
- 1uboot的启动流程分析(一)_armv8架构u-boot启动流程详细分析
- 2网络原理之UDP和TCP协议详细解释_tcp和udp详讲
- 3如何恢复红米手机中已删除的照片?(6种方法可用)
- 42024年深圳杯&东三省数学建模联赛A题B题C题D题超详细解题思路与论文解析_深圳杯2024a题
- 5敖丙给我回信了!_熬太子 csdn
- 6文本向量化表示_文本数据向量化为0说明什么
- 7Linux环境部署以及项目搭建_linux搭建环境部署项目
- 8使用 Selenium 库驱动浏览器:完整入门指南_selenium驱动
- 9mysql中jdbcType的匹配_mysql jdbctype
- 10做人力资源选择小公司or大公司?看完这篇再做决定_大企业的分公司行政人事经理和小企业hrd如何选择
技术突破:llamafile一键部署大模型,释放AI潜力
赞
踩
一、引言
在人工智能的浪潮中,大型语言模型(LLM)已成为推动自然语言处理(NLP)领域进步的关键力量。它们在机器翻译、文本摘要、情感分析等多个领域展现出了卓越的能力。然而,这些强大模型的部署并非易事,传统上需要专业的知识来配置复杂的运行环境和依赖关系,这无疑增加了使用门槛,限制了技术的普及和应用。
随着技术的发展,我们一直在寻求更高效、更便捷的方式来部署和运行这些模型。正是在这样的背景下,llamafile应运而生,它是一项创新的技术,旨在简化大型语言模型的部署流程,让AI的力量触手可及。
llamafile,一个由Mozilla创新团队推出的项目,通过将模型权重和运行环境封装进单个可执行文件中,彻底改变了大型语言模型的分发和运行方式。这项技术的核心在于它的简洁性和易用性,使得即使是没有深厚技术背景的用户也能够轻松地在自己的计算机上部署和运行大型语言模型。

二、什么是llamafile?
llamafile是一种创新的解决方案,它允许用户通过单一的文件来部署和运行大型语言模型(LLM)。这种文件包含了模型的所有权重和必要的运行时环境,使得用户无需进行繁琐的环境配置和依赖安装。(一键部署运行)
1、设计目标
- 简化部署:降低技术门槛,使得部署大型模型变得简单快捷。
- 跨平台兼容性:支持多种操作系统,包括但不限于Windows、macOS、Linux。
- 独立运行:不依赖外部环境,减少了运行时出现问题的可能性。
2、技术构成
- llama.cpp:一个C++库,为模型提供运行所需的底层支持。
- Cosmopolitan Libc:一个跨平台的C标准库,确保了llamafile在不同操作系统上的兼容性。
- 模型权重:直接嵌入到llamafile中,无需额外下载或配置。
3、与传统部署方式的对比
- 环境依赖:传统部署需要用户配置Python环境、安装依赖库等,而llamafile无需这些步骤。
- 安装复杂性:传统部署可能需要编译代码、设置环境变量等,llamafile则通过双击运行来替代。
- 分发效率:传统方式可能需要通过复杂的脚本或容器技术来分发模型,llamafile则通过单个文件实现快速分发。
4、一键部署的优势
- 快速启动:用户可以迅速开始使用模型,无需等待漫长的安装过程。
- 易于分享:开发者可以轻松地将模型分享给其他用户,无需担心环境差异导致的问题。
- 降低维护成本:减少了因环境问题导致的维护工作,提高了模型的稳定性和可靠性。
三、核心特性
1、一键部署的便捷性
llamafile最引人注目的特性之一是它的一键部署能力。用户只需下载相应的llamafile文件,然后执行这个文件,即可启动模型。这种便捷性的背后是大量的工程努力,将模型的复杂性封装在用户友好的界面之后。
2、跨平台支持
llamafile支持多种操作系统,包括但不限于Windows、macOS、Linux等。这种跨平台的特性使得无论用户使用的是哪种操作系统,都能够轻松地部署和运行大型语言模型。
3、独立可执行文件
每个llamafile都是一个独立的可执行文件,这意味着它们包含了运行模型所需的所有依赖和配置。用户无需担心环境配置问题,也不需要安装额外的软件或库。
4、简化的分发流程
通过将模型和运行环境打包到一个文件中,llamafile简化了模型的分发流程。开发者可以轻松地分享他们的模型,而用户则可以立即开始使用,无需复杂的安装步骤。
5、技术细节
- 权重文件的嵌入:模型的权重文件被直接嵌入到llamafile中,这不仅减少了外部依赖,也加快了模型的加载速度。
- 自包含的运行环境:llamafile包含了一个精简的运行环境,这使得它能够在不同的系统上以一致的方式运行。
- 动态链接库的优化:在需要时,llamafile可以动态链接到系统上的特定库,以提供额外的功能,如GPU加速。
6、用户体验
- 无需专业知识:即使是没有深厚技术背景的用户,也能够轻松地使用llamafile。
- 快速反馈:用户可以立即看到模型的运行结果,无需等待长时间的编译或环境搭建。
- 灵活的交互方式:用户可以通过命令行、Web界面或其他客户端与模型进行交互。
7、安全性和隐私
- 本地运行:由于模型在本地运行,用户的数据处理可以保持在本地,增强了隐私性。
- 开源透明:llamafile的开源特性意味着用户可以查看和修改模型的运行代码,增加了透明度。
四、部署流程详解
1、下载模型
部署大型语言模型的第一步是获取模型文件。用户可以从HuggingFace、modelscope等平台下载所需的llamafile。这些文件通常包含了模型的权重和配置信息,并且已经过优化,以确保在不同系统上都能高效运行。
当前llamafile集合中的模型列表:
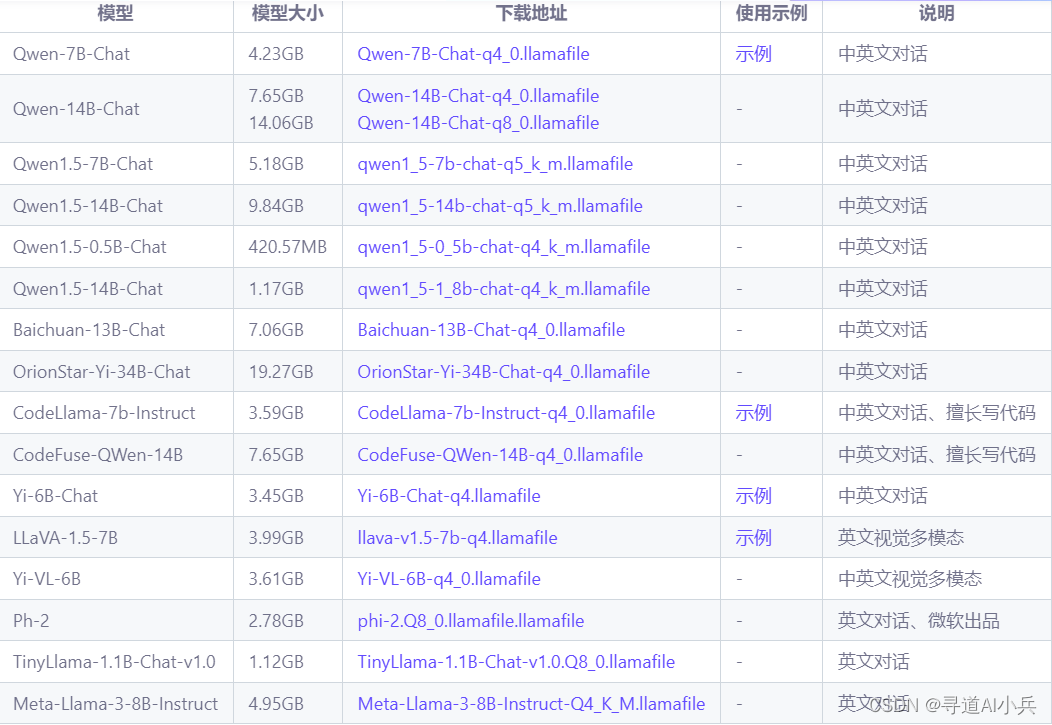
注意:Windows 系统不支持单个 exe 文件超过 4GB,所以大于 4GB 的模型,需要分别下载 llamafile 和 gguf 模型运行;此外,也可以使用 Windows 的 WSL 子系统(Linux)来运行,同样可以绕过 4GB 的限制
2、操作系统特定的运行步骤
-
Linux/macOS:
- 下载llamafile到本地。
- 为文件添加执行权限:
chmod +x filename.llamafile。 - 运行模型:
./filename.llamafile。
-
Windows:
- 下载并重命名llamafile,添加
.exe后缀:filename.llamafile.exe。 - 双击文件或通过命令行运行。
- 下载并重命名llamafile,添加
3、运行环境配置
- 环境依赖:大多数情况下,llamafile不需要额外的环境依赖,因为它是一个自包含的可执行文件。
- 特殊配置:对于需要GPU加速的情况,可能需要根据所使用的硬件安装相应的驱动程序和SDK。
4、访问Web界面
一旦模型运行起来,用户可以通过Web界面与模型进行交互。通常,llamafile会在本地启动一个Web服务器,用户只需在浏览器中输入对应的URL(如http://127.0.0.1:8080)即可访问。
5、命令行交互
除了Web界面,用户也可以通过命令行与模型进行交互。这为需要自动化或脚本化交互的用户提供了一个灵活的选择。
6、模型API的使用
对于开发者来说,llamafile还提供了类似于OpenAI的API接口,使得开发者可以通过编程方式与模型进行交互,实现更复杂的应用场景。
7、部署实践样例
7.1 模型下载部署运行
Windows 系统 (4G以内)
1)模型下载
下载地址:
Qwen1.5-14B-Chat(1.17GB)
qwen1_5-1_8b-chat-q4_k_m.llamafile
https://www.modelscope.cn/api/v1/models/bingal/llamafile-models/repo?Revision=master&FilePath=Qwen1.5-1.8B-Chat%2Fqwen1_5-1_8b-chat-q4_k_m.llamafile
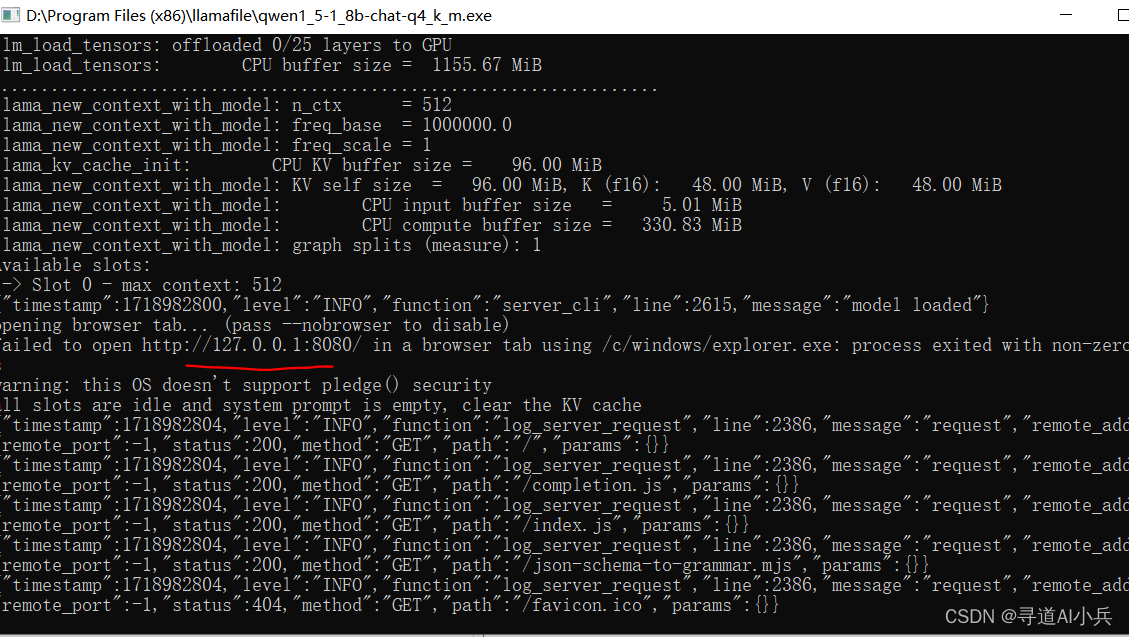
2)模型运行
修改文件名,增加 .exe 后缀,如改成 qwen1_5-1_8b-chat-q4_k_m.exe
双击运行或者打开 cmd 命令行窗口,进入模型所在目录
.\qwen1_5-1_8b-chat-q4_k_m.exe
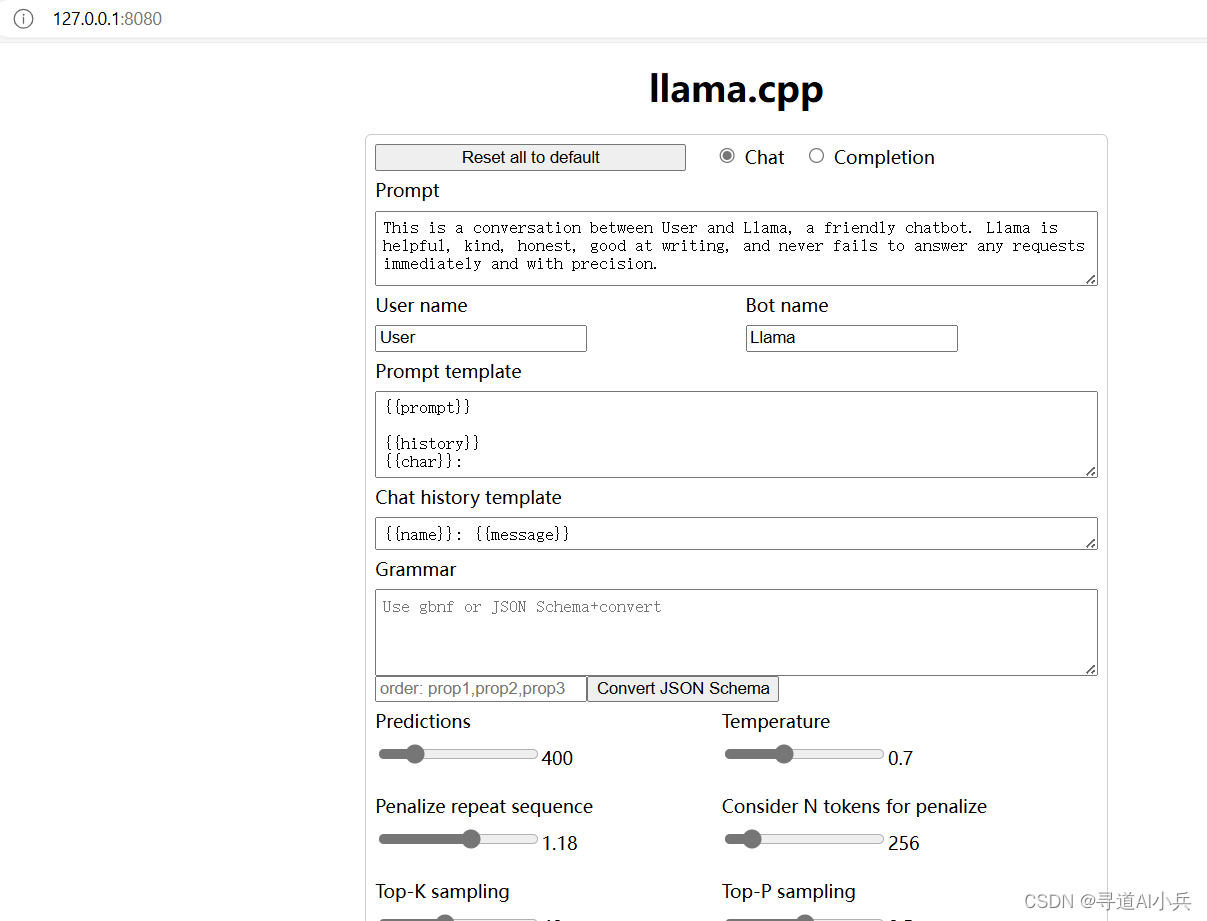
3)模型访问
浏览器打开 http://127.0.0.1:8080 即可开始聊天
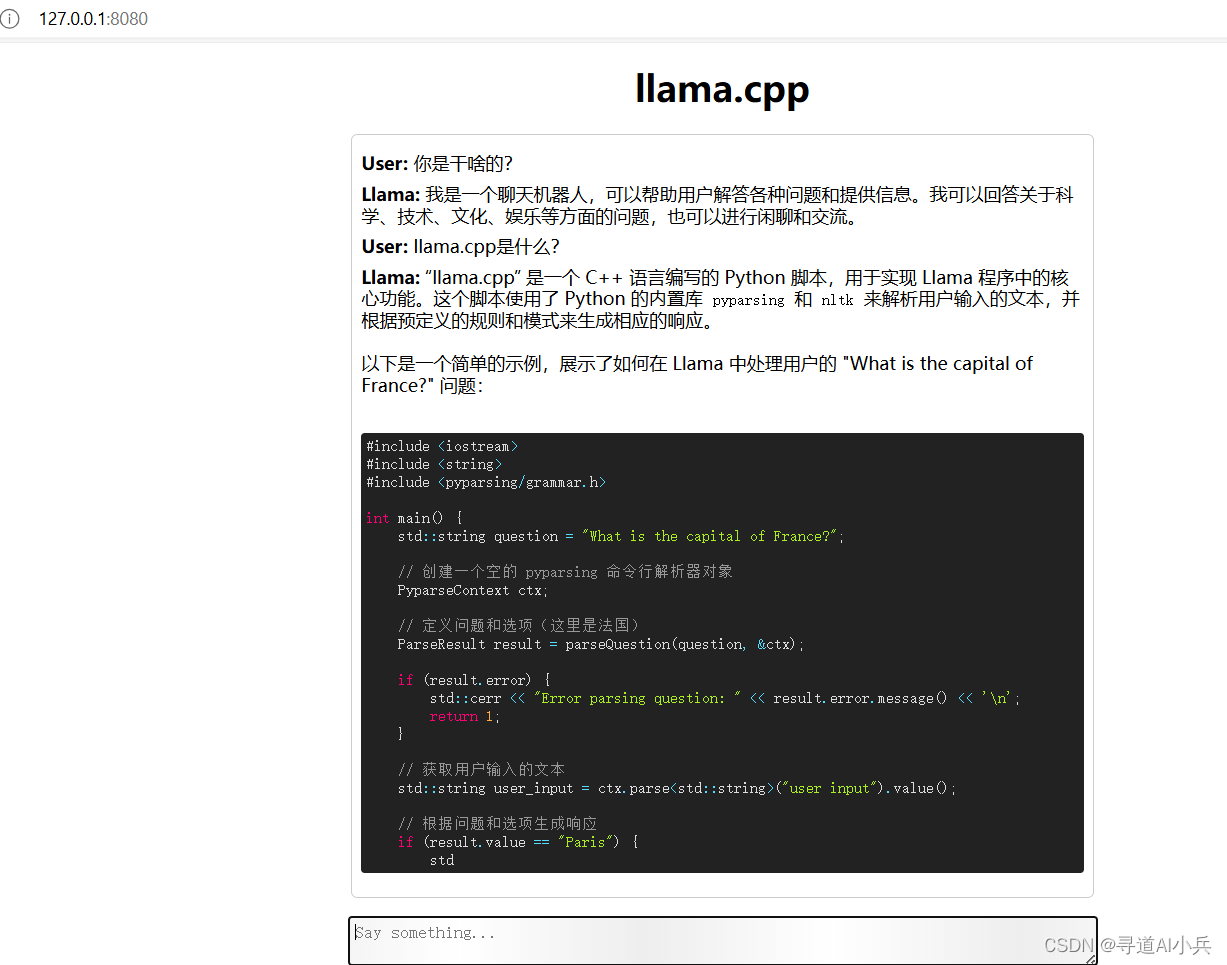
4)聊天对话测试
Windows 系统 (大于4G)
Windows 系统不支持单个 exe 文件超过 4GB 的限制,所以需要分别下载 llamafile 和 gguf 模型运行;此外,也可以通过 Windows 的 WSL 子系统(Linux)运行,同样可以绕过 4GB 的限制
1)模型下载
下载llamafile:
https://www.modelscope.cn/api/v1/models/bingal/llamafile-models/repo?Revision=master&FilePath=llamafile-0.6.2.win.zip
下载后解压得到 llamafile-0.6.2.exe 文件。
下载 Qwen1.5-7B-Chat-GGUF 模型:
Qwen1.5-7B-Chat-GGUF: 70 亿参数的 q5_k_m 量化版本,5.15GB。
https://www.modelscope.cn/api/v1/models/qwen/Qwen1.5-7B-Chat-GGUF/repo?Revision=master&FilePath=qwen1_5-7b-chat-q5_k_m.gguf
2)模型运行
打开 cmd 或者 terminal命令行窗口,进入模型所在目录
.\llamafile-0.6.2.exe -m .\qwen1.5-7b-chat-q5_k_m.gguf -ngl 9999 --port 8080 --host 0.0.0.0
- 1
3)模型访问
浏览器打开 http://127.0.0.1:8080 即可开始聊天
Linux、Mac 系统
终端运行(注意 Mac 系统可能需要授权,在【设置】→ 【隐私与安全】点击【仍然打开】进行授权)
./qwen1_5-1_8b-chat-q4_k_m.llamafile
- 1
浏览器打开 http://127.0.0.1:8080 即可开始聊天
7.2 模型API调用
#!/usr/bin/env python3
from openai import OpenAIclient = OpenAI(
base_url="http://localhost:8080/v1", # "http://<Your api-server IP>:port"
api_key = "sk-no-key-required"
)
completion = client.chat.completions.create(
model="LLaMA_CPP",
messages=[
