
- 12021年面试,整理全网初、中、高级常见Java面试题_面试 初中高级算法
- 2vuefullcalendar怎么判断切换上下月_死锁;上下文切换;常用缓存淘汰策略FIFO、LFU、LRU...
- 3js中会改变原数组的方法及不改变原数组的方法整理_js数组方法会改变原数组
- 4简述OpenStack和华为私有云HCS_fusionsphere openstack
- 5OpenCV基础知识(9)— 视频处理(读取并显示摄像头视频、播放视频文件、保存视频文件等)_opencv播放视频
- 6[Python3网络爬虫开发实战] pyspider 框架介绍_pyspider 后端数据库是什么
- 7LeetCode1 Java_leetcode java 1
- 8高考结束了,聊聊洋哥从学生至今的成长之路~_findyi真实身份
- 9文本生成 [1] 文本生成任务&评分指标
- 10【狂神说Java】Mybatis笔记_【狂神说java】mybatis 笔记
Google推出Gemma 2.0,Gemma家族迎来全新一员_gemma2 token
赞
踩
自从Google在2022年开始开发生成式AI以来,已经过去了2年了。在此期间,OpenAI不断地推出ChatGPT的全新版本,目前最新的大模型已经是ChatGPT-4o,拥有1750亿到2800亿左右的训练数据,是OpenAI目前的当家旗舰。
最近,Google也推出了自己最新的模型:Gemma 2.0,分为9B和27B两个版本。
Gemma介绍
自从bard后,Gemini家族成为了Google公司的当家大模型,不过Google为了给开源社区贡献创新,于是用Gemini模型的相同研究和技术构建了Gemma,Gemma这个名字反映了拉丁语“gemma”,意思是宝石,以支持开发人员创新,促进协作,并指导负责任地使用Gemma模型。
Gemma is a family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. Developed by Google DeepMind and other teams across Google, Gemma is inspired by Gemini, and the name reflects the Latin gemma, meaning “precious stone.” Accompanying our model weights, we’re also releasing tools to support developer innovation, foster collaboration, and guide responsible use of Gemma models.
不仅只有Gemma,Google还在其基础上衍生出了CodeGemma、RecurrentGemma和PaliGemma
其中CodeGemma是建立在Gemma之上的轻量级开放代码模型的集合。CodeGemma模型是仅文本到文本和文本到代码解码器的模型,可作为70亿个预训练的变体,专门用于代码完成和代码生成任务,70亿个参数指令调谐变体,用于代码聊天和指令跟随,以及20亿个参数预训练变体,用于快速代码完成。
RecurrentGemma是一个基于谷歌开发的新型循环架构的开放语言模型家族。预训练版和指令调谐版都有英文版。您可以在技术报告中找到有关RecurrentGemma的更多详细信息。与Gemma一样,RecurrentGemma模型非常适合各种文本生成任务,包括问题回答、总结和推理。由于其新颖的架构,RecurrentGemma比Gemma需要更少的内存,并且在生成长序列时实现更快的推理。
PaliGemma是一个多功能和轻量级的视觉语言模型(VLM),灵感来自PaLI-3,基于SigLIP视觉模型和Gemma语言模型等开放组件。它同时将图像和文本作为输入,并生成文本作为输出,支持多种语言。它专为在各种视觉语言任务(如图像和短视频字幕、视觉问题回答、文本阅读、对象检测和对象分割)上进行一流的微调性能而设计。
摘自:kaggle
Gemma 2.0
它是Google继Gemma 1.0后推出的模型,根据重新设计的架构构建了Gemma 2,旨在实现卓越的性能和推理效率。
以下是Google官方给出的优点:
-
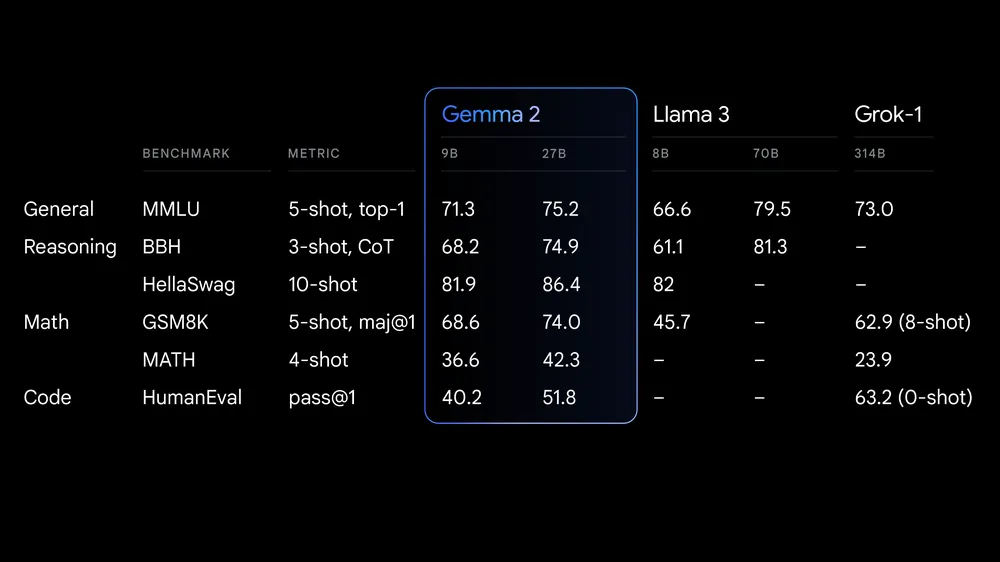
超大性能:在27B,Gemma 2为其尺寸级别提供了最佳性能,甚至为尺寸超过其两倍的型号提供了有竞争力的替代品。9B Gemma 2型号还具有一流的性能,在其尺寸类别中优于Llama 3 8B和其他开放式型号。有关详细的性能明细,请查看技术报告。
