
- 1【proverif】proverif的语法-各种密码原语的介绍和具体编码
- 2Zabbix 7.0 + TimescaleDB时序数据库安装教程_zabbix使用时序数据库
- 3微信小程序路由跳转,API调用,页面传值_微信小程序跳转页面api
- 4机器学习之Transformer模型和大型语言模型(LLMs)
- 5linux 安装Flink_飞连linux
- 6【猫头虎科技角】解决Mysqlcom.mysql.cj.jdbc.exceptions.CommunicationsException: Communications link failure异常详解_com.mysql.cj.jdbc.exception communication link fau
- 7obs学习-windows10上源码编译和安装_obs编译
- 8CSDN搜索小技巧-快速找到最新&高质量内容_如何在csdn找到高质量帖子
- 9sql语句查询出重复的数据_sql跑出一户四条数据
- 10洞察科技,感知未来:人工智能将如何改变学术搜索?
大型语言模型(LLM)简介:基础知识、工作原理和示例_llm大型语言模型_llm语法制
赞
踩
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

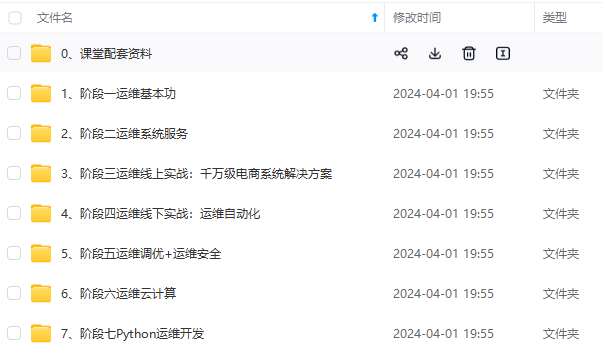
