- 1云游戏是大厂的“游戏”之腾讯云<云游戏指南>
- 2stringstream_stringstream 析构
- 3vscode中使用GitHub Copilot Chat_vscode github copilot chat
- 4Embedding的理解_tcn中的embedding是什么意思
- 5Nginx代理长连接(Socket连接)_nginx socket
- 6fatal: could not create work tree dir ‘xxx’: Permission denied解决办法
- 7Python基础教程(二十二):XML解析
- 8【杭州游戏业:创业热土,政策先行】_乐港 绝地
- 9【Vue】vue项目中使用tinymce富文本组件(@tinymce/tinymce-vue)_vue tinymce
- 10springboot集成neo4j_org.neo4j.ogm是哪个依赖
Linux常用工具使用方式
赞
踩
目录
常用工具:
主要分类为:安装包管理工具(软件商店)、编辑器、编译器、调试器、项目自动化构建工具、项目版本管理工具、文件传输工具。
安装包管理工具:
查找含有关键字的软件包
apt-cache search [关键字]
安装软件
apt-get install [软件名]
安装文件传输工具
apt-get install lrzsz
安装编辑器
apt-get install vim
C语言编译器
apt-get install gcc
C++编译器
apt-get install g++
安装调试器
apt-get install gdb
安装项目版本管理工具
apt-get install git
cmake
apt-get install cmake
卸载软件
apt-get remove [文件名]
安装jsoncpp
apt-get install libjsoncpp-dev
安装boost库
apt-get install libboost-all-dev
安装mariadb
apt-get install mariadb-server
apt-get install mariadb-client
apt-get install libmariadb-dev
安装tree(让目录以tree的形式进行显示)
apt-get install tree
卸载:
apt-get remove [软件名]
编辑器vim
背景:
unix开发出来后,出了第一款类unix平台编辑器vi,但是vi并不好用,因此vim出现。
vim是一个命令行编辑器,因此默认无法使用鼠标进行操作。
为了能够使vim使用更加方便,为此设计了多种操作模式,在不同的操作模式下,相同的按键会有不同的作用。
vim的使用
操作模式共有12种,而写代码的主要只有3种。
普通模式:
是对文档内容进行命令操作
插入模式:
对文档内容的编辑
底行模式:
对文档的保存以及退出操作
vim后边更上文件名,就可以使用vim打开文件,默认处于普通模式
基本操作
a:从光标后开始插入
o:新建一行
还有大写I A O
: 进入底行模式
w 保存
q 退出
q! 强制退出
X 保存并退出
ESC 进入普通模式
复制:
yy 复制一行 nyy从光标行开始复制n行内容
粘贴:
p np 粘贴n行剪切板内容
剪切/删除:
dd删除一行 ndd
x 删除光标所在的字符
ggdG 从首行删除到尾行
撤销:
U 撤销的撤销ctrl+r
对其以及行操作
全文对齐:按照代码风格进行缩进对齐
底行模式输入:
gg=G 对齐
gg 光标移动到文档首行
G 光标移动到末位一行
set number 显示行号
光标移动:
hjkl 左下上右移动光标
w/b 以单词左右移动
翻页:
ctrl+f / ctrl+b 上下翻页
分屏:
进入底行模式输入vnew,新建一个窗口,分屏操作
ctrl+ww切屏
编译器:
将高级语言代码解释成为机器可识别的指令(不同的语言有不同的编译器)
C语言:gcc,msvc,clang.....
C++语言:g++
编译器进行代码解释的四个阶段:
预处理:
头文件引用,去除注释,宏替换...