-
无与伦比的效率和成本节约:27B Gemma 2型号旨在在单个Google Cloud TPU主机、NVIDIA A100 80GB Tensor Core GPU或NVIDIA H100 Tensor Core GPU上以完全精度高效地运行推理,在保持高性能的同时显著降低成本。这允许更易于访问和预算友好的人工智能部署。
-
跨硬件的快速推理:Gemma 2经过优化,可以在一系列硬件上以令人难以置信的速度运行,从强大的游戏笔记本电脑和高端台式机,到基于云的设置。在Google AI Studio中以最精确的方式尝试Gemma 2,使用CPU上的Gemma.cpp的量化版本解锁本地性能,或通过Hugging Face Transformers在家用电脑上使用NVIDIA RTX或GeForce RTX尝试。
-
开放和可访问:就像原始的Gemma模型一样,Gemma 2在我们商业友好的Gemma许可证下提供,使开发人员和研究人员能够分享和商业化他们的创新。
-
广泛的框架兼容性:由于Gemma 2与Hugging Face Transformers以及JAX、PyTorch和TensorFlow等主要AI框架的兼容性,通过原生Keras 3.0、vLLM、Gemma.cpp、Llama.cpp和Ollama,可以轻松将Gemma 2与您首选的工具和工作流程一起使用。此外,Gemma使用NVIDIA TensorRT-LLM进行了优化,以在NVIDIA加速的基础设施上运行,或作为NVIDIA NIM推理微服务运行,并针对NVIDIA的NeMo进行优化。你今天可以用Keras和Hugging Face进行微调。我们正在积极努力实现额外的参数高效微调选项。
-
轻松部署:从下个月开始,谷歌云客户将能够在Vertex AI上轻松部署和管理Gemma 2。
以下是Gemma安全性的评估
-

-
Gemma 2的详细技术
官方网址:https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf
一、知识蒸馏(knowledge distillation)
知识蒸馏是Gemma 2中一个关键的创新点,特别用于训练2B和9B规模的模型。这种方法与传统的语言模型训练方式有显著不同:
-
传统方法: 传统的语言模型训练通常采用"下一个词预测"任务。模型会尝试根据上下文预测序列中的下一个词,并通过最 小化预测误差来学习。
-
Gemma 2的知识蒸馏方法:
-
使用一个更大的模型作为"教师"模型。在Gemma 2的情况下,他们使用27B参数的模型作为教师。
-
教师模型为每个训练样本生成一个概率分布,表示下一个可能的词。
-
较小的"学生"模型(2B和9B)不是直接预测下一个词,而是学习模仿教师模型生成的概率分布。
-
-
知识蒸馏的优势:
-
提供更丰富的训练信号: 不仅仅是正确答案,还包括教师模型对其他可能答案的评估。
-
允许学生模型学习更细微的语言模式和关系。
-
能够在相同或更少的训练数据上获得更好的性能。
-
-
实施细节:
-
文档提到他们对2B和9B模型使用了超过50倍于理论最优计算量的训练。
-
这意味着他们可以模拟远超可用token数量的训练过程,潜在地提高了模型性能。
-
-
效果:
-
文档中的实验结果显示,使用知识蒸馏训练的模型在多个基准测试中表现优异。
-
例如,在一个实验中,一个通过蒸馏训练的2.6B模型在某些任务上的表现比从头训练的模型提高了7个百分点以上。
-
-
意义: 这种方法表明,我们可以通过更有效的训练方法,而不仅仅是增加模型大小或训练数据量,来提高小型模型的性能。这对于在资源受限环境中部署高性能模型有重要意义。
二、交替使用局部滑动窗口注意力和全局注意力机制
根据PDF中的内容,这项技术在Gemma 2模型中的实现如下:
-
结构设计: Gemma 2模型在每隔一层交替使用局部滑动窗口注意力(local sliding window attention)和全局注意力 (global attention)。
-
局部滑动窗口注意力:
-
这种注意力机制只关注输入序列中的一个局部窗口。
-
在Gemma 2中,局部滑动窗口的大小被设置为4096个token。
-
这种机制允许模型高效地处理长序列,因为它限制了每个token需要计算注意力的范围。
-
-
全局注意力:
-
全局注意力层允许模型考虑整个输入序列。
-
在Gemma 2中,全局注意力的跨度(span)被设置为8192个token。
-
这使得模型能够捕捉到长距离的依赖关系和全局上下文信息。
-
-
交替使用的优势:
-
通过交替使用这两种注意力机制,Gemma 2能够在计算效率和模型表现力之间取得平衡。
-
