
- 1MacBook快捷键使用_苹果电脑剪切快捷键
- 2【jdk源码阅读】第三篇:StringBuffer、StringBuilder源码分析
- 3SPA&MPA_mpa和spa
- 4Flink学习笔记(二)_tumblingprocessingtimewindows
- 5Datawhale 2024 年 AI 夏令营第二期学习笔记(1)——电力需求预测挑战赛_停电预测挑战赛
- 6Python 高级实战:基于自然语言处理的情感分析系统_python 情感分析库
- 7最新扣子(Coze)实战案例:手把手教你把扣子(Coze)接入到微信公众号(订阅号)
- 8Java中Spring MVC 框架_javaspringmvc框架
- 9【上海大学数字逻辑实验报告】四、组合电路(三)_74ls151逻辑图及真值表
- 10【Redis】Linux CentOS Redis 的安装—(一)
计算机毕业设计django+vue.js+scrapy租房推荐系统 租房大屏可视化 租房爬虫 hadoop spark 58同城租房爬虫 房源推荐系统
赞
踩
用到的技术:
1. python
2. django后端框架
3. django-simpleui,Django后台
4. vue前端
5. element-plus,vue的前端组件库
6. echarts前端可视化库
7. scrapy爬虫框架
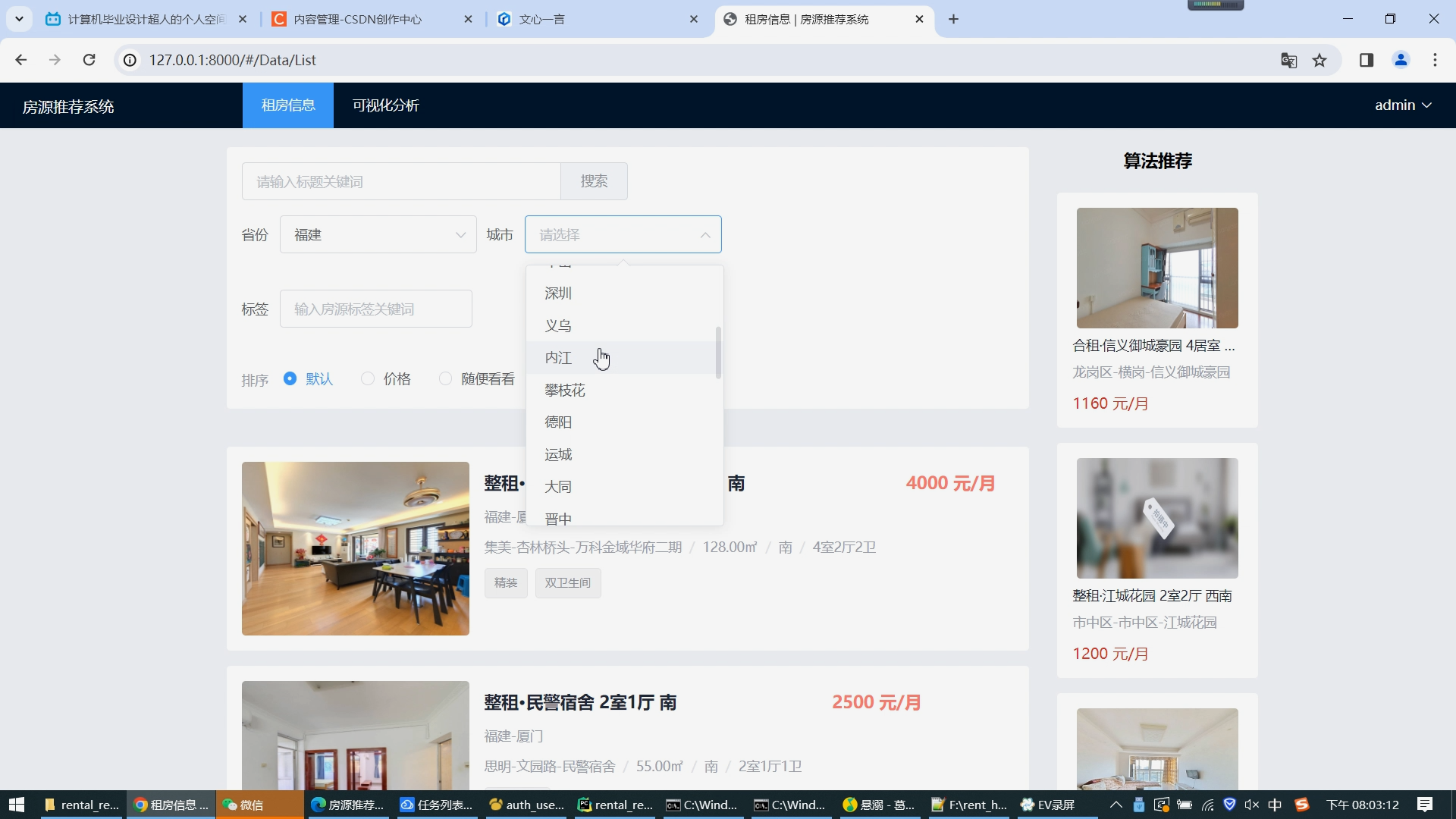
基于大数据的租房信息推荐系统包括以下功能:
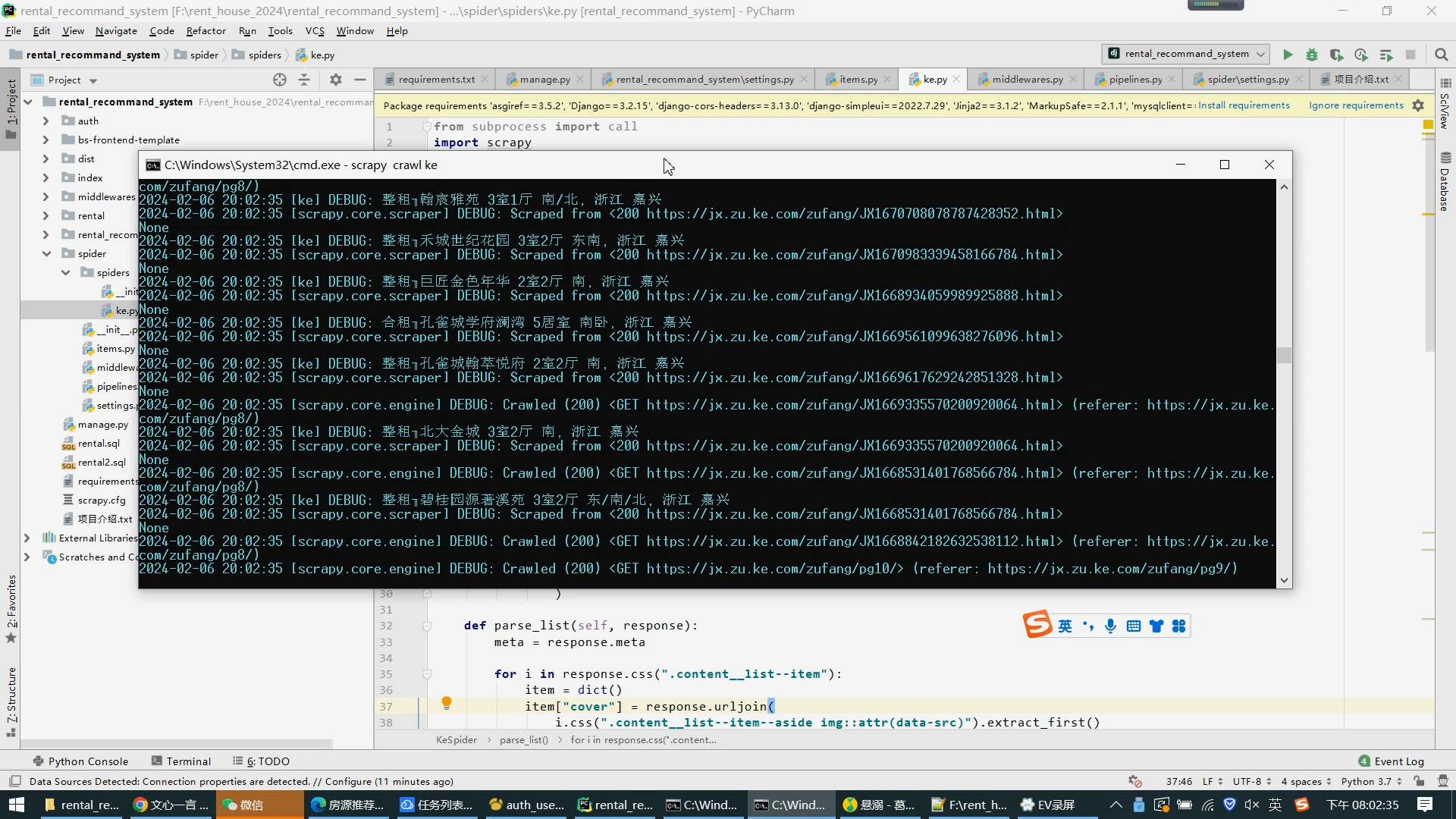
数据爬取和清洗
实现方法:使用Scrapy框架进行数据爬取,通过Python进行数据清洗。首先,定义网页解析器,利用XPath语法获取租房信息的相关数据(如房源价格、房屋类型、朝向、楼层等数据),再使用正则表达式对数据进行清洗。
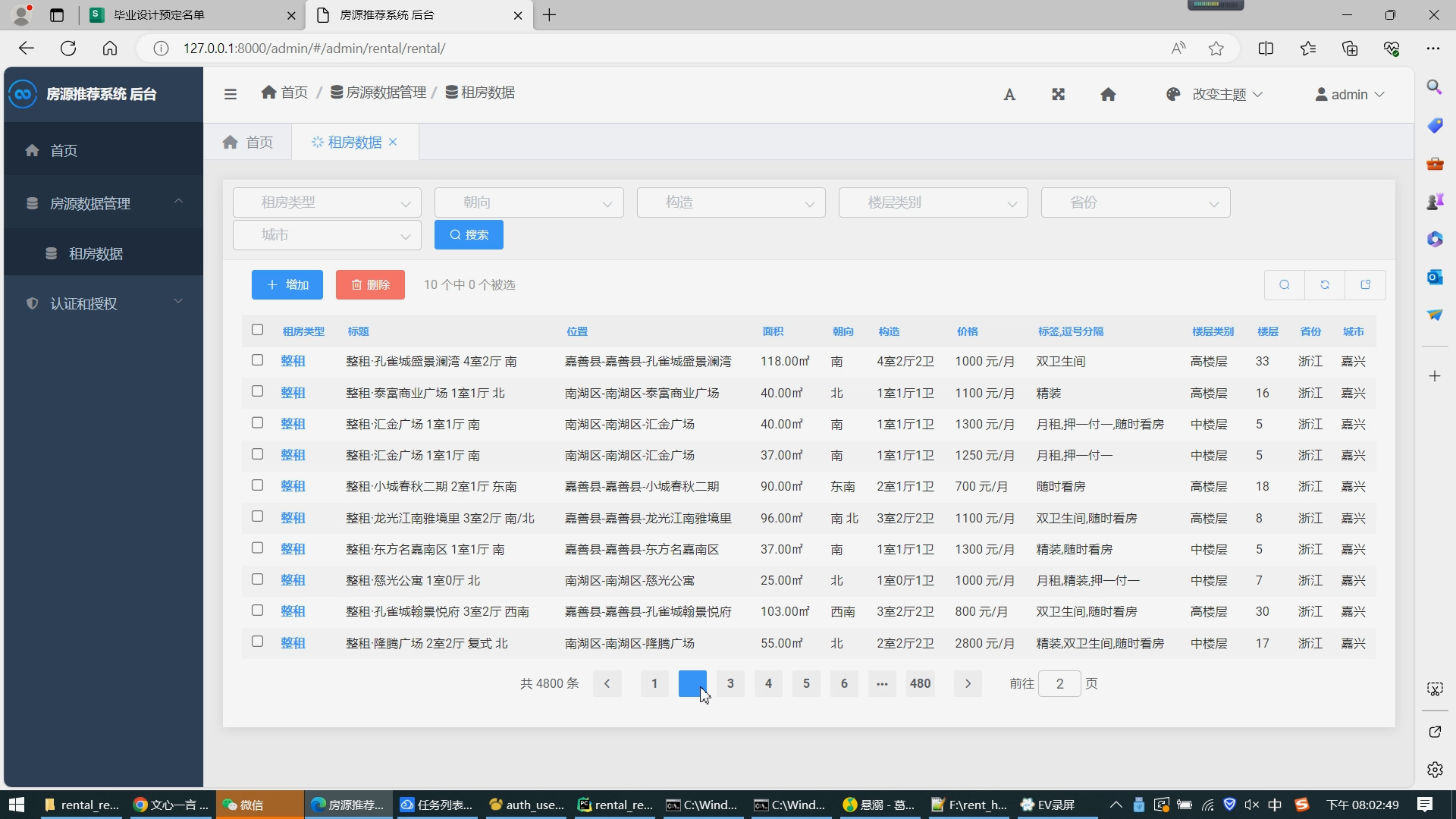
数据库设计与管理
实现方法:使用MySQL数据库存储租房信息数据,设计表结构包括租房信息、用户信息、常用搜索关键词、用户历史搜索记录等,通过Django ORM实现对数据库的数据操作。
推荐算法实现
实现方法:使用基于协同过滤的推荐算法,根据用户过去的租房行为和喜好,从租房信息数据库中寻找类似的房屋信息,然后根据用户的个性化需求和偏好进行推荐。
前后端架构设计与实现
实现方法:使用Vue.js作为前端框架,实现网站界面的交互效果;使用Django作为后端框架,实现网站后台的功能逻辑。采用RESTful API实现前后端数据交互。
可视化展示
实现方法:使用Echarts工具实现数据可视化,并将推荐结果展示在大屏幕上,以便用户能够更直观地了解推荐信息。
统计和分析
