




一,数据存储介绍
1.操作系统获得存储空间的方式一般分为:
(1) DAS:(Direct Attached Storage— 直接连接存储)
(2) NAS:(Network attched storage 网附加存储)
(3) SAN:(Storage Area Networ, 存储区域网络 )
2.DAS,SAN,NAS 三种服务器存储方式应用
1.应用:
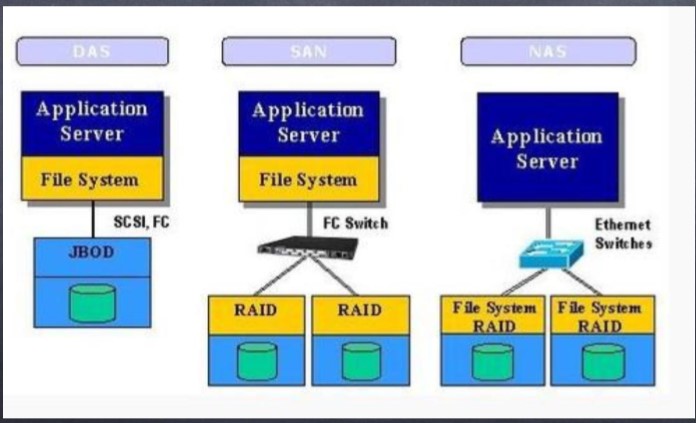
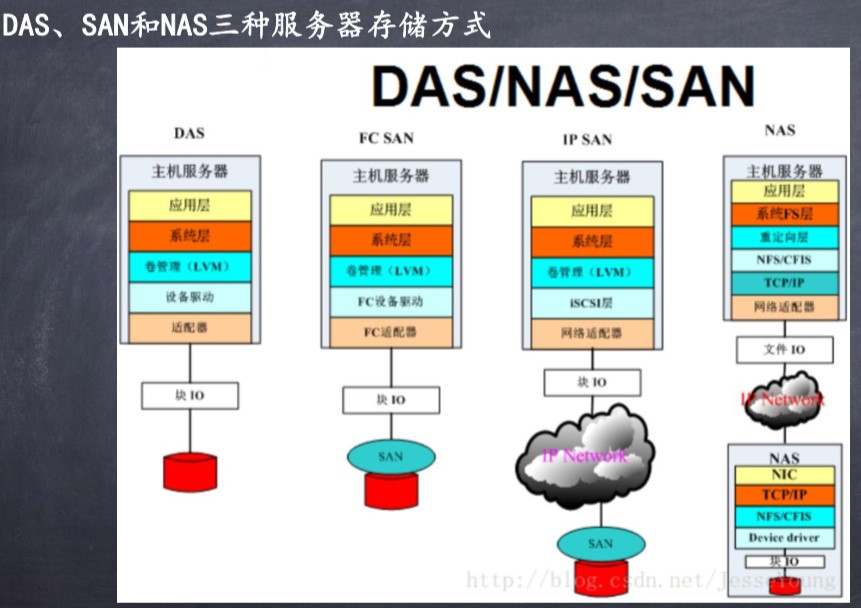
3. DAS, NAS,SAN 的区别
目前服务器所使用的专业存储方案有DAS、NAS、SAN、iSCSI几种。存储根据服务器类型可以分为:封闭系统的存储和开放系统的存储:
(1)封闭系统主要指大型机.
(2)开放系统指基于包括Windows、UNIX、Linux等操作系统的服务器; 开放系统的存储分为:内置存储和外挂存储;
(3)开放系统的外挂存储根据连接的方式分为:
直连式存储(DAS:Direct-Attached Storage)和网络化存储(Fabric-Attached Storage:FAS)
(4)开放系统的网络化存储根据传输协议又分为:
NAS:Network-Attached Storage和SAN:Storage Area Network。由于目前绝大部分用户采用的是开放系统,其外挂存储占有目前磁盘存储市场的70%以上.

