
- 1Macbook 电脑的Type-c接口失灵怎么办_macbook一个充电口失灵
- 2List 删除其中的空元素或者null元素_c# list 删除空值
- 3论文导读 | 图生成模型综述_matlab erdos-renyi topology
- 4一定要用相同的Context 对同一个receiver进行registerReceiver与unregisterReceiver吗?_android registerreceiver 同一个receiver
- 5免费且好用的ssh工具FinalShell的下载与安装_finalshell安装
- 6【面经】小米-软件开发工程师c++-北京-人才库_小米软件开发工程师,c++方向
- 7[转](21条消息) Pico Neo 3教程☀️ 二、从 PicoVR Unity SDK 迁移至 Unity XR SDK_pico怎么导入3d文件
- 8从根儿上学习spring 九 之run方法启动第四段(3)
- 9Stable Diffusion 2.0来了!网友:太快了,V1还没整透彻,V2就来了
- 10交叉编译 QT5.12.2
python机器学习 基于决策树的MNIST数字分类 详细教程 数据集+源码+远程部署
赞
踩
数据集+源码:python机器学习 基于决策树的MNIST数字分类 详细教程 数据集+源码+远程部署
目录
介绍
决策树是一种非常受欢迎的机器学习算法,它可以用于分类和回归任务。在基于决策树的MNIST数字分类中,算法会学习如何从手写数字的图像像素值中提取特征,并根据这些特征来决定图像表示的数字(0到9)。
MNIST数据集是一个包含了手写数字的大型数据库,常用于训练各种图像处理系统。数据集包含60000个训练样本和10000个测试样本。每个样本是一个28x28像素的灰度图像。
要使用决策树进行MNIST数字分类,可以按照以下步骤:
-
数据预处理:加载MNIST数据集,并将图像的28x28像素矩阵平展成一个长度为784的一维数组。这样每个图像就变成了一个特征向量。
-
创建决策树模型:选择一种决策树算法,例如CART(分类和回归树)或者ID3等,然后使用训练数据集来训练模型。
-
训练模型:使用训练集中的图像和对应的标签来训练决策树模型。决策树将会学习如何根据像素值的特征进行分类。
-
评估模型:在测试数据集上评估决策树模型的性能。可以计算准确率(accuracy)、精确度(precision)、召回率(recall)和F1分数等指标来衡量模型的分类能力。
-
优化模型:可能需要调整决策树的一些参数,比如树的深度、最小分裂所需的样本数等,来优化模型的性能。
-
使用模型:一旦模型经过足够的训练并且评估指标令人满意,就可以用它来对新的手写数字图像进行分类。
虽然决策树模型相对简单并且易于理解,它们在处理像MNIST这样的高维数据时通常不如深度学习模型效果好。如果需要高精度的图像分类,可能会考虑使用卷积神经网络(CNN)等更复杂的算法。
[[ 0. 0. 5. 13. 9. 1. 0. 0.]
[ 0. 0. 13. 15. 10. 15. 5. 0.]
[ 0. 3. 15. 2. 0. 11. 8. 0.]
[ 0. 4. 12. 0. 0. 8. 8. 0.]
[ 0. 5. 8. 0. 0. 9. 8. 0.]
[ 0. 4. 11. 0. 1. 12. 7. 0.]
[ 0. 2. 14. 5. 10. 12. 0. 0.]
[ 0. 0. 6. 13. 10. 0. 0. 0.]]
加载数据
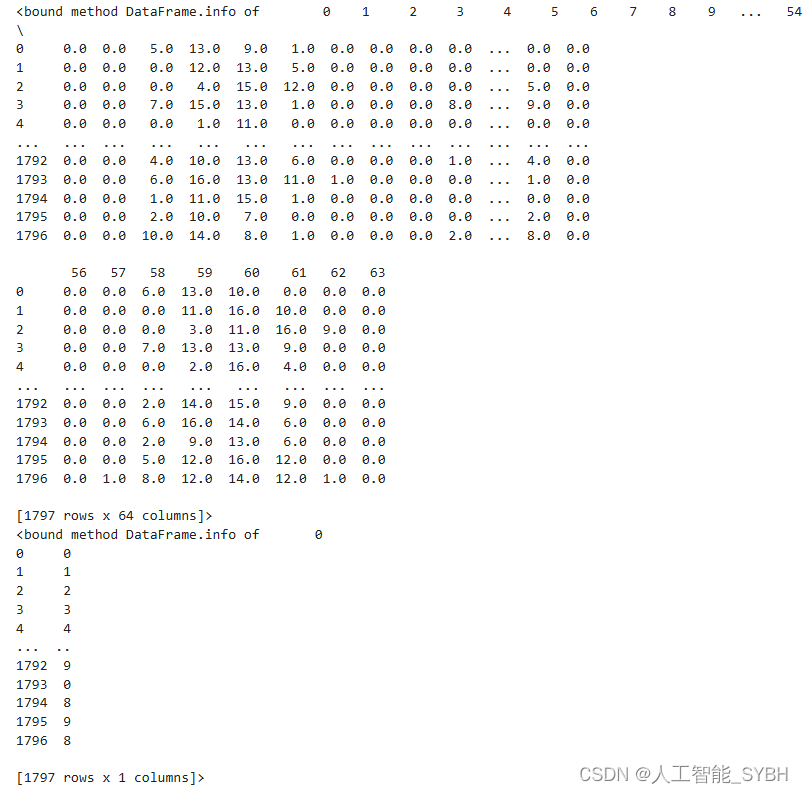
- X, y = sklearn.datasets.load_digits(return_X_y=True)
- X = pd.DataFrame(X)
- y = pd.DataFrame(y)
-
- print(X.info)
- print(y.info)
数据处理
- cate_cols = [] # 离散特征
- num_cols = [] # 数值型特征
-
- # 获取各个特征的数据类型
- dtypes = X.dtypes
-
- for col, dtype in dtypes.items():
- if dtype == 'object':
- cate_cols.append(col)
- else:
- num_cols.append(col)
数值型特征
- class Num_Encoder(BaseEstimator, TransformerMixin):
- def __init__(self, cols=[], fillna=False, addna=False):
- self.fillna = fillna
- self.cols = cols
- self.addna = addna
- self.na_cols = []
- self.imputers = {}
-
- def fit(self, X, y=None):
- for col in self.cols:
- if self.fillna:
- self.imputers[col] = X[col].median()
- if self.addna and X[col].isnull().sum():
- self.na_cols.append(col)
- print(self.na_cols, self.imputers)
- return self
-
- def transform(self, X, y=None):
- df = X.loc[:, self.cols]
- for col in self.imputers:
- df[col].fillna(self.imputers[col], inplace=True)
- for col in self.na_cols:
- df[col + '_na'] = pd.isnull(df[col])
- return df

离散型特征
- class Cat_Encoder(BaseEstimator, TransformerMixin):
- def __init__(self, cols, max_n_cat=7, onehot_cols=[], orders={}):
- self.cols = cols
- self.onehot_cols = onehot_cols
- self.cats = {}
- self.max_n_cat = max_n_cat
- self.orders = orders
-
- def fit(self, X, y=None):
- df_cat = X.loc[:, self.cols]
-
- for n, c in df_cat.items():
- df_cat[n].fillna('NAN', inplace=True)
- df_cat[n] = c.astype('category').cat.as_ordered()
-
- if n in self.orders:
- df_cat[n].cat.set_categories(self.orders[n], ordered=True, inplace=True)
-
- cats_count = len(df_cat[n].cat.categories)
-
- if cats_count <= 2 or cats_count > self.max_n_cat:
- self.cats[n] = df_cat[n].cat.categories
- if n in self.onehot_cols:
- self.onehot_cols.remove(n)
- elif n not in self.onehot_cols:
- self.onehot_cols.append(n)
-
- print(self.onehot_cols)
- return self
-
- def transform(self, df, y=None):
- X = df.loc[:, self.cols]
-
- for col in self.cats:
- X[col].fillna('NAN', inplace=True)
- X.loc[:, col] = pd.Categorical(X[col], categories=self.cats[col], ordered=True)
- X.loc[:, col] = X[col].cat.codes
-
- if len(self.onehot_cols):
- df_1h = pd.get_dummies(X[self.onehot_cols], dummy_na=True)
- df_drop = X.drop(self.onehot_cols, axis=1)
- return pd.concat([df_drop, df_1h], axis=1)
-
- return X
配置流水线
- num_pipeline = Pipeline([
- ('num_encoder', Num_Encoder(cols=num_cols, fillna='median', addna=True)),
- ])
- X_num = num_pipeline.fit_transform(X)
-
- cat_pipeline = Pipeline([
- ('cat_encoder', Cat_Encoder(cols=cate_cols))
- ])
- X_cate = cat_pipeline.fit_transform(X)

数据集训练集划分(8:2)
- X = pd.concat([X_num, X_cate], axis=1)
- print(X.shape, y.shape)
-
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2022)
- print('【训练集】', X_train.shape, y_train.shape)
- print('【测试集】', X_test.shape, y_test.shape)

模型
- dtc = DecisionTreeClassifier(max_depth=5,
- criterion='gini',
- random_state=2022)
模型训练
dtc.fit(X_train, y_train)

训练集测试集验证
- y_train_pred = dtc.predict(X_train)
- y_test_pred = dtc.predict(X_test)
-
- accuracy_train = metrics.accuracy_score(y_train, y_train_pred)
- accuracy_test = metrics.accuracy_score(y_test, y_test_pred)
-
- print('训练集的accuracy: ', accuracy_train)
- print('测试集的accuracy: ', accuracy_test)
![]()
网格搜索
- dtcmodel = DecisionTreeClassifier()
-
- param_grid_dtc = {
- 'criterion': ['gini', 'entropy'],
- 'splitter': ['best', 'random'],
- 'max_depth': range(2, 10, 2),
- 'min_samples_split': range(1, 5, 1),
- 'max_features': ['auto', 'sqrt', 'log2']
- }
-
- dtcmodel_grid = GridSearchCV(estimator=dtcmodel,
- param_grid=param_grid_dtc,
- verbose=1,
- n_jobs=-1,
- cv=2)
- dtcmodel_grid.fit(X_train, y_train)
-
- print('【DTC】', dtcmodel_grid.best_score_)
![]()
- best_modeldtc = DecisionTreeClassifier(criterion=dtcmodel_grid.best_estimator_.get_params()['criterion'],
- splitter=dtcmodel_grid.best_estimator_.get_params()['splitter'],
- max_depth=dtcmodel_grid.best_estimator_.get_params()['max_depth'],
- min_samples_split=dtcmodel_grid.best_estimator_.get_params()['min_samples_split'],
- max_features=dtcmodel_grid.best_estimator_.get_params()['max_features'],)
best_modeldtc.fit(X_train, y_train)

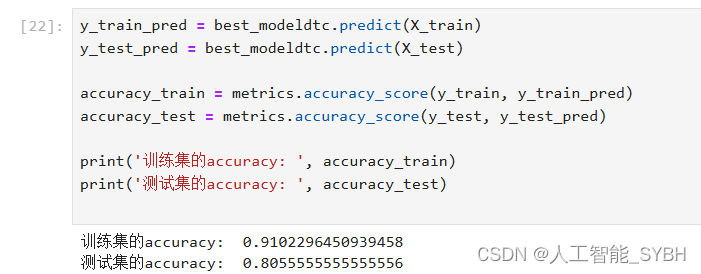
- y_train_pred = best_modeldtc.predict(X_train)
- y_test_pred = best_modeldtc.predict(X_test)
-
- accuracy_train = metrics.accuracy_score(y_train, y_train_pred)
- accuracy_test = metrics.accuracy_score(y_test, y_test_pred)
-
- print('训练集的accuracy: ', accuracy_train)
- print('测试集的accuracy: ', accuracy_test)
![]()