编译:
进行语法,语义纠错,没有错误则将代码解释成为汇编指令
汇编:
将汇编指令,解释成为机器能识别的二进制指令。
链接:
将所有的机器代码(不同.c生成的文件,库文件)进行打包生成一个可执行程序
gcc编译器常用选项:
-E 只进行预处理
-S 只进行编译
-C 只进行汇编
-O 指定生成的文件名称
如果gcc不跟其他选项,那么生成的就是可执行程序
gcc -E main.c -o main.i
gcc -S main.i -o main.s
gcc -C main.s -o main.o
链接:库
在系统中,有一种文件叫做库文件:是进行特定功能,提前封装实现的函数,经过预处理,编译,汇编,打包之后生成的一个提供给别人使用的代码文件
库文件
虽然也是大量的二进制代码打包文件,但是它没有main函数。(因为一个代码里是不能出现两个main函数的。)
动态库&静态库
编译器的链接方式:
动态链接:
链接的是动态库,链接的时候,并不会将库中函数的实现指令给程序中也复制一份,而是只记录了一份符号表到程序中。
优点:
生成的可执行程序比较小
多个程序如果使用了相同的库文件,,实际的库函数代码在内存中就会只加载一份
缺点:
运行程序的时候,需要加载库文件,会耗费时间
多个程序加载时,都会先去扫瞄是否存在该库。
静态链接:
链接的是静态库,链接的时候,是将库中具体用到的函数
优点:
运行时不依赖库文件的存在(具体用到的代码是存在的)
缺点:
生成的可执行程序比较大,如果多个程序都用到了同一个静态库中的代码,则多个程序运行起来后,内存会存在冗余。
gcc默认链接方式:
动态链接(在同一个目录下,有同名的动态库文件,静态库文件lib.so,libc.a,这时候优先链接动态库)
调试器:gdb
作用:
调试程序的运行过程,排查程序运行结果结果不符合预期的原因。
可执行程序分为两类:
debug程序--调试版:
程序员调试程序运行的过程,调试错误
release程序--发布版:
测试人员测试的版本,以及交付的版本
gcc编译器对程序进行编译,最终生成的可执行程序,默认是release版本
然而release版程序是无法被调试的(因为程序中没有调试符号信息,并且代码有可能进行了优化)。
程序调试操作一:
生成debug版本程序
gcc编译链接的时候
gcc -g 生成debug版本程序
程序调试操作二:
使用gdb加载程序
gdb ./main
程序调试操作三:
各种不同的调试指令
1:开始运行程序:run
2:逐步调试程序:start
3:查看调试行附近代码:list main.c:[行号]
如until main.c:9
程序调试操作四:
next--逐过程--遇到函数则直接将函数执行完
step--逐语句--遇到函数则进入函数对函数内部进行逐步调试
程序调试操作五:
直接将代码运行到指定行:until main.c:[行号]
程序调试操作六:
从当前调试位置,开始运行:continue
程序调试操作七:
打断点--让程序运行到指定位置停下来等待调试:break main.c:19 break func
程序调试操作八:
查看断点信息:info break
程序调试操作九:
删除断点:delete [断点编号(info break前方会显示断点编号)]
程序调试操作十:
查看调用栈 backtrace
程序运行一旦崩溃,则调用栈的栈顶函数就是当前导致程序崩溃的代码。
程序调试操作十一:
查看变量内容 print [变量]
程序调试操作十二:
设置变量内容 print [变量]=10
程序调试操作十三:
给变量打断点 watch
项目的自动化构建工具:make&Makefile
Makefile:
就是一个常规的文本文件,但是搭配了make就不一样了
Makefile可以记录项目的构建规则
然后通过make对规则进行解释执行
make:
就是一个Makefile解释程序,会对Makefile中记录的规则按照一定语法规则进行解释执行,最终完成项目的构建
make的执行,会到执行make指令所在的目录下查找Makefile文件,找到了就执行,找不到则会报错。
注意:Makefile文件名是固定的,可以是Makefile或者makefile。其他的都不行
Makefile的编写规则:
[目标对象]:[依赖对象]
\t指令
make解释规则:make会在makefile中找到第一个目标对象
1、检测目标对象文件是否存在
有:则会检测目标对象文件与依赖对象文件的时间关系,判断目标是否需要重新生成(在目标文件上次生成后,源码有没有修改过)
没有:则需要生成
2、如果需要生成,则会检测依赖文件是否存在,是否需要生成因此会到下边找寻依赖文件的生成规则,先生成依赖文件,最终依赖文件都生成后,再去生成目标文件
3、第一个目标对象文件生成后,则退出。所以要把最后想生成什么放在第一行
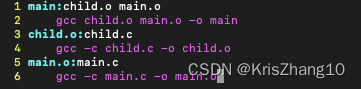
make解释规则:
1、在执行make指令的目录下,查找Makefile文件进行解释
2、在Makefile中,找到第一个目标对象
3、根据目标与依赖的时间关系,判断目标对象是否需要重新生成,不需要则直接退出。
4、判断依赖对象是否需要生成。如果需要则查找依赖对象的生成规则。进行生成
5、执行指令,完成目标对象的生成后退出。
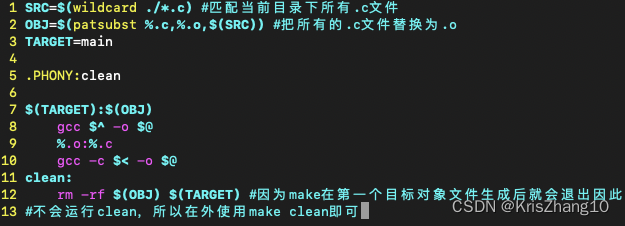
makefile中的其他简化操作:
预定义变量:
- $^ 当前编译规则的所有依赖对象
- $< 当前编译规则中第一个依赖对象
- $@ 当前编译规则中的目标对象

wildcard获取指定目录下特定规则的文件名
patsubst对字符串进行内容替换,将.c替换为.o

伪对象:
使用PHONY声明一个对象为伪对象
作用:分离目标对象与实际文件之间的关系
(声明makefile中的目标对象是一个假的对象,与实际的文件没有关系。)
这样的话,目标对象的编译规则中的指令无论如何都会被执行。
(为了让一个指令不受外部文件影响,每次都执行。比如有时候.o是最新的,就会导致不会运行make,或者说外面有一个clean的文件,再使用make clean它就不知道执行什么,所以需要这样一个设置。)
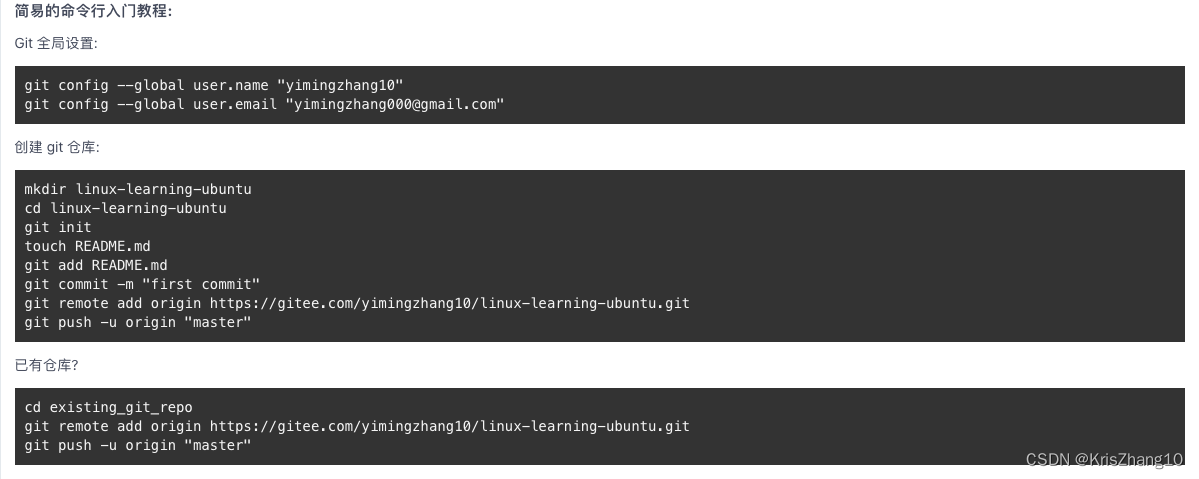
项目版本管理工具:git
项目的版本管理:说白了就是将不同提交版本的代码给备份起来以备回滚,以及容灾。
版本管理的工具种类:svn,git,......
1、克隆远程仓库:git clone [地址]
比如gitee的地址在:

点击http
2、添加修改项:git add --all ./
3、提交版本:git commit -m [本次版本的备注]
4、远程推送:git push origin master
⚠️提示⚠️:比如今天在a文件内提交了main1到master在b文件内也想提交main2到master,那么应该先进行pull再进行main2的提交。
git教程参考网址: