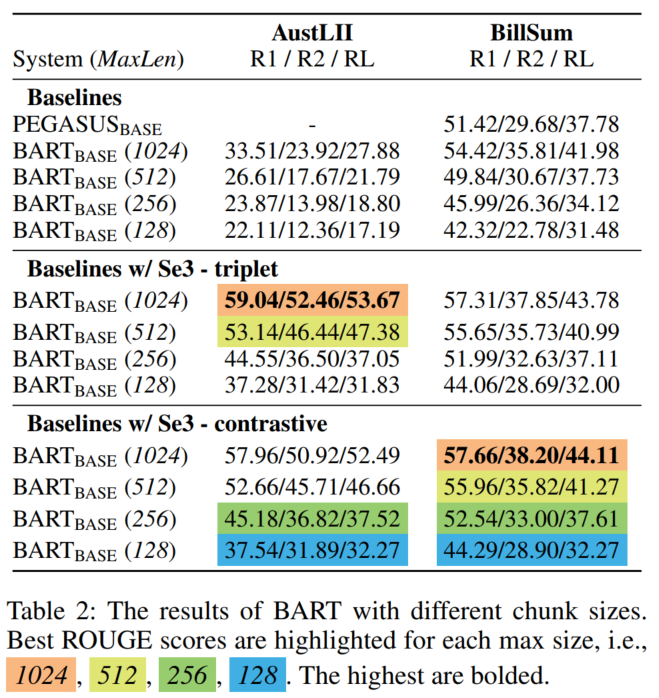
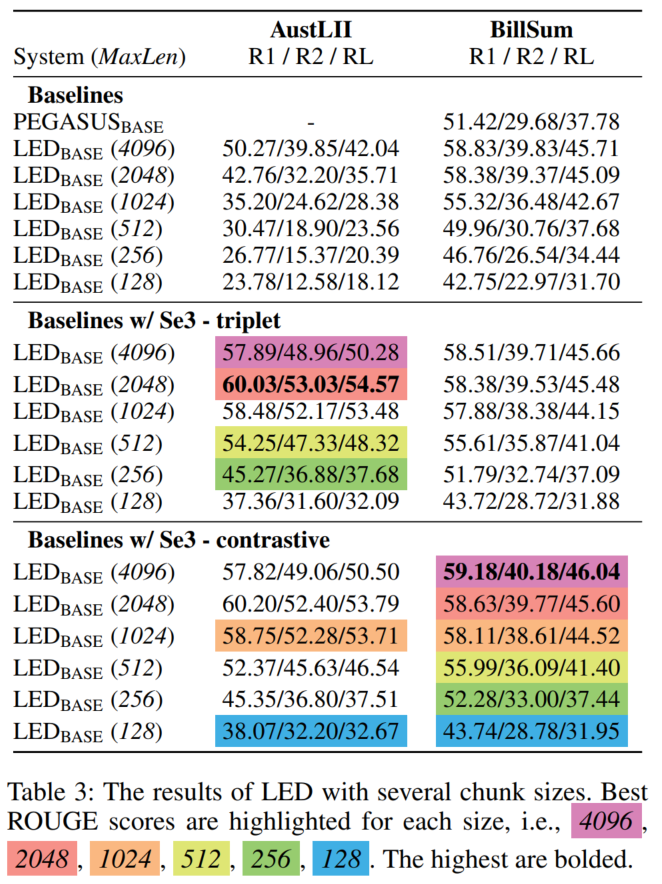
2.3 模型分析
2.3.1 label scarcity问题
仅使用10个或100个标记数据。结果证明了Se3方法在低资源条件下的效果:
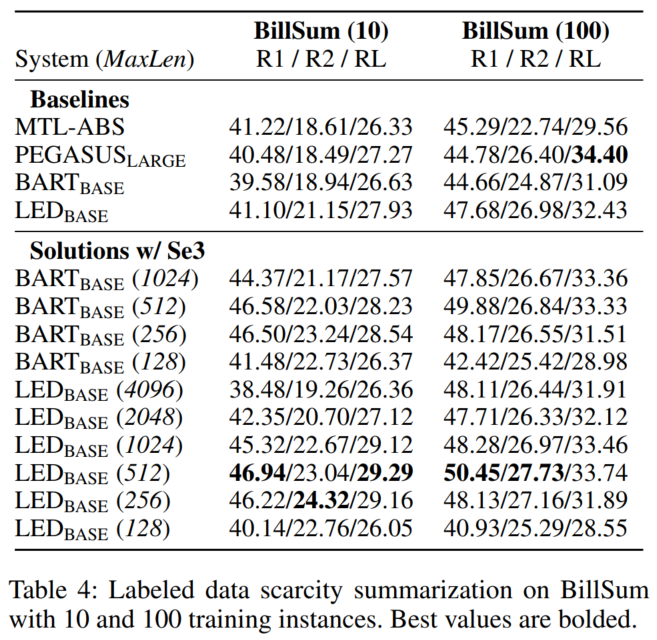
2.3.2 Ablation Study
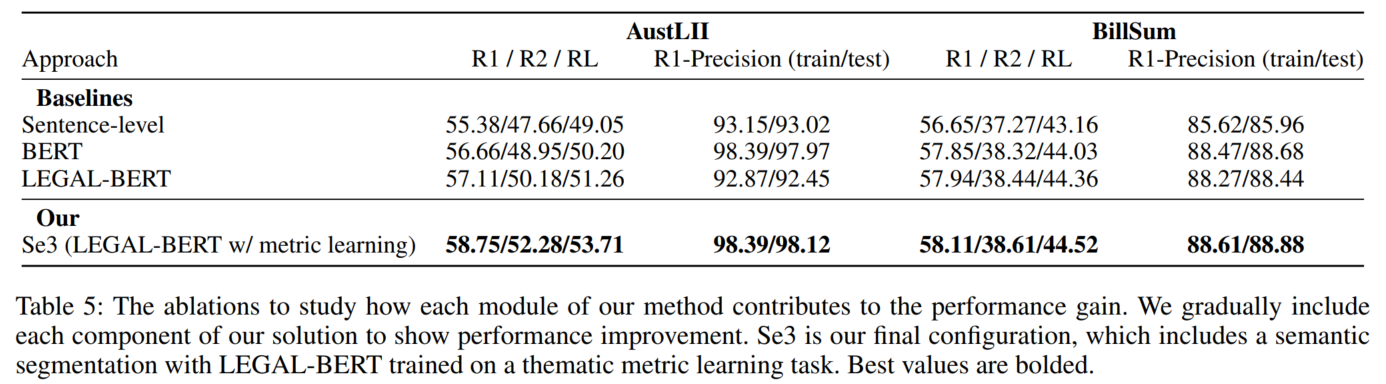
语义连续chunk的效果,baseline是:1. 不考虑语义连续信息,直接用句子组成chunk。2. 使用BERT。3. 使用没有在度量学习任务上微调过的Legal-Bert。
2.3.3 其他指标分析
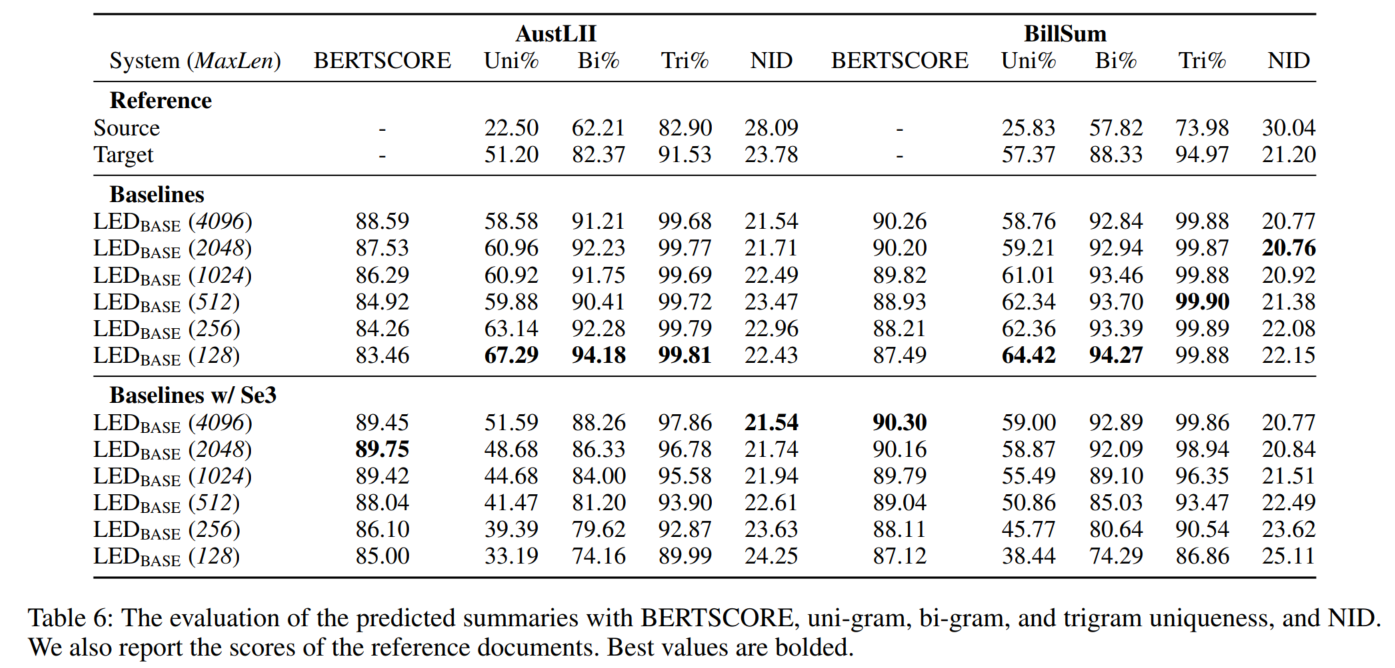
- BERTSCORE
- eventual redundancy:(1) 只出现过一次的n_gram的占比 (2) Normalized Inverse of Diversity (NID) (考虑到不同chunk摘要合并时可能产生冗余)
3. 论文阅读时产生的其他问题
- 语义连续块只是表征的相似性较高,但并没有真的含有某种语义。而且感觉这种截断方式很简单粗暴。既然最后都要和摘要匹配,为什么不先用摘要匹配然后再切分,感觉这样更有可能保留更合理的语义结构信息。但是确实这样会导致测试阶段难以操作……除非先训练个模型来选,但是这样又感觉无异于先抽取后生成范式了。
- 在训练阶段直接丢弃没有匹配摘要的原文连续块感觉不合理,测试时候咋办?
- 虽然原文声称文本信息必须要阅读全文后才能得到,但其实各连续块之间也没有信息交互,事实上还是分块做的。
- 感觉衡量冗余度的标准有些奇怪,真实摘要的这个值就比较低,所以生成结果的指标即使高也感觉是偏离真实值了,这样能说明它效果好吗?
4. 代码复现
官方没有给出代码,我发邮件问了作者还没有回复。
但是看起来这个代码倒是不难写,等我有需要了复现一下,跟demo展示的结果对比对比。