局部注意力提高了处理长序列的效率,而全局注意力确保模型不会丢失重要的长距离关系。
-
-
灵活性:
-
PDF中提到,在推理阶段可以调整局部滑动窗口的大小,以在性能和速度之间取得平衡。
-
例如,将窗口大小从4096减小到2048或1024对模型的困惑度(perplexity)影响很小,但可能会提高推理速度。
-
-
与其他技术的结合:
-
这种注意力机制的设计与分组查询注意力(GQA)等其他技术结合,进一步提升了模型的性能和效率。
-
这种交替使用局部和全局注意力的方法是基于Beltagy等人(2020a)的工作。它允许Gemma 2模型在处理长文本时保持高效,同时不失去捕捉全局上下文的能力,这对于提高模型在各种任务上的表现至关重要。
三、采用分组查询注意力(Grouped-Query Attention, GQA)
根据PDF中的内容,GQA是Gemma 2模型架构中的一个重要组成部分。具体来说:
-
定义: GQA是由Ainslie等人在2023年提出的一种注意力机制变体。
-
应用: 文档明确指出,27B和9B模型都使用了GQA。
-
实现细节:
-
对于27B模型:使用了32个注意力头,其中16个是KV (Key-Value)头。
-
对于9B模型:使用了16个注意力头,其中8个是KV头。
-
文档中提到 "num_groups = 2",这意味着查询头数量是KV头数量的两倍。
-
-
优势: 文档提到进行了消融实验(ablations),结果表明GQA在保持下游性能的同时,能够显著提高推理速度。
-
与MHA的对比: 在一个9B模型的对比实验中,将多头注意力(MHA)替换为GQA后,在4个基准测试的平均性能上略有提升(从50.3提高到50.8)。
-
选择理由: 尽管性能提升看似微小,但文档指出他们选择GQA是因为它需要的参数更少,并且在推理时更快。
GQA的核心思想是将注意力机制中的查询(Query)、键(Key)和值(Value)进行分组处理,而不是为每个注意力头都维护完整的KV对。这种设计能够减少模型参数量和计算复杂度,特别是在大规模模型中更为明显。
通过采用GQA,Gemma 2团队成功地在保持模型性能的同时,提高了模型的效率,这对于需要在实际应用中部署的开源模型来说是一个重要的优势。
四、使用RMSNorm进行归一化
文档中提到:"To stabilize training, we use RMSNorm (Zhang and Sennrich, 2019) to normalize the input and output of each transformer sub-layer, the attention layer, and the feedforward layer."
RMSNorm(Root Mean Square Layer Normalization)是一种归一化技术,用于稳定深度神经网络的训练。它的主要特点是:
-
用于归一化transformer的每个子层的输入和输出
-
应用于注意力层和前馈层
-
相比传统的Layer Normalization,RMSNorm计算更简单,减少了均值的计算
-
有助于提高训练稳定性和模型性能
在Gemma 2中,RMSNorm被用作"post-norm"和"pre-norm",这意味着它在每个子层的输入和输出都被应用,以确保信号在网络中传播时保持稳定。
五、Logit软上限技术
文档中描述:"Following Gemini 1.5 (Gemini Team, 2024), we cap logits in each attention layer and the final layer such that the value of the logits stays between -soft_cap and +soft_cap."
具体实现如下: "logits = soft_cap * tanh(logits/soft_cap)"
这项技术的主要特点和目的是:
-
应用于每个注意力层和最终输出层
-
对于9B和27B模型,注意力层的logits被限制在±50范围内,最终层的logits被限制在±30范围内
-
使用双曲正切函数(tanh)来实现软上限,而不是硬截断
-
目的是防止logits值变得过大,这可能导致数值不稳定或梯度爆炸
值得注意的是,文档提到这种logit软上限技术目前与一些常见的FlashAttention实现不兼容。在使用FlashAttention的库中(如HuggingFace transformers和vLLM),这个功能被移除了。
研究人员进行了消融实验,发现移除注意力logit软上限对大多数预训练和后训练评估的生成质量影响很小。然而,文档也指出一些下游任务的性能可能会受到轻微影响。

