
热门标签
热门文章
- 1[转载]静态成员函数能不能同时也是虚函数?
- 2Git切换账号并推送代码_gitlab切换用户然后拉代码
- 3java输入与输出_java输入和输出
- 412.6 Python read()函数:按字节(字符)读取文件_不管f是文本文件还是二进制总结,f.read()都可以读出文件所有内容
- 5技术领导力实战笔记:14
- 6火车头采集器ChatGPT伪原创接口-火车头伪原创插件的使用指南
- 7【unity】关于unity3D摄像机视角移动的几种方式详解_unity鼠标控制摄像头
- 8如何写一封稍微像样的求职邮件
- 9快速学会python基本编程学习笔记_python快速编程re大学笔记
- 10数据库第四次试验:数据库的组合查询、统计查询及视图_librarydb数据查询实训
当前位置: article > 正文
Ubuntu安装Scala2.12.13+spark2.4.3_ubantu下载scala 2.12
作者:小桥流水78 | 2024-07-02 04:36:44
赞
踩
ubantu下载scala 2.12
百度网盘下载 大数据平台搭建 文件
一、Scala 2.12.13安装
1、下载Scala,并查看其路径
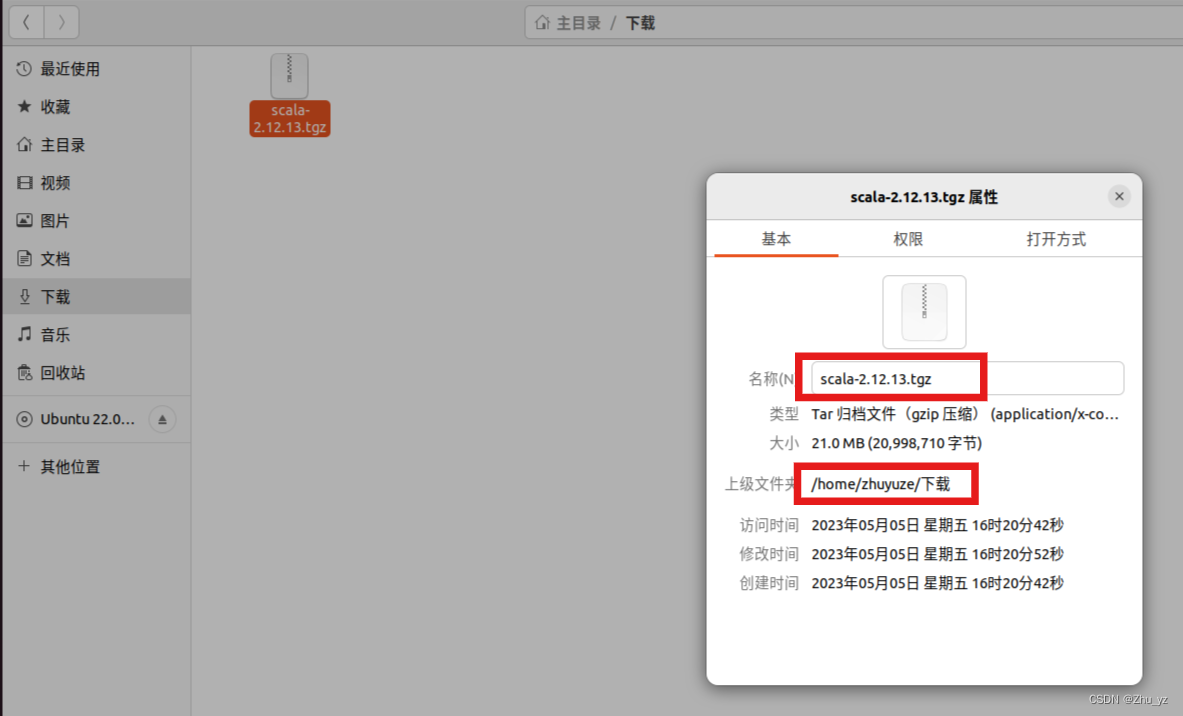
2、安装Scala并配置环境
(1)将下载的scala文件解压到/usr/local目录下并修改文件名为scala
sudo tar -zxf /home/zhuyuze/下载/scala-2.12.13.tgz -C /usr/local
cd /usr/local