实现方法:对租房类型、房屋朝向、楼层类型、房源价格和数量等进行统计和分析,以便为用户提供更全面、准确的租房信息。通过Python的数据分析库(如pandas等)实现数据的处理和分析。
论文可能的摘要:
随着信息化水平的高速发展,租房市场越来越受到人们的青睐。然而,在庞大的租房信息中,如何让用户快速并准确地找到适合自己的房源,成为了当前市场上亟待解决的问题。
本文提出了基于大数据的租房信息推荐系统的实现方案,通过利用 python、django、vue、scrapy、echarts 等技术,搭建一个全面的租房信息平台。
该系统主要分为如下几个模块:信息爬取、数据处理、协同过滤算法、数据可视化以及租房信息推荐等。
在信息爬取方面,本系统采用 scrapy 爬虫框架,对贝壳租房网站进行爬取,获得大量的租房信息。在数据处理方面,本系统通过对爬取的数据进行清洗、去重、筛选等操作,使其更加符合用户需求。
在算法方面,本系统引入协同过滤算法,根据用户在平台上的行为、历史租房记录等因素,为用户推荐有可能满足需求的房源。
在数据可视化方面,本系统利用 echarts 技术,将整合后的数据以图表形式展示在大屏幕上,帮助用户更好地了解市场情况。
通过该租房信息推荐系统的实际应用效果,本文得出结论:该系统能够对租房市场进行有效的数据分析和方便的房源搜索,并且可以根据用户的行为和历史租房记录,向用户推荐更加合适的房源。同时,数据可视化也使得用户更加容易理解市场趋势,更好地做出租房决策。
本文的创新点在于:将 scrapy 与协同过滤算法有机结合,并采用数据可视化的方式展示数据,从而使用户更加直观地了解市场情况。本文还指出了一些改进方向:针对租房市场的特点,可以探索一些更加精准的算法;同时,可以将推荐算法与用户购房意愿、财务状况等个人因素进行结合,提高推荐准确度。
综上所述,本文提出的基于大数据的租房信息推荐系统为租房市场的进一步发展提供了有益的参考。
以下是基于大数据的租房信息推荐系统的论文目录框架:
绪论
1.1 研究背景和意义
1.2 国内外研究现状与进展
1.3 研究内容和目的
1.4 研究方法和技术路线
相关技术介绍
2.1 大数据技术概述
2.2 数据爬取和清洗技术
2.3 协同过滤算法
2.4 可视化技术及工具
系统设计与实现
3.1 系统需求分析与功能模块设计
3.2 数据库设计与管理
3.3 前后端架构设计与实现
3.4 推荐算法实现
系统测试与评估
4.1 测试环境与测试数据
4.2 系统功能测试
4.3 推荐结果评估
结果与分析
5.1 系统实现效果分析
5.2 推荐算法性能对比分析
5.3 用户满意度分析
总结与展望
6.1 主要工作总结
6.2 存在问题与改进方向
6.3 未来发展展望
参考文献
附录
目录介绍:
├── auth