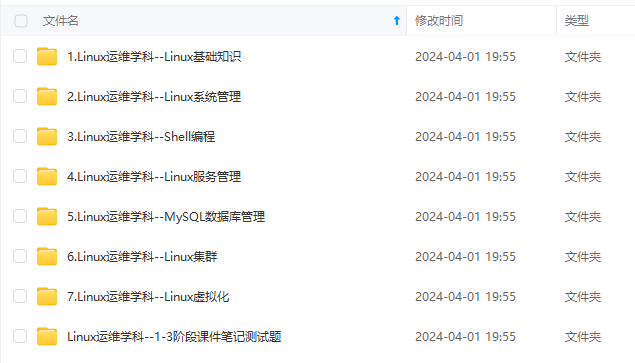
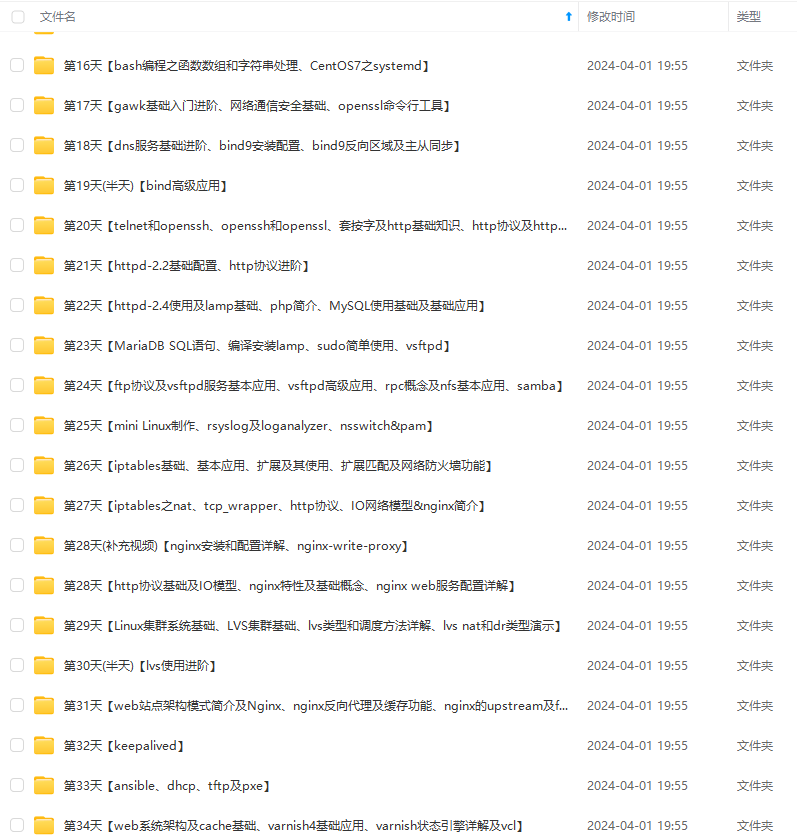
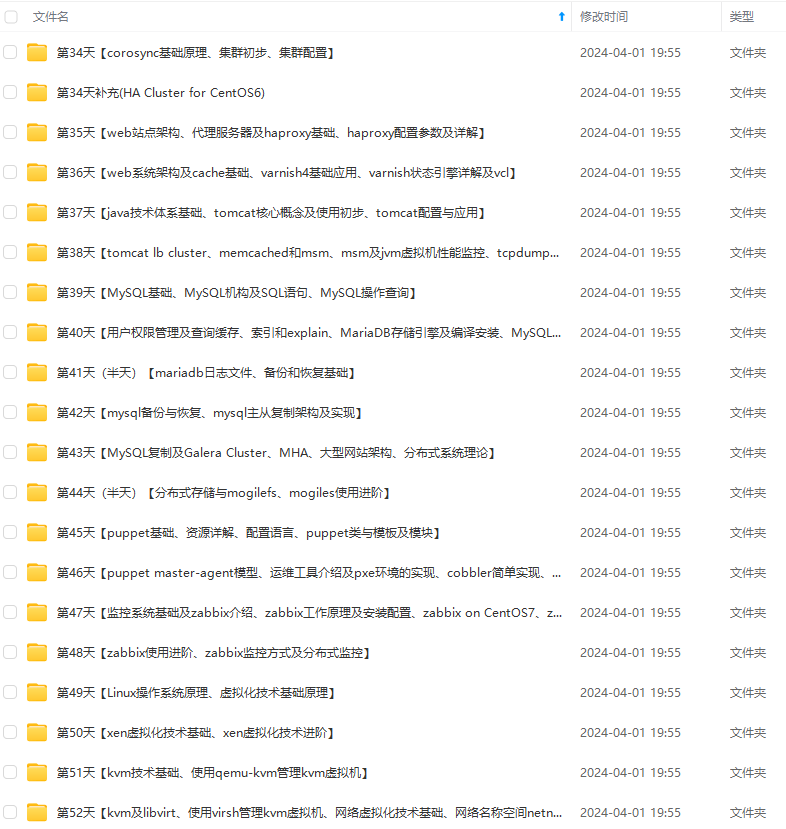
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
对于大型语言模型,用于训练的数据通常是大型文本语料库。该模型学习文本数据中的模式,并使用它们来生成新文本。训练过程包括优化模型参数,以最小化语料库中生成的文本与实际文本之间的差异。
训练模型后,可以使用它来生成新文本。为此,模型被赋予一个单词的起始序列,并根据训练语料库中单词的概率生成序列中的下一个单词。重复此过程,直到生成所需的文本长度。
为了了解大型语言模型的工作原理,了解可用的不同类型的语言模型非常重要。最常见的语言模型类型是递归神经网络 (RNN)、卷积神经网络 (CNN) 和长短期记忆 (LSTM) 网络。这些模型通常用于在大型数据集(如宾夕法尼亚树库)上进行训练,并可用于生成基于语言的数据集。
训练语言模型后,它可用于在各种任务中生成文本,例如文本理解、文本生成、问答等。通过了解语言的一般特征,这些模型能够生成基于语言的数据集,这些数据集可用于为各种 NLP 应用程序提供支持。
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

