
- 1oVirt虚拟化部署_ovirt部署云桌面
- 2平凉市全国计算计算机,甘肃省平凉市2018年3月计算机等级考试公告
- 3透视数字人克隆直播系统:科技革新下的全新互动体验
- 4OSPF协议原理简析
- 5linux tar 7z,.tar.gz和.gz或.tar.7z和.7z有什么区别?
- 6Spark 【RDD基础编程(一)RDD的创建、转换操作】_rdd的创建 -java 第1关:集合并行化创建rdd
- 72024年最全git 安装、创建仓库、常用命令、克隆下载、上传项目(1),大厂大数据开发核心面试题出炉_快速安装git
- 8neo4j 图数据库使用教程_neo4j查看数据库
- 9Android Studio 报错:Failed to create Jar file xxxxx.jar
- 10HarmonyOS APP 开发入门_鸿蒙仓颉编程语言入门,HarmonyOS鸿蒙 面试_仓颉编程入门
Hive基本SQL操作(图文并茂)_hive sql
赞
踩
Hive基本SQL操作
1、Hive DDL(数据库定义语言)
1.1、数据库的基本操作
--展示所有数据库 show databases; --切换数据库 use database_name; /*创建数据库 CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value, ...)]; */ create database test; /* 删除数据库 DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE]; */ drop database database_name;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
注意:当进入hive的命令行开始编写SQL语句的时候,如果没有任何相关的数据库操作,那么默认情况下,所有的表存在于default数据库,在hdfs上的展示形式是将此数据库的表保存在hive的默认路径下,如果创建了数据库,那么会在hive的默认路径下生成一个database_name.db的文件夹,此数据库的所有表会保存在database_name.db的目录下。
1.2、数据库表的基本操作
/* 创建表的操作 基本语法: CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later) [(col_name data_type [COMMENT col_comment], ... [constraint_specification])] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)] ON ((col_value, col_value, ...), (col_value, col_value, ...), ...) [STORED AS DIRECTORIES] [ [ROW FORMAT row_format] [STORED AS