sudo mv ./scala-2.12.13/ ./scala
- 1
- 2
- 3
(2)配置环境变量
vim ~/.bashrc
- 1
在文件最后输入以下代码(输入前先输入i)并保存后退出(Esc+:wq)
export SCALA_HOME=/usr/local/scala
export PATH=$SCALA_HOME/bin:$PATH
- 1
- 2
使环境变量生效
source ~/.bashrc
- 1
3、查看Scala版本
scala -version
- 1

4、Scala编程
(1)使用scala
scala
- 1
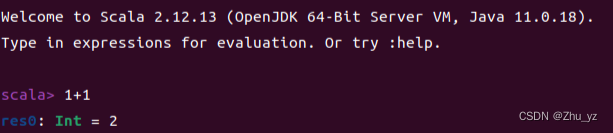
(2)退出scala
:quit
- 1
二、spark安装并配置环境
1、下载安装spark,并查看路径
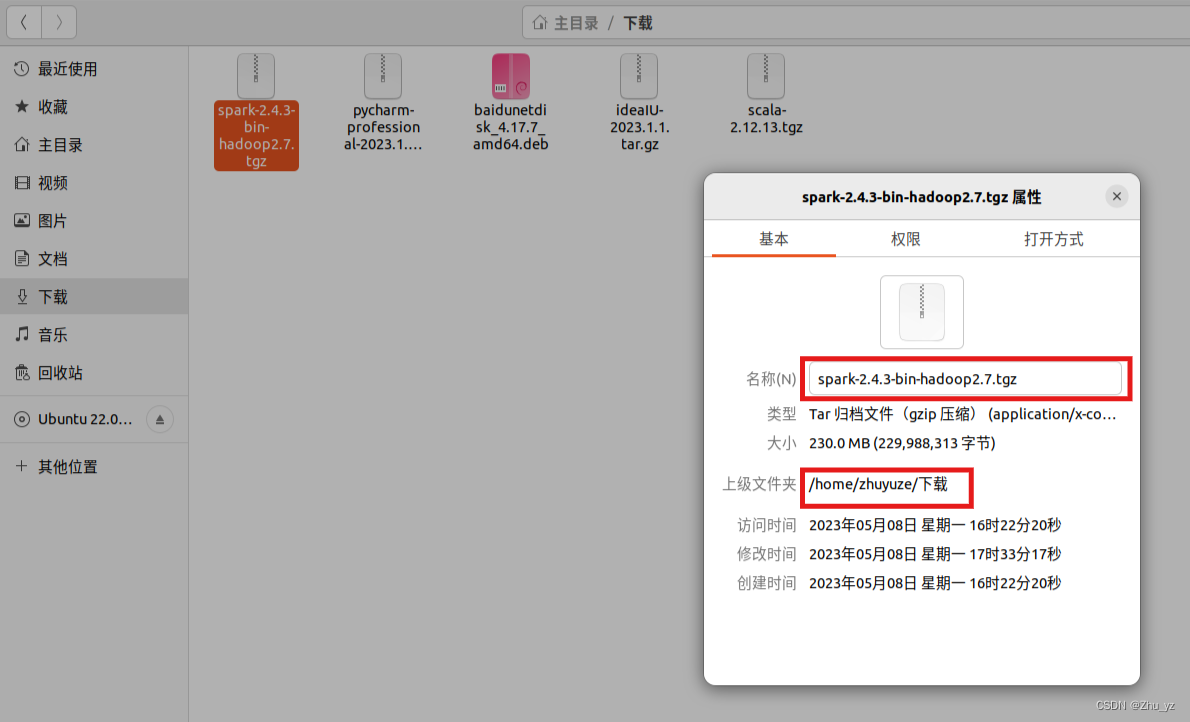
2、将spark解压到/usr/local路径下,并将文件名改为spark
sudo tar -zxf /home/zhuyuze/下载/spark-2.4.3-bin-hadoop2.7.tgz -C /usr/local
sudo mv ./spark-2.4.3-bin-hadoop2.7/ ./spark
- 1
- 2
3、为解压包创建一个软连接
cd /usr/local
ln -s spark/ spark
- 1
- 2
4、修改配置文件
cd spark/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
- 1
- 2
- 3
在文件最后添加配置内容,配置内容如下(根据自己的具体路径进行修改)