{"role": "system", "content": "您是一个人工智能助手。您的首要任务是帮助用户实现他们的请求,以实现用户的满足感。"},
{"role": "user", "content": "写一个与龙有关的故事"}
]
)
print(completion.choices[0].message)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
7.3 可选参数说明
-- ngl 9999 表示模型的多少层放到 GPU 运行,其他在 CPU 运行,如果没有 GPU 则可设置为 -ngl 0 ,默认是 9999,也就是全部在 GPU 运行(需要装好驱动和 CUDA 运行环境)。
-- host 0.0.0.0 web 服务的hostname,如果只需要本地访问可设置为 --host 127.0.0.1 ,如果是0.0.0.0 ,即网络内可通过 ip 访问。
-- port 8080 web服务端口,默认 8080 ,可通过该参数修改。
-- t 16 线程数,当 cpu 运行的时候,可根据 cpu 核数设定多少个内核并发运行。
-- 其他参数可以通过 --help 查看。
- 1
- 2
- 3
- 4
- 5
五、llamafile支持说明
1、llamafile支持以下操作系统(最低标准安装说明)
- Linux:内核版本2.6.18或更高版本(支持ARM64或AMD64架构),适用于任何如RHEL5或更新版本的分发版
- macOS:macOS 14 Sonoma(Darwin版本23.1.0)或更高版本(支持ARM64或AMD64架构,但仅ARM64架构支持GPU加速),Darwin内核版本15.6或更高版本理论上应该得到支持,但我们目前无法进行实际测试。
- Windows:windows 8或更高版本(仅支持AMD64架构)
- FreeBSD: FreeBSD13或更高版本(支持AMD64或ARM64架构,理论上GPU应可工作
- NetBSD:NetBSD9.2或更高版本(仅支持AMD64架构,理论上GPU应可工作)
- OpenBSD:OpenBSD 7或更高版本(仅支持AMD64架构,不支持GPU加速)
2、llamafile支持以下CPU类型
- AMD64架构的微处理器必须支持SSSE3指令集。如果不支持,llamafile将显示错误信息并无法运行。这意味着,如果您使用的是Intel CPU,至少需要是Intel Core或更新系列(约2006年以后);如果是AMD CPU,至少需要是Bulldozer或更新系列(约2011年以后)。如果您的CPU支持AVX或更高级的AVX2指令集,llamafile将利用这些特性以提升性能。目前AVX512及更高级指令集的运行时调度尚未得到支持。
- ARM64架构的微处理器必须支持ARMv8a+指令集。从Apple Silicon到64位Raspberry Pis的设备都应该兼容,只要您的权重数据能够适应内存容量。
3、llamafile 对 GPU 的支持说明
- 在搭载 MacOS 的 Apple Silicon 系统上,只要安装了 Xcode 命令行工具,Metal GPU 就应该能够正常工作。 在 Windows 系统上,只要满足以下两个条件,GPU 就应该能够正常工作:(1)使用我们的发行版二进制文件;(2)传递 -ngl 9999 标志。如果您只安装了显卡驱动程序,那么 llamafile 将使用 tinyBLAS 作为其数学内核库,这对于批处理任务(例如摘要生成)来说会慢一些。为了获得最佳性能,NVIDIA GPU 用户需要安装 CUDA SDK 和 MSVC;而 AMD GPU 用户则需要安装 ROCm SDK。如果 llamafile 检测到 SDK 的存在,那么它将为您系统编译一个原生模块,该模块将使用 cuBLAS 或 hipBLAS 库。您还可以通过启用 WSL 上的 Nvidia
CUDA 并在 WSL 中运行 llamafiles 来使用 CUDA。使用 WSL 的额外好处是,它允许您在 Windows 上运行大于
4GB 的 llamafiles。- 在 Linux 系统上,如果满足以下条件,Nvidia cuBLAS GPU
支持将在运行时编译:(1)安装了 cc 编译器;(2)传递 -ngl 9999 标志以启用 GPU;(3)在您的机器上安装了 CUDA
开发工具包,并且 nvcc 编译器在您的路径中。- 如果您的机器中同时有 AMD GPU 和 NVIDIA GPU,那么您可能需要通过传递
–gpu amd 或 --gpu nvidia 来指定要使用的 GPU。- 如果由于任何原因无法在运行时编译和动态链接 GPU 支持,llamafile 将回退到 CPU 推理。
六、优势与局限性
1、优势概述
- 易用性: llamafile极大地简化了部署大型语言模型的复杂性,使得用户无需深入了解底层技术即可运行模型。
- 跨平台性: 支持多种操作系统,包括Windows、macOS、Linux等,提供了广泛的适用性。
- 快速部署: 用户可以迅速下载并运行模型,无需等待漫长的安装过程。
- 资源共享: 易于分享的特性促进了知识的传播和资源的共享,有助于社区的协作和创新。
2、局限性探讨
-
硬件依赖性:尽管llamafile简化了软件部署,但运行大型语言模型仍然需要相对较强的硬件支持,特别是对于需要大量计算资源的模型。用户可能需要高性能的CPU或GPU来确保模型运行的流畅性。
-
更新维护:模型和底层库的更新可能需要用户定期下载新的llamafile文件,这可能会带来额外的维护工作。此外,每次更新后,用户可能需要重新适应新的功能或接口变化。
-
特定功能的限制:某些特定功能或优化可能需要额外的配置或依赖,这可能会增加部署的复杂性。例如,利用GPU加速可能需要用户进行特定的设置或安装相应的驱动程序。
-
安全性和隐私问题:虽然本地运行模型可以增强数据隐私,但这也意味着用户需要对模型的安全性负责。如果llamafile文件来源不可靠,可能会带来安全风险。
-
可定制性的限制:llamafile作为一个封装好的执行文件,可能在某些情况下限制了用户对模型进行定制或扩展的能力。对于需要深度定制模型以适应特定应用场景的用户来说,这可能是一个限制。
-
错误诊断和调试难度:由于llamafile封装了模型和环境,一旦出现问题,用户可能难以快速定位和解决问题。相比于开放的环境,黑盒式的部署可能会增加调试的难度。
-
平台兼容性问题:虽然llamafile支持多平台,但在一些特定的系统配置或操作系统版本上可能会出现兼容性问题,需要额外的调整或等待开发者发布补丁。
用户应根据自己的需求和资源情况,权衡llamafile的优势和局限性,选择最合适的部署方案。
七、结语
llamafile的意义
llamafile的推出标志着大型语言模型部署方式的重要转变。它不仅降低了技术门槛,还扩大了AI技术的受众范围,使得更多的人能够接触和利用这一强大的技术。
对开发者和企业的影响
对于开发者而言,llamafile提供了一个快速原型和测试模型的工具,加速了开发流程。对于企业来说,它简化了产品的集成和部署过程,有助于快速响应市场变化。
对AI技术普及的贡献
llamafile通过简化部署流程,为AI技术的普及做出了重要贡献。它让更多人能够体验到AI的强大能力,激发了对AI技术的兴趣和探索。
未来展望
随着技术的不断发展,我们期待llamafile能够继续进化,解决现有的局限性,提供更加强大和灵活的模型部署方案。同时,我们也希望看到更多的创新工具和平台出现,共同推动AI技术的进步。
最后的思考
llamafile是AI领域的一个重要里程碑,但它只是开始。随着技术的不断进步,我们期待一个更加开放、易用和高效的AI生态系统的建立,让每个人都能享受到AI带来的便利和乐趣。
相关资料链接
llamafile 模型合集:https://www.modelscope.cn/models/bingal/llamafile-models/
llamafile Github:https://github.com/Mozilla-Ocho/llamafile
llamafile 中文使用指南:https://www.bingal.com/posts/ai-llamafile-usage/

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