file_format] | STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later) ] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later) [AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables) CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name LIKE existing_table_or_view_name [LOCATION hdfs_path]; 复杂数据类型 data_type : primitive_type | array_type | map_type | struct_type | union_type -- (Note: Available in Hive 0.7.0 and later) 基本数据类型 primitive_type : TINYINT | SMALLINT | INT | BIGINT | BOOLEAN | FLOAT | DOUBLE | DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later) | STRING | BINARY -- (Note: Available in Hive 0.8.0 and later) | TIMESTAMP -- (Note: Available in Hive 0.8.0 and later) | DECIMAL -- (Note: Available in Hive 0.11.0 and later) | DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later) | DATE -- (Note: Available in Hive 0.12.0 and later) | VARCHAR -- (Note: Available in Hive 0.12.0 and later) | CHAR -- (Note: Available in Hive 0.13.0 and later) array_type : ARRAY < data_type > map_type : MAP < primitive_type, data_type > struct_type : STRUCT < col_name : data_type [COMMENT col_comment], ...> union_type : UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later) 行格式规范 row_format : DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later) | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)] 文件基本类型 file_format: : SEQUENCEFILE | TEXTFILE -- (Default, depending on hive.default.fileformat configuration) | RCFILE -- (Note: Available in Hive 0.6.0 and later) | ORC -- (Note: Available in Hive 0.11.0 and later) | PARQUET -- (Note: Available in Hive 0.13.0 and later) | AVRO -- (Note: Available in Hive 0.14.0 and later) | JSONFILE -- (Note: Available in Hive 4.0.0 and later) | INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname 表约束 constraint_specification: : [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE ] [, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
1.2.1、创建普通hive表(不包含行定义格式)
create table psn
(
id int,
name string,
likes array<string>,
address map<string,string>
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
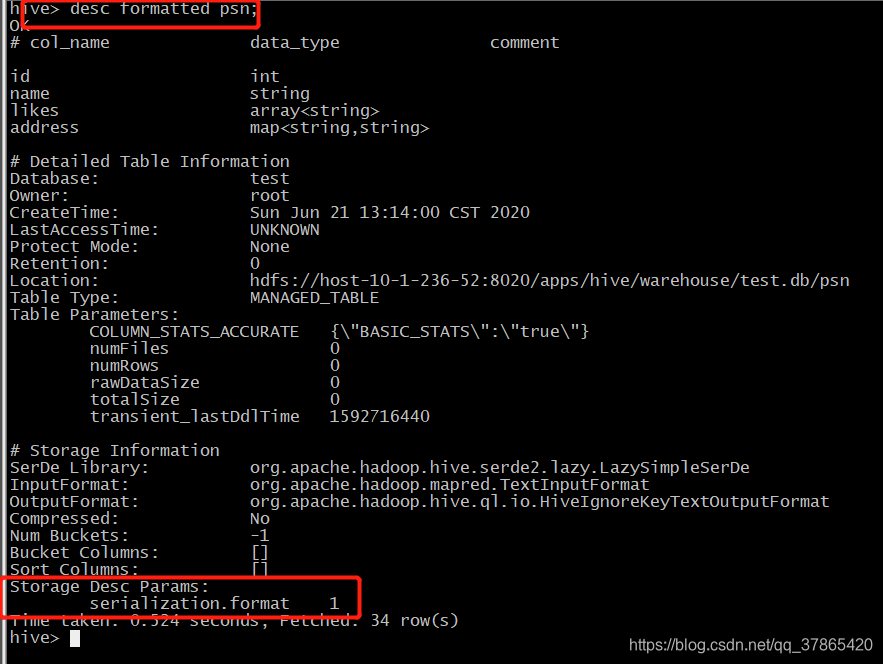
1.2.2、创建自定义行格式的hive表
create table psn2
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
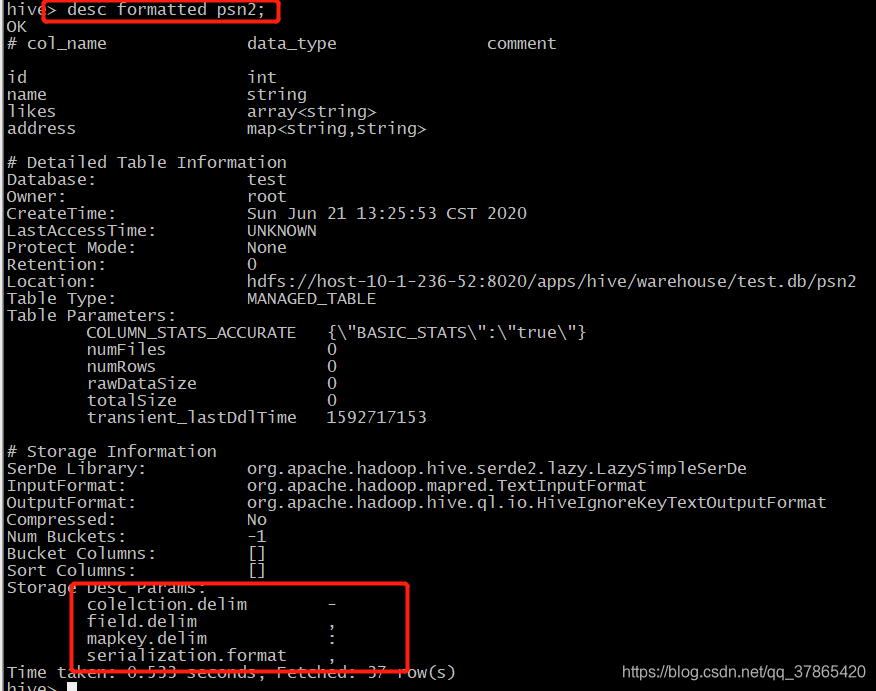
1.2.3、创建默认分隔符的hive表( ^A、 ^B、 ^C)
create table psn3
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by '\001'
collection items terminated by '\002'
map keys terminated by '\003';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
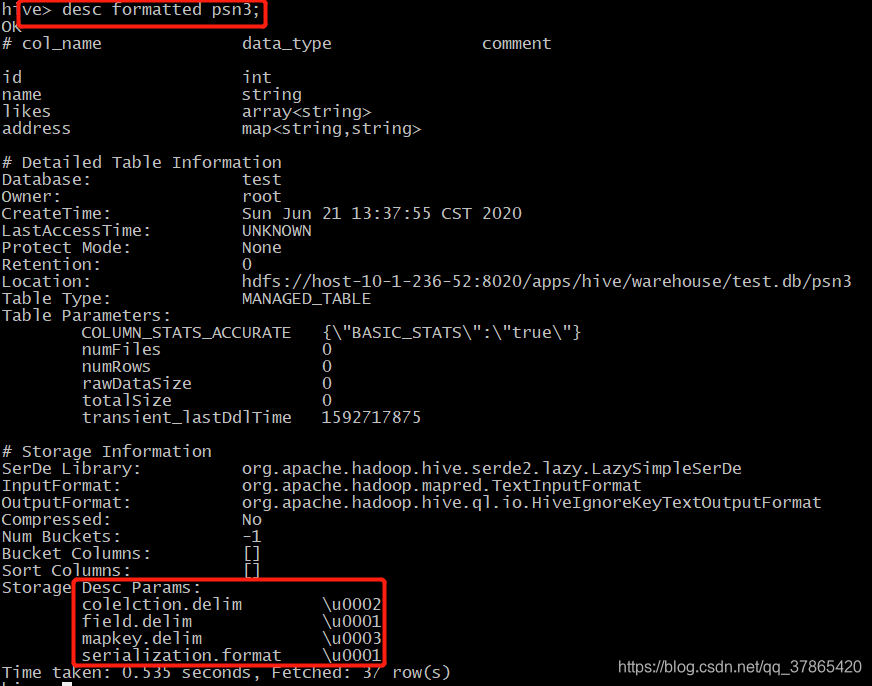
1.2.4、创建hive的外部表(需要添加external和location的关键字)
在之前创建的表都属于hive的内部表(psn,psn2,psn3),而psn4属于hive的外部表
create external table psn4
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/data';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

1.2.5、内部表跟外部表的区别:
1、hive内部表创建的时候数据存储在hive的默认存储目录中,外部表在创建的时候需要指定额外的目录
2、hive内部表删除的时候,会将元数据和数据都删除,而外部表只会删除元数据,不会删除数据
