
- 1数据结构-排序专题(选择、插入、希尔、冒泡、堆、快速、归并、计数)_数据结构要求在一个程序中实现四种排序算法直接插入希尔冒泡快速
- 2pip版本升级后出现错误_pip有点高
- 3Python常见报错信息_#错误1 -str1 = "string" print(-str1) #错误2 1024 = 102
- 4【数据结构】关于Java对象比较,以及优先级队列的大小堆创建你了解多少???
- 5C#与其它编程语言有什么区别,以及相关优势有哪些_c#语言怎么样
- 6Datawhale出品:《GLM-4 大模型部署微调教程》发布!_glm-4微调
- 7ARM寻址方式_arm处理器的寻址方式有哪些?分别做简要介绍
- 8unity Google 广告接入 SDK Android_unity 对接google广告
- 9ABAP 程序间传递数据
- 102024亚太杯数学建模B题一二三问代码+完整解题思路+成品论文更新_亚太杯数学建模竞赛b题
mysql 分表 和 数据冗余_mysql的表结构设计用空间换时间的概念和多表数据冗余哪个好
赞
踩
文献表中有200W条数据
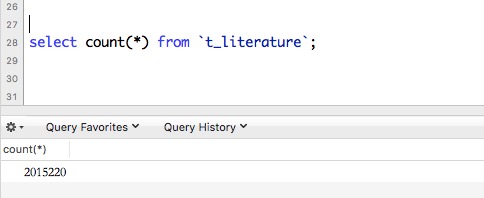
数据量比较大,字段在20个左右,其中有一些字段用到的频率会很低,也就是所谓的冷数据,从而考虑到分表的操作,将表进行垂直分割(下面的第一种表分割方式),将使用少的字段拆分到另外的表中。
1.保存数据的时候先将第一张表中的数据保存,然后获取主键保存另外一张表中的数据
2.并发高的时候会减少数据库压力,避免扫描不必要的数据
当一张的数据达到几百万时,你查询一次所花的时间会变多,分表的目的就在于此,减小数据库单表的负担,缩短查询时间。
1、拆分表的方式(主要有分表和分区)
1、分表
1.1、垂直分割
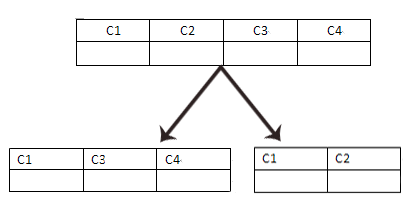
优势:降低高并发情况下,对于表的锁定。感觉有点像读写分离了。
1.2、水平分割
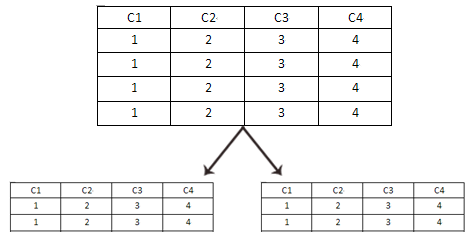
如果单表的IO压力大,可以考虑用水平分割,其原理就是通过hash算法,将一张表分为N多页,并通过一个新的表(总表),记录着每个页的的位置。假如一个门户网站,它的数据库表已经达到了1000万条记录,那么此时如果通过select去查询,必定会效率低下(不做索引的前提下)。为了降低单表的读写IO压力,通过水平分割,将这个表分成10个页,同时生成一个总表,记录各个页的信息,那么假如我查询一条id=100的记录,它不再需要全表扫描,而是通过总表找到该记录在哪个对应的页上,然后再去相应的页做检索,这样就降低了IO压力。
水平分表技术就是将一个表拆成多个表,比较常见的方式就是将表中的记录按照某种HASH算法进行拆分,同时,这种分区方法也必须对前端的应用程序中的SQL进行修改方能使用,而且对于一个SQL语句,可能会修改两个表,那么你必须要修改两个SQL语句来完成你这个逻辑的事务,会使得逻辑判断越来越复杂,这样会增加程序的维护代价,所以我们要避免这样的情况出现。
2.数据冗余
有两张表
文献和分类关系表:t_literature_category_relation(700w条数据) 文献和分类是n对n关系
文献表:t_literature(200w条)
业务场景:根据分类查询文献,并按照文献的发布时间排序
刚开始的做法是:先根据分类id查询出所有的文献id,然后查文献表根据文献发布时间排序
sql如下:
sql1:select literature_id from t_literature_category_relation where category_id = <分类id>;
sql2:select fields from t_literature where id in (sql1返回的文献id集合) order by publish_time limit rowStart,20;
第一条sql查出的id大约有10w左右,因为数据量大,加了索引花费的时间也要500ms,就已经不能满足响应时间小于0.5s的要求,sql2花费的时间更多,大概在2~3秒左右,响应时间就很长,用户体验会很差。
改进方案:
将文献表中的publish_time冗余到t_literature_category_relation中,在publish_time加索引
sql如下:
sql1:select literature_id from t_literature_category_relation where category_id=分类id order by publish_time limit rowStart,20;
sql2:select fields from t_literature where id in(sql1返回的20个文献id集合);
目前的时间都在100ms以内。