#java
export JAVA_HOME=/usr/lib/jvm/default-java
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
#scala
export SCALA_HOME=/usr/local/scala
#spark
export SPARK_MASTER_IP=计算机名
export SPARK_MASTER_PORT=7077
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
计算机名一定要修改为自己的计算机名,以下图为例(命令行模式)

翻译一下:用户名@计算机名:当前路径$…
zhuyuze@hadoop:/usr/local$…
此计算机名为hadoop
5、配置环境变量
vim ~/.bashrc
- 1
在文件最后添加以下代码
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
- 1
- 2
保存使其生效
source ~/.bashrc
- 1
6、启动spark
/usr/local/spark/sbin/start-all.sh
- 1

7、查看进程
jps
- 1

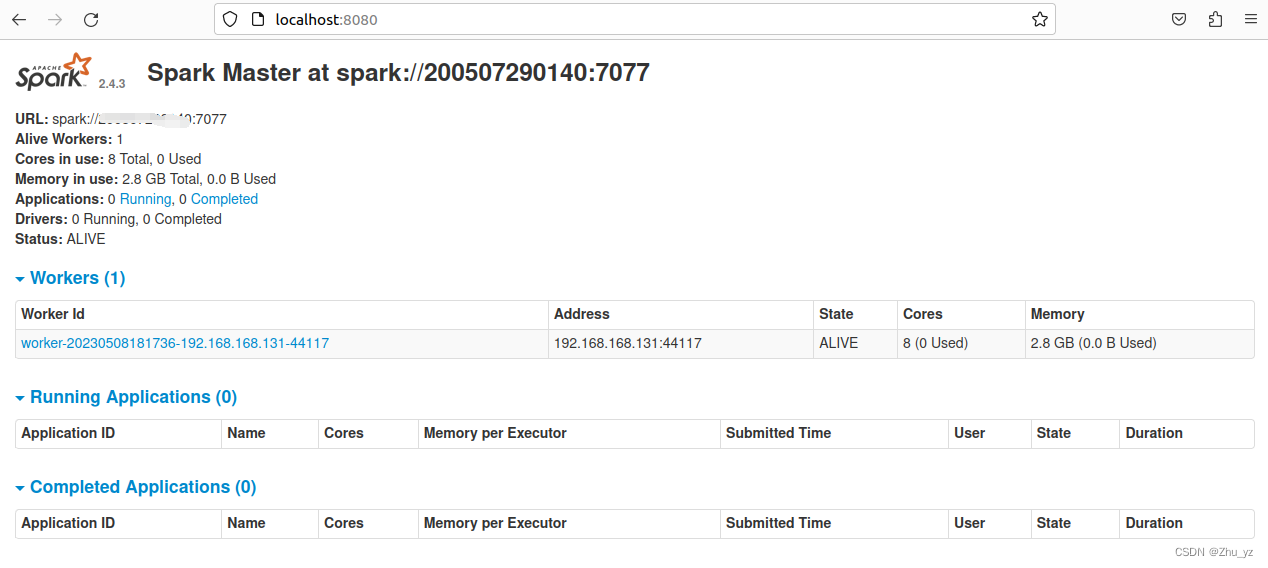
8、查看web界面
http://localhost:8080
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小桥流水78/article/detail/778605
推荐阅读
相关标签