4.缺点
DAS的不足之处:
(1)服务器本身容易成为系统瓶颈;
直连式存储与服务器主机之间的连接通道通常采用SCSI连接,带宽为10MB/s、20MB/s、40MB/s、80MB/s等,随着服务器CPU的处理能力越来越强,存储硬盘空间越来越大,阵列的硬盘数量越来越多,SCSI通道将会成为IO瓶颈;服务器主机SCSI ID资源有限,能够建立的SCSI通道连接有限。
(2)服务器发生故障,数据不可访问;
(3)对于存在多个服务器的系统来说,设备分散,不便管理。同时多台服务器使用DAS时,存储空间不能在服务器之间动态分配,可能造成相当的资源浪费;
(4)数据备份操作复杂。
NAS存在的主要问题是:
(1)由于存储数据通过普通数据网络传输,因此易受网络上其它流量的影响。当网络上有其它大数据流量时会严重影响系统性能;
(2)由于存储数据通过普通数据网络传输,因此容易产生数据泄漏等安全问题;
(3)存储只能以文件方式访问,而不能像普通文件系统一样直接访问物理数据块,因此会在某些情况下严重影响系统效率,比如大型数据库就不能使用NAS。
SAN作为一种新兴的存储方式,是未来存储技术的发展方向,但是,它也存在一些缺点:
(1)价格昂贵。不论是SAN阵列柜还是SAN必须的光纤通道交换机价格都是十分昂贵的,就连服务器上使用的光通道卡的价格也是不容易被小型商业企业所接受的;
(2)需要单独建立光纤网络,异地扩展比较困难;
二 ,存储方案-----ISCSI
背景:
相比直连存储,网络存储解决方案能够更加有效地共享,整合和管理资源。从服务器为中心的存储转向网络存储,一直依赖于数据传输技术的发展,速度要求与直连存储相当,甚至更高,同事需要克服并行SCSI固有的局限性。
所有数据在没有文件系统格式化的情况下,都以块的形式存储于磁盘上。 并行SCSI将数据以块的形式传送至存储,但是,对于网络它的用处相当有限,因为线缆不能超过25m,而且最多连接16个设备;
2.ISCSI 架构

iSCSI是一种使用TCP/IP协议,在现有IP网络上传输SCSI块命令的工业标准,它是一种在现有的IP网络上无需安装单独的光纤网络即可同时传输消息和块数据的突破性技术。iSCSI基于应用非常广泛的TCP/IP协议,将SCSI命令/数据块封装为iSCSI包,再封装至TCP 报文,然后封装到IP 报文中。iSCSI通过TCP面向连接的协议来保护数据块的可靠交付。由于iSCSI基于IP协议栈,因此可以在标准以太网设备上通过路由或交换机来传输
3.iSCSI SAN概念解析:
iSCSI Client/Host:
系统中的iSCSI客户端或主机(也称为iSCSI initiator),诸如服务器,连接在IP网络并对iSCSI target发起请求以及接收响应。每一个iSCSI主机通过唯一的IQN来识别,类似于光纤通道的WWN。
要在IP网络上传递SCSI块命令,必须在iSCSI主机上安装iSCSI驱动。推荐通过GE适配器(每秒1000 megabits)连接至iSCSI target。如同标准10/100适配器,大多数Gigabit适配器使用Category 5 或Category 6E线缆。适配器上的各端口通过唯一的IP地址来识别。
iSCSI Target:
iSCSI target是接收iSCSI命令的设备。此设备可以是终端节点,如存储设备,或是中间设备,如IP和光纤设备之间的连接桥。每一个iSCSI target通过唯一的IQN来标识,存储阵列控制器上(或桥接器上)的各端口通过一个或多个IP地址来标识。
本机与异构IP SAN:
iSCSI initiator与iSCSI target之间的关系如图1所示。
本例中,iSCSI initiator(或client)是主机服务器,而iSCSI target是存储阵列。此拓扑称为本机iSCSI SAN,它包含在TCP/IP上传输SCSI协议的整个组件。

4.iscsi 协议

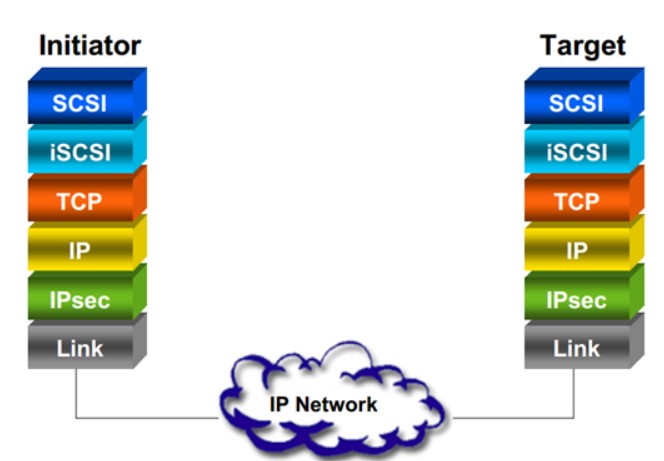
iSCSI有两大主要网络组件。
第一个是网络团体,网络团体表现为可通过IP网络访问的一个驱动或者网关。一个网络团体必须有一个或者多个网络入口,每一个都可以使用,通过IP网络访问到一些iSCSI节点包含在网络团体中。
第二个是网络入口,网络入口是一个网络团队的组件,有一个TCP/IP的网络地址可以使用给一个iSCSI节点,在一个ISCSI会话中提供连接。一个网络入口在启动设备中间被识别为一个IP地址。一个网络入口在目标设备被识别为一个IP地址+监听端口。
iSCSI支持同一会话中的多个连接。在一些实现中也可以做到同一会话中跨网络端口组合连接。端口组定义了一个iSCSI节点内的一系列网络端口,提供跨越端口的会话连接支持。
三.储存方案——GFS
1.概括
GFS: 属于 Scale-Out( 横向扩展 ) 存储解决方案Gluster 的核心,它是一个开源的分 布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数 PB 存储容量和 处理数千客户端。 GlusterFS 借助 TCP/IP 或 InfiniBand RDMA 网络将物理分布 的存储资源聚集在一起,使用单一全局命名空间来管理数据。 GlusterFS 基于可 堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
①Scale Out( 横向扩展 ) :
从字面意思来看, Scale Out 是使用靠增加处理器来提升运算能力和增加独立服 务器来增加运算能力。就是指企业可以根据需求增加不同的服务器和存储应用, 依靠多部服务器、存储协同运算,借负载平衡及容错等功能来提高运算能力及 可靠度。②Scale Up( 纵向扩展 )
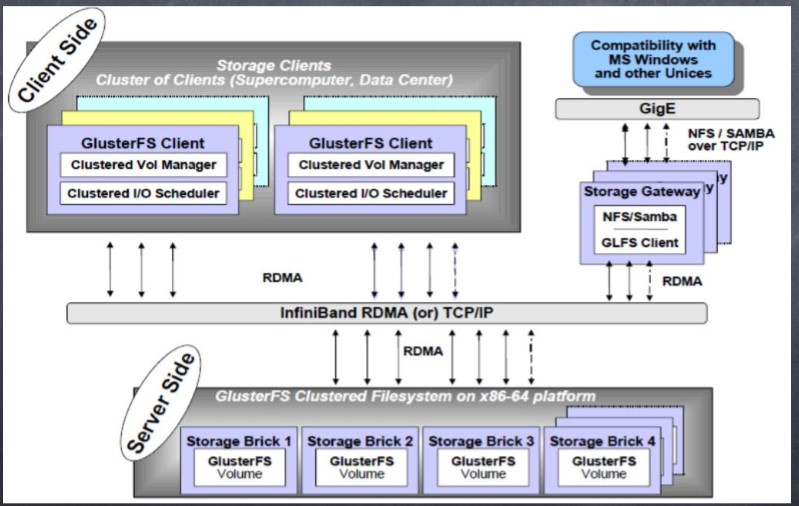
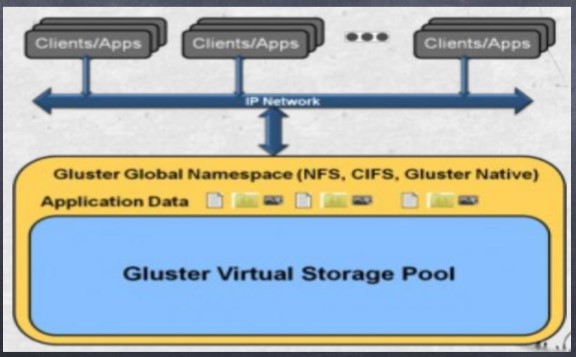
2.特点
1. 扩展性和高性能
2. 高可用性
3. 全局统一命名空间
4. 弹性哈希算法
5. 弹性卷管理

四.GFS技术特点
1. 完全软件实现
2. 完整的存储操作系堆栈
3. 用户空间实现
4. 模块化堆栈式架构

5. 原始数据格式存储
6. 无元数据服务设计
7. Translators
2.GFS Cluster Translators:
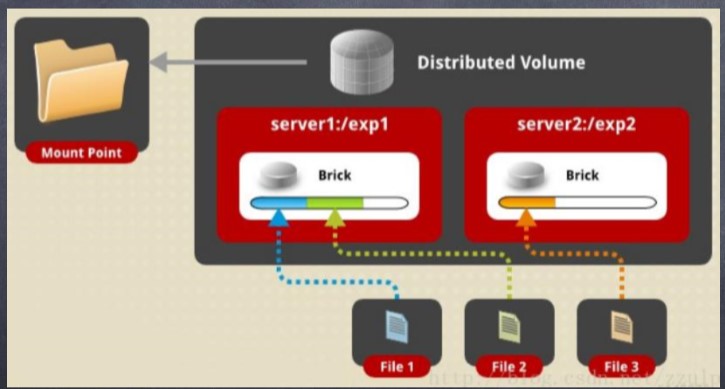
(1)DHT
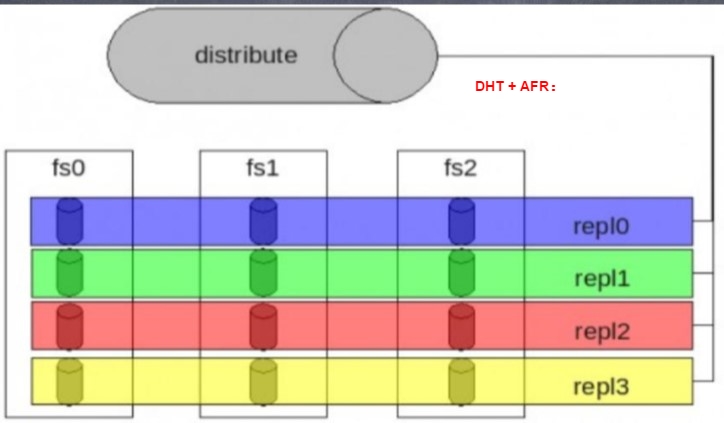
(2)AFR