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ ├── models.py
│ ├── tests.py
│ ├── urls.py 登陆注册相关的路由配置
│ └── views.py 登陆注册相关的代码
├── bs-frontend-template
│ ├── LICENSE
│ ├── encrypt.js
│ ├── index.html
│ ├── jest.config.js
│ ├── mock
│ ├── package-lock.json
│ ├── package.json
│ ├── public
│ ├── src 前端源代码目录,其中views目录是前端每个页面的主要代码
│ ├── tailwind.config.js
│ ├── test
│ ├── tsconfig.json
│ └── vite.config.ts
├── dist
│ ├── assets
│ └── index.html
├── index
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ ├── models.py
│ ├── tests.py
│ ├── urls.py 路由配置
│ ├── utils.py
│ └── views.py 挂起前端页面的代码
├── manage.py 入口文件
├── middlewares
│ └── __init__.py
│ ├── __init__.py
├── rental 最主要的代码目录在此
│ ├── admin.py 租房后台管理配置
│ ├── apps.py
│ ├── migrations
│ ├── models.py 租房数据库模型
│ ├── tests.py
│ ├── urls.py 租房相关路由配置
│ └── views.py 租房相关所有的接口代码都在这,非常重要的一个文件
├── rental.sql 租房原始数据
├── rental_recommand_system 后端总配置目录
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py 路由总配置
│ └── wsgi.py
├── requirements.txt python依赖库文件
├── scrapy.cfg
├── spider 贝壳租房爬虫代码
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py 数据入库代码
│ ├── settings.py
│ └── spiders 爬虫文件所在
└── 项目介绍.txt

核心算法代码分享如下:
- # -*- coding: utf-8 -*-
-
-
-
- import random
- import time