1.2.6、内外部表应用场景
| 类型 | 适用场景 |
|---|---|
| 内部表 | 需要先创建表,然后向表中添加数据,适合做中间表的存储 |
| 外部表 | 可以先创建表,再添加数据,也可以先有数据,再创建表。 本质上是将hdfs的某一个目录的数据跟hive的表关联映射起来, 因此适合原始数据的存储,不会因为误操作将数据给删除掉 |
1.2.7、创建单分区表
hive的分区表:
hive默认将表的数据保存在某一个hdfs的存储目录下,当需要检索符合条件的某一部分数据的时候,需要全量遍历数据,io量比较大,效率比较低。
因此可以采用分而治之的思想,将符合某些条件的数据放置在某一个目录,此时检索的时候只需要搜索指定目录即可,不需要全量遍历数据。
create table psn5
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(gender string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
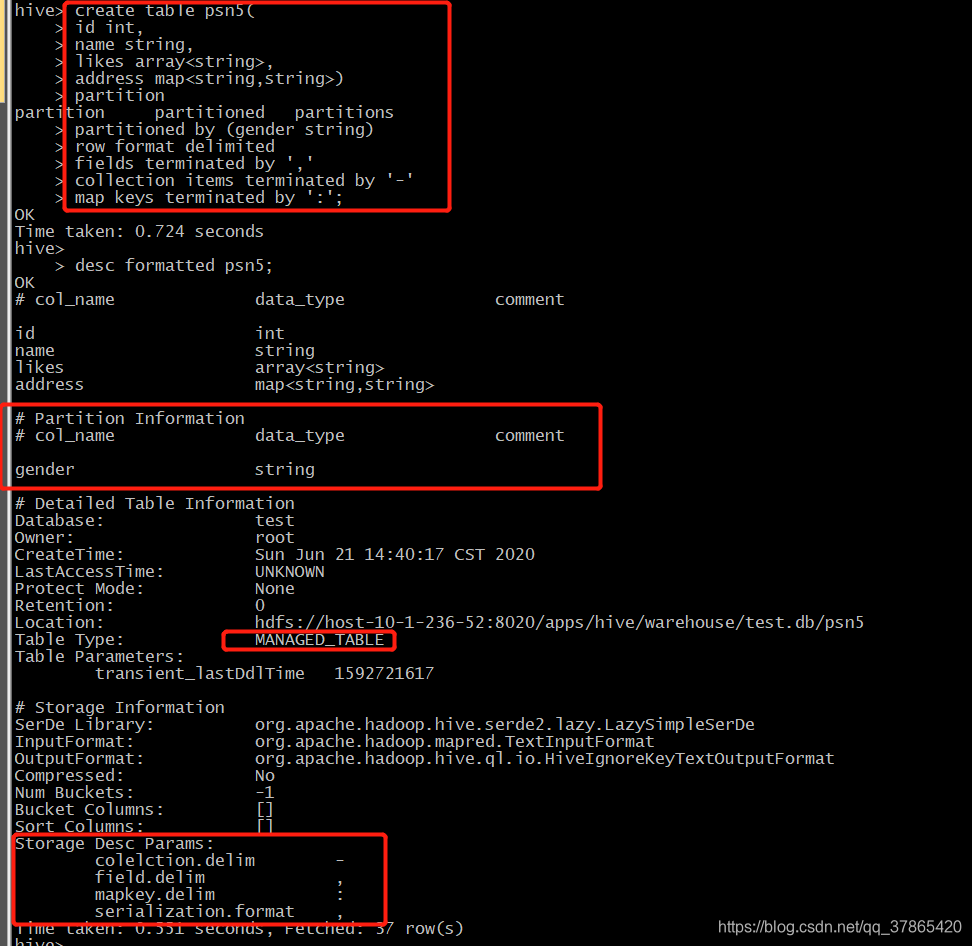
1.2.8、创建多分区表
create table psn6
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(gender string,age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
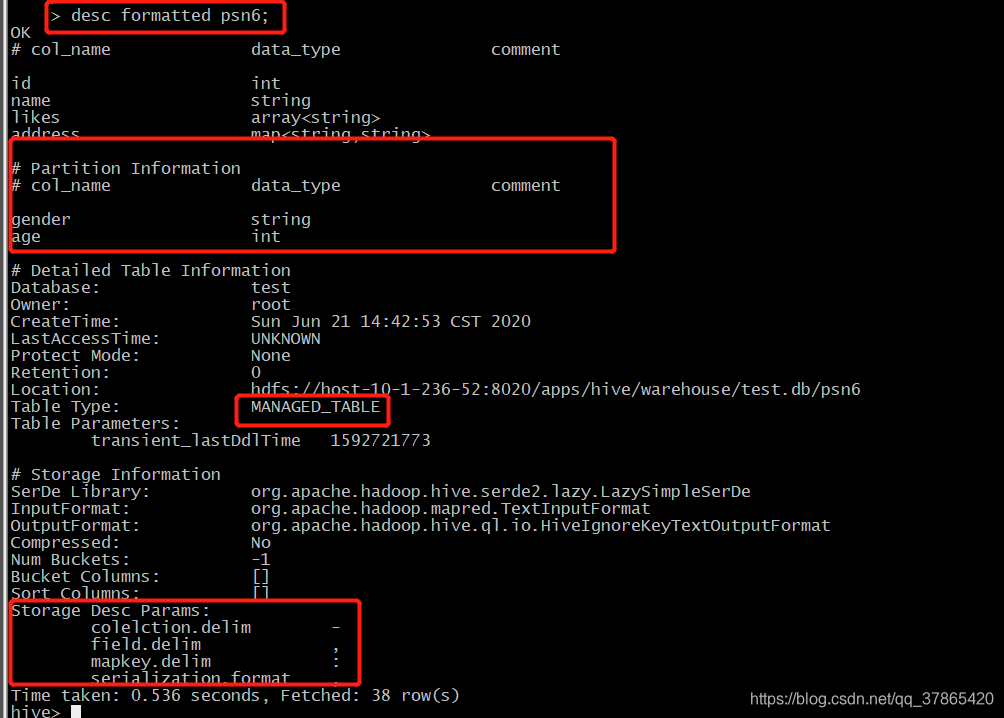
注意:
- 当创建完分区表之后,在保存数据的时候,会在hdfs目录中看到分区列会成为一个目录,以多级目录的形式 存在
- 当创建多分区表之后,插入数据的时候不可以只添加一个分区列,需要将所有的分区列都添加值
- 多分区表在添加分区列的值得时候,与顺序无关,与分区表的分区列的名称相关,按照名称就行匹配
1.2.9、给分区表添加分区列的值
alter table table_name add partition(col_name=col_value)
- 1


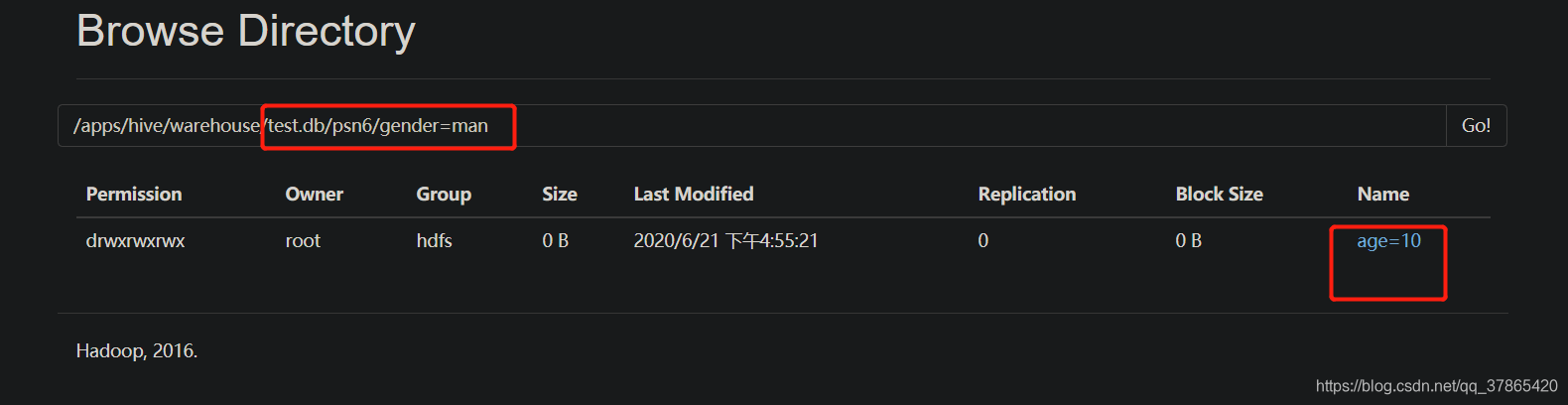

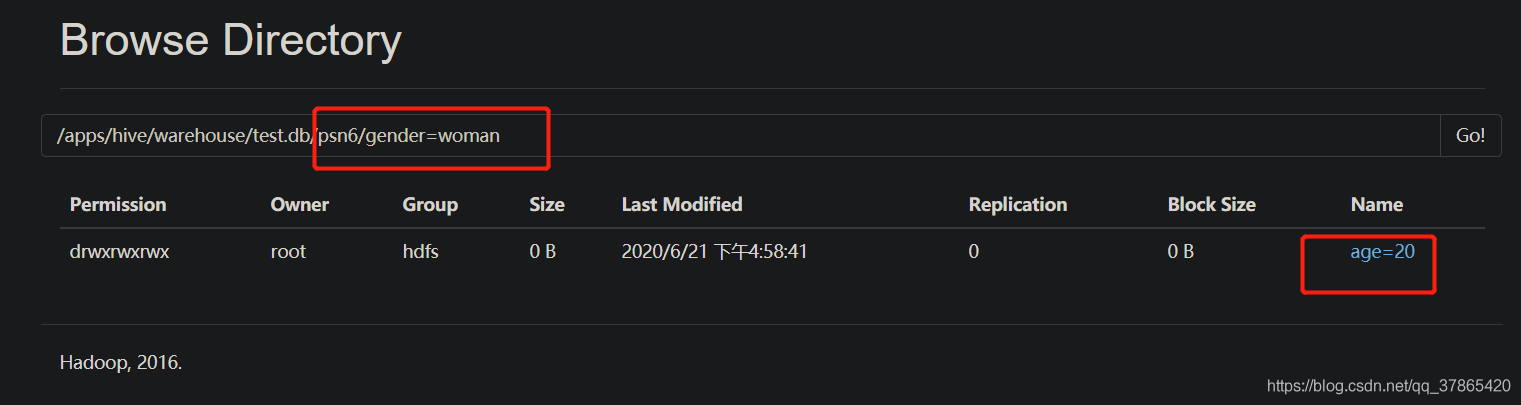
1.2.10、删除分区列的值
alter table table_name drop partition(col_name=col_value)
- 1

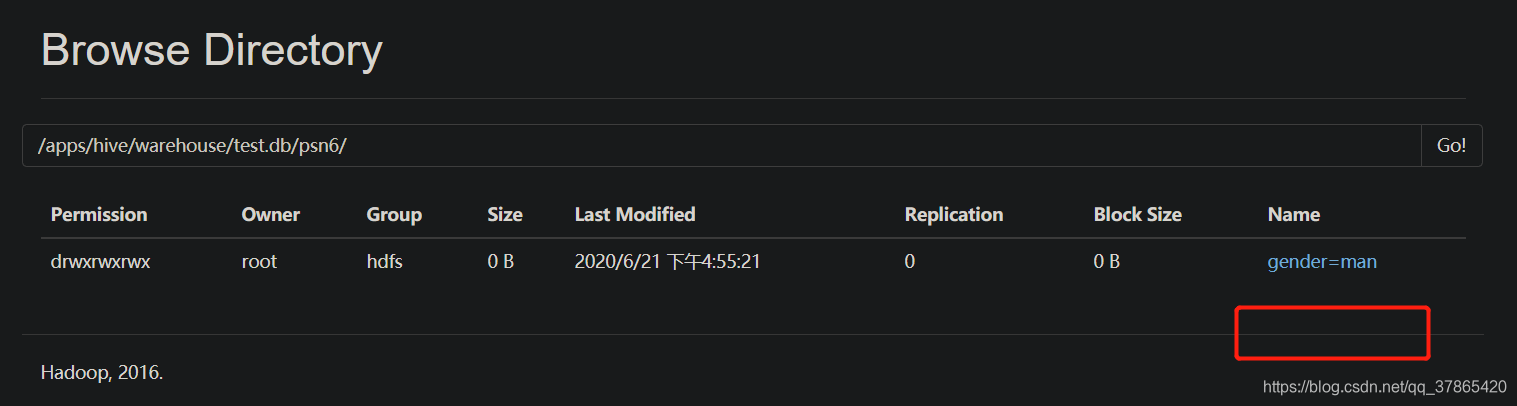
注意:
- 添加分区列的值的时候,如果定义的是多分区表,那么必须给所有的分区列都赋值

- 删除分区列的值的时候,无论是单分区表还是多分区表,都可以将指定的分区进行删除
1.2.11、修复分区:
在使用hive外部表的时候,可以先将数据上传到hdfs的某一个目录中,然后再创建外部表建立映射关系,如果在上传数据的时候,参考分区表的形式也创建了多级目录,那么此时创建完表之后,是查询不到数据的,原因是分区的元数据没有保存在mysql中,因此需要修复分区,将元数据同步更新到mysql中,此时才可以查询到元数据。具体操作如下:
- 在hdfs创建目录并上传文件
hdfs dfs -mkdir /test
hdfs dfs -mkdir /test/age=10
hdfs dfs -mkdir /test/age=20
hdfs dfs -put /root/data/data /test/age=10
hdfs dfs -put /root/data/data /test/age=20
- 1
- 2
- 3
- 4
- 5
- 创建外部表
create external table psn7
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/test';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 查询结果(没有数据)
select * from psn7;
- 1
- 修复分区
msck repair table psn7;
- 1
- 查询结果(有数据)
select * from psn7;
- 1
问题
以上面的方式创建hive的分区表会存在问题,每次插入的数据都是人为指定分区列的值,我们更加希望能够根据记录中的某一个字段来判断将数据插入到哪一个分区目录下,此时利用我们上面的分区方式是无法完成操作的,需要使用动态分区来完成相关操作,后续讲解。
2、Hive DML
2.1、插入数据
2.1.1、Loading files into tables
记载数据文件到某一张表中
语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)]
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)
- 1
- 2
- 3
- 4
- 5
-
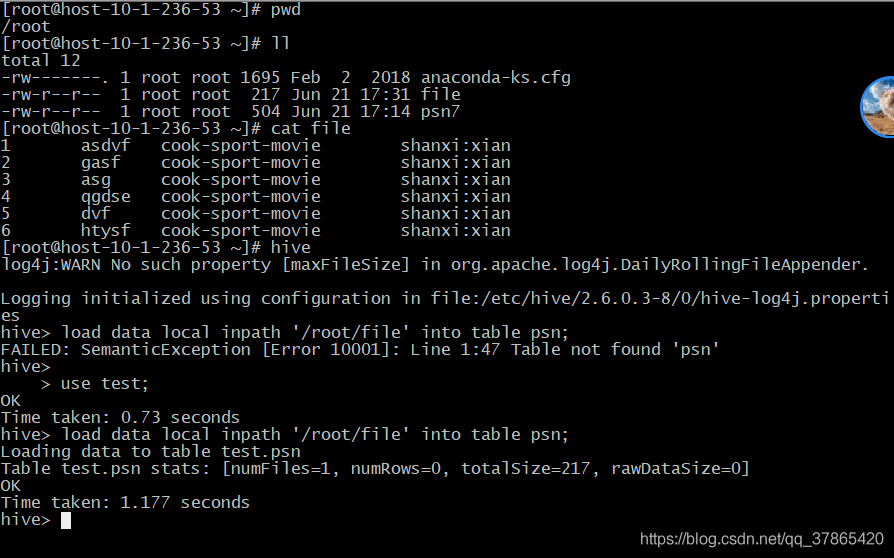
加载本地数据到hive表
load data local inpath '/root/data/data' into table psn;
(/root/data/data指的是本地linux目录)
-
加载hdfs数据文件到hive表
load data inpath '/data/data' into table psn2;
(/data/data指的是hdfs的目录)注意:
1、load操作不会对数据做任何的转换修改操作
2、从本地linux load数据文件是复制文件的过程
3、从hdfs load数据文件是移动文件的过程
4、load操作也支持向分区表中load数据,只不过需要添加分区列的值
5、对于数据格式,hive是读时检查,mysql是写时检查
2.1.1、Inserting data into Hive Tables from queries
从查询语句中获取数据插入某张表
语法:
Standard syntax: INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement; INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement; Hive extension (multiple inserts): FROM from_statement INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 [INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2] [INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2] ...; FROM from_statement INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 [INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2] [INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2] ...; Hive extension (dynamic partition inserts): INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement; INSERT INTO TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 从表中查询数据插入结果表,如下
INSERT OVERWRITE TABLE psn9 SELECT id,name FROM psn
- 1
- 从表中获取部分列插入到新表中,如下
from psn
insert overwrite table psn9
select id,name
insert into table psn10
select id
- 1
- 2
- 3
- 4
- 5
注意:这种方式插入数据的时候需要预先创建好结果表
2.1.1、Writing data into the filesystem from queries
将查询到的结果插入到文件系统中
语法:
Standard syntax:
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0)
SELECT ... FROM ...
Hive extension (multiple inserts):
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] (Note: Only available starting with Hive 0.13)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 将查询到的结果导入到hdfs文件系统中
insert overwrite directory '/result' select * from psn;
- 1
- 将查询的结果导入到本地文件系统中
insert overwrite local directory '/result' select * from psn;
- 1
注意:路径千万不要填写根目录,会把所有的数据文件都覆盖
2.1.1、Inserting values into tables from SQL
这种方式使用传统关系型数据库的方式插入数据,效率较低
语法:
Standard Syntax:
INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...]
Where values_row is:
( value [, value ...] )
where a value is either null or any valid SQL literal
- 1
- 2
- 3
- 4
- 5
- 6
- 插入数据
insert into psn values(1,'zhangsan');
- 1
2.2、数据更新和删除


在官网中我们明确看到hive中是支持Update和Delete操作的,但是实际上,是需要事务的支持的,Hive对于事务的支持有很多的限制,如下图所示:

因此,在使用hive的过程中,我们一般不会产生删除和更新的操作,如果你需要测试的话,参考下面如下配置:
//在hive的hive-site.xml中添加如下配置: <property> <name>hive.support.concurrency</name> <value>true</value> </property> <property> <name>hive.enforce.bucketing</name> <value>true</value> </property> <property> <name>hive.exec.dynamic.partition.mode</name> <value>nonstrict</value> </property> <property> <name>hive.txn.manager</name> <value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value> </property> <property> <name>hive.compactor.initiator.on</name> <value>true</value> </property> <property> <name>hive.compactor.worker.threads</name> <value>1</value> </property> //操作语句 create table test_trancaction (user_id Int,name String) clustered by (user_id) into 3 buckets stored as orc TBLPROPERTIES ('transactional'='true'); create table test_insert_test(id int,name string) row format delimited fields TERMINATED BY ','; insert into test_trancaction select * from test_insert_test; update test_trancaction set name='jerrick_up' where id=1; //数据文件 1,jerrick 2,tom 3,jerry 4,lily 5,hanmei 6,limlei 7,lucky
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38