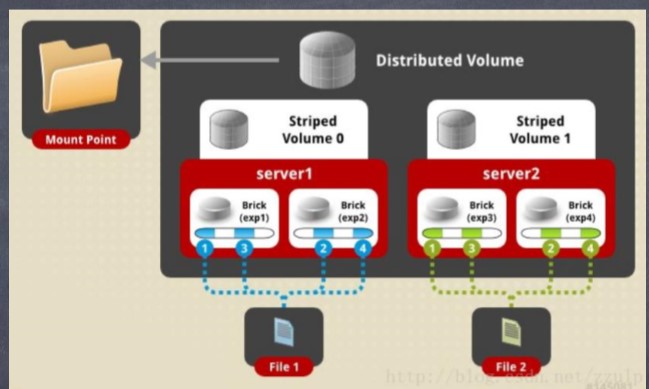
(3)Stripe

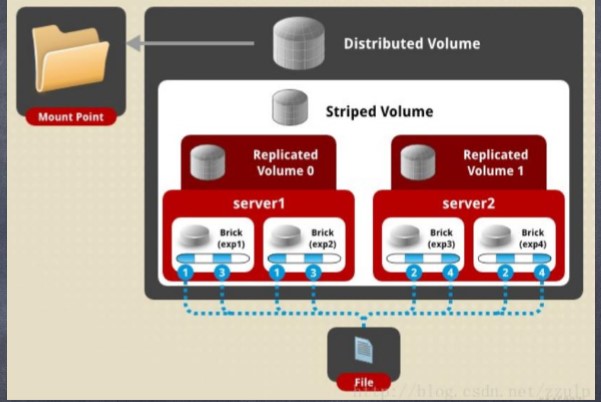
(1)Distribute+Striped
(2)Striped+Replicated
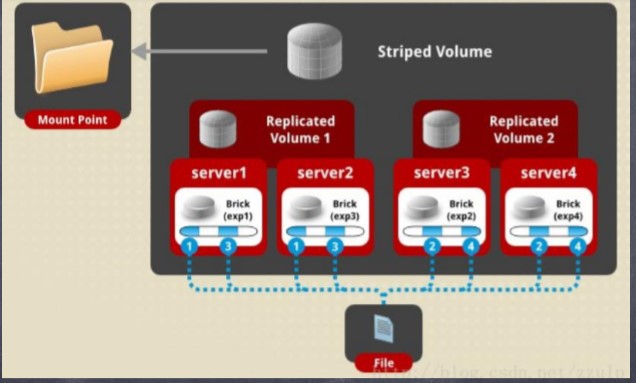
(3)Distribute+Striped+Replicated:
3.GFS 术语
五.储存方案——ceph
1.CEph 简介
2. Ceph 特点
1.高性能
2.高可用性
3.高可扩展性
4.特性丰富
3.Ceph 应用场景:
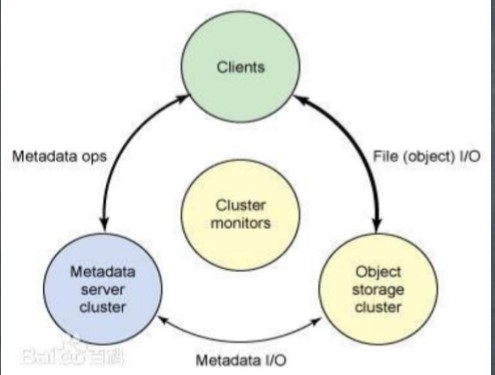
4.什么是块存储/对象存储/文件系统存储?
5.Ceph 核心组件:

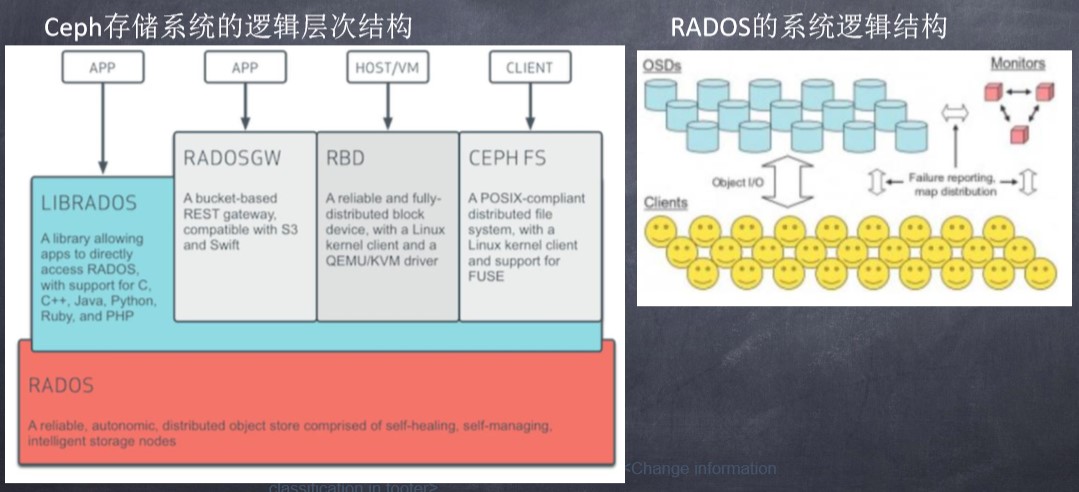
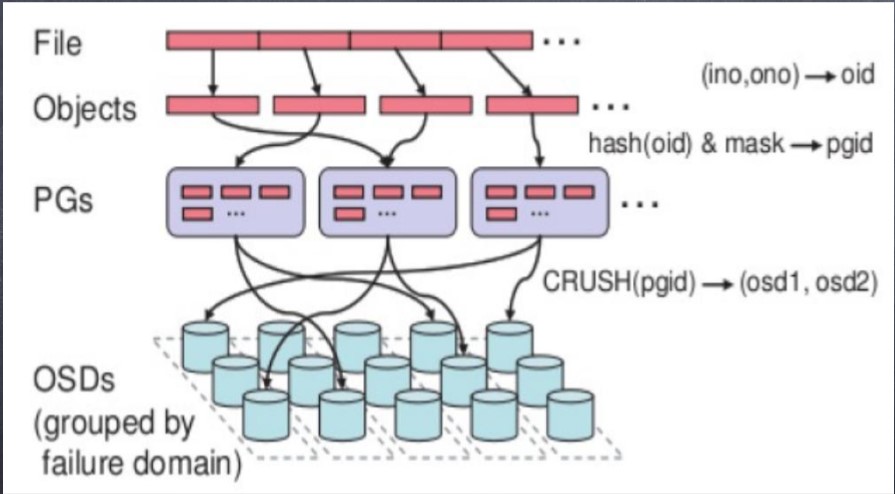
6.Ceph 数据存储过程:
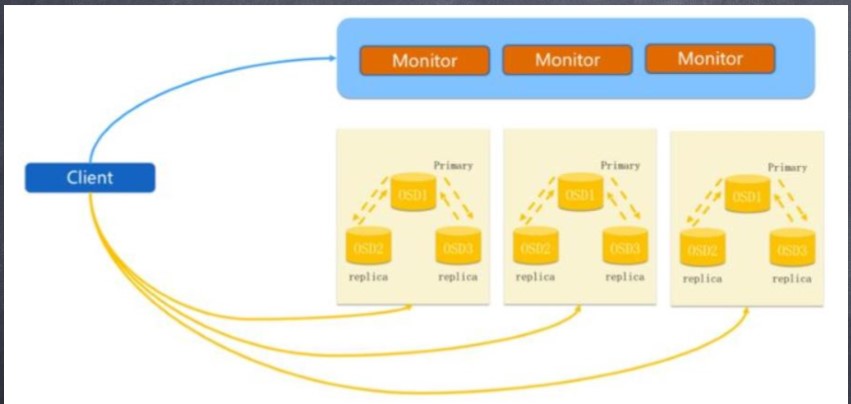
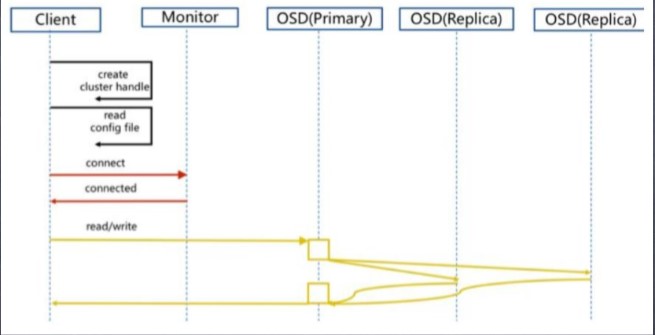
5.Ceph 正常IO 流程图
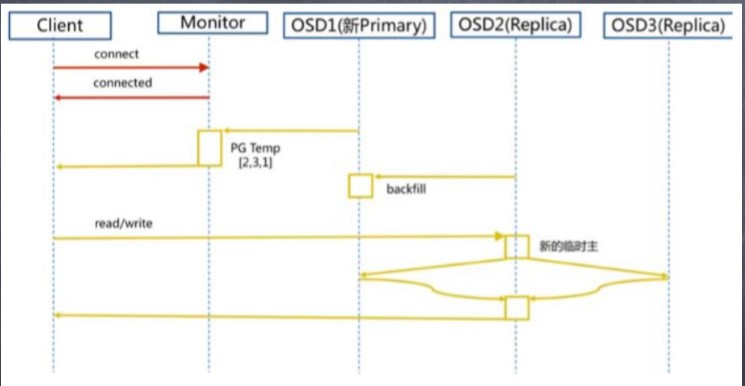
6.Ceph Pool 和PG 分布情况:

六.GFS-cluster 部署与实践
1.前期准备
2. 部署环境:
3.GFS实践
②实现 GFS 之 Replication
③实现 GFS 之 Striping
④实现 GFS 之 Dist+Replica
⑤实现 GFS 之 Stripe+Replica
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">