- from datetime import datetime, timedelta
- from hashlib import md5
-
- from scrapy import signals, Item, Request
- from scrapy.utils.url import urlparse
-
-
- class IPPoolDownloaderMiddleWare(object):
- """
- 代理池中间件
- 必须配合HttpProxyMiddleWare使用, 并且要在其之前
- """
-
- def __init__(self, host, port, order_no, secret, domains=[]):
- self.host = host
- self.port = port
- self.host_port = '%s:%s' % (host, port)
- self.order_no = order_no
- self.secret = secret
- # 需要做ip池代理的域名
- self.ip_pool_domains = domains
-
- @classmethod
- def from_crawler(cls, crawler):
- # ip池URL
- host = crawler.settings.get('IP_POOL_HOST')
- port = crawler.settings.get('IP_POOL_PORT')
- order_no = crawler.settings.get('IP_POOL_ORDER_NO')
- secret = crawler.settings.get('IP_POOL_SECRET')
- domains = crawler.settings.get('IP_POOL_DOMAINS', [])[0:]
- cls.enable_ip_proxy_to_all_spider = crawler.settings.get(
- 'ENABLE_IP_PROXY_TO_ALL_SPIDER', False)
- return cls(host=host, port=port, order_no=order_no, secret=secret, domains=domains)
-
- def process_request(self, request, spider):
- if not request.meta.get('noproxy', False):
- self._set_ip_pool(request)
-
- def _set_ip_pool(self, request):
- """
- 配置ip池代理
- :param request:
- :return:
- """
- url = self._get_real_url(request)
- scheme = urlparse(url).scheme
- proxy_url = '%s://%s' % (scheme, self.host_port)
-
- if 'splash' in request.meta:
- splash_args = request.meta['splash']['args']
- splash_args['proxy'] = 'http://%s' % self.host_port
- splash_args['proxy_info'] = dict(
- host=self.host, port=self.port, scheme=scheme)
- # 这里需要清除 proxy meta(该meta有可能来源于上层请求), 否则访问splash的请求也会走代理, 然而我们希望的是splash通过代理访问目标地址
- if 'proxy' in request.meta:
- del request.meta['proxy']
- else:
- request.meta['proxy'] = proxy_url
-
- timestamp = int(time.time())
- sign_text = 'orderno=%(order_no)s,secret=%(secret)s,timestamp=%(timestamp)s' % dict(order_no=self.order_no,
- secret=self.secret,
- timestamp=timestamp)
- sign = md5(sign_text.encode('utf-8')).hexdigest().upper()
- auth = 'sign=%(sign)s&orderno=%(order_no)s×tamp=%(timestamp)s' % dict(sign=sign, order_no=self.order_no,
- timestamp=timestamp)
- request.headers['Proxy-Authorization'] = auth
-
- def _get_real_url(self, request):
- """
- 获取实际要请求的url(与splash兼容)
- :param request:
- :return:
- """
- meta = request.meta or {}
- is_splash = 'splash' in meta
- return meta.get('splash').get('args').get('url') if is_splash else request.url


